はじめに
こんにちわ。Wano株式会社エンジニアのnariと申します。
今回は、ECS(on EC2)でのAutoScaling設定について、設定したことや苦労したことをまとめようと思います。
今回のプロジェクトでは、インフラ管理にterraformを使用しているため、設定の大半がtfファイルで行われることをご了承ください。
今回やりたかったこと
1.需要に合わせてコンテナをオートスケールさせたい
今回のシステム要件として、アクセス数が集中する時とそうでない時にかなりトラフィックに差があるものだったので、それに適した需要に合わせて変動する、可用性の高いアーキテクチャを構築したい。
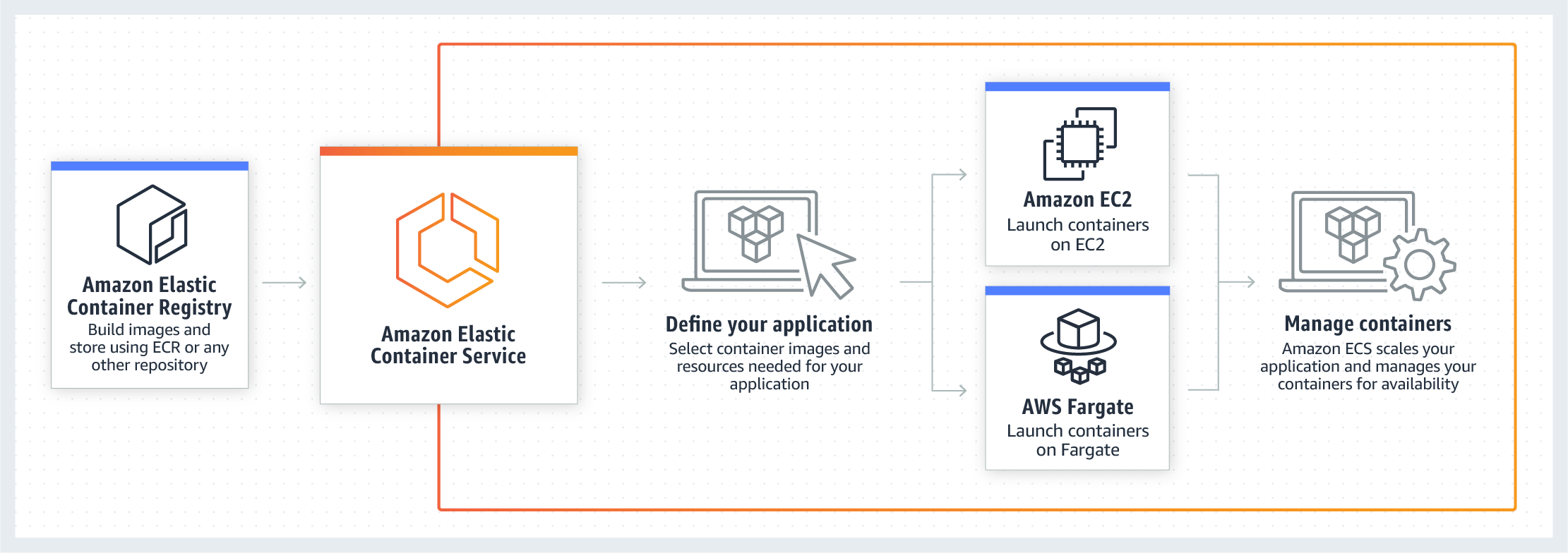
今回は様々な兼ね合いで、Fargateではなくon EC2のタイプを選択したので、コンテナインスタンス自体のスケールも設定する必要があリます。(これが考えることが非常に多くてめちゃくちゃめんどくさい)
しんどさの一番の要因は、スケールイン時にインスタンスをドレイニングの処理を毎回行う必要がある点です。こちらは詳しく後述します。
2.なるべくコストを抑えたい
せっかくEC2インスタンスを使用しているので、Fargateで運用するよりもコストを抑えて、せめてコスト面は恩恵にあずかりたい(Fargateでよしなにやってくれる分考えて設計する必要があるのでここで旨味が欲しい)
そこで、AutoScalingしてくれるインスタンスに関してはSpot Instanceで運用することを試みることにしてみました。
その際やっかいなのが、AWSの運用サーバーをなる安で管理するコツ(Spot Instance,userDataによる構成管理) - Qiitaでも書いた突然供給がストップされることです。
そのため、2分前の供給ストップ通知をうまいこと利用して安定供給のための仕組みを作る必要があります。
3.Blue Greenデプロイと共存させたい(rolling updateでも考慮が必要)
デフォルトのrolling Updateの仕様は、そのままだといささか怖いのでカナリー戦略なりBlue Greenしたいという話はAWS ECSでのデプロイをrolling updateからBlue/Greenデプロイに変更する - Qiitaでまとめた通りです。
しかし、FargateではなくEC2を利用した場合、Blue Greenできるだけのスペースをコンテナインスタンスに常に開けておく配慮が必要があり、その設定をする必要があります。
どう実現していったか
1.需要に合わせてコンテナをオートスケールさせたい
コンテナインスタンスのオートスケール
スケールインするインスタンスを事前にドレイニング
- ドレイニング状態となったインスタンスには新しいタスクが配置されなくなり、別のインスタンスにタスクが配置される。
- ドレイニングを行わずインスタンスを削除した場合、インスタンス上のコンテナが削除され、アプリケーションへの接続が遮断される
- インスタンスがスケールインすると、
"autoscaling:EC2_INSTANCE_TERMINATING"というeventが発行されるように設定し、それをキャッチするとそのインスタンスをドレイニングする仕組みを作る - ドレイニングの設定はAmazon ECS におけるコンテナ インスタンス ドレイニングの自動化方法 | Amazon Web Services ブログを参考に
- インスタンスがスケールインすると、
// EC2のAutoScaleGroupがスケールイン(減る)時、cloudwatch events で取得できるような状態を発行する
resource "aws_autoscaling_lifecycle_hook" "cluster" {
name = "${var.cluster_name}_autoscale_abandon_hook"
autoscaling_group_name = "${aws_autoscaling_group.default.name}"
default_result = "ABANDON"
heartbeat_timeout = 900
lifecycle_transition = "autoscaling:EC2_INSTANCE_TERMINATING"
notification_metadata = <<EOF
{
}
EOF
基本設定
- on_demand_base_capacityで最低限オンデマンドで発行したいインスタンス数を設定
- のちにアラームで発火するaws_autoscaling_policyをスケールアウトとイン両方分作っておく
resource "aws_launch_template" "default" {
name = "cluster-${var.component}-${var.deployment_identifier}-${var.cluster_name}"
image_id = "${data.template_file.ami_id.rendered}"
instance_type = var.cluster_instance_types[0]
key_name = "${aws_key_pair.cluster.key_name}"
iam_instance_profile {
name = "${aws_iam_instance_profile.cluster.name}"
}
vpc_security_group_ids = concat(list(aws_security_group.cluster.id), var.security_groups)
user_data = base64encode(data.template_file.cloud_init.rendered)
block_device_mappings {
device_name = "/dev/xvda" # root device name of amazon linux2
ebs {
volume_size = "${var.cluster_instance_root_block_device_size}"
volume_type = "${var.cluster_instance_root_block_device_type}"
delete_on_termination = true
}
}
depends_on = [
"null_resource.iam_wait"
]
}
resource "aws_autoscaling_group" "default" {
name = "asg-${aws_launch_template.default.name}"
vpc_zone_identifier = "${split(",", var.subnet_ids)}"
min_size = "${var.cluster_minimum_size}"
max_size = "${var.cluster_maximum_size}"
desired_capacity = "${var.cluster_desired_capacity}"
lifecycle {
ignore_changes = ["desired_capacity"]
}
mixed_instances_policy {
launch_template {
launch_template_specification {
launch_template_id = "${aws_launch_template.default.id}"
version = "${aws_launch_template.default.latest_version}"
}
dynamic override {
for_each = var.cluster_instance_types
content {
instance_type = override.value
}
}
}
instances_distribution {
on_demand_base_capacity = 1
on_demand_percentage_above_base_capacity = 0
spot_allocation_strategy = "lowest-price"
spot_instance_pools = "2"
}
}
tag {
key = "Name"
value = "cluster-worker-${var.component}-${var.deployment_identifier}-${var.cluster_name}"
propagate_at_launch = true
}
}
# Automatically scale capacity up by one
resource "aws_autoscaling_policy" "dev_api_scale_out" {
name = "${var.cluster_name}-Instance-ScaleOut-CPU-High"
scaling_adjustment = 1
adjustment_type = "ChangeInCapacity"
cooldown = 300
autoscaling_group_name = aws_autoscaling_group.default.name
}
# Automatically scale capacity down by one
resource "aws_autoscaling_policy" "dev_api_scale_in" {
name = "${var.cluster_name}-Instance-ScaleIn-CPU-Low"
scaling_adjustment = -1
adjustment_type = "ChangeInCapacity"
cooldown = 300
autoscaling_group_name = aws_autoscaling_group.default.name
}
コンテナのオートスケール
- serviceに対して、autoscaletargetと、コンテナインスタンス同様にアラームで発火するaws_appautoscaling_policyをスケールアウトとイン両方分作っておく
resource "aws_appautoscaling_target" "ecs_target" {
count = var.has_autoScaling ? 1 : 0
max_capacity = var.max_capacity
min_capacity = var.min_capacity
resource_id = "service/${var.cluster_name}/${aws_ecs_service.default.name}"
role_arn = var.ecs_scale_role
scalable_dimension = "ecs:service:DesiredCount"
service_namespace = "ecs"
}
# Automatically scale capacity up by one
resource "aws_appautoscaling_policy" "scale_out" {
count = var.has_autoScaling ? 1 : 0
name = "${var.service_name}-task_scale_up"
service_namespace = aws_appautoscaling_target.ecs_target[count.index].service_namespace
resource_id = aws_appautoscaling_target.ecs_target[count.index].resource_id
scalable_dimension = aws_appautoscaling_target.ecs_target[count.index].scalable_dimension
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 300
metric_aggregation_type = "Average"
step_adjustment {
metric_interval_lower_bound = 0
scaling_adjustment = 1
}
}
depends_on = [aws_appautoscaling_target.ecs_target]
}
# Automatically scale capacity down by one
resource "aws_appautoscaling_policy" "scale_in" {
count = var.has_autoScaling ? 1 : 0
name = "${var.service_name}-task_scale_down"
service_namespace = aws_appautoscaling_target.ecs_target[count.index].service_namespace
resource_id = aws_appautoscaling_target.ecs_target[count.index].resource_id
scalable_dimension = aws_appautoscaling_target.ecs_target[count.index].scalable_dimension
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 300
metric_aggregation_type = "Average"
step_adjustment {
metric_interval_upper_bound = 0
scaling_adjustment = -1
}
}
depends_on = [aws_appautoscaling_target.ecs_target]
}
アラームのオートスケール
増えたり減ったりするインスタンスと連動して、そのインスタンスに付随するアラームも減ったり増えたりする必要があります。こちらは以前記事にしているので省略します。
AWS AutoScalingで増減したEC2インスタンスに、動的にCloudWatchのAlarmをLambda(Go)で設定する - Qiita
2.なるべくコストを抑えたい
2分前中断通知でELBのtargetからインスタンスを外す
- スケールアウト時のコンテナインスタンスドレイニングに加え、それだけだとサービスアウトが2分以内という時間制限に引っかかることがあるようなので、ELBのtargetからインスタンスを外す処理を自前で書いてやる必要があるらしい
- 以下のようなイベントを拾う
{
"source": [
"aws.ec2"
],
"detail-type": [
"EC2 Spot Instance Interruption Warning"
]
}
- 以下のようなスクリプトを、ドレイニングのlambdaに追記する(中断通知の場合のみ実行)
func deregisterInstanceFromTargetGroup(ec2InstanceID string) error {
//1.まずinstanceのasgとinstance runningチェック
log.Info("まずinstanceのasgを取得")
ec := ec2.New(session.New(), &aws.Config{Region: aws.String("ap-northeast-1")})
ec2Output, err := ec.DescribeInstances(&ec2.DescribeInstancesInput{
InstanceIds: []*string{
aws.String(ec2InstanceID),
},
})
if err != nil {
return err
}
stateName := ec2Output.Reservations[0].Instances[0].State.Name
if *stateName != "running" {
return errors.New("もうすでに停止しているインスタンスです")
}
var asgName string
for _, tag := range ec2Output.Reservations[0].Instances[0].Tags {
if *tag.Key == "aws:autoscaling:groupName" {
asgName = *tag.Value
}
}
if asgName == "" {
return errors.New("autoScalingGroupが見つかりません")
}
//2.存在しているtargetGroupsを回して、該当のtargets(当該インスタンス分)を剥がす(deregister)
alb := elbv2.New(session.New(), &aws.Config{Region: aws.String("ap-northeast-1")})
descOutput, err := alb.DescribeTargetGroups(&elbv2.DescribeTargetGroupsInput{})
if err != nil {
return err
}
for _, targetGroup := range descOutput.TargetGroups {
albOutput, err := alb.DescribeTargetHealth(
&elbv2.DescribeTargetHealthInput{
TargetGroupArn: targetGroup.TargetGroupArn,
})
if err != nil {
return err
}
if err := dereginsterIfTargetsExists(alb, targetGroup.TargetGroupArn, extractHealthyAndInstanceTargets(ec2InstanceID, albOutput.TargetHealthDescriptions)); err != nil {
return err
}
}
return nil
}
func extractHealthyAndInstanceTargets(instanceID string, targetHealthDescriptions []*elbv2.TargetHealthDescription) []*elbv2.TargetDescription {
var targets []*elbv2.TargetDescription
for _, desc := range targetHealthDescriptions {
if *desc.Target.Id == instanceID && *desc.TargetHealth.State == "healthy" {
targets = append(targets, desc.Target)
}
}
return targets
}
func dereginsterIfTargetsExists(alb *elbv2.ELBV2, targetGroupArn *string, targets []*elbv2.TargetDescription) error {
if len(targets) == 0 {
return nil
}
log.Info("targetを剥がす(deregister)")
_, err := alb.DeregisterTargets(
&elbv2.DeregisterTargetsInput{
TargetGroupArn: targetGroupArn,
Targets: targets,
})
if err != nil {
return err
}
return nil
}
3.Blue Greenデプロイと共存させたい
- コンテナの予約メモリとCPUは基本的に、コンテナインスタンスのキャパの半分以下にする(1serviceの場合。2service以上の場合もblue greenできるだけのキャパの余白を常に確保する)
- 必ずコンテナインスタンスがのスケールアウトがコンテナのスケールアウトより先に起こるように設定する(autoscaling発火アラームの設定)
- このサンプルでは、CPUの使用量がある閾値を超えるとクラスターもサービスもスケールアウトを発火するようになっている(periodをClusterの方を短くして、Serviceより先に発火するようにする)
//autoScaling(cluster,service)発火用alarm
//scale out クラスターが先に
resource "aws_cloudwatch_metric_alarm" "cluster-scale-out-CpuUtilized-for-laboon-stage-ad-ecs-task" {
alarm_name = "scale-out-CpuUtilized-for-ecs-task autoscaling(cluster)発火アラーム(scale out)"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "2"
metric_name = "CpuUtilized"
namespace = "ECS/ContainerInsights"
period = "120"
statistic = "Average"
threshold = "320.0"
alarm_description = "scale-out-CpuUtilized-for-fluentd-ecs-task autoscaling(cluster)発火アラーム(scale out)"
alarm_actions = [
module.ecs_cluster.aws_autoscaling_scale_out_policy_arn
]
dimensions = {
TaskDefinitionFamily = module.task_definition.task_definition_family
ClusterName = module.ecs_cluster.cluster_name
}
}
resource "aws_cloudwatch_metric_alarm" "task-scale-out-CpuUtilized-for-ecs-task" {
alarm_name = "scale-out-CpuUtilized-for-ecs-task autoscaling(task)発火アラーム(scale out)"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "2"
metric_name = "CpuUtilized"
namespace = "ECS/ContainerInsights"
period = "300"
statistic = "Average"
threshold = "320.0"
alarm_description = "scale-out-CpuUtilized-for-ecs-task autoscaling(task)発火アラーム(scale out)"
alarm_actions = [
module.service.aws_appautoscaling_scale_out_policy_arn
]
dimensions = {
TaskDefinitionFamily = module.task_definition.task_definition_family
ClusterName = module.ecs_cluster.cluster_name
}
}
- サービスのタスク配置戦略として、instance毎に均等にタスクが配置される設定をする(以下のような)
resource "aws_ecs_service" "default" {
dynamic ordered_placement_strategy {
for_each = var.has_ordered_placement_strategy ? { dummy = "hoge" } : {}
content {
type = var.ordered_placement_strategy_type
field = var.ordered_placement_strategy_field
}
}
variable "ordered_placement_strategy_type" {
default = "spread"
}
variable "ordered_placement_strategy_field" {
default = "instanceId"
}
終わりに
まだこちら開発段階で、運用してからまたブラッシュアップされる部分がかなり出てくると思うので、そうなったらまた記事にしようと思います。
参考文献
- AWSを活用してゲームサーバーのコストを劇的に下げる––スポットインスタンスを効果的に使うための基礎知識 - ログミーTech
- AWS: aws_spot_fleet_request - Terraform by HashiCorp
- Amazon ECSを安定運用するためにやっていること コンテナインスタンス、ログ、モニタリングにおける工夫 - ログミーTech
- EC2のオートスケールが複数インスタンスタイプの混在指定に対応、廉価なスポット利用が実現しやすくなりました。 | DevelopersIO
- Auto Scalingでスポットインスタンスを活用しつつ可用性も確保する | DevelopersIO
- 終了通知が届いたスポットインスタンスをLambdaでELBから取り外してみた | DevelopersIO
- https://qiita.com/naomichi-y/items/d933867127f27524686a