こちらはフロムスクラッチAdvent Calendar 2017の10日目の記事です。
はじめに
大規模データをバッチで処理を行なった後にS3のバケット内に格納しておく、なんてことは日常茶飯事に行われいるのですが、処理後のデータがちゃんと処理されたのか、どういうデータ内容かを知りたいというニーズがあるようです。
そこでS3に格納されているcsvファイルに関してSQLによって検索し閲覧するためにApache Drillでの利用を検討してみました。
Apache Drill
Apache Drillはもともと2010年に発表されたGoogleのDremel(2012年にGoogle BigQueryとして提供)を元に開発が行われているOSSの分散処理フレームワークです。
2014年からはApacheのトップレベルプロジェクトにもなっています。
Apache Drillを利用することによって、HadoopディストリビューションやRDBMS、NoSQLにあるデータに対してSQLクエリを発行してデータを参照することができます。
なぜApache Drillか
SQL問い合せを行う分散処理フレームワークは、Apache Drill以外のもHiveやPrestoがありますが、スキーマ定義を行わなくてもデータセットに対してのクエリ問い合せが可能であるのがDrillの特徴です。
そのためHiveやPrestoのようにデータを参照するためには、まずスキーマ定義からしなければならないものと違って、一時的にデータセットに対して問い合せが行いたい場合には向いているかなと思います。
またApache DrillはMongoDBなどと同じく、半構造化データに対してのデータ処理を前提としており、公式サイトのチュートリアルにおいてもJSONファイルに対しての問い合せ処理が記述されています。
実践
チュートリアル
まずはApache Drillのダウンロードページから、ダウンロードを行います(今回はバージョン1.11を対象としています)。
以下のコマンドでダウンロードしたファイルを展開してDrillをembeddedモードで起動します。
$ tar -xvzf apache-drill-1.11.0.tar.gz
$ cd apache-drill-1.11.0
$ ./bin/drill-embedded
起動を行うと入力待ちの状態となるので、ここでDrillに組み込まれているサンプルデータ"employee.json"に問い合わせを行います。
0: jdbc:drill:zk=local> SELECT * FROM cp.`employee.json` LIMIT 5;
+--------------+------------------+-------------+------------+--------------+-------------------------+-----------+----------------+-------------+------------------------+----------+----------------+-------------------+-----------------+---------+--------------------+
| employee_id | full_name | first_name | last_name | position_id | position_title | store_id | department_id | birth_date | hire_date | salary | supervisor_id | education_level | marital_status | gender | management_role |
+--------------+------------------+-------------+------------+--------------+-------------------------+-----------+----------------+-------------+------------------------+----------+----------------+-------------------+-----------------+---------+--------------------+

| 1 | Sheri Nowmer | Sheri | Nowmer | 1 | President | 0 | 1 | 1961-08-26 | 1994-12-01 00:00:00.0 | 80000.0 | 0 | Graduate Degree | S | F | Senior Management |
| 2 | Derrick Whelply | Derrick | Whelply | 2 | VP Country Manager | 0 | 1 | 1915-07-03 | 1994-12-01 00:00:00.0 | 40000.0 | 1 | Graduate Degree | M | M | Senior Management |
| 4 | Michael Spence | Michael | Spence | 2 | VP Country Manager | 0 | 1 | 1969-06-20 | 1998-01-01 00:00:00.0 | 40000.0 | 1 | Graduate Degree | S | M | Senior Management |
| 5 | Maya Gutierrez | Maya | Gutierrez | 2 | VP Country Manager | 0 | 1 | 1951-05-10 | 1998-01-01 00:00:00.0 | 35000.0 | 1 | Bachelors Degree | M | F | Senior Management |
| 6 | Roberta Damstra | Roberta | Damstra | 3 | VP Information Systems | 0 | 2 | 1942-10-08 | 1994-12-01 00:00:00.0 | 25000.0 | 1 | Bachelors Degree | M | F | Senior Management |
+--------------+------------------+-------------+------------+--------------+-------------------------+-----------+----------------+-------------+------------------------+----------+----------------+-------------------+-----------------+---------+--------------------+
5 rows selected (0.603 seconds)
このようにSQLの結果が表示されます。またローカルのJSONファイルに対してもSQL問い合せを行うことが出来ます。
0: jdbc:drill:zk=local> SELECT * FROM dfs.`/Users/fuku68/employee.json`;
+--------------+---------------+-------------+------------+--------------+-----------------+-----------+----------------+-------------+------------------------+----------+----------------+------------------+-----------------+---------+--------------------+
| employee_id | full_name | first_name | last_name | position_id | position_title | store_id | department_id | birth_date | hire_date | salary | supervisor_id | education_level | marital_status | gender | management_role |
+--------------+---------------+-------------+------------+--------------+-----------------+-----------+----------------+-------------+------------------------+----------+----------------+------------------+-----------------+---------+--------------------+
| 1 | Sheri Nowmer | Sheri | Nowmer | 1 | President | 0 | 1 | 1961-08-26 | 1994-12-01 00:00:00.0 | 80000.0 | 0 | Graduate Degree | S | F | Senior Management |
+--------------+---------------+-------------+------------+--------------+-----------------+-----------+----------------+-------------+------------------------+----------+----------------+------------------+-----------------+---------+--------------------+
1 row selected (0.156 seconds)
上記のようにデータソースに対してスキーマ定義をせずにSQL問い合せを行うことが出来ます。
S3データソースに対する問い合せ
上記の例のように、DrillではFROM句でデータソースを指定する時に"cp"や"dfs"などと指定します。これはStorage Pluginと言われるものでデータソースの問い合せ先が定義されています。このStorage Pluginを定義することによって、HBaseやHive,MongoDB,kudoなどにあるデータソースに対して問い合せを行うことが出来ます。そのためS3のデータソースに対する問い合せを行うためには、まずS3用のStorage Pluginを定義します。
Drillをembeddedモードで起動していれば、同時にWebサーバも立ち上がるので、http://localhost:8047 へアクセスすると以下のようなページが開きブラウザ経由でDrillを操作することが出来ます。

次に上部のメニューから[Storage]を選択するとStorage Pluginの一覧が表示されます。

DrillではDisables Storage Plugin欄にS3用ののStorage Pluginの雛形が定義されているので、S3の[Update]ボタンからStorage Pluginの定義情報を開きます。
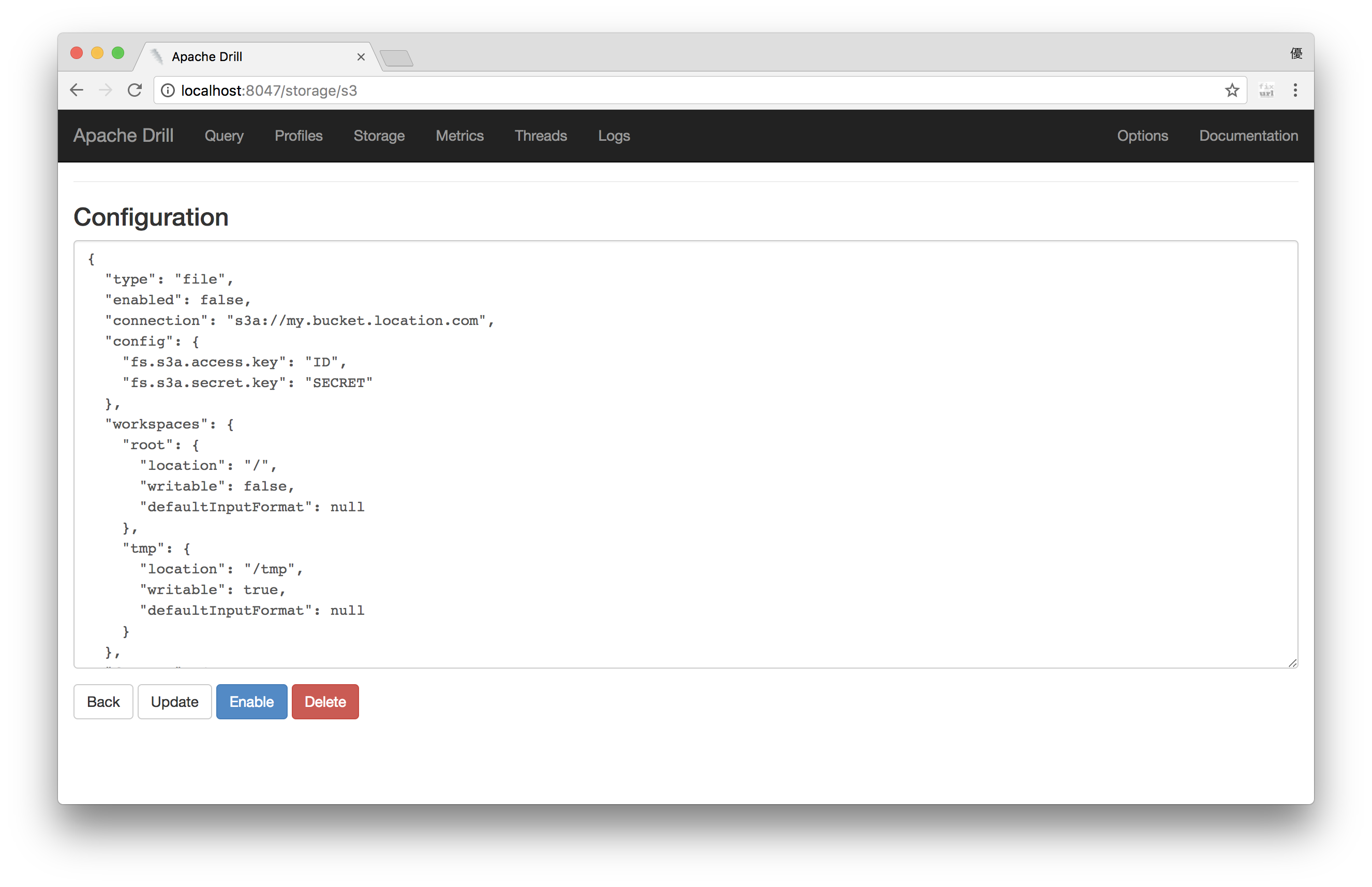
定義情報はJSON形式で定義されており、S3へアクセスするために、"connection"と"config"プロパティを以下のようにバケット名、アクセスキー、シークレットキーの情報に書き換えて[Enable]ボタンから保存と有効化を行います。
{
"connection": "s3a://<バケット名>",
"config": {
"fs.s3a.access.key": "<アクセスキー>",
"fs.s3a.secret.key": "<シークレットキー>"
},
}
これでS3のStorage Pluginが利用出来るようになりました。

では実際にS3上にCSVデータをおいて問い合せを行います(この記事を書いている時間が...)。

上記のテストデータに対して...
SELECT * FROM s3.`test_data.csv`;
SQL問い合せをすると...

このようにS3上のデータが表示されました(今回はブラウザからSQLの実行を行なっています)。
KMSの壁
無事にS3上のデータソースに対して問い合せも行い、よしよしと思ながら次は業務データと思い業務データに対して問い合わせを行いました。
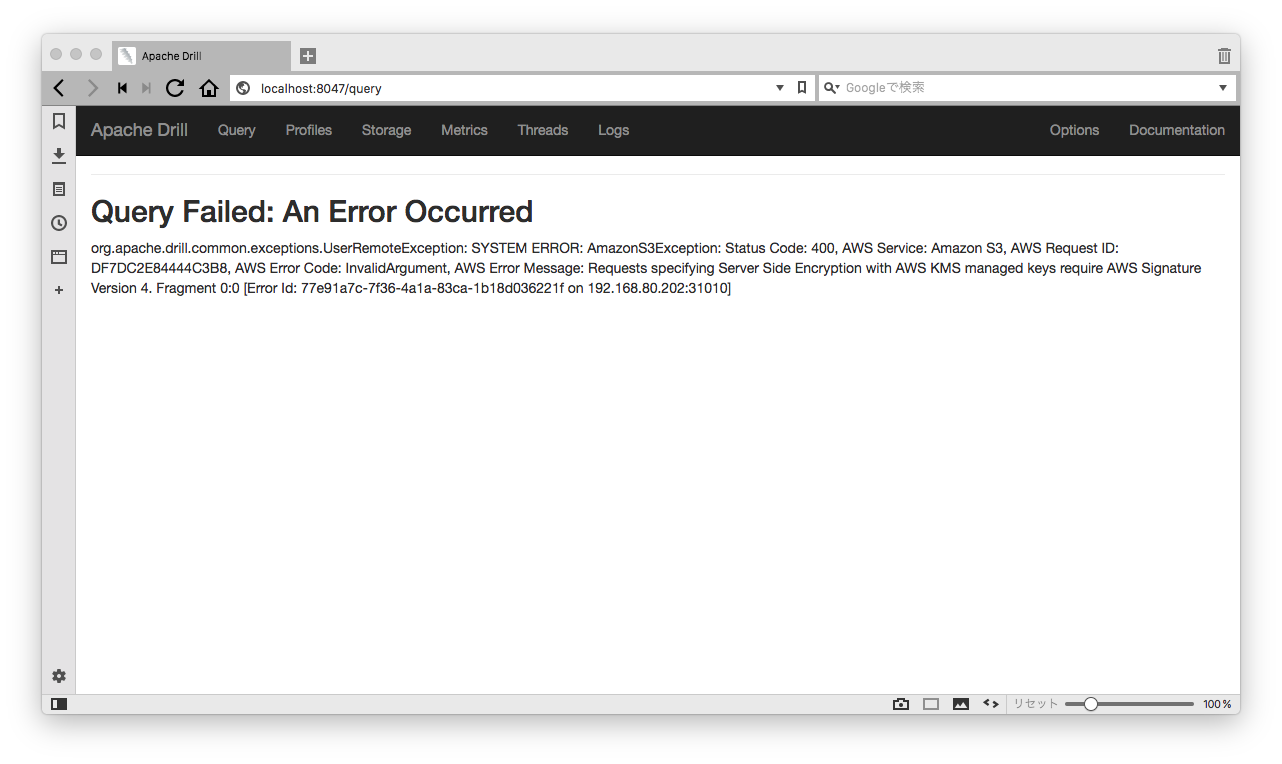
...んっ?
そうかKMSで暗号化されているんだった...
じゃKMS対応のStorage Pluginの設定項目でもあるのかな、としばらく色々調べてみるも
下記のISSUEから現在のバージョンで対応してないことが判明...
https://issues.apache.org/jira/browse/DRILL-5536
どうやらDrillで指定しているHadoopのJarが2.7古くて対応していないよう、2.8からは対応しているのに...
ということで暗号化されたS3上のデータソースに関しては自前でビルドする必要があるようです。
Apache Drillのビルド
気を取り直して、DrillのGithubからソースコードを取ってきます。
$ git clone https://github.com/apache/drill.git
$ cd drill
$ vi pom.xml
ソースコードを取ってきたら、pom.xmlでhadoopのバージョンを変更します。
# 変更前
<hadoop.version>2.7.1</hadoop.version>
# 変更後
<hadoop.version>2.8.2</hadoop.version>
あとはドキュメントに記載されている通りにビルド実行。ビルド時間は長いので、気長に待ちましょう。
$ mvn clean install -DskipTests
ビルドが完了すると"distribution/target"パスいかにtar.gzファイルが出来るので、展開して最初と同じようにembeddedモードで起動し暗号化されたデータソースに対してクエリを実行すると...
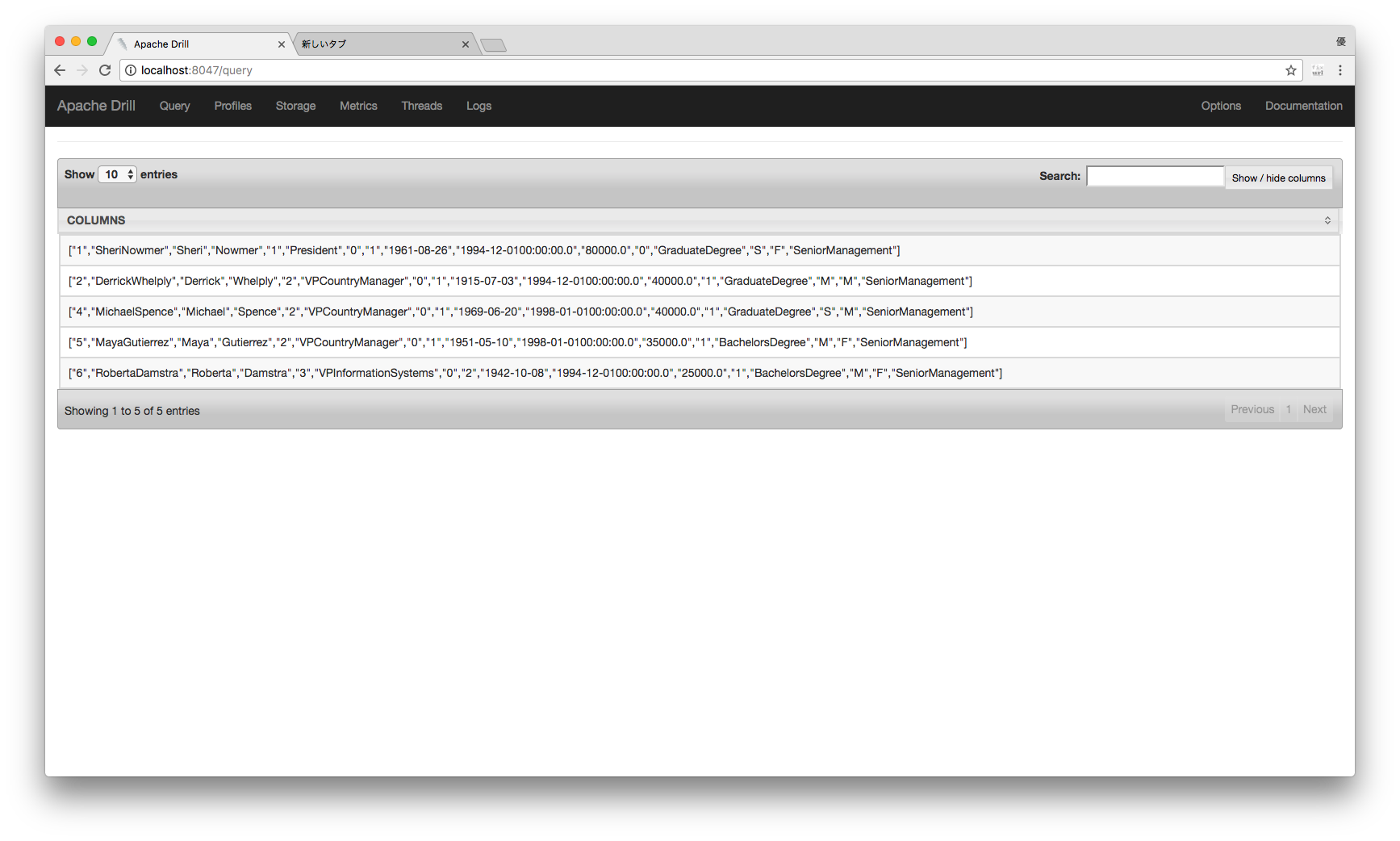
無事に結果が表示されました。
終わりに
今回はS3上のKMS暗号化されたデータソースに対してApache Drillから問い合せを行う方法に関して書きました。
近年では分散処理のOSSが当たり前となっているので、技術者としては必要に応じてキャッチアップを行い、サービスに生かして行けたらと思っています。