はじめに
前回は、SSDのPytorch版を使って自作画像データで学習して物体検出を行った。
https://github.com/amdegroot/ssd.pytorch
今回は、Yolov5のPytorch版を使って自作画像データで学習して物体検出を行う。
https://github.com/ultralytics/yolov5
Yolov5のインストール
参考HPを列挙します
① YOLOv5を使った物体検出
https://www.alpha.co.jp/blog/202108_02
② YOLOv5+PyTorchを試してみるだけ
https://qiita.com/diyin_near_j/items/3fdce6bfadea9085bffa
③ YOLO V5】AIでじゃんけん検出
https://qiita.com/PoodleMaster/items/5f2cc3248c03b03821b8
anaconda3(64bit)がインストールされている環境で
Anaconda Prompt3(Anaconda3)を実行してターミナル画面を起動する。
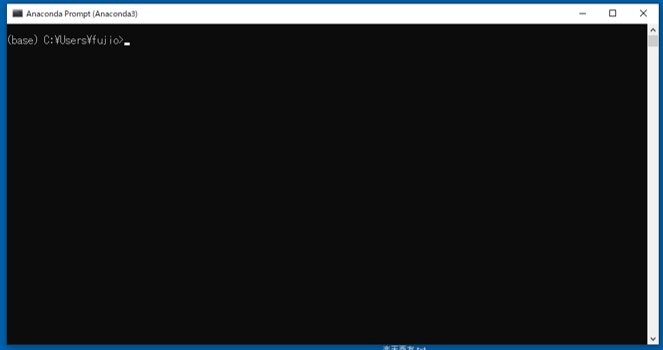
condaでyolo環境を設定し、この環境に切り替えるコマンド
(base) C:\Users\fujio>conda create --name yolo5 python=3.9
(base) C:\Users\fujio>conda activate yolo5
(yolo5) C:\Users\fujio>
python virsion確認
(yolo5) C:\Users\fujio>python --version
Python 3.9.0
(yolo5) C:\Users\fujio>
YOLOv3のPyTorchバージョンを開発していたUltralyticsが、GitHubにYOLOv5のリポジトリを公開しています。
そのリポジトリからYOLOv5をダウンロードします。
https://github.com/ultralytics/yolov5
(yolo5) C:\Users\fujio>git clone https://github.com/ultralytics/yolov5
必要なライブラリをインストールします。
(yolo5) C:\Users\fujio>cd yolov5
(yolo5) C:\Users\fujio\yolov5>pip install -r requirements.txt
自作画像データで学習する
画像strobery001.jpgに対して、アノテーションファイルstrobery001.txtを作成する必要があります。
画像収集
学習用のイチゴの画像を100枚集めた

アノテーションツールlabellingを入手する
アノテーションツールlabellingの実行型ソフト(Windows_v1.8.0.zip)を次のサイトからダウンロードする
https://tzutalin.github.io/labelImg/

解凍したホルダ内のC:\labelling_windows_v1.8.0\labelling.exeを実行する

yolo形式のアノテーションファイルを作成する
① 左の形式指定をクリックしてPascalVOCをYOLOに切り替える
② wキーを押してイチゴの部分に四角を描く
③ ラベル候補が小ウィンドウに表示されるが今回はイチゴのみを学習させるので他の候補を削除する
削除するには、C:\labelling_windows_v1.8.0\data\predefined_classes.txt ファイルを空白に書き換える
④ 候補がなくなった状態でstroberyを登録する これで、ラベル番号0でファイルが作成される
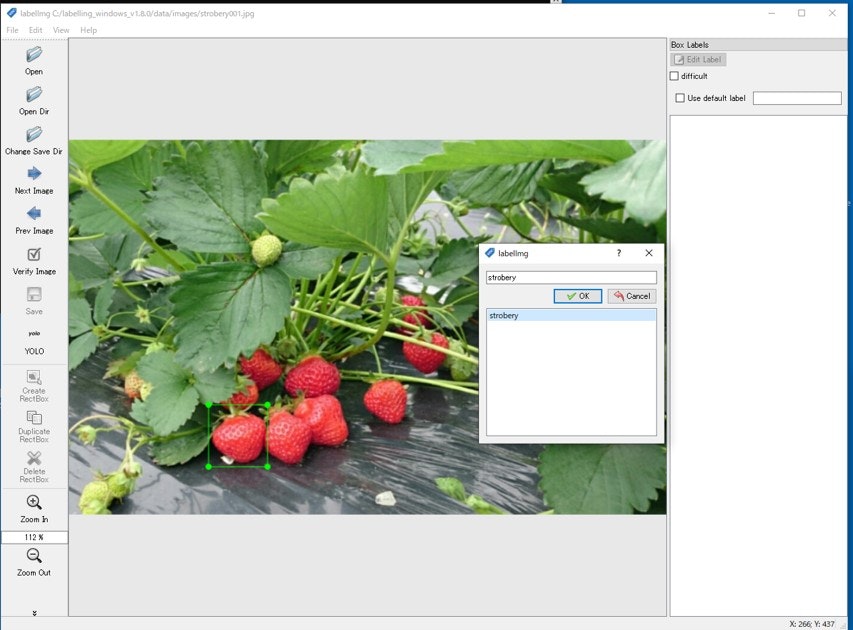

⑤ 複数のイチゴに四角を描いてラベル登録した後 save コマンドアイコンをクリックするとstrobery001.txt ファイルが作成される ファイルの中身は下記のようになっている
0 0.283125 0.785857 0.091250 0.165339
0 0.363750 0.780876 0.092500 0.187251
0 0.424375 0.750000 0.111250 0.149402
0 0.530000 0.687250 0.085000 0.167331
0 0.604375 0.558765 0.083750 0.137450
0 0.574375 0.458167 0.073750 0.103586
0 0.319375 0.598606 0.076250 0.137450
0 0.282500 0.672310 0.075000 0.101594
学習準備
学習用画像ファイルとアノテーションファイルと検証用画像ファイルを次のディレクトリに格納する
学習用画像ファイル
C:\Users\fujio\yolov5\data\train\images
学習用アノテーションファイル
C:\Users\fujio\yolov5\data\train\labels
検証用画像ファイル
C:\Users\fujio\yolov5\data\valid\images
次に、dataフォルダ内にdata.yamlを作成します。
data.yamlはデータセットの設定ファイルです。
#
# yolov5
# └─ data
# └─train
# | └─images
# | | └─strobery001.jpg
# | | strobery002.jpg
# | |
# | └─labels
# | └─strobery001.txt
# | strobery002.txt
# |
# └─valid
# └─images
# └─strobery201.jpg
# strobery202.jpg
#
train: data/train/images # 学習の画像のパス
val: data/valid/images # 検証用画像のパス
nc: 1 # クラスの数
names: [ 'strobery' ] # クラス名
学習コマンドをプロンプト画面に打ち込む
(yolo5) C:\Users\fujio>cd yolov5
(yolo5) C:\Users\fujio\yolov5>train.py --data data.yaml --weights yolov5s.pt --epochs 100 --batch 4
3時間半位で学習が完了すると、runs/train/exp/weightsにlast.pt, best.ptの重みファイルが生成される。
#物体検出
前節で学習させたモデルを使用して物体検出をしてみる。
best.ptを重みファイルとして使用するので、best.ptをyolov5ディレクトリの直下へコピーします。
yolov5ディレクトリに入ってdetect.pyを実行する。
USBカメラで物体検出するには引数sourceに0を指定する。
引数weightsにbest.ptを指定して物体検出する。
(yolo5) C:\Users\fujio>cd yolov5
(yolo5) C:\Users\fujio\yolov5>python detect.py --source 0 --weight best.pt
カメラがイチゴを検出してる画面 検出速度 0.16秒 6FPS です。

ラベル表示が大きすぎるのでplots.pyのソースをいじりました。
① 四角の色を赤から緑にし太さも細くします
② ラベル文字を囲む四角は無くします コメントアウトします
③ ラベル文字も小さく、細くしました
## cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
cv2.rectangle(self.im, p1, p2, (0,255,0), thickness=1, lineType=cv2.LINE_AA)
if label:
tf = max(self.lw - 1, 1) # font thickness
w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
outside = p1[1] - h - 3 >= 0 # label fits outside box
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
## color=(128, 128, 128)
## cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
## cv2.putText(self.im, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, self.lw / 3, txt_color,
## thickness=tf, lineType=cv2.LINE_AA)
## txt_color=(255, 255, 255) white
##
cv2.putText(self.im
, label
, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2)
, cv2.FONT_HERSHEY_SIMPLEX
, self.lw / 6
, txt_color
, thickness = 1 )

キャプチャは「'q'」を押下で終了できます。何度か繰り返すと割り込めて終了します。