前回作成したツールへ、ルビ変換機能を追加します。
今回のゴールは以下です。
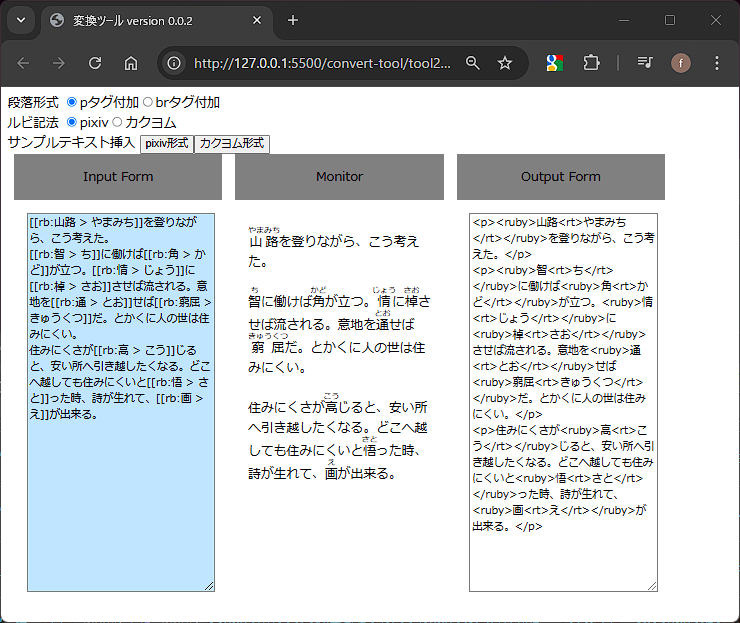
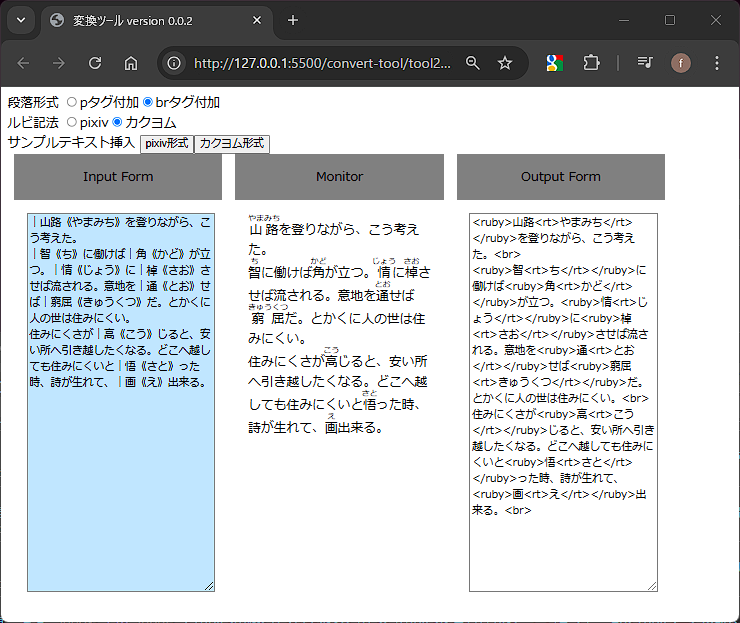
ルビ記法は媒体によって様々なため、今回はpixiv記法とカクヨム記法(部分的)に対応しました。
pixiv記法: [[rb:漢字 > かんじ]]
カクヨム記法: |漢字《かんじ》
カクヨム記法は、「《記号の前が漢字の連続であれば、その連続部分に《》内の文字を振る」という仕組みもあるのですが、今回はそれには対応していません。
「漢字である」という判定がややこしそうだからです。
では、今回の仕組みです。
入出力欄
<div>
ルビ記法
<label><input type="radio" v-model="settingRubyType" value="first" checked />pixiv</label>
<label><input type="radio" v-model="settingRubyType" value="second" />カクヨム</label>
</div>
<div>
サンプルテキスト挿入
<button @click="insertSample(0)">pixiv形式</button>
<button @click="insertSample(1)">カクヨム形式</button>
</div>
見た目のデザインは、今のところ設定せず、デフォルトのままにしています。
ルビ記法のタイプを選択する部分を追加しました。
また、今後ツールのテストを楽にするため、サンプルテキストを挿入できるようにしました。
サンプルテキスト
以下のような関数を作成しました。
サンプルテキストは一部界隈の一部世代にはおなじみのテキストである「草枕」(夏目漱石著)からです。
insertSample(number) {
if(number === 0) {
this.inputText = `[[rb:山路 > やまみち]]を登りながら、こう考えた。
[[rb:智 > ち]]に働けば[[rb:角 > かど]]が立つ。[[rb:情 > じょう]]に[[rb:棹 > さお]]させば流される。意地を[[rb:通 > とお]]せば[[rb:窮屈 > きゅうくつ]]だ。とかくに人の世は住みにくい。
住みにくさが[[rb:高 > こう]]じると、安い所へ引き越したくなる。どこへ越しても住みにくいと[[rb:悟 > さと]]った時、詩が生れて、[[rb:画 > え]]が出来る。`;
}
else {
this.inputText = `|山路《やまみち》を登りながら、こう考えた。
|智《ち》に働けば|角《かど》が立つ。|情《じょう》に|棹《さお》させば流される。意地を|通《とお》せば|窮屈《きゅうくつ》だ。とかくに人の世は住みにくい。
住みにくさが|高《こう》じると、安い所へ引き越したくなる。どこへ越しても住みにくいと|悟《さと》った時、詩が生れて、|画《え》出来る。`;
}
}
最初、ヒアドキュメントを使おうとして、<<EOFを書いたのですが、動かなくて調べたところ、JSにはヒアドキュメント相当がないらしいと知りました。
そのため、テンプレートリテラルを用いました。
後は、準備したテキストを普通に変数に入れただけです。
ルビ変換
ルビ変換は、正規表現による照合と置換を行いました。
正規表現と一致した箇所が見つからなくなるまで照合と置換を繰り返すことで、テキスト全体のルビ記法をHTMLのルビ記法へ置換しています。
convertText(inputText) {
let convertedText = inputText;
let matchResult = true;
while (matchResult) {
let regex = ""
if (this.settingRubyType.includes("first")) {
regex = /\[\[rb:(.+?) > (.+?)\]\]/;
}
else {
regex = /\|(.+?)《(.+?)》/;
}
matchResult = convertedText.match(regex);
if (matchResult) {
convertedText = convertedText.replace(matchResult[0], "<ruby>" + matchResult[1] + "<rt>" + matchResult[2] + "</rt></ruby>")
}
}
const splitedText = convertedText.split("\n");
if (this.settingPerLine.includes("first")) {
return splitedText.map(el => "<p>" + el + "</p>\n").join("");
}
else {
return splitedText.map(el => el + "<br>\n").join("");
}
}
記載の正規表現(/\[\[rb:(.+?) > (.+?)\]\]/)では、matchResultに以下のような値が入ります。
[
"[[rb:山路 > やまみち]]",
"山路",
"やまみち"
]
そのため、matchResult[0]を"<ruby>" + matchResult[1] + "<rt>" + matchResult[2] + "</rt></ruby>"で置換することで、ルビ記法の変換が行われます。
一致する箇所がなくなると、matchResult = nullとなり、whileループが終わります。
終わりに
ツールが少し進化しました。
pixivなどのSNSに加え、HTMLを手打ちして作成するタイプの自サイトを持っている場合は、ルビ変換機能は役立つかもしれません。
今回は一方向のルビ変換ですが、使いやすい仕組みをもう少し考えて、両方向での変換を行えるようにするのもよさそうです。
別機能も今後追加していきましょう。