今回は scikit-learn を使ったナイーブベイズ分類器による迷惑メールの分類を行います。
モデルは前回投稿のベルヌーイ分布を使用します。
データセット
迷惑メールのデータセットは、Kaggle に登録されている以下のデータセットを利用します。
「SMS Spam Collection Dataset」
https://www.kaggle.com/uciml/sms-spam-collection-dataset
このデータセットは、'v1'カラムに spam(迷惑メール)と ham(迷惑メール以外)のスパム判定値が、
'v2'カラムに、メールの文章が格納されています。
また、不要なカラムも存在するためデータの前処理で削除します。

実装コード
データセット準備
先ほどの Kaggle のサイトから sms-spam-collection-dataset.zip をダウンロードし、
解凍した spam.csv を任意のディレクトリにダウンロードしておきます。
インポート
各種ライブラリをインポートします。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import BernoulliNB
データ準備
データセットを読み込み、不要なカラムを削除します。
また、カラム名を分かりやすく 'v1' -> 'class', 'v2' -> 'text' に変更します。
# CSV読み込み
df = pd.read_csv('/path/to/spam.csv', encoding='latin-1')
# 未使用列を削除
df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
# リネーム
df.rename(columns={"v1":"class", "v2":"text"}, inplace=True)
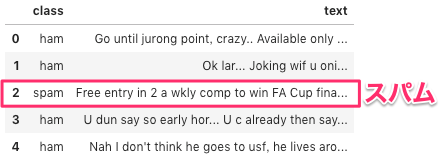
データの先頭5件を表示します。
df.head()
不要なカラムの除去、カラム名が変更されている事が確認できます。
トレーニング・評価データ準備
次に、データセットを 7:3でトレーニングデータと評価データに分けます。
乱数はrandom_state=10で固定しました。
# トレーニング・評価データ分割
X = pd.DataFrame(df['text'])
Y = pd.DataFrame(df['class'])
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.7, test_size=0.3, random_state=10)
テキストデータのベクトル化
テキストデータはそのまま特徴量としては使えないため、
テキストに出現する単語をカウントし、その出現数を特徴量として使います。
※このような情報を数値に変換するプロセスはベクトル化と呼ばれます。
また、sklearn に用意されている CountVectorizer クラスを使う事で、
テキストに出現する単語のカウントが行えます。
まずは、トレーニングデータを使い特徴量とする単語の種類を検出します。
min_df=Nは出現数が低い単語を除外するオプションとなり、
出現数がN回以下の単語は検出しません。
# 単語の出現回数取得
vec_count = CountVectorizer(min_df=3)
vec_count.fit(X_train['text'])
# 単語の種類
print('word size: ', len(vec_count.vocabulary_))
# 先頭5件の単語を表示
print('word content: ', dict(list(vec_count.vocabulary_.items())[0:5]))
fit()を実行すると、単語が 2196 種類検出された事がわかります。
検出された単語を5件見てみると、'hey', 'there'などが検出されている事がわかります。
word size: 2196
word content: {'hey': 901, 'there': 1885, 'babe': 266, 'how': 936, 'doin': 607}
次にtransform()を使い、トレーニングデータと評価データをベクトル化します。
# トレーニング・評価データをベクトル化
X_train_vec = vec_count.transform(X_train['text'])
X_text_vec = vec_count.transform(X_test['text'])
# 先頭5件のベクトル化データ表示
pd.DataFrame(X_train_vec.toarray()[0:5], columns=vec_count.get_feature_names())
単語の種類が多過ぎて、出現数が0で埋め尽くされていますが、
各単語に対する出現数が表示されています。
モデル作成
ベクトル化したトレーニングデータでモデルを作成します。
モデルにベルヌーイを使用します。
また、ベルヌーイモデルは入力特徴量としてバイナリ変数(0 または 1)である必要があるため、
今回のように出現数を特徴とした場合、カウントが1を超える場合がありますが、
デフォルトでカウントが2以上となる場合は、1に丸め込まれるようになっているため、
そのまま利用する事が可能になります。
※この丸め込むための閾値は、binarize オプションで設定が可能です。
# ベルヌーイモデル
model = BernoulliNB()
model.fit(X_train_vec, Y_train['class'])
評価
作成したモデルを使い、評価を実行します。
print('Train accuracy = %.3f' % model.score(X_train_vec, Y_train))
print(' Test accuracy = %.3f' % model.score(X_text_vec, Y_test))
精度は、トレーニングデータをそのまま使った場合は、0.989
評価データを使った場合では、0.984 となりました。
このデータセットに対する精度は高そうです。
Train accuracy = 0.989
Test accuracy = 0.984
予測
次に、予測用のテキストを用意し、予測を行ってみます。
まずは、ベクトル化した予測テキストデータを準備します。
# 予測テキストデータ作成
data = np.array(['I am happy.',
'Are you happy? 00',
'Free service! Please contact me immediately. But it is 300 US dollars next month.'])
df_data = pd.DataFrame(data, columns=['text'])
# 予測テキストデータをベクトル化
input_vec = vec_count.transform(df_data['text'])
# ベクトル化データ表示
pd.DataFrame(input_vec.toarray(), columns=vec_count.get_feature_names())
ベクトル化したデータを表示します。
二番目のデータには "00" と入れたので、単語がカウントされています。

次に予測を実行します。
model.predict(input_vec)
予測結果は以下のようになりました。
array(['ham', 'ham', 'spam'], dtype='<U4')
まとめると以下のようになり、全問正解しています。
| 予測 | 正解 | 予測テキスト |
|---|---|---|
| ham | ham | I am happy. |
| ham | ham | Are you happy? 00 |
| spam | spam | Free service! Please contact me immediately. But it is 300 US dollars next month. |
以上、今回は scikit-learn を使ったナイーブベイズ分類器による迷惑メールの分類を行いました。