xarray を用いたデータ解析
以前の記事
で紹介したxarrayを用いたデータ解析について、もう少し実用的な面から紹介します。
著者について
2017年から、pydata xarray の開発メンバー。
ここ最近はもっぱらユーザーですが、たまにバグ修正のPRを送ったりしています。
本業で行うほぼ全てのデータ解析に xarray を使っています。
想定している読者について
numpy についてある程度知っている(np.ndarray を使った操作・演算ができる)ことを想定しています。
本記事の構成
この記事では、もう一度 xarray のデータモデルを紹介したあと、基本的な操作であるインデクシングについて述べます。
このインデクシングが xarray の本質だと言っても良いかもしれません。
その後、インデクシングの逆操作である concat を紹介します。
これらを踏まえた上で、実際にデータを作ることを考えた時、どのようなデータ構成にしておけば xarray での解析が容易になるか紹介します。
データの保存・読み込みや、dask を使った out-of-memory 処理についても少し述べます。
なお、本記事はGoogle collaboratoryを使って執筆しています。
こちらからコピーしてもらうことで、誰でも実行・トレースできます。
xarray のデータモデル
概要
xarray を一言で述べると、 座標軸付きの多次元配列 です。numpy の nd-array と、pandas の pd.Series を合わせたものだと考えてもよいかもしれません。
使い方に慣れてくると、データ解析の途中で座標のことを考えなくてよくなるので非常に便利です。
一方で、使い方が少し独特であり、学習コストが高いとよく言われます。
この記事は、その学習コストを少しでも低くすることを目指しています。
xarray には大きく2つのクラスがあります。1つは xarray.DataArray で、もう一つは xarray.Dataset です。
それらについて紹介します。
なお、これは 多次元データ解析ライブラリ xarray で述べた内容とほぼ同一です。
xarray.DataArray
座標軸付きの多次元配列 である xarray.DataArray を紹介します。オブジェクトの作り方については後に述べますが、まずは xarray.tutorial にあるデータを用いて説明します。
import numpy as np
import xarray as xr
data = xr.tutorial.open_dataset('air_temperature')['air']
data
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
[3869000 values with dtype=float32]
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]ここで、 data は3次元の xr.DataArray インスタンスです。なお、xarray のオフィシャルな略語は xr です。
data を表示すると、上記のようなサマリが表示されます。一番上の行の (time: 2920, lat: 25, lon: 53) は、格納されている配列の次元名およびその要素数を表しています。
このように、xarray では 各次元に名前をつけて扱います(オフィシャルなドキュメントでは label と呼ばれています)。
1軸目が time 軸、2軸目が lat 軸、3軸目が lon 軸です。
このように名前をつけておくことで、軸の順番を気にしなくてよくなります。
さらに、それぞれの軸には座標値が付加されています。座標のリストが Coordinates セクションに表示されます。
このデータでは、time, lat, lon の全ての軸に座標がついています。
また、その他のデータも添付できます。それらは Attributes セクションにあります。
インデクシングの節で詳しく述べますが、座標軸がついていることで所望の範囲のデータを直感的に取得することができます。例えば 2014年8月30日のデータが欲しい場合、
data.sel(time='2014-08-30')
<xarray.DataArray 'air' (time: 4, lat: 25, lon: 53)>
array([[[270.29 , 270.29 , ..., 258.9 , 259.5 ],
[273. , 273.1 , ..., 262.6 , 264.19998],
...,
[299.5 , 298.79 , ..., 299. , 298.5 ],
[299.29 , 299.29 , ..., 299.9 , 300. ]],
[[269.9 , 270.1 , ..., 258.6 , 259.5 ],
[273. , 273.29 , ..., 262.5 , 265. ],
...,
[299.19998, 298.9 , ..., 298.5 , 298. ],
[299.4 , 299.69998, ..., 299.19998, 299.6 ]],
[[270.4 , 270.69998, ..., 261.29 , 261.9 ],
[273. , 273.6 , ..., 266.4 , 268.6 ],
...,
[297.9 , 297.6 , ..., 298.29 , 298.29 ],
[298.69998, 298.69998, ..., 299.1 , 299.4 ]],
[[270. , 270.4 , ..., 266. , 266.19998],
[273. , 273.9 , ..., 268.1 , 269.69998],
...,
[298.5 , 298.29 , ..., 298.69998, 299. ],
[299.1 , 299.19998, ..., 299.5 , 299.69998]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2014-08-30 ... 2014-08-30T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]のようにできます。ここで.selメソッドは座標軸を用いてデータを選ぶために用います。.sel(time='2014-08-30') は、time軸を参照して'2014-08-30' であるデータを選んでくることに相当します。
DataArray に関する演算
DataArray は np.ndarray のような多次元配列でもあるので、np.ndarrayに対するような演算を行うことができます。
data * 2
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
array([[[482.4 , 485. , 487. , ..., 465.59998, 471. ,
477.19998],
[487.59998, 489. , 489.4 , ..., 465.59998, 470.59998,
478.59998],
[500. , 499.59998, 497.78 , ..., 466.4 , 472.78 ,
483.4 ],
...,
[593.2 , 592.39996, 592.8 , ..., 590.8 , 590.2 ,
589.39996],
[591.8 , 592.39996, 593.58 , ..., 591.8 , 591.8 ,
590.39996],
[592.58 , 593.58 , 594.2 , ..., 593.8 , 593.58 ,
593.2 ]],
[[484.19998, 485.4 , 486.19998, ..., 464. , 467.19998,
471.59998],
[487.19998, 488.19998, 488.4 , ..., 462. , 465. ,
471.4 ],
[506.4 , 505.78 , 504.19998, ..., 461.59998, 466.78 ,
477. ],
...
[587.38 , 587.77997, 590.77997, ..., 590.18 , 589.38 ,
588.58 ],
[592.58 , 594.38 , 595.18 , ..., 590.58 , 590.18 ,
588.77997],
[595.58 , 596.77997, 596.98 , ..., 591.38 , 590.98 ,
590.38 ]],
[[490.18 , 488.58 , 486.58 , ..., 483.37997, 482.97998,
483.58 ],
[499.78 , 498.58 , 496.78 , ..., 479.18 , 480.58 ,
483.37997],
[525.98 , 524.38 , 522.77997, ..., 479.78 , 485.18 ,
492.58 ],
...,
[587.58 , 587.38 , 590.18 , ..., 590.58 , 590.18 ,
589.38 ],
[592.18 , 593.77997, 594.38 , ..., 591.38 , 591.38 ,
590.38 ],
[595.38 , 596.18 , 596.18 , ..., 592.98 , 592.38 ,
591.38 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00直感的にそうあるべきなように、掛け算はアレイデータに対してのみ行われ、座標軸データは変更されずにそのまま保持されます。
アレイ以外で保持できるデータ
アレイデータ以外に、Coordinate を保持できることを述べました。Coordinateデータは以下のように分類できます。
- dimension coordinate
- non-dimension coordinate
- scalar coordinate
Dimension coordinate
これは、前節で Coordinate として紹介したものです。dimensionの名前(前節のデータではtime, lon, lat)と同じ名前を持っています。
Non-dimension coordinate
dimension とは異なる名前の座標も保持できます。どういう場面でそれが必要・便利になるかは後ほど説明しますが、基本的には 保持されているけど演算されないデータ だと理解すれば良いと思います。
Scalar coordinate
座標軸になりうるスカラーを保持できます。これもよく使うデータタイプですが、ひとまずは Non-dimension coordinate のように演算されないけど保持されているデータだと思っておけば良いと思います。
基本的なメソッド
np.ndarray にある基本的なメソッドを有しています。
-
.shape: 形状を返します -
.size: 合計の大きさを返します -
.ndim: 次元数を返します
そのほか、
-
.sizes: 次元名と大きさの連想配列(辞書型)を返します
型に関するもの
-
.dtype: 配列の型を返します -
.astype(): 配列の型を変更します -
.real: 全データの実部を返します -
.imag: 全データの虚部を返します
DataArrayからnp.ndarrayに変換する。
DataArrayの中には、np.ndarray が収納されています。
(補足ですが、実際はnp.ndarray 以外の多次元配列も格納できます。)
.data とすることで、中身の配列にアクセスできます。
(なお、.values では中身の配列がどんなオブジェクトであれ np.ndarray に変換して返してくれます。)
type(data.data), data.shape
(numpy.ndarray, (2920, 25, 53))
座標軸情報を取り出す
座標軸オブジェクトは、辞書のように[]内に軸名を渡すことで取り出すことができます。
data['lat']
<xarray.DataArray 'lat' (lat: 25)>
array([75. , 72.5, 70. , 67.5, 65. , 62.5, 60. , 57.5, 55. , 52.5, 50. , 47.5,
45. , 42.5, 40. , 37.5, 35. , 32.5, 30. , 27.5, 25. , 22.5, 20. , 17.5,
15. ], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
Attributes:
standard_name: latitude
long_name: Latitude
units: degrees_north
axis: Y取り出したものも DataArray オブジェクトになります。
xarray.Dataset
DataArrayを複数まとめたオブジェクトがDatasetです。
data = xr.tutorial.open_dataset('air_temperature')
data['mean_temperature'] = data['air'].mean('time')
data
<xarray.Dataset>
Dimensions: (lat: 25, lon: 53, time: 2920)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 241.2 242.5 ... 296.19 295.69
mean_temperature (lat, lon) float32 260.37564 260.1826 ... 297.30502
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...この例では、data は air と mean_temperature の2つのDataArrayを保持しています。
それらは Data variables というセクションに書かれています。
-
airは (time,lon,lat) 次元を持つ3次元配列 -
mean_temperatureは (lon,lat) 次元を持つ2次元配列
です。
保持するDataArrayは、座標軸を共有できます。そのため、以下のように複数のDataArrayに対して同時にインデクシングすることが可能です。
data.sel(lat=70, method='nearest')
<xarray.Dataset>
Dimensions: (lon: 53, time: 2920)
Coordinates:
lat float32 70.0
* lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lon) float32 250.0 249.79999 ... 242.59 246.29
mean_temperature (lon) float32 264.7681 264.3271 ... 253.58247 257.71475
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...保持されている DataArray は、異なる次元(Dimension)を持っていてもかまいません。軸が共通かどうかは、軸の名前で判断します。そのため、共通でないけど同じ名前の座標軸をもたせるということはできません。
Datasetから DataArray を取得するには、辞書のようにDataArrayの名前をキーとして渡せばよいです。
da = data['air']
da
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
array([[[241.2 , 242.5 , ..., 235.5 , 238.59999],
[243.79999, 244.5 , ..., 235.29999, 239.29999],
...,
[295.9 , 296.19998, ..., 295.9 , 295.19998],
[296.29 , 296.79 , ..., 296.79 , 296.6 ]],
[[242.09999, 242.7 , ..., 233.59999, 235.79999],
[243.59999, 244.09999, ..., 232.5 , 235.7 ],
...,
[296.19998, 296.69998, ..., 295.5 , 295.1 ],
[296.29 , 297.19998, ..., 296.4 , 296.6 ]],
...,
[[245.79 , 244.79 , ..., 243.98999, 244.79 ],
[249.89 , 249.29 , ..., 242.48999, 244.29 ],
...,
[296.29 , 297.19 , ..., 295.09 , 294.38998],
[297.79 , 298.38998, ..., 295.49 , 295.19 ]],
[[245.09 , 244.29 , ..., 241.48999, 241.79 ],
[249.89 , 249.29 , ..., 240.29 , 241.68999],
...,
[296.09 , 296.88998, ..., 295.69 , 295.19 ],
[297.69 , 298.09 , ..., 296.19 , 295.69 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]DataArray のインスタンス化
ここでは、DataArray オブジェクトを作る方法について説明します。
最も簡単な方法は、np.ndarray とそれぞれの軸名を与える方法です。
xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'])
<xarray.DataArray (x: 3, y: 4)>
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Dimensions without coordinates: x, y上記の例では、3x4 要素を持つ DataArrayを作成しています。1つ目の次元の名前が x で、2つ目の次元が y です。
座標軸を与えるには、coords キーワードに対して辞書型で指定します。
xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'],
coords={'x': [0, 1, 2], 'y': [0.1, 0.2, 0.3, 0.4]})
<xarray.DataArray (x: 3, y: 4)>
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Coordinates:
* x (x) int64 0 1 2
* y (y) float64 0.1 0.2 0.3 0.4non-dimension coordinate を含めるためには、それが依存する軸名を指定しないといけません。そのために、辞書型の引数(コロンの右側)をタプルにします。1つ目の要素が依存する軸名で、2つ目が配列本体です。
xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'],
coords={'x': [0, 1, 2], 'y': [0.1, 0.2, 0.3, 0.4],
'z': ('x', ['a', 'b', 'c'])})
<xarray.DataArray (x: 3, y: 4)>
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Coordinates:
* x (x) int64 0 1 2
* y (y) float64 0.1 0.2 0.3 0.4
z (x) <U1 'a' 'b' 'c'ここで、non-dimension coordinate z は x軸上に定義されたものです。
scalar coordinate も coords に渡します。
xr.DataArray(np.arange(12).reshape(3, 4), dims=['x', 'y'],
coords={'x': [0, 1, 2], 'y': [0.1, 0.2, 0.3, 0.4], 'scalar': 3})
<xarray.DataArray (x: 3, y: 4)>
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Coordinates:
* x (x) int64 0 1 2
* y (y) float64 0.1 0.2 0.3 0.4
scalar int64 3scalar coordinate は、どの次元にも属していないことがわかります。
軸情報の他に、attribute や DataArray の名前も渡すことができます。ただし、attribute は演算の途中で失われてしまうので、まとめてファイルに保存したいものなどを入れる程度にしたほうがよいかもしれません。
このあたりは後で説明する、保存のためのデータ構造の章で説明したいと思います。
インデクシング .isel, .sel, .interp, .reindex
インデクシングは、最も基本的かつ本質的な操作です。それをシンプルにするために xarray の開発がスタートしたと言っても過言ではないと思います。
xarray では、位置ベースインデクシングと座標軸ベースのインデクシングが可能です。
位置ベースインデクシング .isel
これは、np.ndarray などの一般的な配列に対するインデクシングと同様のものです。
data[i,j,k] のようにカギカッコの中に整数を引数として与えます。
引数は、 配列の中の要素の位置 を示すものです。
da[0, :4, 3]
<xarray.DataArray 'air' (lat: 4)>
array([244. , 244.2 , 247.5 , 266.69998], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5
lon float32 207.5
time datetime64[ns] 2013-01-01
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]上記の書き方だと、各次元の位置(例えばtime軸が一番最初の軸で、というようなもの)を覚えておく必要があります。
解析ごとにそれらを覚えておくというのは意外と大変です。以下のような書き方をすると、軸の名前だけを覚えておけばよいことになります
da.isel(time=0, lat=slice(0, 4), lon=3)
<xarray.DataArray 'air' (lat: 4)>
array([244. , 244.2 , 247.5 , 266.69998], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5
lon float32 207.5
time datetime64[ns] 2013-01-01
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]このように、.isel()メソッドの引数にキーワード形式で軸名を入れ、それに対応するインデックスをイコールの後に与えます。
なお、範囲を指定するときは明示的にスライス(slice(0, 4))を使う必要があります。
座標ベースインデクシング .sel
実際のデータ解析では、興味のある範囲は座標で指定されることが多いと思います。xarray では .sel メソッドを用いることで実現できます。
da.sel(time='2013-01-01', lat=slice(75, 60))
<xarray.DataArray 'air' (time: 4, lat: 7, lon: 53)>
array([[[241.2 , 242.5 , ..., 235.5 , 238.59999],
[243.79999, 244.5 , ..., 235.29999, 239.29999],
...,
[272.1 , 270.9 , ..., 275.4 , 274.19998],
[273.69998, 273.6 , ..., 274.19998, 275.1 ]],
[[242.09999, 242.7 , ..., 233.59999, 235.79999],
[243.59999, 244.09999, ..., 232.5 , 235.7 ],
...,
[269.19998, 268.5 , ..., 275.5 , 274.69998],
[272.1 , 272.69998, ..., 275.79 , 276.19998]],
[[242.29999, 242.2 , ..., 236.09999, 238.7 ],
[244.59999, 244.39 , ..., 232. , 235.7 ],
...,
[273. , 273.5 , ..., 275.29 , 274.29 ],
[275.5 , 275.9 , ..., 277.4 , 277.6 ]],
[[241.89 , 241.79999, ..., 235.5 , 237.59999],
[246.29999, 245.29999, ..., 231.5 , 234.5 ],
...,
[273.29 , 272.6 , ..., 277.6 , 276.9 ],
[274.1 , 274. , ..., 279.1 , 279.9 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 62.5 60.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2013-01-01T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ].isel の場合と同様に、キーワードに軸名、イコールの後にほしい座標の値を与えます。
slice オブジェクトも使うことができます。その場合は、sliceの引数に実数を入れればよいです。
ただし、.selメソッドにはいくつか注意点があります。
おおよその座標値を用いたい時
.sel メソッドにはオプション method, tolerance があります。
最もよく使う method は nearest だと思います。これは、最も近い座標値を用いてインデクシングしてくれます。
da.sel(lat=76, method='nearest')
<xarray.DataArray 'air' (time: 2920, lon: 53)>
array([[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 , 238.59999],
[242.09999, 242.7 , 243.09999, ..., 232. , 233.59999, 235.79999],
[242.29999, 242.2 , 242.29999, ..., 234.29999, 236.09999, 238.7 ],
...,
[243.48999, 242.98999, 242.09 , ..., 244.18999, 244.48999, 244.89 ],
[245.79 , 244.79 , 243.48999, ..., 243.29 , 243.98999, 244.79 ],
[245.09 , 244.29 , 243.29 , ..., 241.68999, 241.48999, 241.79 ]],
dtype=float32)
Coordinates:
lat float32 75.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]座標軸ベースのインデクシングが働かない時
座標軸は自由度があるので、うまくインデクシングできない場合があります。例えば以下のようなケースが該当します。
座標軸が単調増加・単調減少でないとき
da.sortby('lat') のようにsortbyメソッドでその軸方向にソートできます。
座標軸に Nan が含まれている時
da.isel(lat=~da['lat'].isnull()) のように、Nan でない座標を返すisnullメソッドを併用することで、その座標値をスキップした配列を作れます
座標軸に重複値があるとき
da.isel(lat=np.unique(da['lat'], return_index=True)[1]) とすると、重複座標に対応する部分をスキップした配列を作れます
補間 .interp
インデクシングと同じようなシンタックスで補間が可能です。
da.interp(lat=74)
<xarray.DataArray 'air' (time: 2920, lon: 53)>
array([[242.23999321, 243.29999998, 243.9799988 , ..., 232.79998779,
235.41999512, 238.87998962],
[242.69999081, 243.25999451, 243.53999329, ..., 231.60000001,
233.1599945 , 235.75999145],
[243.21998903, 243.07599789, 242.97999266, ..., 232.69998783,
234.45999444, 237.49999702],
...,
[245.72999275, 245.38999009, 244.68999648, ..., 242.74999088,
243.20999146, 244.00999451],
[247.42999566, 246.58999336, 245.48999023, ..., 242.4899933 ,
243.38999027, 244.58999329],
[247.00999749, 246.28999329, 245.32999587, ..., 240.84999084,
241.00999144, 241.74999085]])
Coordinates:
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
lat int64 74
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]
条件によるインデクシング xr.where
複雑な条件を満たすデータだけを選びたいときがあります。例えば上記の例だと、
-
timeがある曜日の時だけ選びたい -
airがある値以上のものだけを選びたい
とかです。
選択結果が一次元のとき、例えばある曜日を選択するときなどは、Bool型の一次元配列を.iselメソッドに渡すことで実現できます。
import datetime
# 週末だけを選びます
is_weekend = da['time'].dt.dayofweek.isin([5, 6])
is_weekend
<xarray.DataArray 'dayofweek' (time: 2920)>
array([False, False, False, ..., False, False, False])
Coordinates:
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00# bool型を.isel メソッドに渡します。
da.isel(time=is_weekend)
<xarray.DataArray 'air' (time: 832, lat: 25, lon: 53)>
array([[[248.59999, 246.89 , ..., 245.7 , 246.7 ],
[256.69998, 254.59999, ..., 248. , 250.09999],
...,
[296.69998, 296. , ..., 295. , 294.9 ],
[297. , 296.9 , ..., 296.79 , 296.69998]],
[[245.09999, 243.59999, ..., 249.89 , 251.39 ],
[254. , 251.79999, ..., 247.79999, 250.89 ],
...,
[296.79 , 296.19998, ..., 294.6 , 294.69998],
[297.19998, 296.69998, ..., 296.29 , 296.6 ]],
...,
[[242.39 , 241.79999, ..., 247.59999, 247.29999],
[247.18999, 246.09999, ..., 253.29999, 254.29999],
...,
[294.79 , 295.29 , ..., 297.69998, 297.6 ],
[296.38998, 297.19998, ..., 298.19998, 298.29 ]],
[[249.18999, 248. , ..., 244.09999, 242.5 ],
[254.5 , 253. , ..., 251. , 250.59999],
...,
[294.88998, 295.19998, ..., 298. , 297.29 ],
[296.1 , 296.88998, ..., 298.5 , 298.29 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-05 ... 2014-12-28T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]多次元配列のデータをもとに選択を行いたいとき、選んだ後の配列の形状を定義できないので、選ばない要素をNanで置き換えるとよいでしょう。
そういうときには where 関数が使えます。
da.where(da > 270)
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
array([[[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
...,
[296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 ,
294.69998],
[295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 ,
295.19998],
[296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 ,
296.6 ]],
[[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
...
[293.69 , 293.88998, 295.38998, ..., 295.09 , 294.69 ,
294.29 ],
[296.29 , 297.19 , 297.59 , ..., 295.29 , 295.09 ,
294.38998],
[297.79 , 298.38998, 298.49 , ..., 295.69 , 295.49 ,
295.19 ]],
[[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
[ nan, nan, nan, ..., nan, nan,
nan],
...,
[293.79 , 293.69 , 295.09 , ..., 295.29 , 295.09 ,
294.69 ],
[296.09 , 296.88998, 297.19 , ..., 295.69 , 295.69 ,
295.19 ],
[297.69 , 298.09 , 298.09 , ..., 296.49 , 296.19 ,
295.69 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]ここでは、 da > 270 に当てはまらない要素を np.nan で置き換えています。
発展的なインデクシング
これまで基本的なインデクシングを紹介しましたが、xarray では発展的なインデクシングも可能です。
この図のように、多次元配列の中から別の配列を切り出すことができます。
オフィシャルドキュメントでは Advanced indexingと呼んでいます。
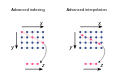
これを実現するためには、引数として渡す配列を DataArrayとして定義します。そのとき、それらの配列の次元を新しく作成する配列の次元にしておきます。
上の図に沿うと、新しい次元は z なので、z 上のDataArrayを定義します。
lon_new = xr.DataArray([60, 61, 62], dims=['z'], coords={'z': ['a', 'b', 'c']})
lat_new = xr.DataArray([16, 46, 76], dims=['z'], coords={'z': ['a', 'b', 'c']})
これらを .selメソッドの引数として渡すと (lon, lat) がそれぞれ [(60, 16), (61, 46), (62, 76)] のもの(に最も近いもの)を選んできてくれます。
da.sel(lon=lon_new, lat=lat_new, method='nearest')
<xarray.DataArray 'air' (time: 2920, z: 3)>
array([[296.29 , 280. , 241.2 ],
[296.29 , 279.19998, 242.09999],
[296.4 , 278.6 , 242.29999],
...,
[298.19 , 279.99 , 243.48999],
[297.79 , 279.69 , 245.79 ],
[297.69 , 279.79 , 245.09 ]], dtype=float32)
Coordinates:
lat (z) float32 15.0 45.0 75.0
lon (z) float32 200.0 200.0 200.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
* z (z) <U1 'a' 'b' 'c'
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]新たに得られた配列は、もはやlon, lat軸には依存していなくて、 z に依存していることがわかります。
また、同様の方法を補間にも用いることができます。
da.interp(lon=lon_new, lat=lat_new)
<xarray.DataArray 'air' (time: 2920, z: 3)>
array([[nan, nan, nan],
[nan, nan, nan],
[nan, nan, nan],
...,
[nan, nan, nan],
[nan, nan, nan],
[nan, nan, nan]])
Coordinates:
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
lon (z) int64 60 61 62
lat (z) int64 16 46 76
* z (z) <U1 'a' 'b' 'c'
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]
データの結合 xr.concat
複数の xarray オブジェクトを結合させたいこともよくあります。
例えば、色々なパラメータで得られた実験データ・シミュレーションデータを合わせて解析したいときとかでしょうか。
これは np.concatenate, np.stack に相当する関数です。
インデクシングの逆操作だと思うとわかりやすいと思います。
シンタックスは
xr.concat([data1, data2, ..., ], dim='dim')
です。
最初の引数として、複数の DataArray (もしくは Dataset)を渡します。
2つ目の引数として、結合の方向を指定します。
結合方向によって、 concatenate 動作と stack 動作に分けられます。
既存の軸を指定する(concatenate動作)
xr.concat関数の基本的な操作は、既存の軸方向に複数の DataArray をつなげることができます。
例えば以下の2つの DataArray
da0 = da.isel(time=slice(0, 10))
da1 = da.isel(time=slice(10, None))
da0
<xarray.DataArray 'air' (time: 10, lat: 25, lon: 53)>
array([[[241.2 , 242.5 , ..., 235.5 , 238.59999],
[243.79999, 244.5 , ..., 235.29999, 239.29999],
...,
[295.9 , 296.19998, ..., 295.9 , 295.19998],
[296.29 , 296.79 , ..., 296.79 , 296.6 ]],
[[242.09999, 242.7 , ..., 233.59999, 235.79999],
[243.59999, 244.09999, ..., 232.5 , 235.7 ],
...,
[296.19998, 296.69998, ..., 295.5 , 295.1 ],
[296.29 , 297.19998, ..., 296.4 , 296.6 ]],
...,
[[244.79999, 244.39 , ..., 242.7 , 244.79999],
[246.7 , 247.09999, ..., 237.79999, 240.2 ],
...,
[297.79 , 297.19998, ..., 296.4 , 295.29 ],
[297.9 , 297.69998, ..., 297.19998, 297. ]],
[[243.89 , 243.79999, ..., 240.29999, 242.59999],
[245.5 , 245.79999, ..., 236.59999, 239. ],
...,
[297.6 , 297. , ..., 295.6 , 295. ],
[298.1 , 297.69998, ..., 296.79 , 297.1 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2013-01-03T06:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]を time方向につなげることで、もとのデータを復元できます。
xr.concat([da0, da1], dim='time')
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)>
array([[[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 ,
238.59999],
[243.79999, 244.5 , 244.7 , ..., 232.79999, 235.29999,
239.29999],
[250. , 249.79999, 248.89 , ..., 233.2 , 236.39 ,
241.7 ],
...,
[296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 ,
294.69998],
[295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 ,
295.19998],
[296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 ,
296.6 ]],
[[242.09999, 242.7 , 243.09999, ..., 232. , 233.59999,
235.79999],
[243.59999, 244.09999, 244.2 , ..., 231. , 232.5 ,
235.7 ],
[253.2 , 252.89 , 252.09999, ..., 230.79999, 233.39 ,
238.5 ],
...
[293.69 , 293.88998, 295.38998, ..., 295.09 , 294.69 ,
294.29 ],
[296.29 , 297.19 , 297.59 , ..., 295.29 , 295.09 ,
294.38998],
[297.79 , 298.38998, 298.49 , ..., 295.69 , 295.49 ,
295.19 ]],
[[245.09 , 244.29 , 243.29 , ..., 241.68999, 241.48999,
241.79 ],
[249.89 , 249.29 , 248.39 , ..., 239.59 , 240.29 ,
241.68999],
[262.99 , 262.19 , 261.38998, ..., 239.89 , 242.59 ,
246.29 ],
...,
[293.79 , 293.69 , 295.09 , ..., 295.29 , 295.09 ,
294.69 ],
[296.09 , 296.88998, 297.19 , ..., 295.69 , 295.69 ,
295.19 ],
[297.69 , 298.09 , 298.09 , ..., 296.49 , 296.19 ,
295.69 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]ここで、 time 軸も同じように復元されていることにも気をつけてください。
新しい軸を指定する (stack 動作)
例えば以下のように2つのDataArrayがあるとします。
da0 = da.isel(time=0)
da1 = da.isel(time=1)
da0
<xarray.DataArray 'air' (lat: 25, lon: 53)>
array([[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 , 238.59999],
[243.79999, 244.5 , 244.7 , ..., 232.79999, 235.29999, 239.29999],
[250. , 249.79999, 248.89 , ..., 233.2 , 236.39 , 241.7 ],
...,
[296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 , 294.69998],
[295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 , 295.19998],
[296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 , 296.6 ]],
dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
time datetime64[ns] 2013-01-01
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]これを、time軸方向に結合するには以下のようにします。
xr.concat([da0, da1], dim='time')
<xarray.DataArray 'air' (time: 2, lat: 25, lon: 53)>
array([[[241.2 , 242.5 , 243.5 , ..., 232.79999, 235.5 ,
238.59999],
[243.79999, 244.5 , 244.7 , ..., 232.79999, 235.29999,
239.29999],
[250. , 249.79999, 248.89 , ..., 233.2 , 236.39 ,
241.7 ],
...,
[296.6 , 296.19998, 296.4 , ..., 295.4 , 295.1 ,
294.69998],
[295.9 , 296.19998, 296.79 , ..., 295.9 , 295.9 ,
295.19998],
[296.29 , 296.79 , 297.1 , ..., 296.9 , 296.79 ,
296.6 ]],
[[242.09999, 242.7 , 243.09999, ..., 232. , 233.59999,
235.79999],
[243.59999, 244.09999, 244.2 , ..., 231. , 232.5 ,
235.7 ],
[253.2 , 252.89 , 252.09999, ..., 230.79999, 233.39 ,
238.5 ],
...,
[296.4 , 295.9 , 296.19998, ..., 295.4 , 295.1 ,
294.79 ],
[296.19998, 296.69998, 296.79 , ..., 295.6 , 295.5 ,
295.1 ],
[296.29 , 297.19998, 297.4 , ..., 296.4 , 296.4 ,
296.6 ]]], dtype=float32)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 2013-01-01T06:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]このように、 da0, da1 に timeという scalar coordinate が存在している場合、その方向につなげることで
(dim='time' というようにdimキーワードに名前を指定することで)、time 軸を新たな座標軸(dimension coordinate)にすることができます。
ほかにも、dimキーワードにDataArrayを与えることで、その名前の座標軸を新しく作ることも可能です。
ファイルIO
xarray のもう一つのメリットは、DataArray や Dataset などのデータを無矛盾・自己完結的に保存できることです。
いくつかファイルフォーマットをサポートしていますが、最も使いやすいのは netCDF でしょう。
Wikipedia にも説明があります。
NetCDFは、コンピュータの機種に依存しないバイナリ形式であり(機種非依存)、データを配列として読み書きすることができ(配列指向)、さらにデータに加えそのデータに関するに関する説明を格納できる(自己記述的)という特徴がある。NetCDFは、オープンな地理情報標準を策定する国際的なコンソーシアムである、Open Geospatial Consortiumにおける国際標準である。
現在、バージョン3と4がメンテナンスされていますが、バージョン4を使っておくほうが無難でしょう。
バージョン4はHDF5の標準に準拠していますので、通常の HDF5 リーダでも内容を読み込むことができます。
なお、正式な拡張子は .nc です。
netCDF 形式でファイルを保存・読み込みをする
netCDF 形式で保存するためには、 パッケージ netcdf4 が必要です。
pip install netcdf4
もしくは
conda install netcdf4
を実行してシステムにインストールしておきましょう。
xarray オブジェクトを netCDF 形式で保存するには、.to_netcdfメソッドを実行します。
data.to_netcdf('test.nc')
/home/keisukefujii/miniconda3/envs/xarray/lib/python3.7/site-packages/ipykernel_launcher.py:1: SerializationWarning: saving variable air with floating point data as an integer dtype without any _FillValue to use for NaNs
"""Entry point for launching an IPython kernel.
これで、現在のパスに test.nc が保存されたと思います。
逆に、保存されたファイルを読み込むためには、 xr.load_dataset を行います。
xr.load_dataset('test.nc')
<xarray.Dataset>
Dimensions: (lat: 25, lon: 53, time: 2920)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 241.2 242.5 ... 296.19 295.69
mean_temperature (lat, lon) float32 260.37564 260.1826 ... 297.30502
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...このように、配列の部分だけでなく、軸の名前、座標の値、 attributes にあるその他の情報まで保存されていることがわかります。
scipy.io.netcdf に関する注意
xarray の .to_netcdf は、デフォルトでは netcdf4 ライブラリを使いますが、システムにインストールされていない場合、 scipy.io.netcdf を使います。 ただし scipy.io.netcdf でサポートされているのはバージョン3で、バージョン4では互換性がないので混乱の元になります。
システムに netcdf4 をインストールするのを忘れないようにしましょう。
もしくは、 .to_netcdf('test.nc', engine='netcdf4') というように、陽に使うパッケージを指定することもできます。
Out-of-memory 配列
netCDF 形式のファイルはランダム読み込みができます。そのため、ファイルのある部分のデータだけを使いたいというようなときは、全てのデータをまずハードディスクから読み込むのではなく、必要なときに読み込むようにすれば効率がよいでしょう。
特に、メモリに格納できないくらい大きなサイズのファイルを扱うときは、そういった処理が本質的に重要になってきます。
これを out-of-memory 処理と呼びます。
xarray における out-of-memory 処理は結構重要な機能と位置づけられていて、様々な実装が進んでいます。
その詳細はまた別の記事で紹介することにして、ここでは最も基本的な内容だけを述べようと思います。
読み込み時に load_dataset ではなく open_dataset をすることで、out-of-memory 処理が行われます。
unloaded_data = xr.open_dataset('test.nc')
unloaded_data
<xarray.Dataset>
Dimensions: (lat: 25, lon: 53, time: 2920)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 ...
mean_temperature (lat, lon) float32 ...
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...Data variables のところを見てもらうと、例えば air のところに数字が入っておらず、単に ... となっていることがわかります。
これはデータが読み込まれていないことを示しています。
ただし座標軸は常に読み込まれるので、上記のインデクシング作業はこのまま可能です。
unloaded_data['air'].sel(lat=60, method='nearest')
<xarray.DataArray 'air' (time: 2920, lon: 53)>
[154760 values with dtype=float32]
Coordinates:
lat float32 60.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ]変数を選んだり、インデクシングしたりしてもまだロードされません。
演算されたり、.data や .values が呼ばれるとメモリに初めてロードされることになります。
明示的にロードするには、.compute() メソッドを使っても良いと思います。
unloaded_data.compute()
<xarray.Dataset>
Dimensions: (lat: 25, lon: 53, time: 2920)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 241.2 242.5 ... 296.19 295.69
mean_temperature (lat, lon) float32 260.37564 260.1826 ... 297.30502
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...注意
open_dataset, open_dataarray では、ファイルをロックし今後の読み込みに備えます。そのため、別のプログラムで同じ名前のファイルを触るとエラーが起こります。
例えば、時間のかかる計算の結果を .nc ファイルとしてその都度出力しているときを考えます。途中経過を見たいと思って open_dataset で開くと、その後そのファイルに書き込もうとすると失敗します。
失敗して止まるだけならましですが、既存のデータを壊してしまうことも多いようです。
この out-of-memory 処理は注意して使う必要があります。
以下のように、 with 文を使うと、確実にファイルを閉じてロックを解除してくれます。
with xr.open_dataset('test.nc') as f:
print(f)
<xarray.Dataset>
Dimensions: (lat: 25, lon: 53, time: 2920)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 ...
mean_temperature (lat, lon) float32 ...
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...
おすすめデータ構造
上記のように、netcdf 形式でデータを保存しておくと xarray でスムースにデータ解析を行うことができます。
実験やシミュレーションなどでデータを作成する時には、その後の解析のことを考えたデータ構造を作っておいて、それを含めた netcdf 形式で保存しておくとよいでしょう。
以下を抑えたデータにしておくことをお勧めします。
- 座標軸データも保存する
- 実験時刻やスキャンするパラメータは、
attributesではなくscalar coordinateとする -
attributesには変化させないもの(実験に使った機器の情報や、データに関する説明文など) を入れるとよいでしょう。
実験の場合、以下のような構造で保存すれば良いと思います。
from datetime import datetime
# これをカメラで撮影した画像データだとします。
raw_data = np.arange(512 * 2048).reshape(512, 2048)
# 画像のx軸・y軸の座標です。
x = np.arange(512)
y = np.arange(2048)
# 画像の各ピクセルに対する位置データ
r = 300.0
X = r * np.cos(x / 512)[:, np.newaxis] + r * np.sin(y / 2048)
Y = r * np.sin(x / 512)[:, np.newaxis] - r * np.cos(y / 2048)
# 実験で使ったパラメータ
p0 = 3.0
p1 = 'normal'
# 実験時刻
now = datetime.now()
data = xr.DataArray(
raw_data, dims=['x', 'y'],
coords={'x': x, 'y': y,
'X': (('x', 'y'), X),
'Y': (('x', 'y'), Y),
'p0': p0, 'p1': p1,
'datetime': now},
attrs={'camera type': 'flash 4',
'about': 'Example of the recommended data structure.'})
data
<xarray.DataArray (x: 512, y: 2048)>
array([[ 0, 1, 2, ..., 2045, 2046, 2047],
[ 2048, 2049, 2050, ..., 4093, 4094, 4095],
[ 4096, 4097, 4098, ..., 6141, 6142, 6143],
...,
[1042432, 1042433, 1042434, ..., 1044477, 1044478, 1044479],
[1044480, 1044481, 1044482, ..., 1046525, 1046526, 1046527],
[1046528, 1046529, 1046530, ..., 1048573, 1048574, 1048575]])
Coordinates:
* x (x) int64 0 1 2 3 4 5 6 7 8 ... 504 505 506 507 508 509 510 511
* y (y) int64 0 1 2 3 4 5 6 7 ... 2041 2042 2043 2044 2045 2046 2047
X (x, y) float64 300.0 300.1 300.3 300.4 ... 414.7 414.8 414.9 414.9
Y (x, y) float64 -300.0 -300.0 -300.0 -300.0 ... 89.66 89.79 89.91
p0 float64 3.0
p1 <U6 'normal'
datetime datetime64[ns] 2020-11-13T03:31:56.219372
Attributes:
camera type: flash 4
about: Example of the recommended data structure.実験中に変わりうるものを scalar coordinate にまとめておくことで、後にそれらに対する依存性を知りたい時にも解析が容易になります。
その他の有用な関数・メソッド
Reduction .sum, .mean, etc
np.sum, np.mean などの reduction 処理はメソッドとして提供されています。
例えば np.sum では、どの軸方向に足し合わせるかを指定できます。xarray では同様に、軸を軸名として指定できます。
data = xr.tutorial.open_dataset('air_temperature')['air']
data.sum('lat')
<xarray.DataArray 'air' (time: 2920, lon: 53)>
array([[6984.9497, 6991.6606, 6991.5303, ..., 6998.77 , 7007.8804,
7016.5605],
[6976.4307, 6988.45 , 6993.2407, ..., 6994.3906, 7006.7505,
7019.941 ],
[6975.2603, 6982.02 , 6988.77 , ..., 6992.0503, 7004.9404,
7020.3506],
...,
[6990.7505, 6998.3496, 7013.3496, ..., 6995.05 , 7008.6504,
7019.4497],
[6984.95 , 6991.6504, 7007.949 , ..., 6994.15 , 7008.55 ,
7020.8506],
[6981.75 , 6983.85 , 6997.0503, ..., 6985.6494, 6999.2495,
7012.0493]], dtype=float32)
Coordinates:
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00このようにある軸方向に足し合わせを行えば、その方向の座標軸がなくなります。
他の座標軸は残っています。
なお、.sum などを実行する場合、デフォルトでは np.sum ではなく np.nansum が呼ばれ、Nanをスキップした計算が行われます。
Nan をスキップしてほしくない場合(np.nansumではなくnp.sumを使いたい場合)は、skipna=False を与える必要があります。
描画 .plot
DataArray には plot メソッドが備わっており、データの内容を簡単に可視化することができます。
data.sel(time='2014-08-30 08:00', method='nearest').plot()
<matplotlib.collections.QuadMesh at 0x7f9a98557310>
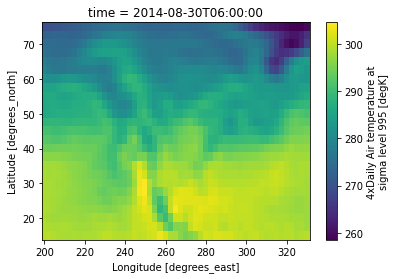
論文・報告の最終的な図を作るためというよりは、簡易的なものと思っておいたほうがよいかもしれませんが、Jupyter や Ipython などでデータを可視化して理解しながら解析を進めるために使うには非常に便利です。