もはや「プロンプト」ではない。これからは「コンテキスト」の時代?!
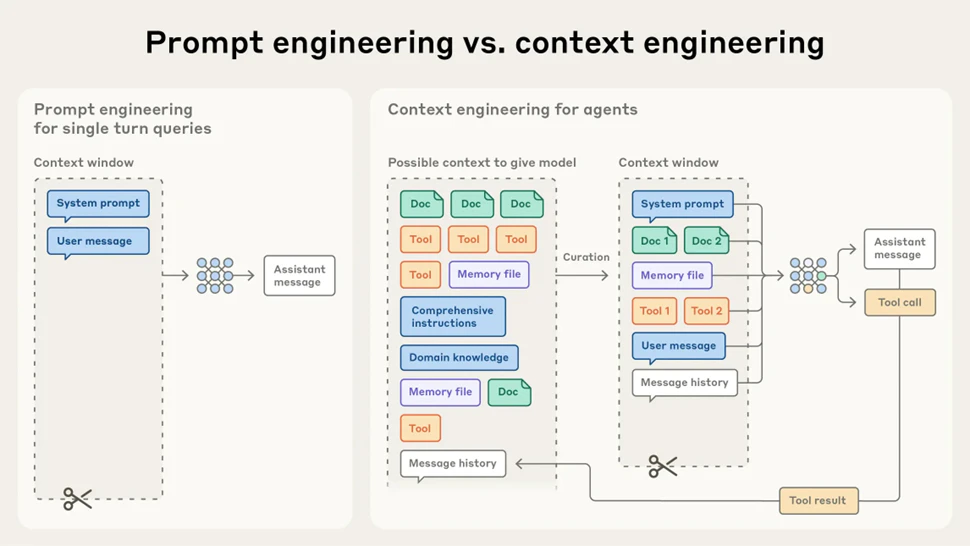
従来の「プロンプトエンジニアリング」が、生成AIに最適な指示文(プロンプト)を作成する技術であったのに対し、「コンテキストエンジニアリング」はより広範な概念です。
それは、システムプロンプト、ツール定義、会話履歴、外部データなど、LLMに渡される「すべての情報(トークン)の最適な組み合わせを設計する」技術を指します。
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents

https://www.philschmid.de/context-engineering
なぜコンテキストエンジニアリングが必要なのか?

そもそもコンテキストは大きいほど良い!は間違い。生成AIにも「注意力の限界」がある
「たくさんの情報を渡せば、生成AIはもっと賢くなる」と考えがちですが、実はこれは間違っており、コンテキストウィンドウに詰め込むほど、生成AIがその中の情報を正確に思い出す能力が低下します。これを 「コンテキストの劣化」 と呼ばれています。
生成AIにも人間と同じように 「注意予算(Attention Budget)=同時に効率的に処理できる情報量には限界がある」 があります。

技術的には、Transformerアーキテクチャの特性に起因します。トークン数が増えるほど、トークン間の関係性の計算量は爆発的に増加し、結果として一つひとつの情報に対する注意が分散してしまうからです。
で、コンテキストエンジニアリングは何をするの?
Anthropicの提言では
「望む結果の可能性を最大化する、最小限の高信号なトークンのセットを見つけること」
簡単にいうと、量より質!
関係ないノイズはそぎ落として、本当に重要な情報のみをLLMに渡すこと

静的アプローチ
■システムプロンプトの最適化
シンプルで、直接的な言葉を使う
「適切な粒度」を見つける ←最小限の高信号なトークン
具体的すぎず、抽象的すぎず
あいまいな指示や、共有コンテキストの仮定を避ける
タグやMarkdownを使い、プロンプトのセクションを分ける
■Few-shot Prompting
Anthropic: 「例は千の言葉に値する」
ジャンルは違うけど、典型的なパターン
細かいケースを列挙はNG
「最小限」は「短い」という意味ではない
左の曖昧で短い指示だと、生成AIは何をどう記録すれば良いか分からず、推測に頼らざるを得ないため動作が不安定になります。右は左より長いですが、生成AIが安定してタスクを遂行するために必要な情報がすべて含まれており、自己完結しているため、生成AIが推測する必要性がなくなります。

動的アプローチ:必要な情報はその場で探がす「Just-in-Time検索」という新発想
どうすれば「注意予算(Attention Budget) 」を無駄にせず、必要な情報だけを与えられかという方法が、「Just-in-Time」アプローチです。これは、関連する可能性のある全データを事前に渡すのではなく、AIエージェント自身が必要になったタイミングで、情報を動的に取得させる方法です。

長時間タスク時のアプローチ
数時間に及ぶような大規模なタスクでは、コンテキストウィンドウのサイズ制限を乗り越えるための特別な技術が必要になります。
Anthropic社は、そのための主要な戦略として以下の3つを挙げています。
・圧縮 (Compaction)
長くなった会話履歴の要点をモデル自身に要約させ、新しいコンテキストで作業を継続させる手法
・構造化ノート (Structured note-taking)
作業中に重要な発見や決定事項を、外部のファイルにメモとして書き出し、後で参照する手法
・マルチエージェント (Multi-agent architectures)
1つのエージェントに処理させるのではく、特化型の複数サブエージェントに分割して処理させる手法
コンテキストエンジニアリングのまとめ
コンテキストエンジニアリングの本質は、生成AIに与える 「コンテキストを貴重で有限なリソースとして扱い、生成AIのアテンションを最も価値のある情報に集中させること」 にあります。
今後、生成AIの構築に必要になってくるナレッジは、「プロンプトエンジニアリング」から「コンテキストエンジニアリング」へと変化するに可能性が高いと考えられます。
また、生成AIの性能がどれだけ向上しても、「情報を厳選する」 というこの原則の重要性はきっと変わらないはずです。むしろ、生成AIがより自律的に動作するようになるほど、この原則は生成AI活用の信頼性と効果を左右する、永続的な設計原則として、コンテキストエンジニアリングはさらに中心的なナレッジとなるかもしれません。

でも、要約するとコンテキストエンジニアリングって、結局、機械学習(ML)と同じ
データマネジメント(DMBOK)
が重要って、ことなのでは?