動機
絶賛ダイエット中の筆者。そんな時、考えるのは「限界までお寿司を食べたい!」ということ。
ということで、ダイエット中でどれだけどんなお寿司を食べられるのかを最適化してみました!
使用データ
今回は、PFCバランス(タンパク質、脂質、炭水化物の比率)も考慮に入れたいため、
PFCの値まで公開してくださっている活美登利さんのこちらのデータを使用します。
※ PDFは、katsumidori_pfc.pdf という名前でダウンロードした前提で下記を進めていきます。
ソルバー選択
Pythonの最適化ライブラリ PuLPを使用します。
データ成形
今回しようするデータはPDFデータとなっています。
PDFデータからpandas DataFrameを作成したい場合、取れる選択肢は下記のようになっています(他の選択肢もあるかと思います)。
- tabula-py を使用する
pip install camelot-pyを実行し、下記のようにしてファイルを読み込むfrom tabula.io import read_pdf tables = read_pdf("katsumidori_pfc.pdf", pages='all') - camelot を使用する
pip install camelot-py[cv]を実行
ghostscriptをダウンロードしてインストール
下記のようにしてファイルを読み込むfrom camelot.io import read_pdf tables = read_pdf("katsumidori_pfc.pdf") - fitz を使用する
下記のようにしてファイルを読み込むimport fitz doc = fitz.open('katsumidori_pfc.pdf')
今回は、「fitz を使用する」を選択し、下記のようにデータを成形しました。
【データ成形コード】
import fitz
import pandas as pd
import numpy as np
filename = 'katsumidori_pfc.pdf'
doc = fitz.open(filename)
Cols = ['menu_no'
,'item_name'
,'calorie'
,'protein'
,'fat'
,'carbo'
,'water_content'
,'na'
,'salt']
FloatCols= ['calorie', 'protein', 'fat', 'carbo' ,'water_content', 'na','salt']
PageDfms = []
for page in range(len(doc)):
text = doc[page].get_text()
text = text.rstrip('\n').replace('\n', ' ')
if page == 0:
text = text.replace('にぎり寿司 ', '')
# text = text.replace(' '.join(columns)) ではreplaceされないため、ベタ打ちで対応
text = text.replace("メニュー番号 品名 エネルギー〔kcal〕 たんぱく質〔g〕 脂質〔g〕 炭水化物〔g〕 含水率〔%〕 ナトリウム[mg] 塩分〔g〕 ", '')
# アボカドシュリンプ巻(クレープ一貫) には、品名とエネルギーの間に空白がないため追加
text = text.replace("アボカドシュリンプ巻(クレープ一貫)","アボカドシュリンプ巻(クレープ一貫) ")
array = text.split(' ')
print('=== page:', page, len(array), '===')
c_num = len(Cols)
r_num = int(len(array) / c_num)
array2 = np.array(array).reshape(r_num, c_num)
print('shape:', array2.shape)
page_dfm = pd.DataFrame(array2, columns=Cols)
PageDfms.append(page_dfm)
sushi_df = pd.concat(PageDfms)
for l in FloatCols:
sushi_df[l] = sushi_df[l].astype(float)
print('---dtypes---')
print(sushi_df.dtypes)
print('---shape---')
print(sushi_df.shape)
ログはこちら
=== page: 0 288 ===
shape: (32, 9)
=== page: 1 297 ===
shape: (33, 9)
=== page: 2 297 ===
shape: (33, 9)
=== page: 3 297 ===
shape: (33, 9)
=== page: 4 270 ===
shape: (30, 9)
---dtypes---
menu_no object
item_name object
calorie float64
protein float64
fat float64
carbo float64
water_content float64
na float64
salt float64
dtype: object
---shape---
(161, 9)
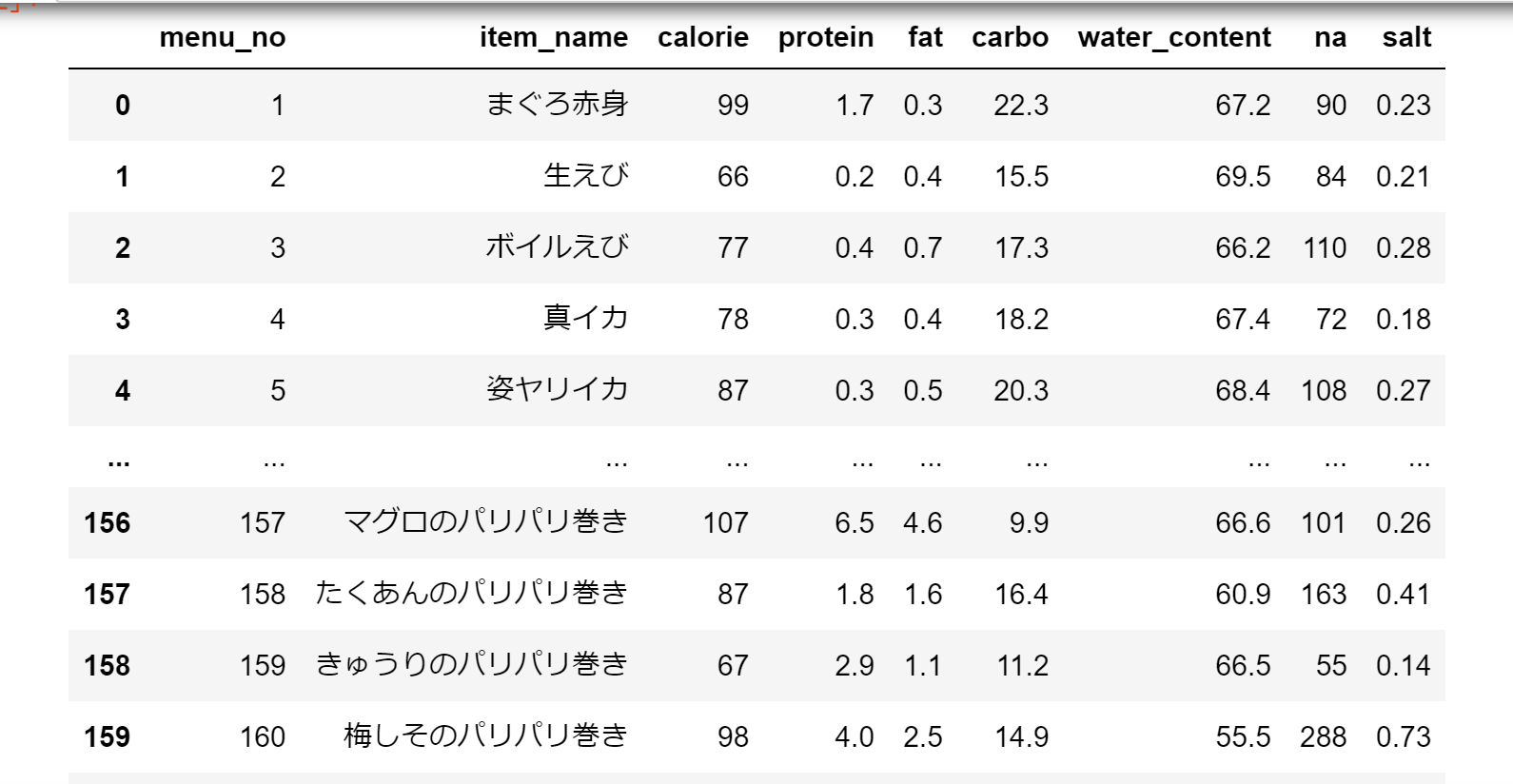
sushi_df の中身はこちらになります。
ここで、カロリーの値が正しいかどうかを下記で調べてみます。
# タンパク質、炭水化物は 4kcal/g、脂質は 9kcal/g
sushi_df['calculated_calorie'] = sushi_df['calorie'] - ((sushi_df['protein']+sushi_df['carbo'])*4 + sushi_df
['fat']*9)
# 計算値との誤差が1.oよりも多いものを抽出
sushi_df[sushi_df['calculated_calorie'].abs() > 1.0]
明らかに、しらす軍艦の値がおかしいことがわかりました。
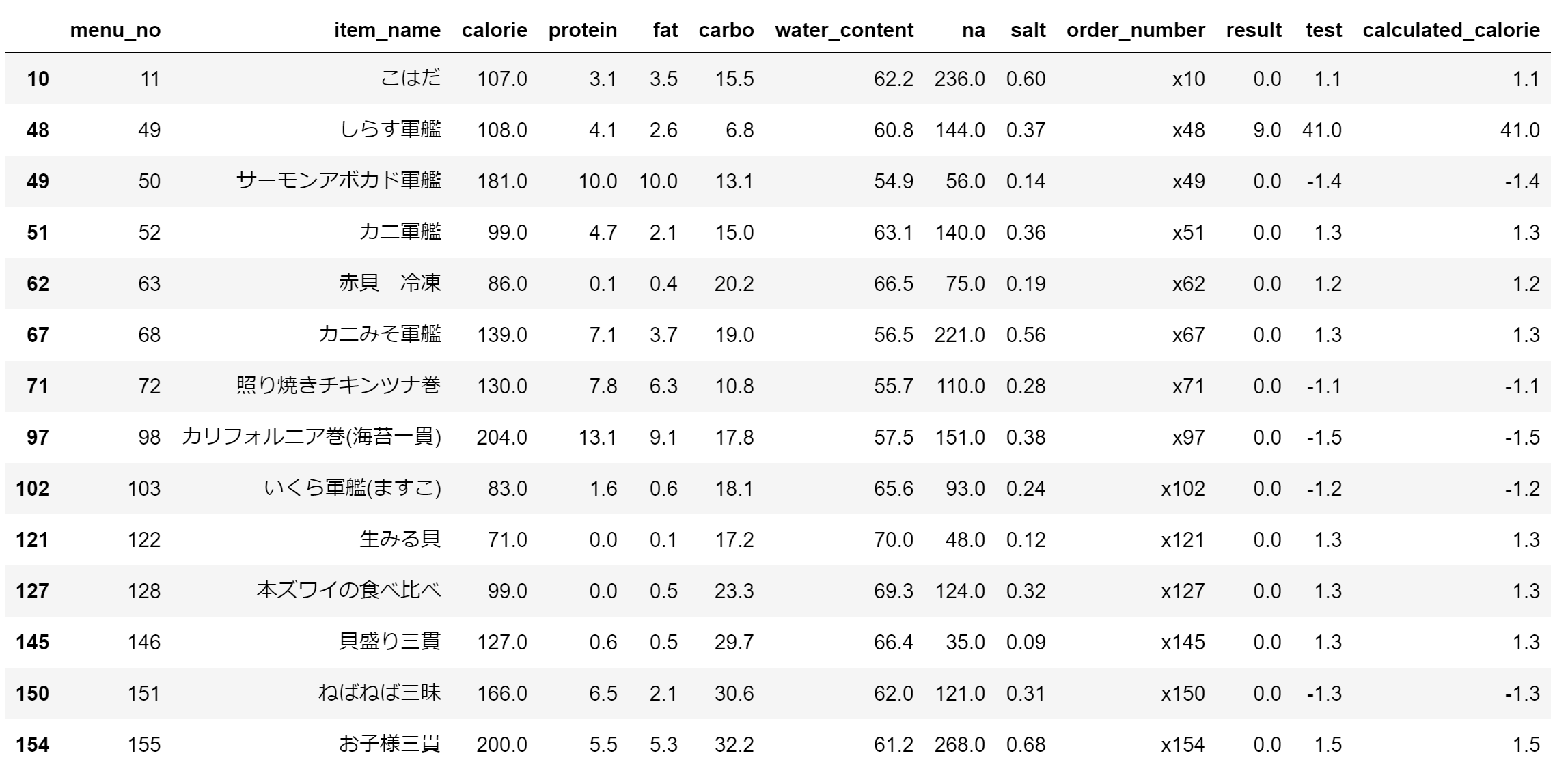
下記コードを追加して、しらす軍艦のカロリーの値を変更します。
sushi_df.loc[48,'calorie'] = (sushi_df.loc[48,'protein']+sushi_df.loc[48,'carbo'])*4 + sushi_df.loc[48,'fat']*9
コーディング
下記のような数字設定で1日の食事を管理している筆者は、同じような制約条件でモデルを設定します。
- 脂質は30g以下
- タンパク質は100g以上120g以下
※下記2のモデルでは実行不可能Infeasibleのステータスとなってしまったので、
タンパク質は80g以上120g以下の条件に変更しています。 - 炭水化物は180g以下
また、気分に応じてモデルを選択できるように下記3つのモデルを定義しています。
- 同じネタでもいいから、とにかく多くの皿数を食べたい時
- とにかく多くのカロリーを摂取したい時
- バラエティーの富んだネタを食べたい時
① 同じネタでもいいから、とにかく多くの皿数を食べたい時
import pulp
# 数理モデルのインスタンス作成
prob = pulp.LpProblem('WantToEatSushi', pulp.LpMaximize)
# 変数を定義
sushi_df['order_number'] = [pulp.LpVariable(f'x{i}',lowBound=0, cat='Integer') for i in sushi_df.index]
# 脂質は30g以下
prob += pulp.lpDot(sushi_df['fat'], sushi_df['order_number']) <= 30
# タンパク質は100g以上120g以下
prob += pulp.lpDot(sushi_df['protein'], sushi_df['order_number']) >= 100
prob += pulp.lpDot(sushi_df['protein'], sushi_df['order_number']) <= 120
# 炭水化物は180g以下
prob += pulp.lpDot(sushi_df['carbo'], sushi_df['order_number']) <= 180
# 皿数を最大化させる
prob += pulp.lpSum(sushi_df['order_number'])
② とにかく多くのカロリーを摂取したい時
import pulp
# 数理モデルのインスタンス作成
prob = pulp.LpProblem('WantToEatSushi', pulp.LpMaximize)
# 変数を定義
sushi_df['order_number'] = [pulp.LpVariable(f'x{i}',lowBound=0, cat='Integer') for i in sushi_df.index]
# 脂質は30g以下
prob += pulp.lpDot(sushi_df['fat'], sushi_df['order_number']) <= 30
# タンパク質は100g以上120g以下
prob += pulp.lpDot(sushi_df['protein'], sushi_df['order_number']) >= 100
prob += pulp.lpDot(sushi_df['protein'], sushi_df['order_number']) <= 120
# 炭水化物は180g以下
prob += pulp.lpDot(sushi_df['carbo'], sushi_df['order_number']) <= 180
# 総カロリーを最大化させる
prob += pulp.lpDot(sushi_df['calorie'], sushi_df['order_number'])
③ バラエティーの富んだネタを食べたい時
import pulp
# 数理モデルのインスタンス作成
prob = pulp.LpProblem('WantToEatSushi', pulp.LpMaximize)
# 変数を定義
sushi_df['order_number'] = [pulp.LpVariable(f'x{i}',lowBound=0, cat='Binary') for i in sushi_df.index]
# 脂質は30g以下
prob += pulp.lpDot(sushi_df['fat'], sushi_df['order_number']) <= 30
# タンパク質は80g以上120g以下
prob += pulp.lpDot(sushi_df['protein'], sushi_df['order_number']) >= 80
prob += pulp.lpDot(sushi_df['protein'], sushi_df['order_number']) <= 120
# 炭水化物は180g以下
prob += pulp.lpDot(sushi_df['carbo'], sushi_df['order_number']) <= 180
# 総カロリーを最大化させる
prob += pulp.lpDot(sushi_df['calorie'], sushi_df['order_number'])
最適化結果
モデル1~3のいずれかを選択した後、下記のコードを追加します。
status = prob.solve()
# Optimal が表示されれば最適化成功
print(pulp.LpStatus[status])
sushi_df['result'] = sushi_df['order_number'].apply(lambda x: pulp.value(x))
eating_sushi_df = sushi_df[sushi_df['result'] != 0]
sum_calorie = (eating_sushi_df['calorie']*eating_sushi_df['result']).sum()
sum_protein = (eating_sushi_df['protein']*eating_sushi_df['result']).sum()
sum_fat = (eating_sushi_df['fat']*eating_sushi_df['result']).sum()
sum_carbo = (eating_sushi_df['carbo']*eating_sushi_df['result']).sum()
print(f'最適化結果:総カロリー{sum_calorie}kcal,タンパク質{sum_protein}g, 脂質{sum_fat}g, 炭水化物{sum_carbo}g')
【結果】
① 同じネタでもいいから、とにかく多くの皿数を食べたい時

最適化結果:総カロリー1380.0kcal,タンパク質100.4g, 脂質28.800000000000004g, 炭水化物180.0g
② とにかく多くのカロリーを摂取したい時

最適化結果:総カロリー1429.0kcal,タンパク質109.60000000000001g, 脂質30.0g, 炭水化物180.0g
③ バラエティーの富んだネタを食べたい時
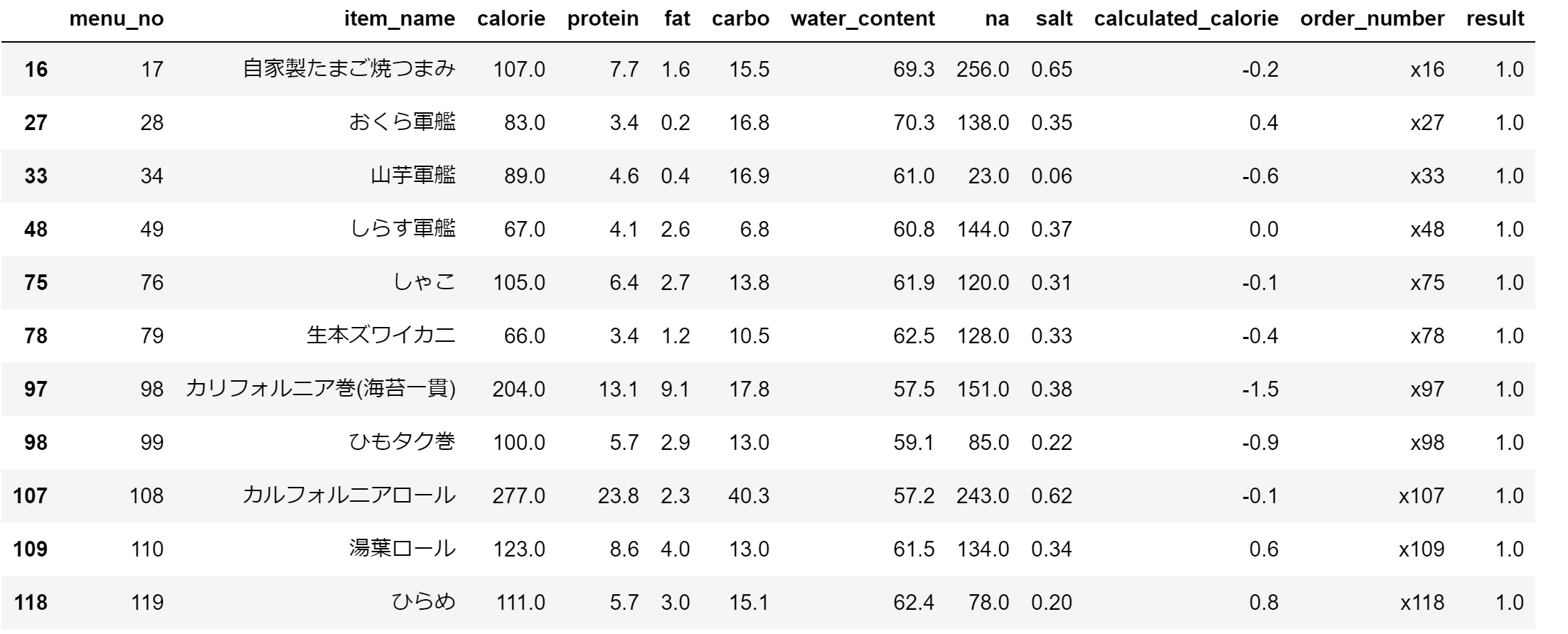
最適化結果:総カロリー1332.0kcal,タンパク質86.5g, 脂質30.0g, 炭水化物179.49999999999997g
所感
お寿司は炭水化物が多い印象だったので、PFCのバランスよくするのは難しいのかな、と思っていましたが、
① 同じネタでもいいから、とにかく多くの皿数を食べたい時
② とにかく多くのカロリーを摂取したい時
の場合では、タンパク質100g以上になりつつ炭水化物は抑えられていたのが驚きでした。
これを参考にお寿司を楽しみたいと思いますが、
正直なところ最適化の結果の中には好きなネタがあまりないので、
次は「好きなネタ」はできるだけ入れるように最適化モデルを作っていけたらいいな、と思います。
また、お寿司最適化のWebアプリケーションも作っていけたらなと思います。