にじさんじの配信者間で"似ている"配信者はどういう人たちか
唐突ですが、一週間前は文化の日でしたね。せっかくだったので、文化らしいことをしたいなと思い、youtube data apiを使って遊んでみることにしました。
youtube のデータを使ってなにかしよう、となったとき、他の人はどういう分析をするんでしょうか。最近よくみるデータとしてはスパチャランキング・登録者数推移の予測などが思い当たります。
そしてまた唐突に語り始めるのですが、僕はvtuberの配信をラジオ代わりに流していることが多く、いわゆるvtuberのオタクです。オタクのあり方には諸説ありますが、僕はラジオ代わりということもあり雑談配信やマイクラ配信を流していることが多いです。「にじさんじ」の配信を見ることが多い気がします。
さて、「にじさんじ」は言わずとしれた大所帯グループです。約100人の配信者が一つの箱に所属しています。これだけたくさんいると(大体は見ているのですが)全然追っていない人が実は自分の好きなタイプの配信をしていることがあるわけです。なんならチャンネル登録していても単純に物量が多いので、youtubeからの通知がないと後でtwitterで気づいたりとかもままあります。
自分の好きなタイプの配信をよくやっている配信者と、似ている配信者を知りたい。まあどちらかといえば新しく沼に入ってきた人のためのものな気はしますが、しばらく見ている人にとっても有用でしょう。たぶん。
というわけで今回は、youtube data apiから取得できるデータを使って、配信者間の類似性について分析をしたいと思います。
TL;DR;
- にじさんじの配信者による直近30動画(アーカイブ)のチャットデータを収集。チャットデータから配信者をノードとしたグラフを作成した
- 作ったグラフをモジュラリティクラスタリングするとなかなか綺麗に分かれたので、配信者の類似性はチャットユーザの共通性からある程度測れそうということがわかった
- ついでに、作成したグラフからPageRank(あるノードの重要性を示す指標)を計算してチャンネル登録者数と相関しているか、このグラフにおけるPageRankは何を示すものなのか考察した
類似性の分析をするための案を練る
さて、どんなデータを使って類似性を分析しましょうか。といっても、youtube から得られるデータだけで考えるとそれほど選択肢は多くはありません。今回選ばなかった選択肢を書き出してみたのが以下です。
- 動画から...動画の映像・音声データを用いて、ある動画と動画の類似度を出すモデルを作る。その後、各動画の類似度を出したあとにそれを配信者ごとに集計すれば配信者同士の類似度が得られる。が、計算しないといけない動画のペアが当然多いので、サクッとやる分析には向かない(動画データにはできるだけ触れたくない)
- タイトル・動画概要のテキストデータから...動画データではなくタイトル・概要欄のテキストデータから類似度を出す案もある。が、タイトル・概要欄だけではその配信がどういう配信なのか分かることはあまり多くはない
いずれもコンテンツベースで類似度を出す方法を書いているわけですが、動画データはしんどい・動画のメタ情報は不十分なことが多い、と一番要である動画データから攻めるのは少し筋が悪そうです。
また、コンテンツベースで類似度を出すよりも、そのアイテムにアクションを起こしたユーザのデータ: 行動データを用いた協調フィルタリングっぽいやり方のほうが単純で簡単です。
しかし、youtube上である動画にアクションしたユーザの情報が取れそうなところって全然ないんですよね。大体のユーザは自分が高評価した動画リストを公開していませんし、どの配信者のチャンネルを登録しているかも分かりません。プライバシーですから、当然の仕様ですね。しょうがない。
まあ、というわけで今回は別の方法を取ります。どういう方法かというと、配信アーカイブのチャットデータを使います。
チャットデータからはどのようなユーザがチャットを行ったかが取得できます。つまり、対象とする配信者全員の動画に対してチャットデータ取得を行うと、配信者Aでチャットしたユーザと、配信者Bでチャットしたユーザがわかることになりますね。では仮に、両チャットに同一人物(ユーザa)がいた場合、配信者Aと配信者Bには何かしらの共通して推せる点があったのでユーザaはどちらでもチャットしたのだと考えられます。

配信者Aと配信者Bをネットワークグラフのノードと考えると、AとBには一本エッジが張れそうな気配が出てきました。というわけで、このネットワークグラフを実際に作り、グラフ分析をすることにしましょう。
以降の章ではデータ取得から記述しています。分析結果から確認される方はこちらからどうぞ。
データを実際に集める
ここでは必要なデータを如何にして集めたかについて書きます。省略なしのコードはこちらのリポジトリにあります。https://github.com/fufufukakaka/2434_comment_user_graph
にじさんじの配信者のチャンネルIDを取得する
チャットデータを取得するためには動画IDが必要です。配信者ごとの動画IDを取得するためにはチャンネルIDが必要なのでそれを取得していきます。チャンネルURLがわかればそこから取れるので、「いつからlink」の一覧ページからURLを取り出します。
target_url = "https://www.itsukaralink.jp/livers"
def get_channel_ids():
options = Options()
options.set_headless(True)
driver = webdriver.Chrome(chrome_options=options)
driver.get(target_url)
soup = BeautifulSoup(driver.page_source.encode("utf-8"), "html.parser")
# 最後はにじさんじ公式のため除く
streamer_names = [
v.text for v in soup.find_all("span", attrs={"class": "liver-followBoxText"})
][:-1]
channel_URL = [
v.a["href"].split("?")[0]
for v in soup.find_all("div", attrs={"class": "liver-linkImage"})
if "youtube" in v.a["href"]
][:-1]
config_json = {}
for name, url in zip(streamer_names, channel_URL):
config_json[name] = url
with open("config/2434_streamer_channel_IDs.json", "w") as f:
json.dump(config_json, f, ensure_ascii=False, indent=2)
チャンネルIDを基準にして動画ID・メタデータを取得する
取得したチャンネルIDを使って、youtube data apiに問い合わせていきます。
API_KEYは事前に発行しておきます(このへんを見るなど https://developers.google.com/youtube/v3/getting-started)。
そして、youtube data apiを使う上で気にしないといけないのがquotaです。一日に使えるquotaは10000までと決まっており、1動画の情報を取得すると1quotaを消費するので(正確に測っていないので曖昧です)、1日に10000件までしか動画情報を取得できません😭
にじさんじは100人程度いるので、一人あたり100件を取得できることになります。全員の全動画を取得しようとするとこの制限を余裕で超えてしまうので、今回は直近50件の動画を対象とすることにしました。大体2020年の9月~10月が対象になります。
def get_video_data():
API_KEY = os.environ["API_KEY"]
base_url = "https://www.googleapis.com/youtube/v3"
with open("config/2434_streamer_channel_IDs.json", "r") as f:
channel_ID_config = json.load(f)
for streamer_name, channel_URL in channel_ID_config.items():
if os.path.exists(f"video_list_output/{streamer_name}_videos.csv"):
print(f"already exists: {streamer_name}")
continue
print(f"now processing...{streamer_name}")
CHANNEL_ID = channel_URL.split("/")[-1]
url = (
base_url
+ "/search?key=%s&channelId=%s&part=snippet,id&order=date&maxResults=50"
)
infos = []
# quotaを節約するために最新50件のみ取得する
time.sleep(10)
response = requests.get(url % (API_KEY, CHANNEL_ID))
if response.status_code != 200:
print("exit by error")
continue
result = response.json()
infos.extend(
[
[
streamer_name,
item["id"]["videoId"],
item["snippet"]["title"],
item["snippet"]["description"],
item["snippet"]["publishedAt"],
]
for item in result["items"]
if item["id"]["kind"] == "youtube#video"
]
)
if "nextPageToken" in result.keys():
if "pageToken" in url:
url = url.split("&pageToken")[0]
url += f'&pageToken={result["nextPageToken"]}'
else:
print("success")
videos = pd.DataFrame(
infos,
columns=["streamer_name", "videoId", "title", "description", "publishedAt"],
)
videos.to_csv(f"video_list_output/{streamer_name}_videos.csv", index=None)
動画IDからチャットデータを取得する
さて、今回の一番欲しいデータであるチャットデータをようやく取得できそうです。で、ここもyoutube data apiか...quota大丈夫かな、と思いつつ調べてみたのですが、youtube data apiではアーカイブ配信のチャットデータ(リプレイ)は直接取得できるところはないようです😭
(refs. https://note.com/or_ele/n/n5fc139ff3f06)
スクレイピングをして取るしかないということですね。自分で一から書いてもいいのですが、既にまとめてくださっているものがあるので、今回はそれを使いました。(version 0.4.7で動作確認)
https://github.com/taizan-hokuto/pytchat
save_path = f"comment_list_output/{video_id}.csv"
if os.path.exists(save_path):
print(f"already exists: {video_id}")
continue
archiver = TSVArchiver(save_path)
# Extractorの生成
ex = Extractor(video_id, div=10, callback=disp, processor=archiver)
# 抽出
info = VideoInfo(video_id)
if info.get_duration() == 0:
print("指定した動画はアーカイブされていないか、チャットデータが存在しません")
print(f"Extracting: {info.get_title()}")
ex.extract()
video_idを渡して、その動画のチャットデータが存在するのであれば ex.extract で抽出することができます。抽出した後、データから必要な情報だけ取り出しておきます。
video_id, chat_author, comment
iyeTOzYHTuE, hogehoge, コメント
...
これでグラフを作るための前準備はだいたい完了!ちなみにここに来るまでに時間のかかった順でいうと
コメントデータ取得(5時間くらい?)→動画メタデータ取得(2時間くらい)→チャンネルID取得(30秒程度)
勘の良い方はおわかりかと思いますが、既に思いついてよしやるか!の範疇は超えていますね。文化の日はデータ取得だけで終わりました。
グラフを作る
チャットデータまでできたところから、ようやく作りたかったグラフ構築に入れます。配信者Aの配信でチャットにコメントしたユーザが、他の配信者のところでコメントしたかどうかを見ていきます。
def get_combination(streamers, all_chat_users, chat_user):
_chated_streamers = []
for streamer, chat_users in zip(streamers, all_chat_users):
if chat_user in chat_users:
_chated_streamers.append(streamer)
# コメントしたstreamerのリストをcombinationして組み合わせをすべて出す
combinations = list(itertools.combinations(_chated_streamers, 2))
return combinations
def main():
# 配信者ごとにチャットしたユーザ一覧を予め作っておく
streamer_unique_chat_authors = pd.read_csv(
"streamer_unique_chat_authors.csv",
converters={"unique_chat_authors": ast.literal_eval},
)
# 辞書にしたほうがやりやすかったので辞書化
streamer2chat_users = streamer_unique_chat_authors.set_index("streamer_name")[
"unique_chat_authors"
].to_dict()
streamers = list(streamer2chat_users.keys())
# チャットしたユーザの全一覧を作る
unique_chat_users = list(
set(sum(streamer_unique_chat_authors["unique_chat_authors"].tolist(), []))
)
all_chat_users = [set(v) for v in streamer2chat_users.values()]
edge_list = []
for chat_user in tqdm(unique_chat_users):
# あるユーザがどの配信者にコメントしたかの組み合わせをつくる
combinations = get_combination(streamers, all_chat_users, chat_user)
# エッジのリストとする
for combi in combinations:
# source, target, edge_name
edge = [combi[0], combi[1], chat_user]
edge_list.append(edge)
edge_df = pd.DataFrame(edge_list, columns=["source", "target", "edge_name"])
edge_df.to_csv("streamer_chat_user_edge_df.csv", index=None)
これでエッジのリストができました。今回はそのエッジを張ったユーザではなく配信者が興味の対象なので、配信者ごとにエッジをまとめて、エッジが何本あったかを基準にエッジの重みとします。
作ったグラフを眺める
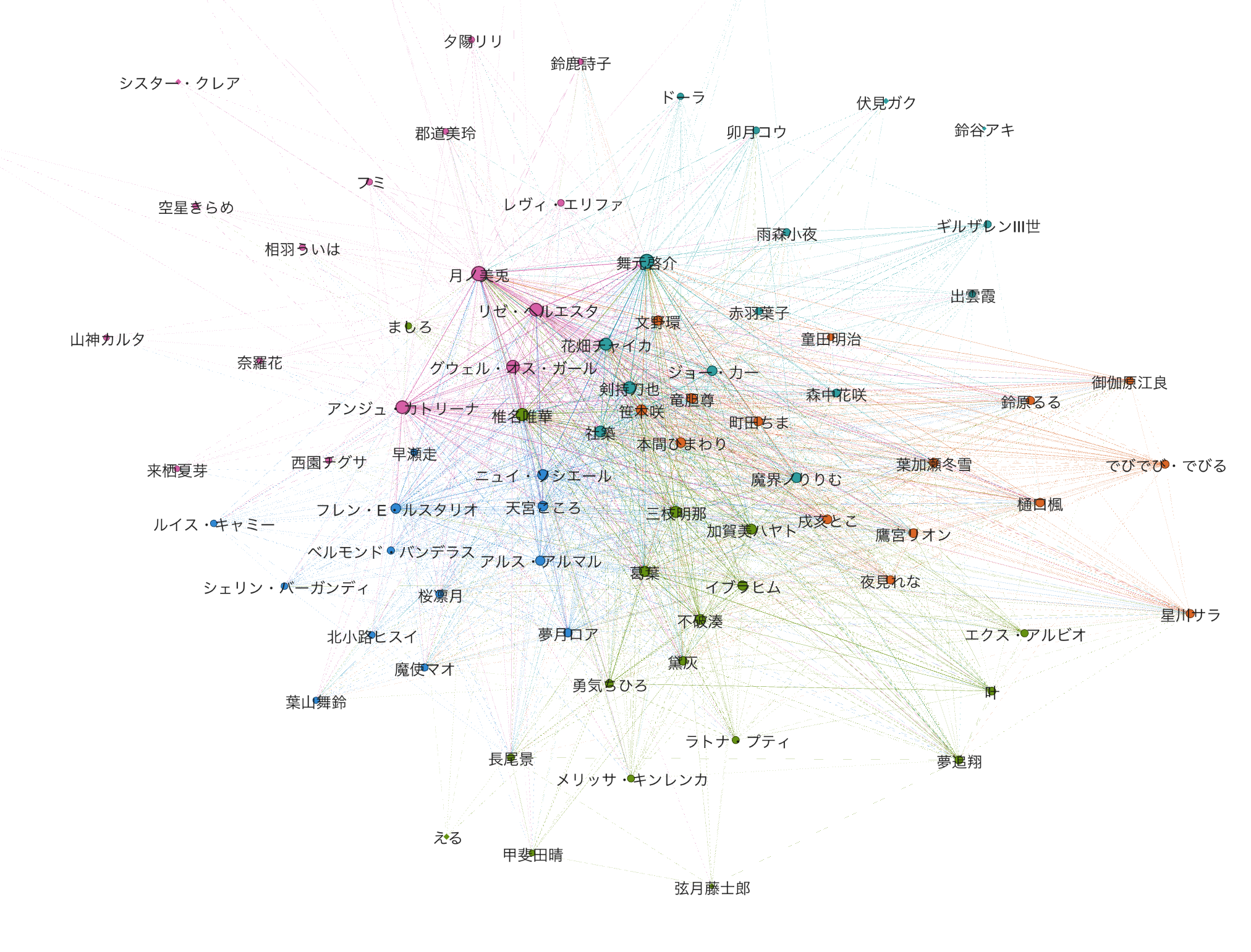
ではこのエッジリストを使ってグラフを可視化してみましょう。可視化にはGephi(https://gephi.org)を用いています。また可視化する際、エッジの重みが一定以下のものは可視化していません。
仮にこの制限無しで可視化すると、全員の配信者が自分以外の配信者と必ずエッジが結ばれる完全グラフになり、可視化してレイアウトアルゴリズムでバラけさせることができず、面白みにかけちゃうので...
また、登場していない配信者が何人かいます。これは直近30動画を見た際に、他の配信者とのエッジの重みが小さく、上述した理由でどこともエッジを張れなかったケースとなります。また単純にミスってる可能性もあります。ご容赦ください。
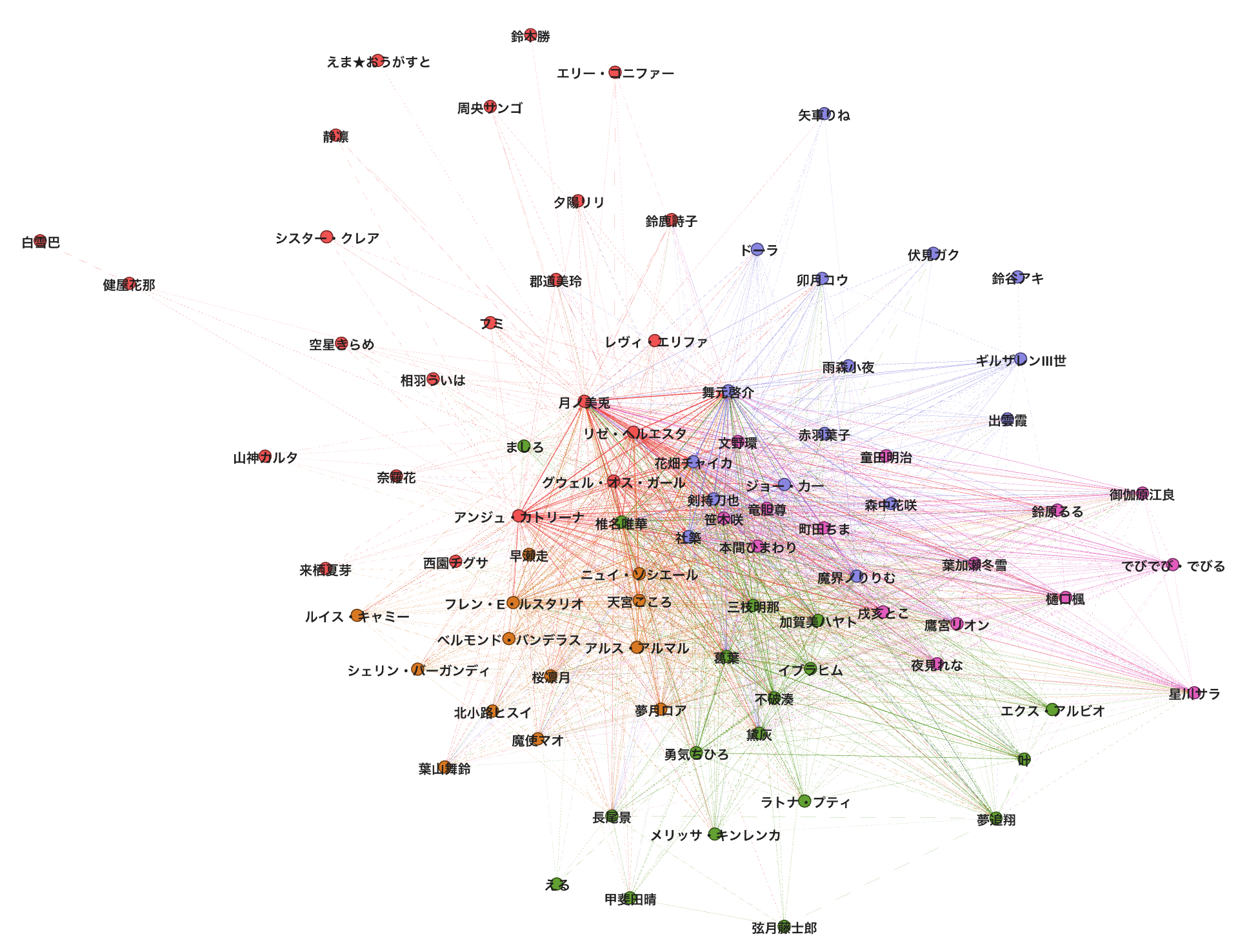
色が濃いほど、その配信者間で同じユーザがコメントしたことを表しています。また、各配信者のノードの色はモジュラリティクラスタリングの結果を元にしています。中央の方はノードが集まりすぎて、誰を表しているのかどうしてもわかりにくくなってしまいますね...
さて、可視化したグラフを眺めていくつかの仮説を確かめてみたいと思います。
またここから幾度か配信者の名前に言及する部分がありますが、敬称は略させていただいております。
クラスタの中に共通項は見いだせるか
モジュラリティクラスタリングは、コミュニティを見つけるための手法です。ざっくりいえば、密接に繋がり合っているノード群が同じクラスタになりやすいです。今回は5つのクラスタに分けましたが、これら5つのクラスタ内でなにか共通項は見いだせるでしょうか。
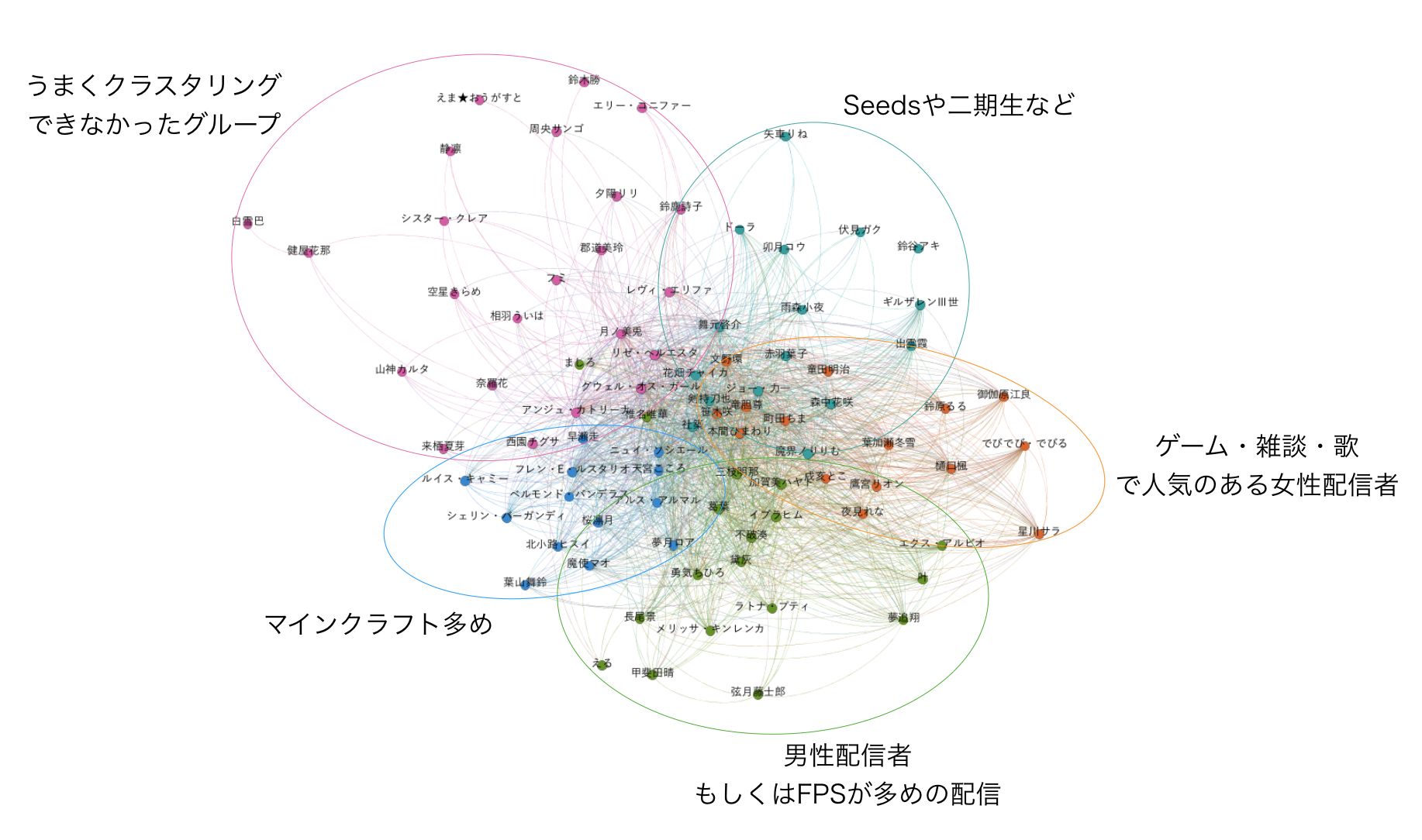
ということで、各クラスタに注釈をつけてみました。
- seedsや二期生が多いクラスタ(暗めの青色)
- 歌や雑談・ゲームなどで人気のあるかわいい雰囲気の配信者クラスタ(オレンジ色)
- FPSなど硬派なゲームの配信が多いクラスタ(緑色)
- マインクラフト配信が多めのクラスタ(青色)
- 今回のクラスタリングではうまく分けられなかったクラスタ(ピンク色)
ざっとこのような感じに落ち着いたようです。
クラスタリングというのはどうしてもうまく解釈できないクラスタが一つは出てしまうので、ピンク色のクラスタについては残念でした。 月ノ美兎氏, リゼ・ヘルエスタ氏, アンジュ・カトリーナ氏, 静凛氏など、チャットユーザに特色の出そうな配信者もこのクラスタの中に散見されており、クラスタの数を増やしてクラスタリングを行えばまた別の結果になりそうなところです。
他のクラスタに関していえば、概ね良い感じに分類できていそうです。これだけクラスタリングできていることを考えると、このグラフはかなり配信者間の類似性を表現できていそうな気がしてきました。
登録者数と中心性は比例するか
次に、中心性と呼ばれる指標を使います。中心性とは、ざっくりいえば「あるノードがそのグラフにおいてどれだけ重要なのか」を示すための指標です。
様々な指標がありますが、それら中心性を見る際に何と比較して考えるかというと、今回はチャンネル登録者数と紐付けて考えてみたいと思います。配信者間のネットワークグラフを作るとして、単純に考えれば登録者数が多ければ多いほど、そのチャンネルはネットワークにおけるハブとしての役目を果たすことになると考えられます。なので、ネットワークにおける重要度も高いのではないだろうか...という具合ですね。
今回はPageRankというものを見ることにします。googleの検索スコアにも使われているやつですね。PageRankの考え方としては、「重要度の高いノードから接続されているノードはそれ以上に重要度が高いだろう」という感じです。とりあえずwikipediaを貼っておく... https://ja.wikipedia.org/wiki/ページランク
では早速計算した結果をみていきましょう。
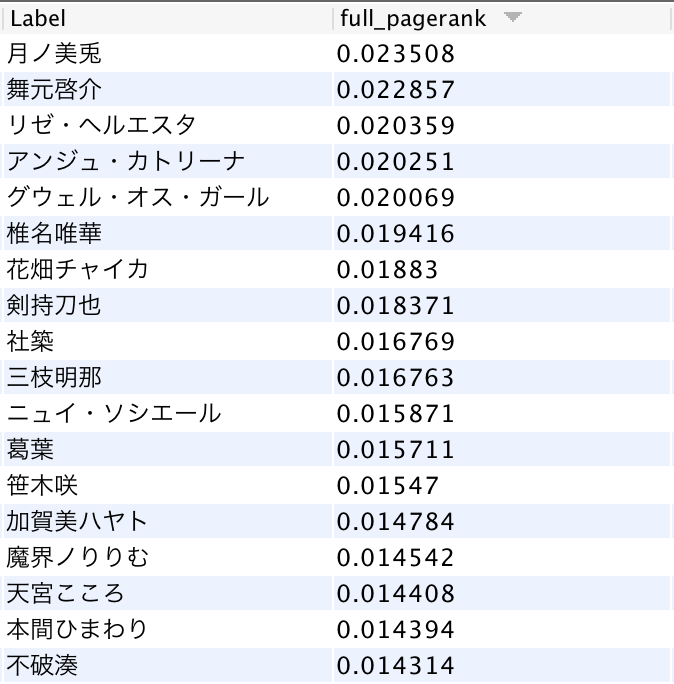
PageRankが高い順に、月ノ美兎氏,舞元啓介氏,リゼ・ヘルエスタ氏,アンジュ・カトリーナ氏,グウェル・オス・ガール氏 ... という順番となりました。にじさんじ内での登録者数1位の月ノ美兎氏がPageRankでも1位に来ているのは登録者数との関係性を示唆するものですが、それ以降は単純に登録者数に比例するとは言えなさそうな順番になっています。
登録者数をx軸、PageRankをy軸にして、散布図に起こしてみます。
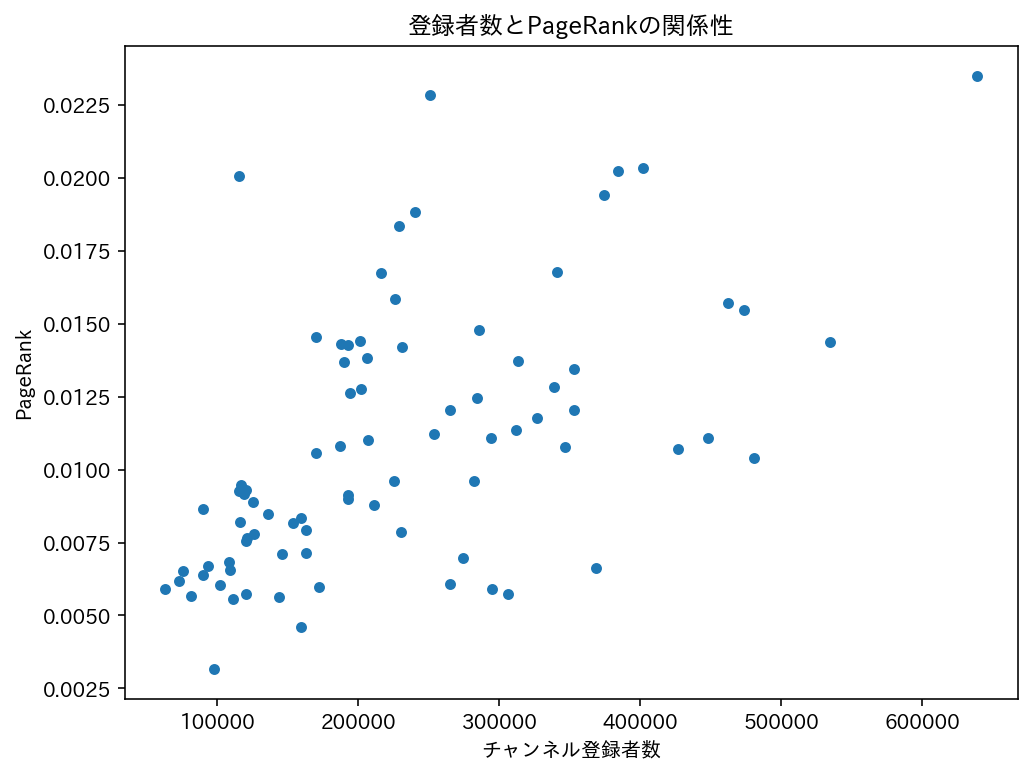
いい感じに回帰線が引けそうな散布図になりましたね。実際、相関係数を計算してみると0.55ほどになりそれなりの相関係数が認められました。しかし、0.8とかではなく0.5なので、登録者数がノードの重要性とイコールで語れるわけではなさそうです。
ちなみにPageRankが強いノードを大きくして可視化すると以下のようになります。
PageRankは何と関係しているのか?
さて、今回PageRankを計算するベースとしたネットワークグラフは、9-10月の配信のチャットデータから作成したものでした。今までは集約してみていましたが、細かい挙動を理解するためにはもう少し小さい視点で見たほうが良さそうです。ということで、配信ごとに見ていきたいと思います。
この期間のデータに強い特徴を持った配信があったことで、PageRankがあのような挙動になったと考えるべき。どんな特徴がよさそうでしょうか。
たとえば、普段別の配信でコメントしているユーザが流入してきた数が多ければ多いほど、その配信の特徴が強いと考えても良さそうです。
実際にそれ(diversity_scoreとします)を計算してみて、高い順に配信をソートすると次のようになります。

大型企画の配信、3Dお披露目、誕生日凸待ちなどがdiversity_scoreの高い配信になります。(これらの配信の内容がわからない人にとってはなんのことやらという感じですが)
再生数を併記して並べてみるとこんな感じになります。
- 「にじさんじ甲子園 決勝」... 136万回再生
- 「百物語2020」... 152万回再生
- 「にじさんじ甲子園 Bリーグ」... 89万回再生
- 「月ノ美兎生誕祭2020」... 57万回再生
- 「椎名人狼」... 52万回再生
- 「グウェル・魔界ノりりむ 積分配信」... 92万回再生
- 「町田ちま フリージア耐久配信」... 90万回再生
- 「アンジュ凸待ち」... 66万回再生
- 「葉加瀬3D」... 44万回再生
- 「桜凛月3D」... 40万回再生
単純にdiversity_scoreと再生数が比例しているといいきれそうならいいのですが、再生回数が30万規模で順位が入れ替わっていたりするので、有意な関係性はでてこなさそうな気がします。単なるコラボとかではなく、コメントしやすい雰囲気が配信にあることがdiversity_scoreが上位になっている理由でしょう。(再生回数が一定規模にあることは前提っぽいですが)
さて、これら配信を行った配信者は、先程のPageRankも比較的高い傾向にありました。PageRankと、その配信者が該当期間に行った配信がどれくらい話題になったのか、がだいたいイコールの関係性にあると言っても差し支えなさそうに見えますね。大きなコラボをやっていればdiversity_scoreが上位に来るのはそれはそう、なのですが、「町田ちま フリージア耐久配信」「グウェル・魔界ノりりむ 積分配信」のように、コラボ人数が絶対条件というわけではない、というのが難しいところです。
拡散力のある配信をどれくらい行ったのか、と言い換えても良いかもしれません。
このネットワークグラフで何かできるの?
さて、そろそろいい加減長々書いてきてしまったので、最後にこのネットワークグラフって何かに使えるのかという話をして終わりたいと思います。
そのデータの期間から話題になった配信者がわかる
ここまで書いてきたように、ネットワークグラフに集約すればノードの重要性を計算することで、そのデータを集めた期間にその配信者がどれくらい話題になったか、が定量化出来ます。
配信者の推薦ができる
ネットワークグラフになっていることで、各配信者の類似性が構造化されたデータに落とすことが出来ていると言えます。それを使って、「この配信者を見たことあるけど、他に似たような配信してる人が同じ箱にいたら見てみたいな」といったニーズに対して答えられるレコメンドができます。
以下は Node2Vec という技術を用いて、各ノードをベクトル化している様子です。
from node2vec import Node2Vec
import networkx as nx
df = pd.read_csv("nijisanji_chat_graph.csv")
df.columns = ['source', 'target', 'weight']
G = nx.from_pandas_edgelist(df, "source", "target", ["weight"])
node2vec = Node2Vec(G, dimensions=128, walk_length=30, num_walks=200, workers=4)
model = node2vec.fit(window=10, min_count=1, batch_words=4, seed=42)
model.wv.most_similar('叶')
> [('葛葉', 0.9757106304168701),
('不破湊', 0.962429940700531),
('椎名唯華', 0.9347176551818848),
('勇気ちひろ', 0.9159013032913208),
('ラトナ・プティ', 0.9092192649841309),
('エクス・アルビオ', 0.8829002380371094),
('イブラヒム', 0.8717691898345947),
('三枝明那', 0.8703913688659668),
('渋谷ハジメ', 0.861824631690979),
('グウェル・オス・ガール', 0.8347264528274536)]
9-10月にAPEX配信を多く行っていた叶氏を対象とすれば、このように「くろのわちー」の葛葉氏・勇気ちひろ氏が次にお薦めできる配信者としてレコメンドされます。チャットユーザがそれだけ似通っていた、ということですね。
YouTubeのレコメンドだけで大抵の場合は事足りると思います。が、ある一つのグループに限定してそれら関係性からレコメンドをしたい、といったドメイン特化したケースはYouTubeは特に守備範囲ではありません。
にじさんじでレコメンドを作るとしたら、それぞれの関係性がとても重要だと思うので、それらを陽に考えられるネットワークグラフからレコメンドモデルを作るのがいいんじゃないかな〜と勝手に思いました。
まとめ
- にじさんじの配信者による直近30動画(アーカイブ)のチャットデータを収集。チャットデータから配信者をノードとしたグラフを作成
- グラフをモジュラリティクラスタリングすると、どんなゲームを配信していることが多いか・配信者のキャラクター性・関係性などによってそれなりに綺麗なクラスタに分かれた。チャットユーザの共通性から作成した今回のグラフは、配信者の類似性をある程度表現できていそうと分かった。
- ついでに、チャンネル登録者数とPageRank(あるノードの重要性を示す指標)が相関しているかどうかを検証したところ、結論として、PageRankは登録者数とある程度の相関が見られた。が、登録者数だけでなく、どれくらい話題になった(拡散力のある)配信をしたか、がPageRankによって表現されているとも言えることがわかった。
- ネットワークグラフがあればいろいろな応用例が考えられる。その一つとしてグラフデータを入力として、ある配信者に"近い"配信者をレコメンドするモデルを作成するなど。
はい、ということで長々書いてきましたが、youtube data apiを使って文化的な遊びができました。これを思い立った文化の日から一週間経ってしまいましたが、まとめられてよかった。
(追記)今振り返ってみると、大型コラボ・企画を除いた場合のデータで分析したほうが今回の目的にはより適切だったかもですね。ただ、一つ一つの配信タイトルを見て除外していく作業時間を取るのが億劫で今回はえいやとやってしまいました。