前回Functionsのデバッグ環境を整えたわけですが、今回はAzure SQLにFunctionsからアクセスしていきたいと思います。
おおまかな流れ
- パッケージのインストール
- コードの確認
- AzureFunctionsにpublish、そして確認
- 余談、パッケージのバージョン指定
パッケージのインストール
今回、Functionsの中でAzureSQLに接続する中で、最初はODBCを使うという選択をしていました。
私が参考にしたコードの中でpyodbcが使われていたんですね。
しかし、これはあんまり上手くない方法だと分かりました。
理由は、ODBCを使うにはシステムにODBCを使うためのインストール作業を行わなければならなかったからです。
aptにMicrosoftのリポジトリを追加して、システムにODBCをインストールし、そのインタフェースとしてPythonインタプリター側にpyodbcパッケージをインストールし、コード内で使っていく、という流れになります。
しかしこうなると、このODBC自体はFunctionsの環境に入っているのか?という疑問が当然起こります。
requirements.txtにパッケージ情報を書くことで、Pythonインタプリターにインターフェースとしてのパッケージをインストールすることはできますが、そのインタフェースの先にODBCコアがなければコードは正常に動きません。
それで調べてみたんですが、どうやらFunctionsの中にはODBC環境はないようでした。
ということで、ODBCを使わずにAzureSQLに接続する方法を探したところ、sqlalchemyと
pymssqlを使えばイケるということが分かりました。
ついては、これらをインストールしていきます。
pip install sqlalchemy
pip install pymssql
ついでにパスワード等、DB接続情報の安全運用を行うため
pip install python-dotenv
もやっておきます。
続いて、コードベースで説明していきます。
コードの確認
こちらがFunctionsのコードの全文となります。
import os
import logging
import json
from datetime import datetime
from sqlalchemy import create_engine, text
from azure.functions import EventHubEvent
from typing import List
from dotenv import load_dotenv
load_dotenv()
def main(events: List[EventHubEvent]):
server = os.getenv('DB_SERVER')
database = os.getenv('DB_NAME')
username = os.getenv('DB_USER')
password = os.getenv('DB_PASSWORD')
# SQLAlchemy 接続文字列の作成
connection_string = f"mssql+pymssql://{username}:{password}@{server}/{database}"
# SQLAlchemy エンジンの作成
engine = create_engine(connection_string)
for event in events:
# イベントデータの解析
event_data = json.loads(event.get_body().decode('utf-8'))
logging.info(
f"Python EventHub trigger processed an event: {event_data}")
temperature = event_data['temperature']
humidity = event_data['humidity']
create_time = datetime.now()
try:
# データベースへのデータ挿入
with engine.connect() as connection:
insert_statement = text(
"INSERT INTO test_table (create_time, temperature, humidity) VALUES (:create_time, :temperature, :humidity)"
)
# パラメータを辞書形式に変換
params = {'create_time': create_time,
'temperature': temperature, 'humidity': humidity}
connection.execute(insert_statement, params)
connection.commit()
logging.info("データベースにデータを挿入しました。")
except Exception as e:
logging.error(f"データベースへのデータ挿入中にエラーが発生しました: {e}")
データベースの接続文字列の作り方
冒頭でSQLAlchemy向けのデータベース接続文字列を作っています。
server = os.getenv('DB_SERVER')
database = os.getenv('DB')
username = os.getenv('DB_USER')
password = os.getenv('DB_PASSWORD')
# SQLAlchemy 接続文字列の作成
connection_string = f"mssql+pymssql://{username}:{password}@{server}/{database}"
この内容についてはデータベースの接続文字列の画面から取得することができます。
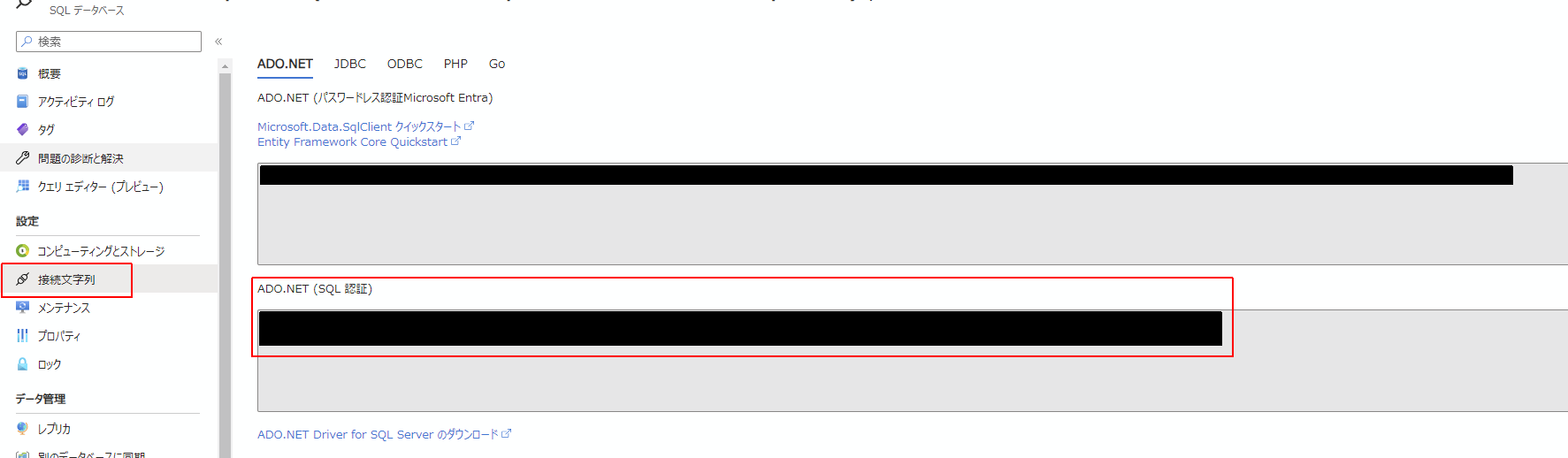
Server=tcp:<DB_SERVER>,1433;Initial Catalog=<DB_NAME>;Persist Security Info=False;User ID=<DB_USER>;Password=<DB_PASSWORD>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
というようなフォーマットでDB接続に必要な各情報が収められていますので、ここから取得して環境変数として保持します。
python-dotenvについて
環境変数に格納するにあたって、.envに書いておき、python-dotenvを使ってロードするとコードの中に重要情報を書き込むことなく、デバッグにもAzureにアップロードした後にも使えていい感じでした。
os.getenv()はローカルデバッグ時にはプロジェクト直下.envに書かれた情報を参照してくれます。
また、Azure環境上にアップロードされた後には、Functionsの「構成」で設定した環境変数を参照してくれます。
したがって、本番コードもデバッグコードも同じコードを使用することができます。
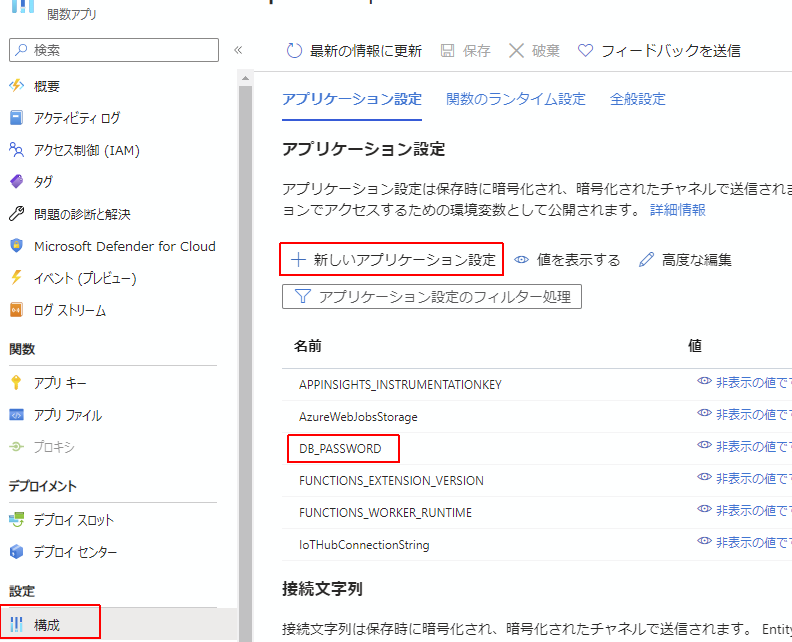
IoT Hubへの接続文字列の追加
構成には、忘れずIoT Hubへの接続文字列も追加しておきましょう。
これは前回の記事で紹介した function.js の "connection": "IoTHubConnectionString"に当たる文字列のことです。ローカルデバッグのときにはlocal.settings.jsonのIoTHubConnectionStringの値を読みに行って接続していましたが、local.settings.jsonはFunction上にアップロードされないため、IoTHubConnectionStringの値はFunctionsの構成に設定しておく必要があります。
AzureFunctionsにpublish、そして確認
ローカルデバッグで動作を確認したら、Functionsにデプロイします。
func azure functionapp publish <function-app-name> --python
下記の表示が出たら成功です。

アップロードできたら、その動作を確認します。
Functionsリソースの概要から、先ほどアップした<function-app-name>の書かれている「名前」欄の項目をクリックします。
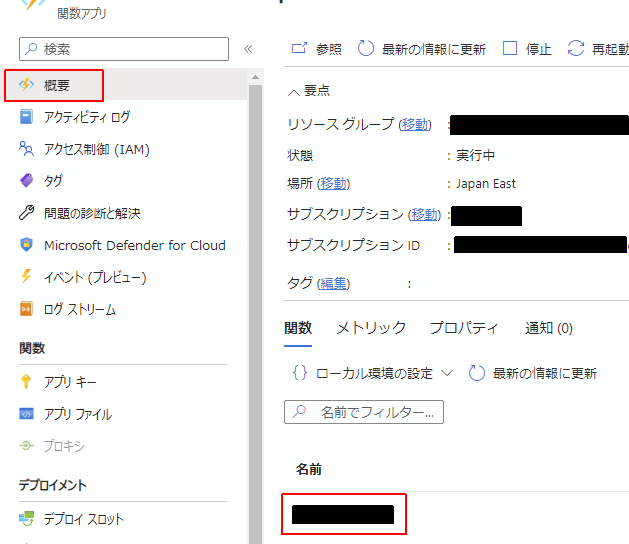
更に左側のペインからモニターの画面に行き、ログのタブをクリックしてしばらくするとApplication Insights に接続しています...というメッセージが表示され接続されました。となります。
この状況でIoT Hubに対してメッセージを送信すると、リアルタイムでログが表示されます。
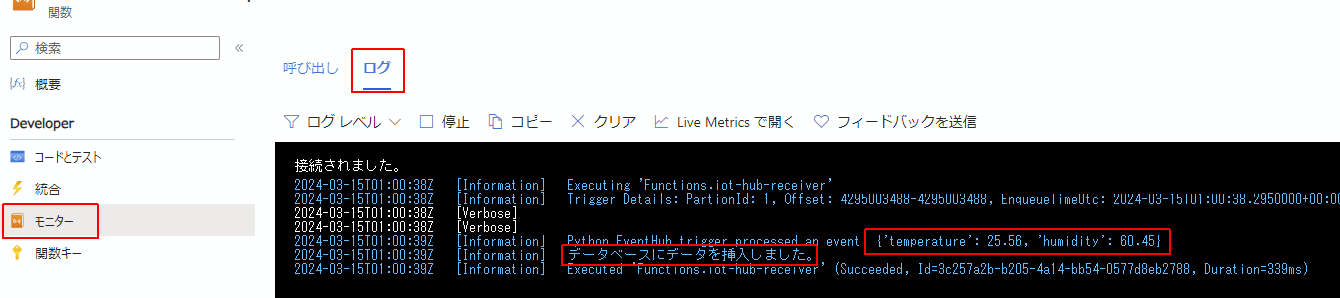
データベースでクエリを発行すると、無事データはDBの中に収められていました。
ただ、create_timeに関してはAzureの中ではUTCが採用されるようなので、このあたり+9時間で入力するかどうかは考えものですね。
デバッグ時にはシステムの時間(日本時間)がcreate_timeに入ってくるので、常に日本時間を入力しようとすると、本番とデバッグ時でコードを変更する必要があり、これは中々面倒な問題です。
余談、パッケージのバージョン指定
最後に余談ですが、AzureFunctions上のランタイムにインストールされるリストとして、requirements.txtを用意する必要がありますが、こちらの内容について、私の場合はバージョンを指定しました。
greenlet==3.0.3
pymssql==2.2.11
python-dotenv==1.0.1
sqlalchemy==2.0.28
typing-extensions==4.10.0
バージョンを指定しない場合、常に最新のバージョンがインストールされることになると思います。
そうなると、バージョン互換性の問題が発生する可能性があります。
バージョンを指定していても、そのバージョンがパッケージリポジトリから削除されたりした場合、逆に問題の原因になりますが、まあバージョンは指定しておいたほうがいいのではないかなと思います。
これらバージョンについてはpoetryを使って抽出することができます。パッケージが依存しているパッケージのバージョンも固めることができ、より運用安全性が増すと思われます。
poetry export --without-hashes -f requirements.txt > requirements.txt