OSXで擬似分散モードのApacheHadoop2.7.0を動かす で構築したHadoop上に、YARN+Spark環境を構築したメモ
ダウンロード & 展開
ビルドするのだるいので https://spark.apache.org/downloads.html から
1.4.0 / Pre-build for Hadoop 2.6 and later を選択してダウンロード

/usr/local2/以下に展開
$ tar zxvf ~/Download/spark-1.4.0-bin-hadoop2.6.tgz -C /usr/local2/
設定
/usr/local2/spark-1.4.0-bin-hadoop2.6/conf/spark-env.shを作成
このhadoopに合わせてある。
/usr/local2/spark-1.4.0-bin-hadoop2.6/conf/spark-env.sh
HADOOP_CONF_DIR=/usr/local2/hadoop-2.7.0/etc/hadoop
動作確認
yarn-clientモードでspark-shellを起動する
$ /usr/local2/spark-1.4.0-bin-hadoop2.6/bin/spark-shell --master yarn-client
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/27 18:49:49 INFO SecurityManager: Changing view acls to: kodai_abe
15/06/27 18:49:49 INFO SecurityManager: Changing modify acls to: kodai_abe
15/06/27 18:49:49 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(kodai_abe); users with modify permissions: Set(kodai_abe)
15/06/27 18:49:49 INFO HttpServer: Starting HTTP Server
15/06/27 18:49:49 INFO Utils: Successfully started service 'HTTP class server' on port 60019.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_05)
Type in expressions to have them evaluated.
Type :help for more information.
15/06/27 18:49:51 INFO SparkContext: Running Spark version 1.4.0
15/06/27 18:49:51 WARN SparkConf:
SPARK_CLASSPATH was detected (set to ':/usr/local2/hadoop-2.7.0/lib').
This is deprecated in Spark 1.0+.
## 以下省略
## ズラズラ流れてくる中に下のメッセージがあることを確認
## ....
15/06/27 18:50:04 INFO SparkILoop: Created spark context..
Spark context available as sc.
## ....
15/06/27 18:50:07 INFO SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext.
## scalaのreplが出てくる
scala>
## 適当なファイルでワードカウント
scala> val textfile = sc.textFile("/user/kodai_abe/hadoop-env.sh")
scala> val counts = textfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
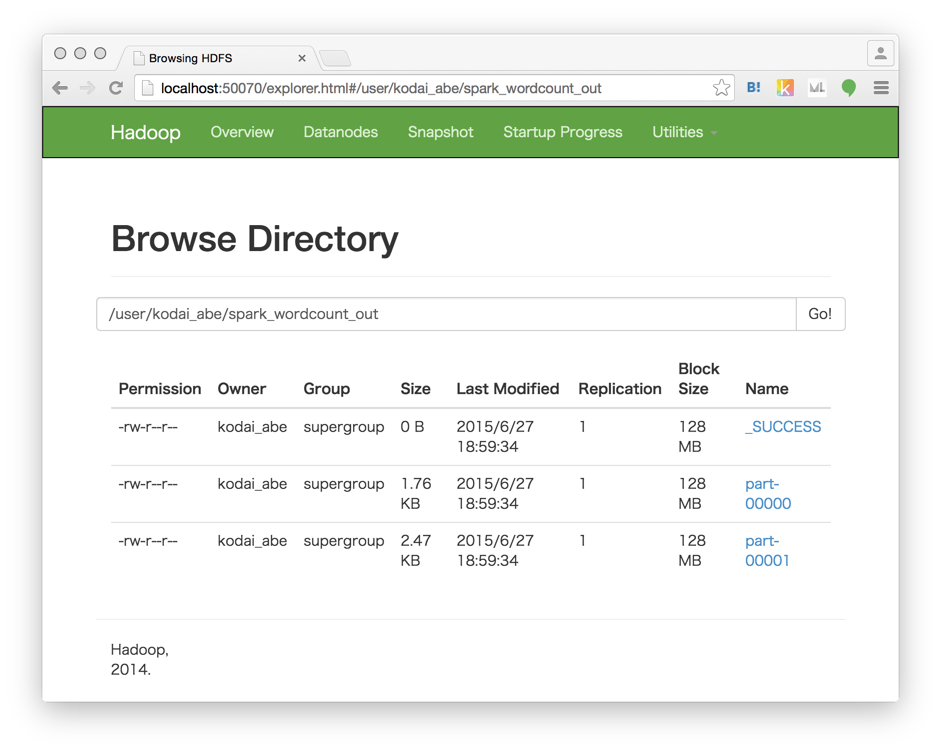
scala> counts.saveAsTextFile("/user/kodai_abe/spark_wordcount_out")
HDFSのWebインターフェースから確認