はじめに
Datadogは、インフラやアプリケーションの監視を一元管理できるプラットフォームで、AWSやGCP、Azureとも簡単に統合できます。
今回は、Datadog Agentの導入が完了したので、実際に監視設定を作成する手順をまとめます。
システムの状態をリアルタイムで把握したい、インシデント対応をスムーズにしたいと考えている場合は、無料トライアルで試してみるのもおすすめです。
書こうと思ったきっかけ
受講しているITスクールのチーム開発において、今回は運用監視をDatadogで一元管理することにしました。

一部AWSのCloudWatchやLambdaといったサーバーレスアーキテクチャを構築していますが、基本的なリソース監視やログ監視はDatadogを活用する方針です。
その中で、今回トライアル期間を活用して実装を進めてみようと思い、改めてDatadogについてキャッチアップしていきます。
Datadogとは?
Datadog は、クラウドやオンプレミス環境の 監視・分析 を行うための SaaS型オブザーバビリティプラットフォーム です。

引用画像:https://www.datadoghq.com/ja/blog/network-performance-monitoring/
サーバー・コンテナ・アプリケーション・ネットワーク・セキュリティ など、システム全体のパフォーマンスを リアルタイムに可視化・監視 できます。
Datadogに関する基本的な内容については、過去の記事でまとめていますので、そちらも参考にしてみてください。
実際にやってみた
ここでは、AWS上のWindowsサーバーにDatadog Agentが既に導入されていることを前提に進めます。
まだ導入が完了していない場合は、以下の記事で詳しく解説しているので、参考にしてください。
Datadog Agentの導入手順
監視対象の確認
まず、Datadog Agentが正しく動作しているかを、Datadogのダッシュボードで確認します。
手順
- Datadogのダッシュボードにログイン
- 「Infrastructure」 → 「Hosts」 を開く
- EC2インスタンスがリストに表示されていることを確認
ホスト一覧のスクリーンショット

さらに
- CPU使用率やメモリ使用率をリアルタイムで確認
- カスタムダッシュボードを作成して、必要なメトリクスを整理
- アラート設定で異常を検知
リソースモニタリング画面のスクリーンショット

そもそも、監視定義(Monitor)とは?
監視定義(Monitor)とは、特定のメトリクス(CPU使用率、メモリ使用量、ネットワークトラフィックなど)に対してしきい値を設定し、異常時にアラートを発生させる機能です。
Datadogでは、さまざまな種類のモニターを作成し、システムの異常をリアルタイムで検知することが可能です。
主な監視タイプ(Monitor Types)
| 監視タイプ | 説明 |
|---|---|
| メトリクスモニター | CPU使用率やメモリ使用量など、リアルタイムのメトリクスを監視 |
| ログモニター | 指定した条件のログが記録された場合にアラートを発行 |
| APMモニター | アプリケーションのリクエスト遅延やエラーレートを監視 |
| ネットワークモニター | サーバーやAPIの疎通を監視(Ping監視、HTTP監視など) |
| インテグレーションモニター | AWS、Azure、GCPなどのクラウドリソースの異常を監視 |
Datadogで監視定義(モニター)を作成する方法
Datadogでは、モニター(Monitor)を作成することで、システムの異常を検知し、アラートを発生させることができます。
ここでは、ホストの死活監視(Host Monitor) を作成する方法を紹介します!
まず、Datadogのダッシュボードにログインし、「Monitors」メニューを開いて「New Monitor」をクリックします。
次に、「Host Monitor」を選択することで、ホストの状態を監視する設定を開始できます。

監視したいホストを host タグで指定
Datadogでは、「Pick hosts by name or tag」 を使用して監視対象のホストをタグで指定できます。
手順
- Datadogのダッシュボードにログイン
- 「Monitors」 → 「New Monitor」 を選択
- 「Pick hosts by name or tag」 で監視対象のタグを指定
- 例:
host:my-server(特定のホストを指定)

これにより、特定のサーバーを対象とした監視を簡単に設定できます。
ポイント
-
特定のタグを持つホストのみを監視対象にする場合 は、
hostタグを使用する。 - 監視対象を絞ることで、不要なアラートを防ぎ、効率的な監視が可能。
今回は、アラートの条件はデフォルトの設定を使用し、カスタムメッセージを以下のように作成して入力しました。
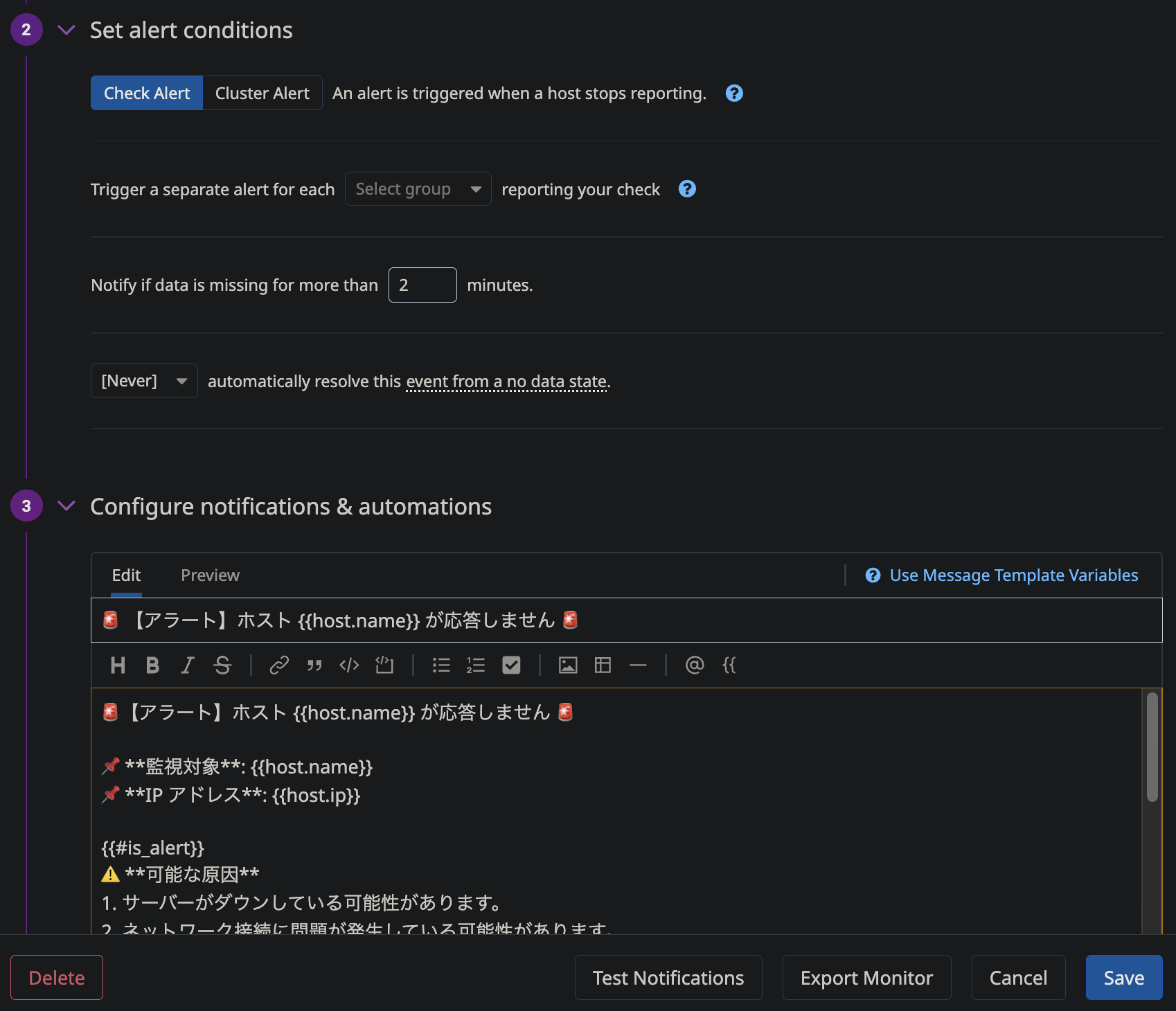
以下のメッセージは、一例としてのテンプレートになります。
🚨【アラート】ホスト {{host.name}} が応答しません 🚨
📌 **監視対象**: {{host.name}}
📌 **IP アドレス**: {{host.ip}}
{{#is_alert}}
⚠️ **可能な原因**
1. サーバーがダウンしている可能性があります。
2. ネットワーク接続に問題が発生している可能性があります。
3. Datadog Agent が停止している可能性があります。
🛠 **対応方法**
- AWS マネジメントコンソールで該当ホストの状態を確認
- SSH で接続できるかチェック
- Datadog Agent のステータスを確認 (`sudo systemctl status datadog-agent`)
🔍 **追加情報**
- Datadogダッシュボード: [ホスト詳細](https://app.datadoghq.com/infrastructure?filter=host:{{host.name}})
- Ops Guide: [トラブルシューティング手順](http://ops.myorg.com/guide)
🔔 **通知**: @xxx@gmail.com
{{/is_alert}}
このテンプレートを活用することで、障害発生時に迅速に対応できるようになります。
必要に応じて、環境に合わせたメッセージのカスタマイズを行ってください。
実際にOSを停止してみた
Datadogのホスト監視(Host Monitor)の動作を確認するために、WindowsサーバーのOSを停止するテストを実施しました。
まず、OSを停止する前の状態では、監視対象のホストが正常に動作していることを示す緑色のマークが表示され、正常であることを確認しました。
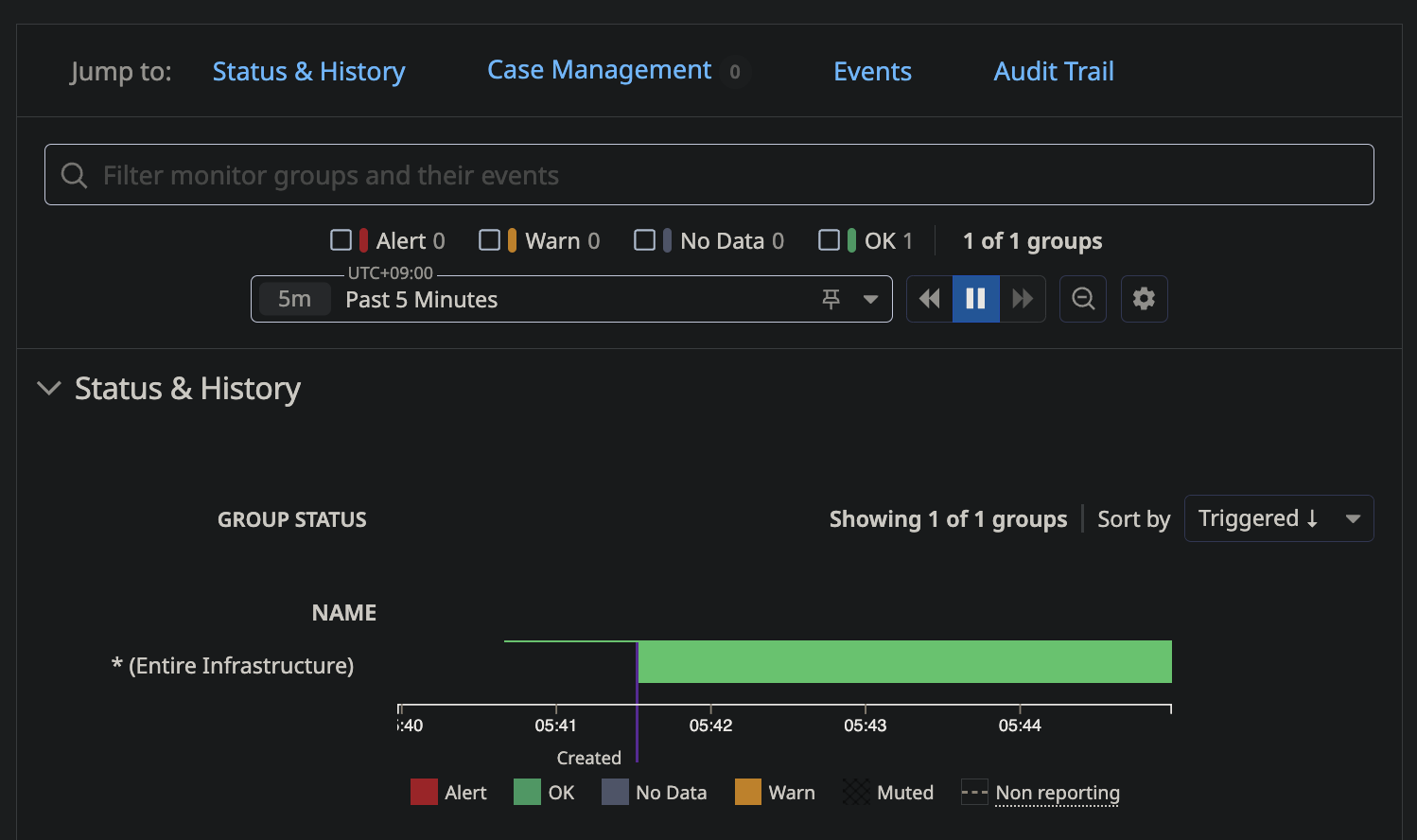
次に、AWSのマネジメントコンソール上から対象のWindowsサーバーのOSを停止しました。
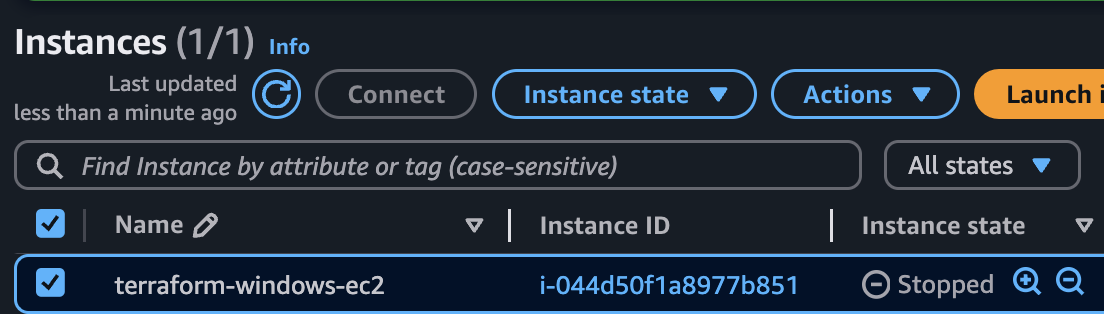
すると、Datadogの監視結果が更新され、ホストの状態が緑色マークから赤色マークに変わり、アラートが発生したことを確認しました。

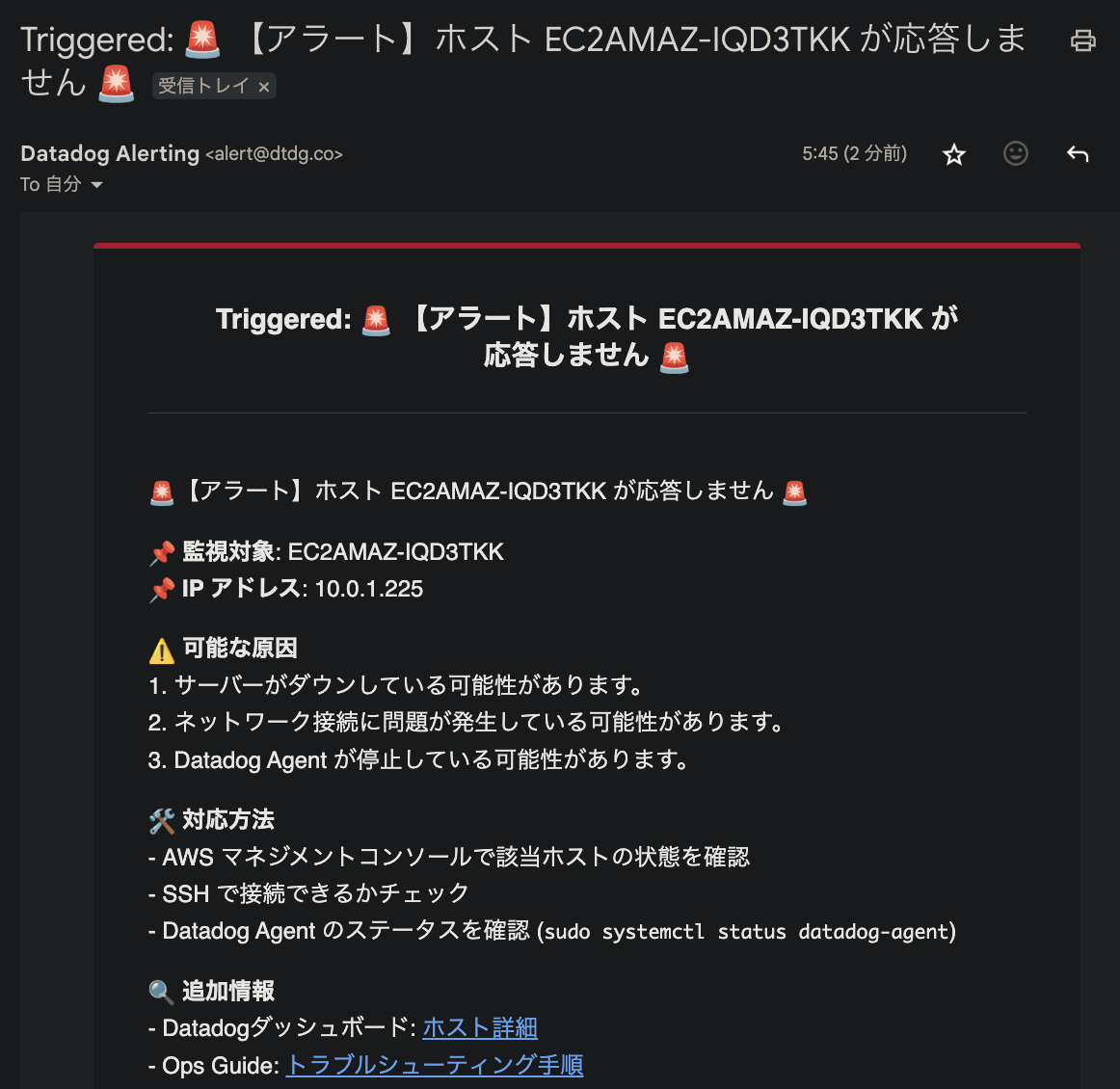
その結果、想定通りのアラートメールが届いていることが確認できたため、今回の検証は成功と言えます。
受信したアラートメール
まとめ
ここまで読んでいただきありがとうございました。
すべての検証が想定通りにスムーズに進み、Datadogを活用したホストの死活監視が正しく機能することを確認できました。
次回は、実際にログ監視の設定を行い、特定のエラーログを検知する監視定義を作成 していこうと思います。
興味のある方は、ぜひ引き続きご覧ください!