この記事は古川研究室 Workout_calendar 24日目の記事です。
本記事は古川研究室の学生が学習の一環として書いたものです。内容が曖昧であったり表現が多少異なったりする場合があります。
はじめに
機械学習について学んでいる皆様、こんにちは。本記事ではデータの前処理について基礎的なところをまとめ、解説していきます。
既存の機械学習手法を利用するにしても、学習に適したデータが無ければ始まりません。とりたての、いわゆる"生データ"は、そもそも数値データでなくて処理できなかったり、そのまま用いても欲しい情報を得られなかったりといったことがあります。機械学習を活用するためには、まずデータの前処理の手法を身に着けましょう!ということで今回は入門編です。前処理の代表的な手法を、ライブラリでの実装も含めて見ていきましょう。
具体的には、Python機械学習チュートリアルを参考に scikit-learn, pandas, numpy といったライブラリを利用して前処理を行います。必要であれば参考文献を参照してください。
代表的な前処理たち
さっそく代表的な前処理を見ていきましょう。
各章後半ではライブラリによる実装を行います。実装にはJupyter notebook とPython3 を用います。
カテゴリデータの符号化
データを表の形にしたとき、記号や文字列で保持されていることが多いのがこのカテゴリデータです。コンピュータで処理する以上、数値化されていなければ扱えません。
例えば以下のようなデータがあったとします。

このときの「ドリンクの種類」がカテゴリデータです。これを、例えば Label Encoder を使って処理すると

このようになって、対応表は次のようになります。

こうしておけば、ドリンクの種類を数値で扱えるようになります。欲しい行を抜きだすときも数値で指定できます。シンプルで重要な前処理です。
OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
MF = [['r','Male', 'A'], ['r','Female', 'B'], ['l','Female', 'AB'], ['l','Male', 'O'], ['l','Male','AB']]
print(MF)
enc.fit(MF)
for i in enc.categories_:
print(i)
enc.transform(MF).toarray()
[利き手、性別、血液型] のデータを用意してみました。

各属性が何通りあるかが表示されます

↑の属性の対応するところに1、それ以外に0が入ります。例えば一人目は、
[0, 1] 右利き
[0, 1] 男性
[1, 0, 0, 0] A型
これをつなぎ合わせると
[0, 1, 0, 1, 1, 0, 0, 0]
となって次の出力の一行目と一致します。

LabelEncoder
from sklearn.preprocessing import LabelEncoder
label_encoder=LabelEncoder()
input_classes=['Havells','Philips','Syska','Eveready','Lloyd']
label_encoder.fit(input_classes)
input_classes
for i,item in enumerate(label_encoder.classes_):
print(item,'-->',i)
labels=['Lloyd','Syska','Philips']
output= label_encoder.transform(labels)
output
label_encoder.inverse_transform(output)

アルファベットの順に並びが変わりますが、それぞれに数字が割り当てられます

ラベルの列を作ってエンコードすると、割り当てられた数字に変換されます
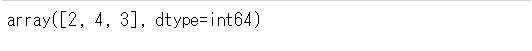
数列を渡して逆変換を行うと、対応する文字列に変換されます

データの数値の範囲を変更する
データの属性が望みのものと異なるスケール(値の幅)を持つ場合には、それらの値が扱いやすい範囲(例えば0から1)に収まるように数値を変更する操作を行います。正規化と呼ばれる処理です。複数の属性のスケールを揃えることで、比較を容易にするといった利用があります。特に最小値が0、最大値が1となる指定は、スケールを揃えると同時に重み処理などで都合がよいため、正規化ではよく用いられます。
正規化
import pandas, numpy
df=pandas.read_csv( 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ',sep=';')
array=df.values
# Separating data into input and output components
x=array[:,0:8]
print(x)
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler(feature_range=(0,1)) #正規化
rescaledX=scaler.fit_transform(x)
numpy.set_printoptions(precision=3) #Setting precision for the output
print(rescaledX[0:5,:])
print(numpy.max(rescaledX))
print(numpy.min(rescaledX))
処理前のデータ

処理後のデータ

最大値が1、最小値が0と、指定した範囲に収まっています。
データの分布を変更する
データの分布を、平均0、分散1に変更します。標準化と呼ばれる処理です。複数の異なるデータ間の分布を比較しやすくなります。同じデータ内の属性を比較したいときにはスケールを揃える正規化、異なるデータ同士の比較をしたいときには分布の位置を揃える標準化、といったような使い分けが考えられます。
例えば以下のような回帰問題を解いた図では、
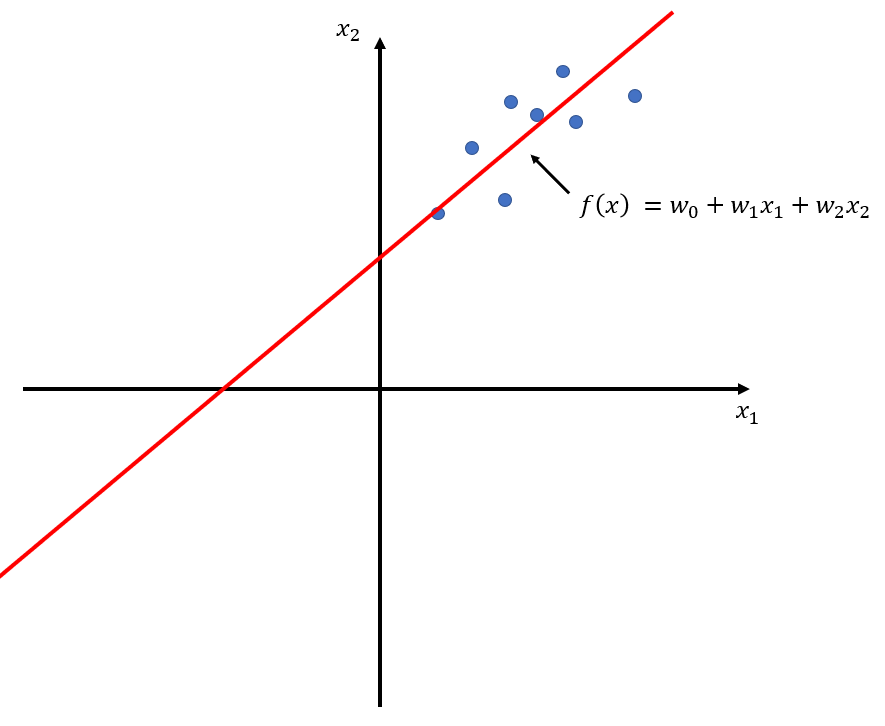
標準化を行うことで次のようになります。

標準化
import pandas, numpy
df=pandas.read_csv( 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ',sep=';')
array=df.values
# Separating data into input and output components
x=array[:,0:8]
print(x)
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler().fit(x) #平均0、分散1に変換
rescaledX=scaler.transform(x)
print(rescaledX[0:5,:])
print(rescaledX.mean(axis=0))
print(rescaledX.std(axis=0))
処理前のデータ

処理後のデータ

平均が0付近になり、分散が1になっています
欠損値の処理
欠損値があった際の対応は主に2パターンです。
- 欠損値をもつデータを取り除く
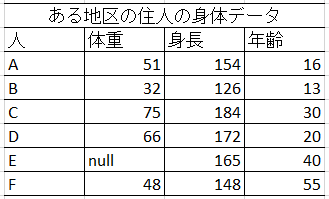
十分に数が揃えばよいデータの場合、データがとれていない、失った、などで欠損が見られるときは、その欠損値をもつ行を削除するという処理が考えられます。この場合はEさんの行を削除してしまえばデータセットとしての形が揃います。ただしサンプル数が少ない場合にはデータの再取得を試みるべきかもしれません。
- 欠損値をもつデータを取り除かない

全員がレビューをしてくれるとは限らない!ので、欠損値が多くなっています。こうなると欠損値を持つからと言ってその人のデータを削除するわけにはいきません。購入者には潜在的な評価値があるが、データには表れていない、といったようにデータごとに分析し、その意味を考えなくてはなりません。
→ データごとに分析し、どのように処理するか考える必要があります。欠損値を持つ行を削除するコマンドは存在します。
属性値の変換、追加
カテゴリデータの符号化とはまた違う意味で、データの解釈を変えたり加えたりすることです。
例えば着ているシャツの色を調べて次の表のようになったとき、
- 色の参考ページ:原色大辞典(https://www.colordic.org/)
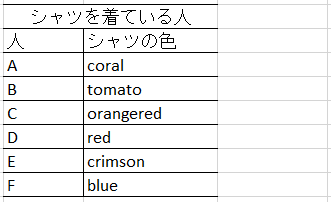
A~E の人の似たような色のシャツについてまとめてしまって次のようにしたほうが都合がよい場合があります。

このような操作は特徴量の追加とも呼ばれます。
→ データごとに分析し、どのように処理するか考える必要があります。
データの次元の削減
データの属性が多い(データの次元が高い)と、計算に大きな時間を要したり、いくつかの要素がノイズとなってしまって機械学習の効率と精度に悪影響が出てしまう場合に行います。多々ある属性のデータの特徴を、それより少ない成分でもって的確に表すことも出来るだろうという仮定のもと、特徴を表す成分の抽出を試みます。主成分分析で実現されます。
主成分分析(PCA)
# 数値計算やデータフレーム操作に関するライブラリをインポートする
import numpy as np
import pandas as pd
# URL によるリソースへのアクセスを提供するライブラリをインポートする。
import urllib.request
# 図やグラフを図示するためのライブラリをインポートする。
import matplotlib.pyplot as plt
%matplotlib inline
import sklearn #機械学習のライブラリ
from sklearn.decomposition import PCA #主成分分析器
df = pd.read_csv( 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ',sep=';')
df.head()
df = df.values
# 行列の標準化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler().fit(df) #平均0、分散1に変換
dfs = scaler.transform(df)
pd.DataFrame(pd.Series(dfs.ravel()).describe()).transpose()
# 主成分分析の実行
pca = PCA(n_components=2).fit(dfs)
dfs = pca.transform(dfs)
print(dfs)
print(pca.explained_variance_ratio_)
plt.figure(figsize=(6, 6))
plt.scatter(dfs[:, 0], dfs[:, 1], c=list(dfs[:, 1]), alpha=0.5)
plt.grid()
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.show()
はじめに持っている属性は12個あります。このうち、特徴を多く表してくれる順に2つの属性に絞っていきます。

各属性の比較をしやすくするために標準化を行います。

2つの主成分による表現に置き換わりました。こちらの値は寄与率といって、本来の属性すべてを足し合わせて計算すると1.0になります。これが高いほど特徴を失わずに表現できていることになります。今回は足し合わせておよそ0.45、本来12個の属性を持つデータについて、この2つで半分くらいの特徴を捉えられています。

プロットしてみると次のようになります。属性"quality"をカテゴリとして色を付けました。色ごとにまとまっていることがわかります。このとき広く分布してくれると重なり合いが少なくなっていき、例えばこの後に分類を行う場合にカテゴリごとに分けやすくなってありがたいです。この場合は完全にわかれてはいませんが、これで十分とすることも考えられます。必要であれば、主成分を3つに増やすなどします。

おわりに
今回は前処理入門編でした。前処理は後の段階でどのようなデータが欲しいか考えながら行う必要があります。データの解析も合わせ、慣らしていかなくてはと思います。
この記事では入門編として代表的なものを挙げましたが、例えば対象が画像になれば、またいくつもの手法があります。奥深いです。
まずは今回のようなライブラリによる処理をひとつずつ扱い、次に組み合わせて用いる、といったように慣らしていくのが良いかなと思います。
それでは!
参考文献
Python Machine Learning Tutorial [1]
https://data-flair.training/blogs/python-ml-data-preprocessing/
機械学習のデータ前処理備忘録 [2]
https://qiita.com/takuya_tsurumi/items/53b9e3f7427b631b17cf
「データ前処理」- Kaggle人気チュートリアル [3]
https://qiita.com/hokuto_HIRANO/items/12e046b3e02961d8460d
データ前処理② データを Categorical から Numerical に。 [4]
https://qiita.com/kibinag0/items/723f95277263921650b4