はじめに
ABEJA Advent Calendar 2021 4日目の記事です。
ABEJAでは Insight for Retail というサービスで、店舗内の顧客の数や動きなどをカメラやセンサーで把握して、商品陳列や店員の配置、施策の効果検証などを分析するインストアアナリティクスを提供しております。
本記事はそのデータ分析を支えるAirflow/BigQueryの運用事例についてご紹介します。
データ基盤の構成について
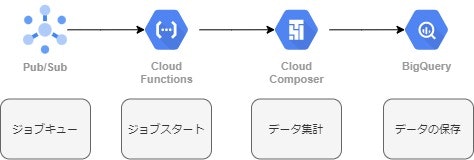
Insight for Retailではデータ基盤をGCP上で構築しています。
Pub/Subをジョブキューとして利用し、Cloud FunctionsからAirflowのDAGを実行、集計結果をBigQueryに保存する仕組みになっています。
Cloud Composer
データ集計処理はAirflowを利用しています。構築はGCPが提供している、フルマネージドサービスのCloud Composerを利用しています。
Airflowを利用することで柔軟なタスクの依存関係の設定や、Airflow UIによる可視化が実現されています。
BigQuery
データレイク、データウエアハウス、データマートはすべてBigQuery上で統一してアクセス可能になっています。
-
データレイク: 生データをそのままロード -
データウエアハウス: データレイクの生データをもとに、重複データ除去や正規化などがされた状態で保存 -
データマート: ダッシュボードで出したい情報に合わせたデータ集計結果や機械学習モデルの実行結果を保存
Insight for Retailでは店舗のデータ(来客数、来客属性など)を準リアルタイムでダッシュボードに提供しており、当日のデータは常に集計されている一方、過去のデータは集計ロジックの追加・変更などがなければ集計されないという特徴があります。
そのためBigQueryのスキャン量を抑えるために、時系列データを扱うテーブルは基本的に日次パーティション分割されています。
Pub/Subの利用
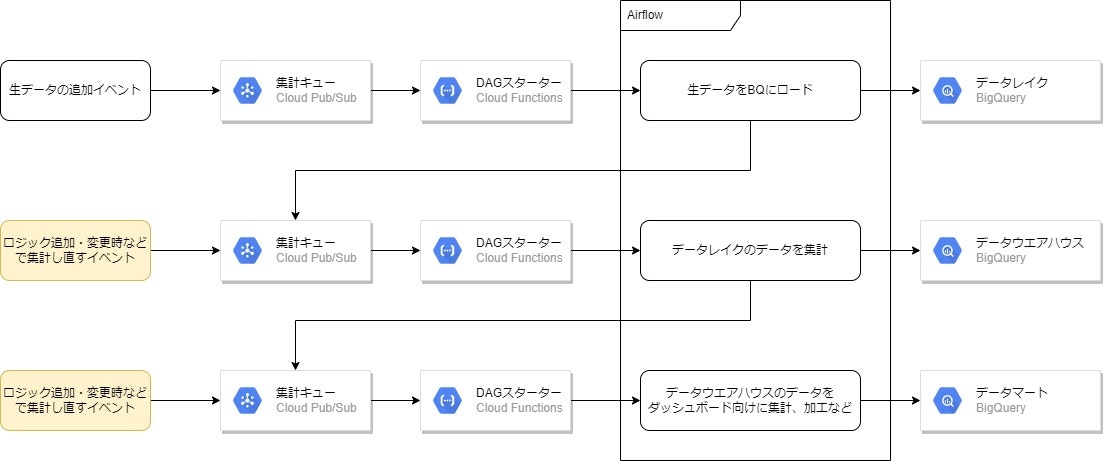
集計のためのDAGは2点の理由でPub/Subを挟んでDAG実行のキューイングしています。
ABEJAではアプリ/インフラのモニタリングに Datadog を利用していて、Pub/Subのメッセージ数と未確認メッセージ数をモニタリングすることが容易です。
これによりDatadog上で現在の処理状況が可視化され、状況の把握や障害検知などに役立てています。
また普通のユースケースではまず困ることはないと思うのですが、負荷試験の結果大量のタスクを投入するとスペック不足等によってタスクがrunningのままハングしてしまうという課題もありました。
これが発生すると付随して、ハングしたrunningのタスクがAirflowに設定した同時実行数まで到達したときにこれ以上タスクの実行ができないとスケジューラが判断して、すべてのタスクの実行がされなくなってしまうという問題も発生してしまいます。
Insight for Retailではオペレーション的に発生しうるということで、Composerのスペックを上げるというよりは安価で高い信頼性のあるPub/Subをキューイングに利用しています。
Airflowチューニング
ある程度はAirflowが面倒を見てくれますが、データ分析という特性上DAGの特性に合わせてチューニングを行わないと期待した性能を得られませんでした。
Insight for Retailは後述する3つの点を調整しました。
並列実行数の設定
Airflowの並列実行数を設定はやや複雑ですが、DAGの特性に合わせて4点をおさえて、スループットとリソース制約のバランスをとっています。
クラスタ全体のタスク並列数 (core.parallelism) とワーカーのタスク並列数 (celery.worker_concurrency)の設定はairflow.cfgで設定できます。
クラスタ全体のタスク並列数 = ワーカーのタスク並列数 * ワーカー数を設定しています。
DAGの同時実行数はDAG定義時にmax_active_runsパラメータで設定することができます。
また、DAG内のタスクの同時実行数もDAG定義時にconcurrencyパラメータで設定する事ができます。
両者ともairflow.cfgで上限が設定できますが、DAGの特性に合わせて個別で定義するのが良さそうでした。
他にもタスクレベルでプール(pool,pool_slots)や並列数(task_concurrency)が設定でき、Airflow以外の外部のリソースを利用するときなどに、レートリミットなどを超えないように同時実行数を抑えるといった制御も可能です。
タスクのタイムアウトを設定
前述のDAG大量実行や、タスクのバグ、何かしらの不具合やエラーによってタスクがrunningのままハングしてしまうことがあります。runningのままだとfailしていない状態なので、エラー通知もリトライのハンドリングもされない状態となってしまいます。
そこでタスクの想定実行時間に合わせて execution_timeout パラメータを適切に設定することでトラブルを回避しています。
BigQueryのレートリミットに注意
BigQueryのレートリミットは細かく設定されていて、テストしておかないと思わぬレートリミットにかかってしまい、データが更新できなくなるということが発生します。
時系列データを扱う都合上、パーティション分割テーブルを多用しているのですが、これのレートリミットが1回で変更できるパーティション4000個とか1日のパーティション分割テーブルあたりのパーティション変更回数5000回とかで、日次パーティションデータが仮に10年分あるとすると10年 * 365日 = 3650なので、タスクの重複などがあるとレートリミットに引っかかってしまいます。
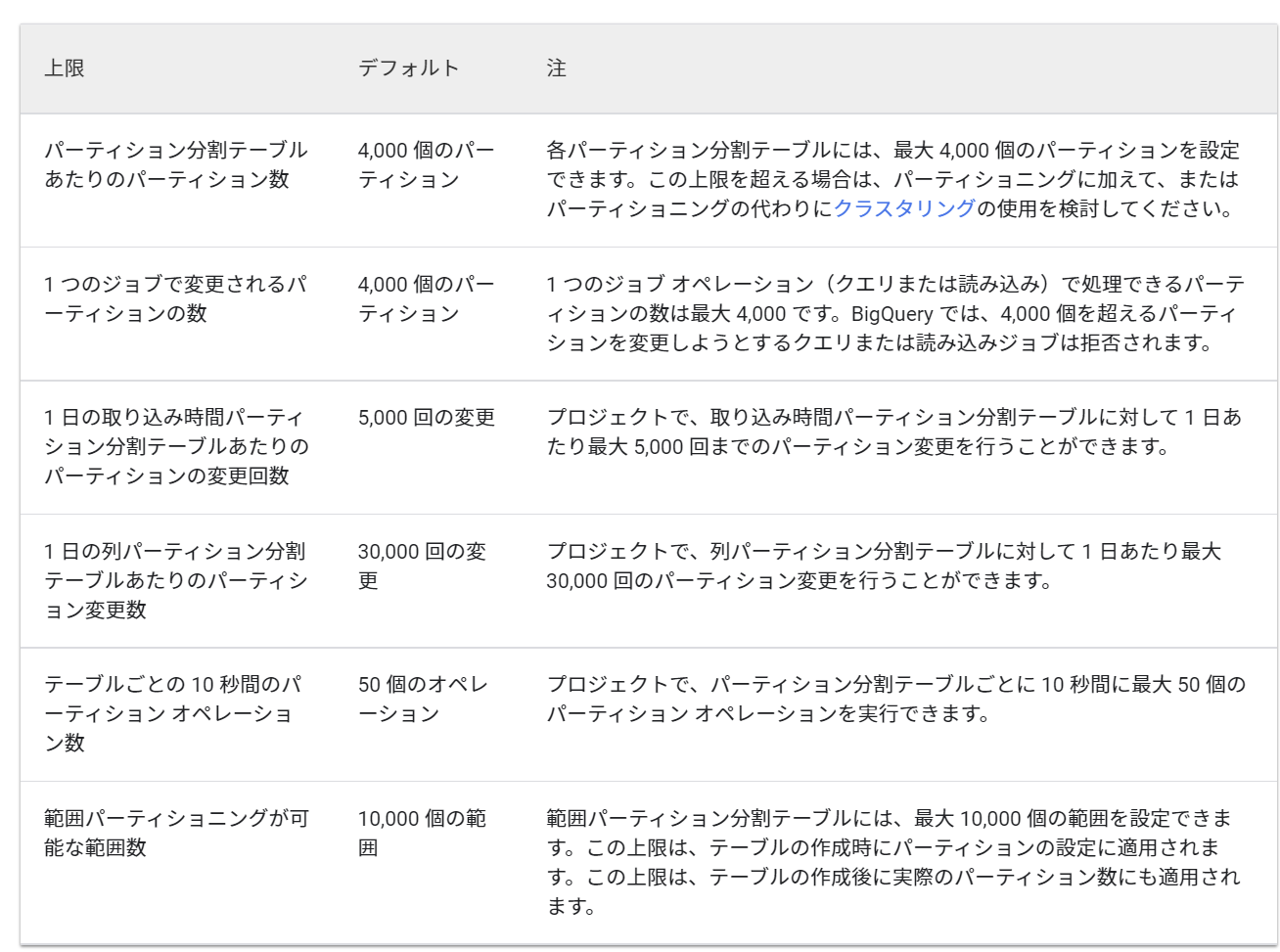
レートリミットにかかってしまうと準リアルタイムなデータ提供ができなくなってしまうので、負荷テスト実施時にレートリミットにかかる部分を洗い出し、前述の並列実行数の制限やジョブスタート時に重複ジョブを排除するロジックなどを導入してなるべくかからないように工夫しています。
レートリミットはBigQueryのエラーとして記録されてるため、以下のクエリで確認することができます。
SELECT
project_id,
user_email,
creation_time,
job_type,
CASE WHEN statement_type IS NULL THEN 'N/A' ELSE statement_type END AS statement_type,
error_result
FROM
`region-{region_name}`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
error_result.reason IS NOT NULL
ORDER BY
creation_time DESC
その他
AirflowドキュメントのFAQ にハマリポイントの解決方法が書いてあったりするので、もしなにかairflowでトラブルに見舞われてる方は一通り読むことをおすすめします。
データ基盤とかプロダクトの事をもっと気になる方へ
ABEJA Insight for Retailの技術スタックを公開します (2021年10月版)
こちらのTechblogに技術スタックが公開されておりますので、もっと興味が湧いてきた方はぜひ覗いてみてください!
お知らせ
現在ABEJAでは一緒にAIの社会実装を進める仲間を募集しています。
ABEJA Advent Calendar 2021 を読んで少しでもいいねとおもったら、まずはお話を聞きに来てください。
【現在募集中の職種】 はこちらから確認できます。ご応募をお待ちしております。