1. はじめに
理系用にグラフ作成のあれこれをまとめる。Spyder上でプログラムを実装した。個人的にSpyderが変数の中身を見やすかったりするのでおすすめしたい。
2. Excelからのデータ所得
任意のファイル(今回はtest.xlse)からpythonにデータをロードさせる。
# ライブラリの設定
import pandas as pd
# データロード
df = pd.read_excel("test.xlsx")
これでExcelからデータを所得できる。df内はこのようになっている。
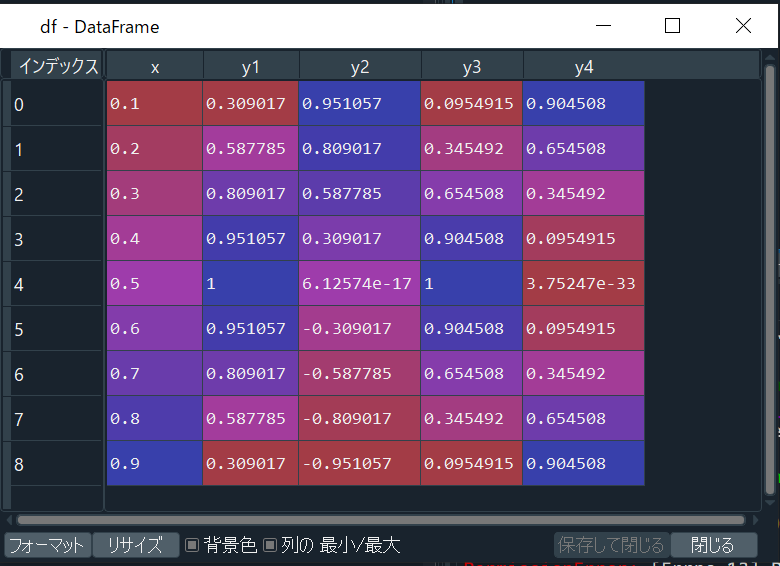
また元ファイルはこうなっている。
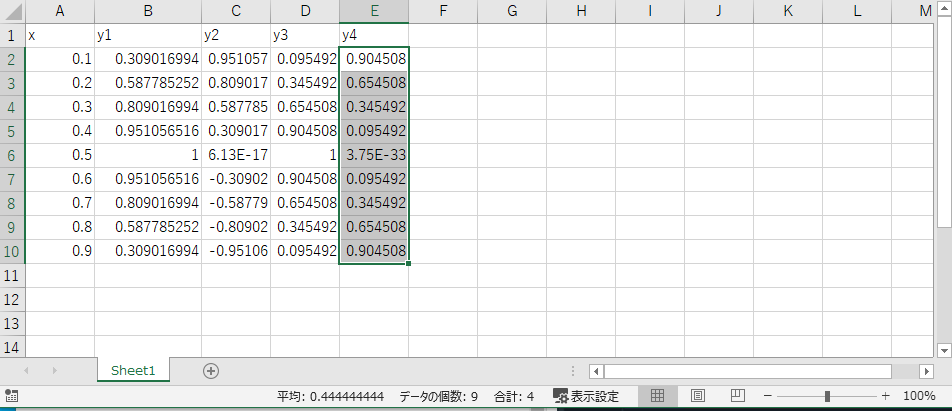
このとき、同じファイル内に両ファイルを置いておくことに注意する。(両ファイルを同じところにおかなくてもディレクトリを指定すれば可能)
3. グラフ化
3.1グラフの基本設定
一般的な理系のグラフを作成するために以下のようにグラフ全体の設定をしておく。
import matplotlib.pyplot as plt
# フォントをTimes New Romanに
plt.rcParams['font.family'] = 'Times New Roman'
# フォントサイズを20に
plt.rcParams["font.size"] = 20
# グラフの向きを内側に
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
また、
plt.savefig("任意の名前.png")
で同じファイルに保存できる。
3.2 グラフ一つ
x-y1でのグラフを作成する。
# データのインデックス
x = "x"
y = ["y"+str(i+1) for i in range(4)]
# y = [y1,y2,y3,y4]になる
# プロット
plt.scatter(df[x],df[y[0]],c="white",linewidths="1",edgecolors="red")
# plt.scatter(df.iloc[:,0],df.iloc[:,1],c="white",linewidths="1",edgecolors="red")でも可能
# df.ilocはdf.iloc[行数,列数]で指定する。
plt.xlabel("x")
plt.ylabel("y1")
plt.scatterではなく、plt.plot(df[x],df[y[0]])で折れ線グラフにできるのでデータ数が多いときはこちらを使う。これらのデータの描写方法を変えたいときはplt.scatterかplt.plotでggると細かく変えられる。
・logスケールで表したいとき
[matplotlib ログスケール表示とグリッド表示][link1]
[link1]:https://qiita.com/irs/items/cd1556c568887ff2bdd7
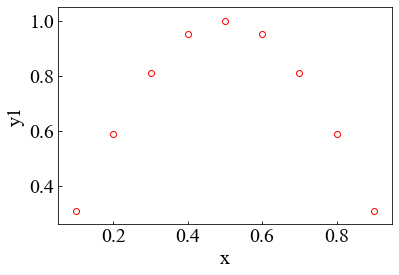
3.3 複数のグラフ
# (a)~(z)の名前リスト
abc = ["(" + chr(ord('a') + i) + ")" for i in range(26)]
# 全体のグラフの大きさ
plt.figure(figsize = (12,7))
for i in range(len(y)):
#中のグラフの位置決め
#subplot(縦に何個並べるか,横に何個並べるか,左上から1.2...としたときの位置)
plt.subplot(2,2,i+1)
#左上に(a)...を示す
plt.title(abc[i],loc="left")
plt.scatter(df[x],df[y[i]],c="white",linewidths="1",edgecolors="red")
#plt.scatter(df.iloc[:,0],df.iloc[:,i+1],c="white",linewidths="1",edgecolors="red")でも可能
plt.xlabel("x")
plt.ylabel(y[i])
# 万能コマンド 文字がかぶらないようにしてくれる
plt.tight_layout()
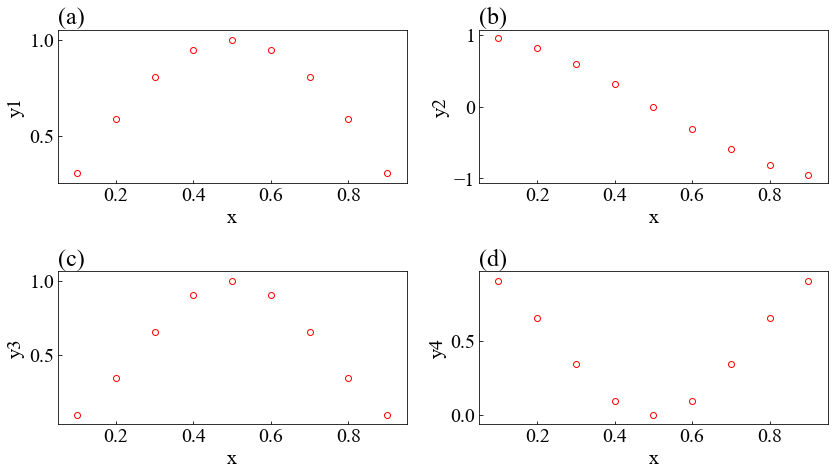
3.4 複数のデータを同じところに
# 色の指定
color = ["red","blue","green","purple","aqua"]
plt.figure()
for i in range(len(y)):
plt.plot(df[x],df[y[i]],c=color[i],label = y[i])
#plt.plot(df.iloc[:,0],df.iloc[:,i+1],c=color[i],label = y[i])でも可能
plt.ylabel(y[i])
plt.xlabel(x)
plt.legend(loc = "best",fontsize = 15)
3.5 豆知識
グラフの軸上に点をプロットする
plt.scatter(x,y,clip_on=False)
4 全部のコード
# ライブラリの設定
import pandas as pd
import matplotlib.pyplot as plt
# データロード
df = pd.read_excel("test.xlsx")
# 前設定
plt.rcParams['font.family'] = 'Times New Roman' #フォント一括
plt.rcParams["font.size"] = 20
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
# データのインデックス
x = "x"
y = ["y"+str(i+1) for i in range(4)]
# プロット
plt.scatter(df[x],df[y[0]],c="white",linewidths="1",edgecolors="red")
plt.xlabel("x")
plt.ylabel("y1")
# (a)~(z)の名前リスト
abc = ["(" + chr(ord('a') + i) + ")" for i in range(26)]
# 全体のグラフの大きさ
plt.figure(figsize = (12,7))
for i in range(len(y)):
#中のグラフの位置決め
#subplot(縦に何個並べるか,横に何個並べるか,左上から1.2...としたときの位置)
plt.subplot(2,2,i+1)
#左上に(a)...を示す
plt.title(abc[i],loc="left")
plt.scatter(df[x],df[y[i]],c="white",linewidths="1",edgecolors="red")
plt.xlabel("x")
plt.ylabel(y[i])
# 万能コマンド 文字がかぶらないようにしてくれる
plt.tight_layout()
# 色の指定
color = ["red","blue","green","purple","aqua"]
plt.figure()
for i in range(len(y)):
plt.plot(df[x],df[y[i]],c=color[i],label = y[i])
plt.ylabel("y")
plt.xlabel(x)
plt.legend(loc = "best",fontsize = 15)