🎯 背景
複数の店舗から届く売上データのフォーマットがバラバラで、
集計や分析の前に毎回「整形・確認・結合」といった前処理に時間がかかる――
そんな状況を想定して、実務で役立つETLパイプラインの構築に取り組みました。
支店や店舗単位で売上データが提出されるような業務(例:小売・飲食・フランチャイズ運営など)では、 形式の異なるCSVが毎月集まり、整形・集計に毎回工数がかかるケースがあると思います。
本ツールは、そうした 「バラバラな売上データを扱う実務現場」を想定して設計し、異なるCSVを統一→DBに格納→可視化まで一気通貫で行えるETLパイプラインを構築しました。
データエンジニアを志す中で、こうした「分析可能な形にデータを整える力」を強化したくて取り組んだプロジェクトです。
⏱ Before / After(改善効果)
| 項目 | Before(従来の業務) | After(本ツール使用後) |
|---|---|---|
| データ整形 | フォーマット確認・手作業で統一 |
normalize.pyで自動整形(5分未満) |
| 集計処理 | Excelで関数・ピボット | DB+SQLで自動抽出 |
| 可視化・共有 | スクショやExcelグラフ貼付 | Streamlitで即グラフ表示・共有可能 |
| 総作業時間 | 約1.5〜2時間 | 約10分以内に短縮 |
🛠 使用技術
- Python(pandas)
- SQLite
- Streamlit
- Altair
- Mermaid
今回は 軽量なSQLite + Streamlit を選定しています。
理由は、ローカルでもすぐ動かせるシンプルな構成であり、非エンジニアでも扱いやすく、「PoCや業務支援ツール」として実運用に近い形を模擬できるからです。
また、整形処理には pandas を活用し、将来的なクラウドDB連携(BigQuery等)も見据えた設計としています。
📁 構成図
ETLパイプライン全体の流れ
Streamlitアプリ内部の処理構造
📦 課題と解決策
| 課題 | 解決方法 |
|---|---|
| 列名の違い(Date vs 販売日) | normalize.pyで統一 |
| 商品名の表記ゆれ(Tシャツ, tshirt, シャツ) | 辞書で正規化 |
| 日付や数値の形式不統一 | pandas.to_datetimeで統一 |
| DB設計が曖昧 | schema.sqlで明示的に設計 |
📁 ディレクトリ構成
ec_sales_pipeline/
├── data/
│ ├── store_a_2025.csv
│ ├── store_b_2025.csv
├── scripts/
│ ├── etl.py
│ ├── normalize.py
├── db/
│ ├── schema.sql
│ └── sales.db
├── output/
│ └── reports/
├── README.md
├── requirements.txt
└── .gitignore
🧹データ整形:normalize.pyの例(列名統一・商品名正規化)
def normalize_file(filepath, store_name):
df = pd.read_csv(filepath, encoding='utf-8-sig', quotechar='"')
df.columns = [col.strip().lower() for col in df.columns]
col_map = {
'item': 'item_name', '商品名': 'item_name',
'date': 'sale_date', '売上日': 'sale_date',
'qty': 'quantity', '数量': 'quantity',
'price': 'unit_price', '単価': 'unit_price'
}
df = df.rename(columns=col_map)
df['item_name'] = df['item_name'].replace({
'tshirt': 'Tシャツ', 'シャツ': 'Tシャツ'
})
df['sale_date'] = pd.to_datetime(df['sale_date'], errors='coerce').dt.strftime('%Y-%m-%d')
df['store_name'] = store_name
return df[['sale_date', 'item_name', 'quantity', 'unit_price', 'store_name']]
🏗️ DB設計:schema.sql
CREATE TABLE stores (
id INTEGER PRIMARY KEY,
name TEXT
);
CREATE TABLE products (
id INTEGER PRIMARY KEY,
name TEXT
);
CREATE TABLE sales (
id INTEGER PRIMARY KEY AUTOINCREMENT,
sale_date TEXT,
store_id INTEGER,
product_id INTEGER,
quantity INTEGER,
unit_price INTEGER,
FOREIGN KEY (store_id) REFERENCES stores(id),
FOREIGN KEY (product_id) REFERENCES products(id)
);
🔍 分析例:月別売上推移
SELECT
strftime('%Y-%m', sale_date) AS month,
p.name AS product,
SUM(s.quantity * s.unit_price) AS total_sales
FROM sales s
JOIN products p ON s.product_id = p.id
GROUP BY month, product
ORDER BY month;
📺 Streamlitで売上データを可視化
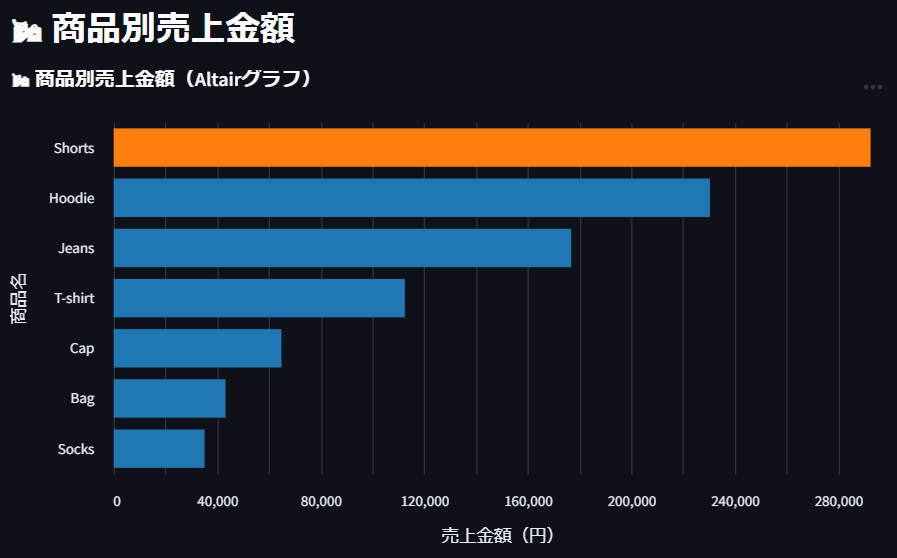
📷 アプリ画面(Altairグラフ) → 商品別の売上金額をランキング表示。Shortsの売上が突出していたことが視覚的にわかります。
https://animated-robot-x57764xpqq5h9pj9-8502.app.github.dev/
グラフから「Shorts」の売上が突出していたことが分かりました。
🧪 Altairコード例
import pandas as pd
import sqlite3
import altair as alt
import streamlit as st
st.title("📊 売上データビューア")
conn = sqlite3.connect("db/sales.db")
query = """
SELECT sale_date, item_name, quantity, unit_price, store_name
FROM sales_raw
"""
df = pd.read_sql_query(query, conn)
df["売上"] = df["quantity"] * df["unit_price"]
st.dataframe(df)
summary = df.groupby("item_name", as_index=False)["売上"].sum()
chart = alt.Chart(summary).mark_bar().encode(
x=alt.X("売上:Q", title="売上金額(円)"),
y=alt.Y("item_name:N", sort='-x', title="商品名"),
color=alt.condition(
alt.datum.item_name == "Shorts", alt.value("orange"), alt.value("steelblue")
)
).properties(title="商品別売上金額(Altairグラフ)")
st.altair_chart(chart, use_container_width=True)
🧵 学び・工夫・今後の展望
- GitHub Actions を活用して、定期的にデータ整形・更新処理を自動実行したい(例:週1でCSV更新&Web再生成)
- SQLiteの代わりに PostgreSQLやBigQuery に対応することで、クラウド連携・データ量拡張にも対応
- アプリの汎用性を高めるため、複数商品カテゴリへの対応、売上比率の円グラフ化なども計画中
今後は GitHub Actions による定期実行や BigQuery対応などを通じて、
「業務の中で本当に使えるデータ整備」の土台づくりを強化していきたいです。
🔗 GitHubリポジトリ
👉 https://github.com/flopsy212/Sales-etl-streamlit