https://qiita.com/floatnflow/items/6d723739e7ed0221a3d2
Nintendo Switchから投稿された動画に自分を探す(2/4)の続きです。
テッセラクトはイカの文字を見るか
切り出した画像を早速認識させてみます。
| 元画像 | 認識結果 |
|---|---|
 |
ヨ iU:i は 水 |
うーん、これは疲れている人ならここで挫折してもおかしくないレベル。
念のため他の文字も見てみましょう。(お名前お借りします。)
| 元画像 | 認識結果 |
|---|---|
 |
⑪E は 浩 |
 |
ぽ -C し ゃ く ⑧ た お し E |
 |
ゆ ⑤⑧ た お LEI |
 |
ま ⑧ と ⑧ た お し E |
 |
TGKN&E お LEI |
 |
り E コ バ - コ J⑧ た お し E |
 |
ね ⑤ る ね る ね る ぉ み ①⑧ お し E |
 |
bttLG②00 i 水0d |
む! 少しおかしいのもあるけど、読み取れている文字もちらほら。あまりにおかしいのは図と地を誤認識している可能性がありますね。ということで反転してみる。
| 元画像 | 認識結果 |
|---|---|
 |
た U せ U&E お し E |
はるかにまともになったので、おそらく予想通り。ただ、反転しなくても読み取れているものもあり、ここら辺の違いは不明。
誤認識の傾向を見ると、次のようなパターンが多いです。
| 文字 | 誤認識 |
|---|---|
| を | ⑧、& |
| し | L |
| た | E |
| い | U |
| ! | I、認識せず |
若干クセの強いフォントだしほとんど認識しないだろうと予想していたので、思ったより頑張っている印象です。
テッセラクトはイカの文字を学ぶか
表示に使われているフォントを使って学習させればもう少しは改善するはずです。学習といえば普通はそれなりに大量の訓練データが必要になるイメージですが、フォントが1個と決まっているのなら1文字につき1回の学習でもそこそこの精度が期待できるのではないか? という甘い見通しで進んでみましょう。
ということでフォントを入手。込み入った方法でもいいんですが、今回は漢字はいらない(名前に漢字は使えない)のでこちらのフォントでも、このクオリティならおそらく十分でしょう。
Splatfont 2
http://downloads.paperyoshi.at/product/splatfont-2/
さて、https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00 によれば、学習の概要は、
- トレーニングテキストを用意する。
- テキストをimage+boxファイルに書き出す。
- unicharsetファイルを作成する。
- unicharsetと辞書データからスターター学習済みファイルを作成する。
- tesseractを実行し、トレーニングデータセットを作成する。
- トレーニングデータセットで学習を実行する。
- データファイルを結合する。
などと書いてありますが、手探りでやっていきます。
Tesseract-OCRがインストールされたフォルダに text2image.exe があるのでこれを実行するとエラーが出たりしながら fonts.conf というファイルが生成されました。
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<dir>C:\Windows\Fonts</dir>
<cachedir>.</cachedir>
<config></config>
</fontconfig>
名前に使われる文字を書いたファイルを chars.txt として UTF-8 で保存し、次を実行します。(Splatfont 2を入れた場合はフォント指定を適宜変更)
text2image --fonts_dir C:\Windows\Fonts --text chars.txt --outputbase Splatoon2 --fontconfig_tmpdir . --font Splatoon2 --ptsize 24
すると、カレントディレクトリに Splatoon2.tif と Splatoon2.box というファイルが生成されます。tifファイルは chars.txt に書かれた文字がSplaton2フォントでレンダリングされた画像ファイル、boxファイルはtif画像内の文字の位置と対応する文字の情報が出力されています。これでたぶん、
- トレーニングテキストを用意する。
- テキストをimage+boxファイルに書き出す。
ができましたが、この先がよくわかりません。tesstrain.sh を実行するみたいなことが書いてあるのでもしかするとlinuxでの作業前提っぽいです。Windowsだとどうすればいいのか途方にくれました。4.0.0のWindows用学習ツールは移植されていないという話もあります。
試しに jTessBoxEditor というツールを使ってみましょう。
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
から、jTessBoxEditor-2.2.0.zip をダウンロードし、展開。(実行にはJRE8以上の環境が必要)
readmeを見ると、"LSTM Training for Tesseract 4.0x is not supported." とありますね。4.0には新規搭載のLSTM以外にLegacyなエンジンを積んでいるようなので、もしかしたらいけるかも知れません。
展開したフォルダの train.bat を実行すると以下のようなアプリケーションが起動します。
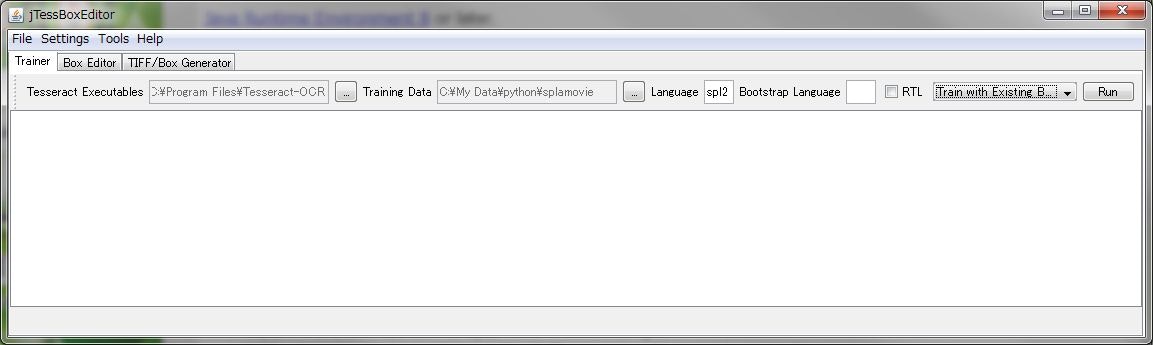
- [Trainer] タブで、Tesseract Executablesに C:\Program Files\Tesseract-OCR\tesseract.exe を指定。
- Language に spl2 を設定。
- Training Data に slatoon2.tif を指定。
- Training Mode に Train with Existing Box を指定。
- Run を実行。
ログが表示され、うまくいけばTraining Dataに指定したフォルダ(?)に spl2.* というファイルがいろいろ生成されるはずです。
C:\"Program Files"\Tesseract-OCR\combine_tessdata.exe spl2.
を実行(最後の.に注意)すると spl2.traineddata が生成されるので、期待にwkwkしながら C:\Program Files\Tesseract-OCR\tessdata にコピーします。
それでは学習データを使ってもう一度文字認識をやってみましょう。image_to_text()のlangに設定していたjpnをspl2に変更します。
| 元画像 | jpnで認識 | spl2で認識 |
|---|---|---|
|
ヨ iU:i は 水 | たいせぃをたおした! |
|
⑪E は 浩 | KAlをたおした! |
|
ぽ -C し ゃ く ⑧ た お し E | ぽ-じしゃくをたおした! |
|
ゆ ⑤⑧ た お LEI | ゆうをたおした! |
|
ま ⑧ と ⑧ た お し E | まさとをたおした| |
|
TGKN&E お LEI | TAKAをたおした| |
|
り E コ バ - コ J⑧ た お し E | ケビン ベーコンをたおした! |
|
ね ⑤ る ね る ね る ぉ み ①⑧ お し E | わるわるわるわ※にたおした! |
|
bttLG②00 i 水0d | ペちゃこ(ーωー`)をたおした| |
キター!
正答率が一気に高まりました。そして「をたおした」をかなり高い率で認識しているのは大きいです。対象がキル表示である、そしてその左側がプレイヤー名であると判定できるからです。
若干の誤答もありますが、実用レベルに近づきました。もう少し正答率を上げるために画像の調整をしてみましょう。
長くなったので続きます。次が最後でしょう。(^^;
続きはこちら。>https://qiita.com/floatnflow/items/bd3b291957982e10066e