ここんとこなんかいろいろあって、最近はゴミ記事が増えて目的の記事を探すのが大変になった、とかいう意見も散見したけど、なに言ってんだネットなんてとっくの昔からノイズだらけだ、検索スキル磨けや、としか思わなかったので皆さんも気にせずどんどん書きましょうね。
さて、前回(3/4)
https://qiita.com/floatnflow/items/d0accb0689a51b8b01b0
の続き。
OpenCVはイカの文字を読みやすくするか
文字認識の正答率を高めるために画像処理をしようという話。画面から切り出した文字をいかに学習データ(フォントでのレンダリング画像)に近づけるか、ということになると思われます。
使えそうなアルゴリズムは悠久の昔から先人の皆さんがいろいろと考えてくれてましてですね、今回少し勉強してみましたがなかなか感心してしまいますね。何気なく使っていたアンシャープマスクって、そんなタコが自分の足食ってるような原理でいいのか!とか。また、画像処理の多くは行列に対する演算処理なので、OpenCVが画像をndarrayで扱っているのも非常に理にかなっています。
試したのは、
| 画像 | 処理 | 関連するOpenCV関数 |
|---|---|---|
 |
オリジナル | - |
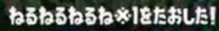 |
平準化 (blur) | cv2.GaussianBlur() 等 |
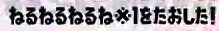 |
反転 (invert) | cv2.bitwise_not() |
 |
グレイスケール | cv2.cvtColor() |
 |
コントラスト | cv2.LUT() |
 |
先鋭化 (unsharp mask) | cv2.addWeighted() |
 |
侵食 (erotion) | cv2.erode() |
 |
拡張 (dilation) | cv2.dilate() |
 |
二値化 | cv2.threshold() |
組合せやパラメータで認識結果がころころ変わるので、簡単なアプリ
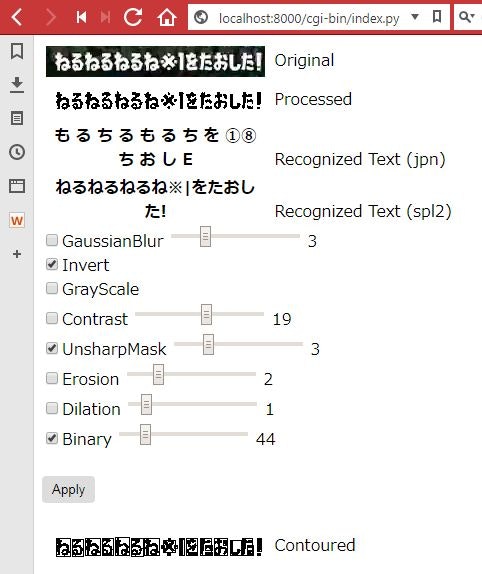
を作っていろいろと試してみましたが、なかなか全体を最適化するのは難しいですね。あちらを立てればこちらが立たずのような。
なので結果的にこの工程はあまり意味なかったです。
終わりに
ということで、「運がよければ自分がやられたときの動画なら見つかるかもね」くらいのアプリケーションになりました。誤認識されやすい文字をそんなに使っていなければかなり正確に検出してくれますが、そもそも自分を倒したプレイヤーがその瞬間を含む動画をどれくらいアップしてるのかっつー話ですよ。
OpenCVやTesseractはなかなか素晴らしいツールです。Tesseract4.0のLSTMはどんくらい精度が上がってるのか楽しみですね。
私はサーバを持っていないので今回のアプリケーションを公開する予定はありませんが、もし公開するなら毎度OAuthで各自に検索させるのは非常に無駄が多いので、定期的にデータを収集してTweetのIDと認識したプレイヤー名のリストをDBに保存し、それに対する検索(あいまいオプション付き)という実装がいいでしょうね。
それにしてもいい加減月ごとのルールとステージ固定やめてくれないもんかな。
(了)