databricksの標準ファイルフォーマットであるdeltaにはtime travelなる機能があり、この機能を使うと過去のバージョンのデータにアクセスできる。このdelta形式は実はhiveメタストアにも使われているので、hiveメタストアに保存されたテーブルにもtime travelは使える。しかし、やや面倒な方法をとる必要があるため、備忘録的に書いておく。なおtime travel機能については下記を参考のこと。
https://www.databricks.com/jp/blog/2019/02/04/introducing-delta-time-travel-for-large-scale-data-lakes.html
hiveメタストア上のテーブルのフォーマットを確認してみる
とりあえず下準備としてsklearn.datasetsのbreast_cancerを使って、hiveメタストアにデータを保存してみる。
import pandas as pd
from sklearn import datasets
breast_cancer_data = datasets.load_breast_cancer()
breast_cancer_df = pd.DataFrame(
breast_cancer_data.data,
columns = breast_cancer_data.feature_names
)
breast_cancer_df.columns = [col.replace(' ', '_') for col in breast_cancer_df.columns]
cols = list(breast_cancer_df.columns)
# spark DataFrameに変換
breast_cancer_df['target'] = breast_cancer_data.target
breast_cancer_sdf = spark.createDataFrame(breast_cancer_df)
# hiveメタストアにテーブルを保存
breast_cancer_sdf.write.saveAsTable('default.breast_cancer')
ここでdefaultデータベースに保存されたテーブルbreast_cancerのデータフォーマットを確認してみよう。
display(spark.sql('DESCRIBE DETAIL default.breast_cancer'))
実行結果は以下のとおり。
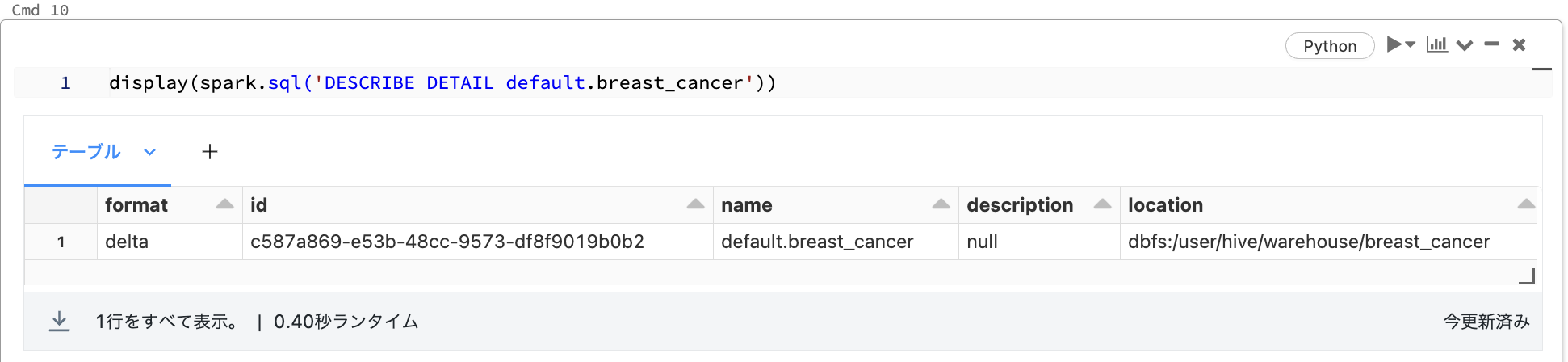
format列の値がdeltaになっていることが分かる。さてdeltaのtime travelで過去バージョンにアクセスするには、hiveメタストアに保存されたテーブルのファイルパスが必要になる。ファイルパスはこの結果のlocation列の値になる。
実際にtime travelしてみる
ではbreast_cancerからtarget列を削除してhiveメタストア上のテーブルを上書き保存してみる。
breast_cancer_sdf = breast_cancer_sdf.drop('target')
# hiveメタストアに上書き保存
(breast_cancer_sdf
.write
.mode('overwrite')
.option('overwriteSchema','true')
.saveAsTable('default.breast_cancer')
)
ついでにバージョン履歴も確認しておく
display(spark.sql('DESCRIBE HISTORY default.breast_cancer'))
結果は以下のとおり。hiveメタストアもバージョン管理されていることがわかる。
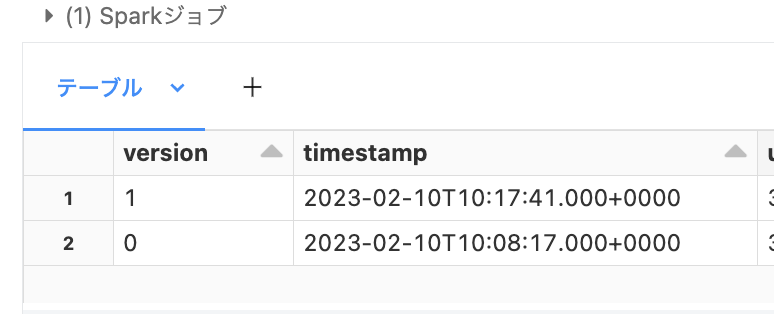
繰り返しになるがtime travelにはデータのファイルパスが必要になるため、DESCRIBE DETAILで取得する。
location = (spark
.sql('DESCRIBE DETAIL default.breast_cancer')
.select('location')
.collect()[0][0]
)
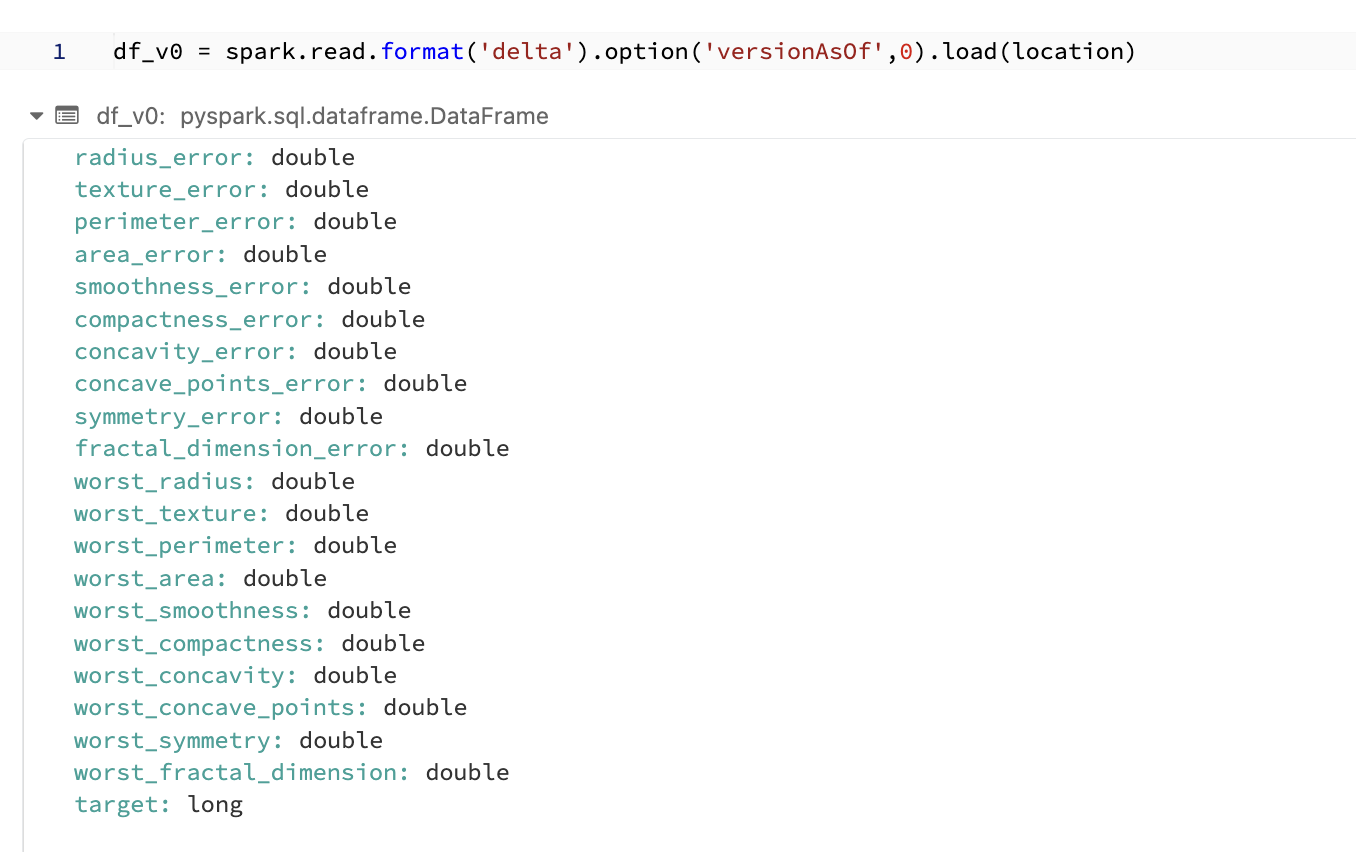
# version 0のテーブルを読み込む
df_v0 = spark.read.format('delta').option('versionAsOf',0).load(location)
結果は以下のとおり、target列が存在しているので、列を削除前のバージョンを復元できていることがわかる
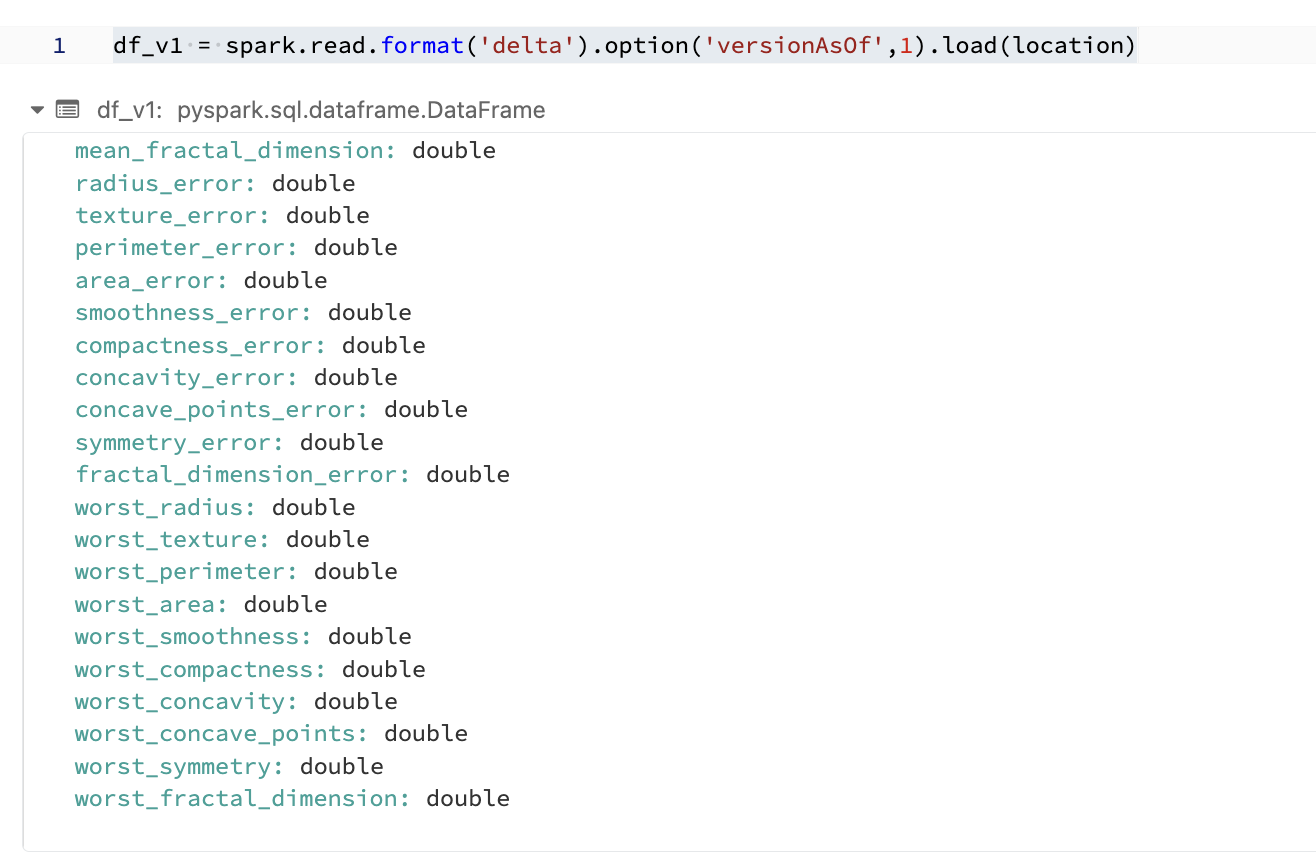
一応バージョン1の結果も載せてみる。当然だがtarget列は存在しない。
df_v1 = spark.read.format('delta').option('versionAsOf',1).load(location)
なおtime travelで遡れる期間はデフォルトで30日なので、それ以上長い期間のバージョンを保持する場合は別途設定が必要な点に注意が必要。