概要
はじめまして、ふきです!
この記事では 最近使い始めたGPUサーバーを気軽に借りられるサービスの "RunPod Serverless" の基本的な使い方を解説します。
この記事を読むと、以下のことができるようになります。
- RunPod Serverlessの理解
- RunPodアカウントの作成
- Serverless Endpointの作成
- Hugging Faceのモデルを使った推論環境の準備
- API経由で推論実行
自前でGPUを用意しなくても、数十~数百円のコストで動画生成や画像生成といったローカルLLMをお試し実行できるようになります! あのSulphur 2も試せます
自分の場合は、RunPod Serverlessを使って、Wan2.2で1動画あたり3円かからず生成するなどしています。
本記事では細かい最適化は扱いません。まずはRunPod上でローカルLLMを動かすことを目標とします。
RunPodとは
RunPodは、AIモデルの学習や推論を行うためのGPUクラウドサービスです。
一般的なクラウドサービスでは、GPUインスタンスの構築や環境設定を自分でする必要がありますが、RunPodでは比較的少ない設定でGPUを利用できます。秒単位の課金でサクサク生成できるので、ローカルLLMを試しやすくておすすめです。
主な利用方法は次の2つです。
- Pod:常時起動するGPUインスタンス
- Serverless:必要なときだけ起動するGPUインスタンス(AWS Lambdaみたいなの)
今回は、より手軽に使える Serverless の方を利用します。
Serverlessとは
Serverlessは、必要なタイミングだけGPUを起動し、処理が終わると自動停止するインスタンス上でLLMを動かせるサービスです。常時GPUを起動する必要がないため、推論用途ではコストを抑えやすい特徴があります。
ちなみに動画生成も快適にできるA100などのハイエンドGPUは、1秒あたり約0.1円前後のコストです。
Serverlessでは、Endpointにリクエストを送信するとRunPod側が必要なWorkerを起動し、自動的に処理を実行します。
RunPod Serverlessを使う最大の利点
RunPodのServerlessには Model Cache という機能があります。これは、Hugging Faceのモデルリポジトリを指定することで、従量課金時間外にそのモデルをダウンロードし、キャッシュしておける機能です。
この機能のおかげで、イメージにモデルを焼きこんだり、モデルのダウンロード時間にお金を払ったりせずに済みます。公式ドキュメントにも「モデルのダウンロード中はワーカー時間の課金は発生しない(You aren't billed for worker time while your model is being downloaded)」と明記されています。
ただ、ちょっと癖があり、注意が必要です。公式仕様として以下を押さえておきましょう。
- 1エンドポイントにつきキャッシュできるモデルは1つだけ
- リポジトリに複数の量子化バージョンが含まれていると、すべてDLされる
- ゲート(利用申請制)モデルは Hugging Face のアクセストークンが必要
- キャッシュは
/runpod-volume/huggingface-cache/hub/に展開される
では、実際に動かすための手順を紹介していきます。
0. 事前準備
RunPodアカウントを作成
RunPodアカウントを作成します。無料枠はないため、最初に最低金額($10)のチャージが必要です。
下記招待リンクからアカウント登録をすると、お互いに$5分のクレジットが付与されます。自分もうれしいので、よかったら下記URLから"Sing Up"をお願いします!
アカウント作成後はAPIキーも発行しておきます。

Settings
↓
API Keys
↓
Create API Key
発行したキーは後で Authorization: Bearer <APIキー> の形でリクエストに使うので控えておきましょう。
1. 推論ロジックを準備する
推論ロジック自体は、使用したいHugging FaceのモデルのページをClaude Codeに渡して、実装を頼めば大体いけます。 コスト最適化はされないですが…
Serverlessでは推論ロジックをコンテナイメージとして登録します。方法は大きく2種類あります。
1. GitHub連携を利用する
GitHubリポジトリを直接連携してデプロイできます。Dockerfileを用意すれば、リモートにプッシュしたタイミングでRunPod側のビルドが開始します。ビルドが完了すると、起動中のワーカーたちが新しいイメージに順次切り替わっていきます。
すごく手軽なので、こちらの方法をおすすめします!
2. ビルド済みイメージを利用する
最も自由度が高い方法です。イメージにモデルを焼きこみたいときは、自前でイメージをビルドする必要があります。
また、公式テンプレートのPublicイメージも公開されているので、それを使うこともできます。
LLMを「とりあえず動かす」だけなら、公式の runpod-workers/worker-vllm を使うのが最短です。
2. Endpointを作成する
RunPodコンソールからServerless Endpointを作成します。
Serverless
↓
New Endpoint
↓
Custom Deployment
↓
Deploy from Docker registry or a template
↓
Model
左メニューの Serverless から New Endpoint で作成。
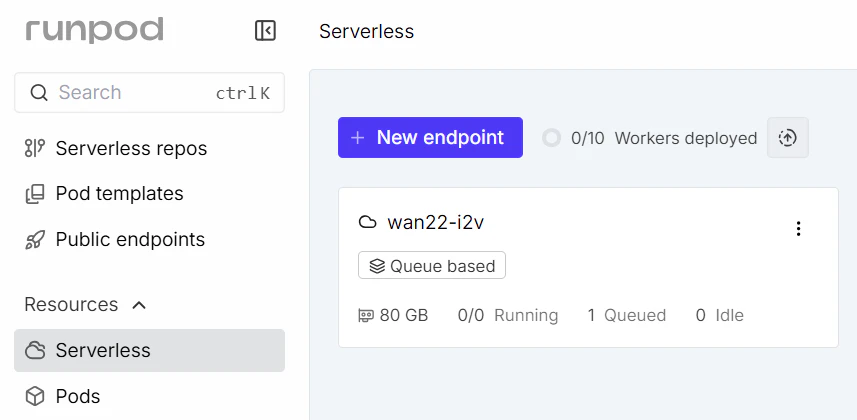
Custom deployment を選んで
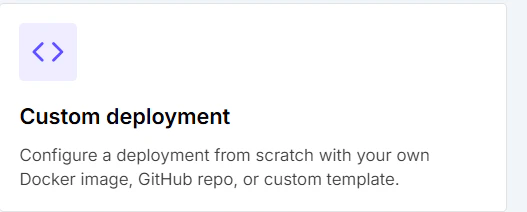
Deploy from Docker registry or a template で、作成したイメージを指定します。
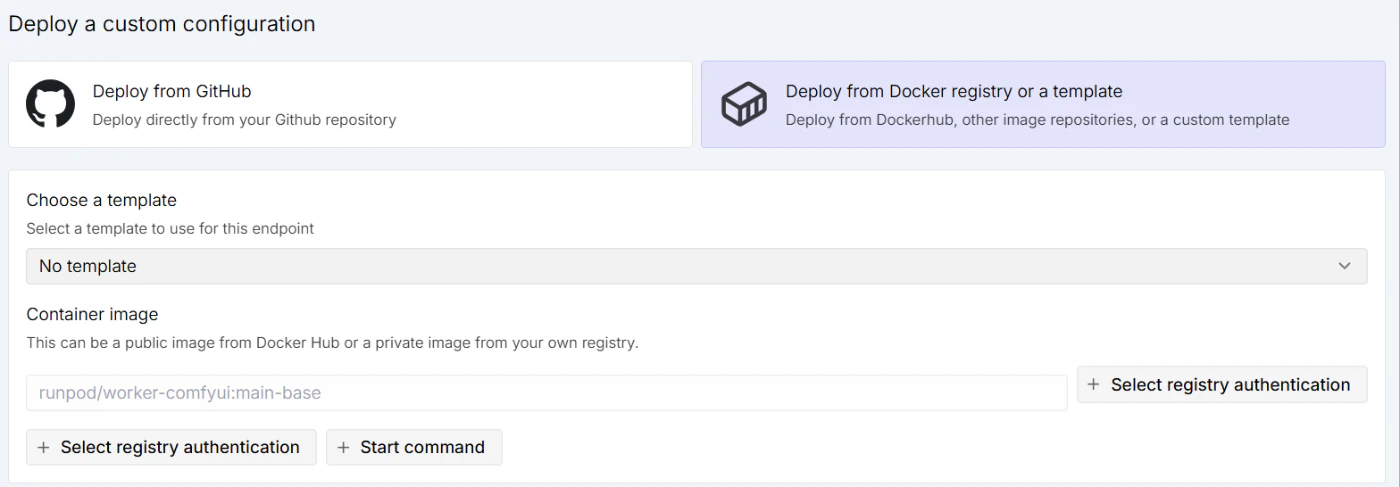
少し下に行って、Model を指定しましょう。

ここが前述の Model Cache の設定です。Model フィールドに Hugging Face のリポジトリパスを入れるだけ。例えば軽量LLMなら以下のように指定します。
Qwen/Qwen2.5-7B-Instruct
ゲートモデルの場合はここで Hugging Face のアクセストークンも入力します。
GPUや環境変数などの他の設定は、目的や実装に応じて変更してください。
設定項目の例
- GPU:H100
- Max Workers:1
- Active Workers:0
- Idle Timeout:1秒
Active Workersは常時課金状態のワーカーの数なので、0にしておきましょう。個人利用ならば Idle Timeout は最小値の1秒でよいと思います。
Idle Timeout とは、モデルをVRAMにロードした状態のインスタンスを保持しておく時間のことです。後述のとおりVRAMロードは課金対象なので、巨大モデルを高頻度で叩く場合は、少し長めにして使い回した方が安くなることもありますが、個人利用の場合は無駄なコストになります。
3. 最初の推論を試す
Endpoint作成後、API URLが発行されます。リクエストは「最上位に input キーを持つJSON」が基本形です。input の中身は、ワーカーのハンドラが受け取るパラメータになります。
非同期実行(/run)の例:
curl -X POST \
https://api.runpod.ai/v2/{ENDPOINT_ID}/run \
-H "Authorization: Bearer {API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"input": {
"prompt": "ねこについて一句よんで"
}
}'
/run はジョブを受け付けると、すぐにジョブIDを返します。
{
"id": "eaebd6e7-6a92-4bb8-a911-f996ac5ea99d",
"status": "IN_QUEUE"
}
返ってきた id を使って /status をポーリングし、完了を待ちます。
curl https://api.runpod.ai/v2/{ENDPOINT_ID}/status/{JOB_ID} \
-H "Authorization: Bearer {API_KEY}"
完了すると status が COMPLETED になり、output に結果が入ります(output の中身はワーカーの実装によって変わります)。
{
"id": "60902e6c-08a1-426e-9cb9-9eaec90f5e2b-u1",
"status": "COMPLETED",
"delayTime": 31618,
"executionTime": 1437,
"output": {
"result": "..."
}
}
status には次の値が入ります。
| status | 意味 |
|---|---|
IN_QUEUE |
キューで待機中 |
IN_PROGRESS |
実行中 |
COMPLETED |
正常終了(output あり) |
FAILED |
エラー |
CANCELLED |
キャンセル済み |
TIMED_OUT |
タイムアウト |
短い処理なら
/runの代わりに/runsyncを使うと、完了までブロックして結果を直接返してくれます。なお非同期ジョブの結果は完了後30分間だけ取得可能です。
Pythonでまとめると、最小のクライアントはこんな感じです。
import requests, time
EP = "{ENDPOINT_ID}"
KEY = "{API_KEY}"
H = {"Authorization": f"Bearer {KEY}", "Content-Type": "application/json"}
# 1. ジョブを投げる
jid = requests.post(
f"https://api.runpod.ai/v2/{EP}/run",
headers=H,
json={"input": {"prompt": "ねこについて一句よんで"}},
).json()["id"]
# 2. 完了までポーリング
while True:
s = requests.get(f"https://api.runpod.ai/v2/{EP}/status/{jid}", headers=H).json()
if s["status"] in ("COMPLETED", "FAILED", "CANCELLED", "TIMED_OUT"):
break
time.sleep(2)
print(s["status"], s.get("output"))
設定と実行方法については以上です!
あとは、HuggingFaceからお好みのモデルを見つけて、煮るなり焼くなり好きにして下さい
まとめ
今回は、RunPod Serverlessの基本的な使い方を紹介しました。GPUサーバー管理を意識せずにHugging Faceのモデルを利用できます。
これでいろいろ捗りますね??
ただし、使ってみて動かなかったり、試行錯誤や推論に時間がかかってコストがかさんでしまうことがよくあります。コスト最適化のお話は、別途記事を出す予定です。
(追記)出しました!
最後まで読んでいただき、ありがとうございました!