はじめに
以前、ExcelファイルをSnowflakeに取り込む方法について記載しました。
今度はそのPDF版です。
同じテーマでこちらのイベントで登壇してきたのですが、そのブログ版といった感じです。
PDFといえば、なんらかのレポート、データとかある程度まとまった文書になっていて、分析に使えそうなデータも眠っていそうな感じがしますよね(?)。
Snowflake上でPythonを使えば、PDFからのデータの抜き出し・整形・DBテーブルに格納の一連の流れを楽に実現できます。一度データベースに入ってしまえば用途が広がります。
PDFをデータのサイロかから救う...というと大袈裟かもですが、それを実現するための第一歩的な内容として、ここではPDFからデータを抜き出してSnowflakeに格納する方法をまとめてみます。
作ったもの
順を追って書いていきます。
ハンズオン的にも実施できます。
今回扱うPDF
こちらのPDFを対象としてみました。
- 総務省統計局 - 地域メッシュ統計
このPDFの14ページ目にある表データを抜き出してみました。

セットアップ
前提としてお試しできるSnowflakeアカウントとユーザーがあるものとします。
-
SQLワークシートで以下の準備をします。
-- デフォルトのWAREHOUSEを使う想定 use role accountadmin; grant usage on warehouse compute_wh to role sysadmin; -- お試し用。名前を変えたい場合は適宜変更。 use role sysadmin; create database test_db; create schema test_db.test_schema; create stage test_db.test_schema.test_stage; -
こちらのPDFをダウンロードします。
-
ダウンロードしたPDFを作成したステージ(test_db.test_schema.test_stage)に格納します。
なお、ここではSYSADMINの権限でアップロードするように注意してください。
ついでにステージの画面で「Enable Directory Table」をクリックして有効化しておきます。
-
一応SQLシートからもステージに格納されていることを確認できるか見ておきます。
list @test_db.test_schema.test_stage;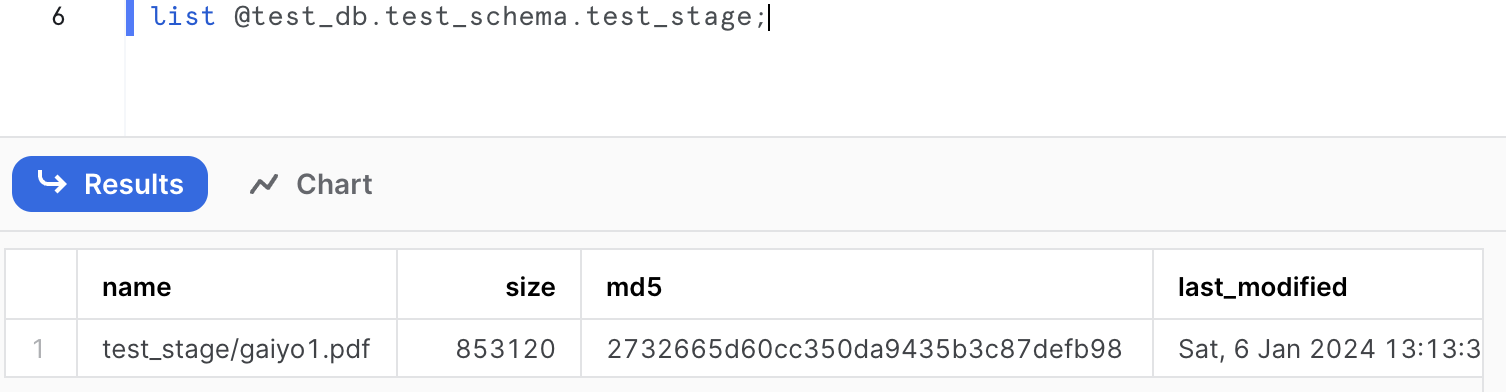
コードの実装
Pythonワークシートを使います。
-
ワークシートを設定します。
- ROLE : SYSADMIN
- WAREHOUSE : COMPUTE_WH
- 作成したDB、スキーマ(TEST_DB, TEST_SCHEMA)を選択
- Settings - Return type を Table() に変更
- Packages - Anaconda Packages より「pypdfium2」を検索して選択する
-
以下のようなコードを作ってみました。そのまま貼り付けてもらってお試しできます。
コード全体
import snowflake.snowpark as snowpark import pypdfium2 as pdfium import pandas as pd import re import sys import io # Outputに日本語を表示できるようにする (https://www.curict.com/item/c7/c7eaca3.html) sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8') def get_table_data(line): parts = line.split() # 都道府県名の抽出 prefecture_name_parts = [] for part in parts: prefecture_name_parts.append(part) if part[-1] in ['都', '道', '府', '県']: if ''.join(prefecture_name_parts) == '京都' and parts[parts.index(part)+1] == '府': prefecture_name_parts.append(parts[parts.index(part)+1]) break else: break prefecture_name = ''.join(prefecture_name_parts) # 県庁所在地の抽出 city_name_parts = [] for part in parts[len(prefecture_name_parts):]: city_name_parts.append(part) if part[-1] in ['市', '区']: break city_name = ''.join(city_name_parts) # メッシュコードの抽出 mesh_code_pattern = r"\d+-\d+-\d+" mesh_code_match = re.search(mesh_code_pattern, line) mesh_code = mesh_code_match.group() if mesh_code_match else None # 座標の抽出 coordinates_pattern = r"\d+°\d+′\d+″" coordinates_matches = re.findall(coordinates_pattern, line) latitude = coordinates_matches[0] if len(coordinates_matches) > 0 else None longitude = coordinates_matches[1] if len(coordinates_matches) > 1 else None return prefecture_name, city_name, mesh_code, latitude, longitude def main(session: snowpark.Session): """ PDFのデータを抜き出してテーブルに書き込む 対象PDF : <https://www.stat.go.jp/data/mesh/pdf/gaiyo1.pdf> """ table_name = 'TEST_DB.TEST_SCHEMA.TEST_TABLE' # 読み込みたいPDFの情報 stage_name = "TEST_DB.TEST_SCHEMA.TEST_STAGE" file_name = "gaiyo1.pdf" pdf_page_num = 13 skip_from_start = 6 skip_from_end = 5 load_dir = "/tmp" # 処理内でファイルを扱えるように、ステージからファイルを取得する session.file.get(f"@{stage_name}/{file_name}", load_dir) # PDFを読み込む (https://pypdfium2.readthedocs.io/en/stable/index.html) pdf = pdfium.PdfDocument(f"{load_dir}/{file_name}") pdf_pages = len(pdf) page = pdf[pdf_page_num] width, height = page.get_size() textpage = page.get_textpage() text_all = textpage.get_text_range() lines = text_all.splitlines() print(f"totale_pages={pdf_pages}, read_page={pdf_page_num+1}, {width=}, {height=}") print(f"{len(text_all)=}") print(f"{len(lines)=}") message = " ORIGINAL PDF TEXT " print("-"*15 + message + "-"*15) print(text_all) print("-"*(30+len(message))) print() header = skip_from_start footer = len(lines)-skip_from_end prefecture_list = [] city_list = [] mesh_list = [] latitude_list = [] longitude_list = [] for i, line in enumerate(lines): if header < i < footer: if line: prefecture_name, city_name, mesh_code, latitude, longitude = get_table_data(line) print(f"{i=}, 都道府県名: {prefecture_name}, 県庁所在地: {city_name}, メッシュコード: {mesh_code}, 緯度: {latitude}, 経度: {longitude}") prefecture_list.extend([prefecture_name]) city_list.extend([city_name]) mesh_list.extend([mesh_code]) latitude_list.extend([latitude]) longitude_list.extend([longitude]) df = session.create_dataframe( pd.DataFrame( { "PREFECTURE_NAME" : prefecture_list, "CITY_NAME" : city_list, "MESH_CODE" : mesh_list, "LATITUDE" : latitude_list, "LONGITUDE" : longitude_list } ) ) df.write.mode("overwrite").save_as_table(table_name) df.show() return df
このコードを作るにあたっては、事前にターゲットとなるPDFを読み込めるように諸々試行錯誤を重ねております。
- 何ページ目を読むか
- そのページのどこが取り込みたいデータか (読み込まない前後の行をカットしたいので)
- 表を取り込むので、その表の構成、中身のデータを確認
- 表を1行ごとに分解してforで回せるようにリスト化
- 必要な列、文字列を抜粋して取り込むので文字列加工方法を検討
- etc...
ここは泥臭い作業になりますが、読み込みたいPDFに合わせてカスタマイズが必要になってくる部分です。
これはターゲットがExcelでも同じですね。
取り込んでみる
Pythonワークシートを実行します。
なお、実行前に、Snowflakeアカウント上でAnacondaを有効化しておいてください。
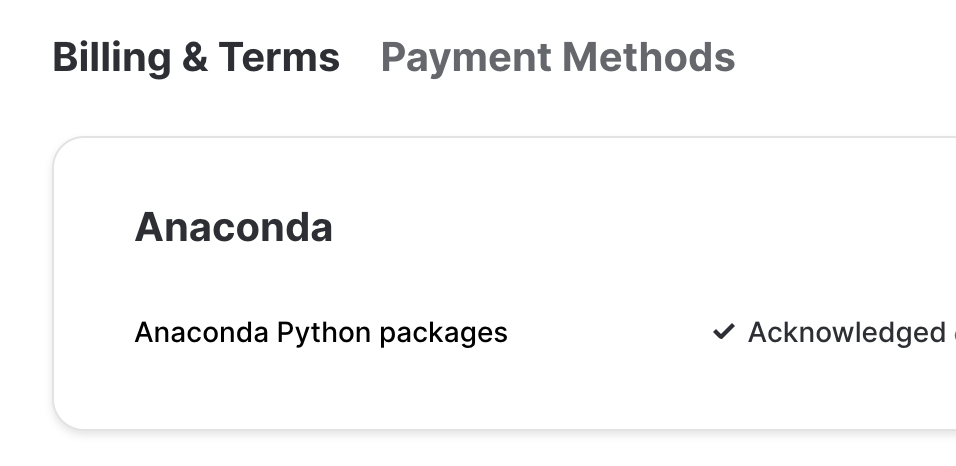
これをしておかないと、実行時に以下のように怒られてしまいます。
Anaconda terms must be accepted by ORGADMIN to use Anaconda 3rd party packages. Please follow the instructions at https://docs.snowflake.com/en/developer-guide/udf/python/udf-python-packages.html#using-third-party-packages-from-anaconda.
Anacondaが有効になっている前提で実行します。(Runボタンを押す。)
実行結果
こんな感じになります。

いい感じにデータがテーブルに入りました。
また、デバッグプリントもある程度入れているので、「Output」タブから抜き出したり整形する前の文字列とかも確認できます。

SQLワークシートから、SQLが実行できるか確認しておきます。
use role sysadmin;
use warehouse compute_wh;
use database test_db;
use schema test_schema;
select mesh_code
from test_table
where prefecture_name='沖縄県';

実装内容
今回の実装内容から部分的に見ていきます。
PDFの読み込み
import pypdfium2 as pdfium
PDFを読むために使いました。
ググると特に日本語での情報(実装事例)があまり出てこなかったのですが、使ってみてうまくいったのでよかったです。
公式ドキュメントを参考に、デバッグ出力も兼ねて諸々情報を取ってみてます。
pdf = pdfium.PdfDocument(f"{load_dir}/{file_name}")
pdf_pages = len(pdf)
page = pdf[pdf_page_num]
width, height = page.get_size()
textpage = page.get_textpage()
text_all = textpage.get_text_range()
lines = text_all.splitlines()
print(f"totale_pages={pdf_pages}, read_page={pdf_page_num+1}, {width=}, {height=}")
print(f"{len(text_all)=}")
print(f"{len(lines)=}")
message = " ORIGINAL PDF TEXT "
print("-"*15 + message + "-"*15)
print(text_all)
print("-"*(30+len(message)))
print()
ページ番号は0からカウントされる、PDFリーダーで見た時に14ページ目は13として指定します。
PDFの中身(テキスト)の解析
The 泥臭い実装の部分です。
諸々試行錯誤するところですが、ChatGPTに手伝ってもらって楽しました。
このPDFに合わせた場当たりな実装感がありますが。。。他への流用は特にないし動いたのでヨシッ!としています。
「京都府」は罠ですね。「都/道/府/県」のいずれかが語尾になっていることを期待して文字列抜き出そうとすると、最初に「都」が引っかかって、ロジックによって「京」とか「京都」が抜き出されてしまいます。
ここでは「京都府」が欲しかったのでそうなるように特別な処理を入れています。
京都だけ結果がおかしいのでなんとかして!とChatGPTに聞いて得られた結果を採用しています。
def get_table_data(line):
parts = line.split()
# 都道府県名の抽出
prefecture_name_parts = []
for part in parts:
prefecture_name_parts.append(part)
if part[-1] in ['都', '道', '府', '県']:
if ''.join(prefecture_name_parts) == '京都' and parts[parts.index(part)+1] == '府':
prefecture_name_parts.append(parts[parts.index(part)+1])
break
else:
break
prefecture_name = ''.join(prefecture_name_parts)
# 県庁所在地の抽出
city_name_parts = []
for part in parts[len(prefecture_name_parts):]:
city_name_parts.append(part)
if part[-1] in ['市', '区']:
break
city_name = ''.join(city_name_parts)
# メッシュコードの抽出
mesh_code_pattern = r"\d+-\d+-\d+"
mesh_code_match = re.search(mesh_code_pattern, line)
mesh_code = mesh_code_match.group() if mesh_code_match else None
# 座標の抽出
coordinates_pattern = r"\d+°\d+′\d+″"
coordinates_matches = re.findall(coordinates_pattern, line)
latitude = coordinates_matches[0] if len(coordinates_matches) > 0 else None
longitude = coordinates_matches[1] if len(coordinates_matches) > 1 else None
return prefecture_name, city_name, mesh_code, latitude, longitude
読み取ったPDFを1行ずつ見て必要なデータだけ抜粋させています。
for i, line in enumerate(lines):
if header < i < footer:
if line:
prefecture_name, city_name, mesh_code, latitude, longitude = get_table_data(line)
テーブルの生成・書き込み
必要なデータを一通り抜粋した後、以下の処理で一気に行います。
型もいい具合に決めて定義してくれます。
df = session.create_dataframe(
pd.DataFrame(
{
"PREFECTURE_NAME" : prefecture_list,
"CITY_NAME" : city_list,
"MESH_CODE" : mesh_list,
"LATITUDE" : latitude_list,
"LONGITUDE" : longitude_list
}
)
)
df.write.mode("overwrite").save_as_table(table_name)
Snowparkを用いますが、Snowparkらしいこと(メソッドチェインとか、遅延評価を活かすとか)はここではしていません。
Sessionを使うことと、データフレームをテーブルとして書き込むのに使っています。
おまけ : ストアドプロシージャとして実行
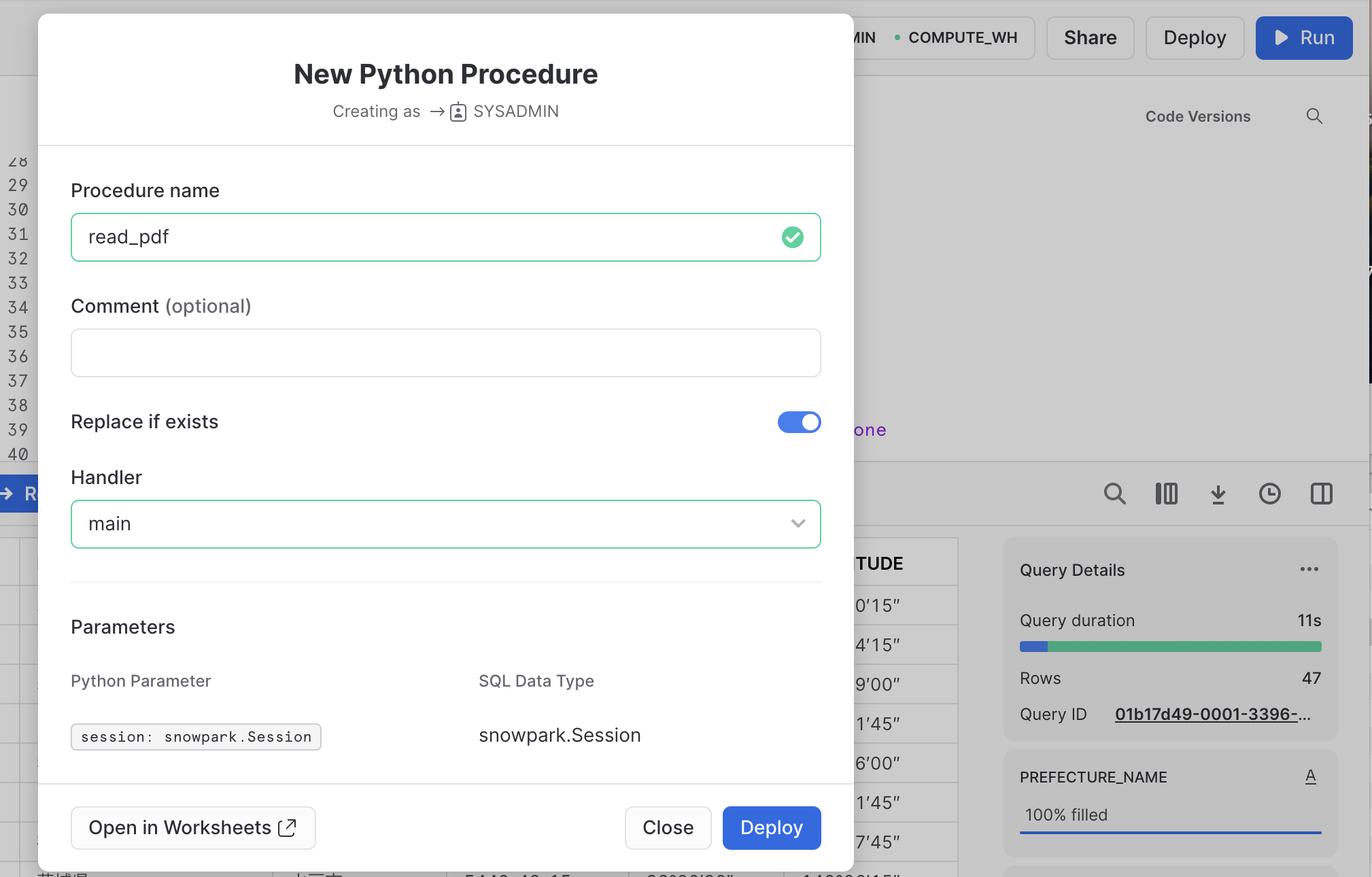
上記のロジックをPythonワークシートで実行してみましたが、そこからストアドプロシージャ化してみます。
「Deploy」ボタンから簡単にできるのがいいですね。
SQLワークシートで実行してみます。
call READ_PDF();
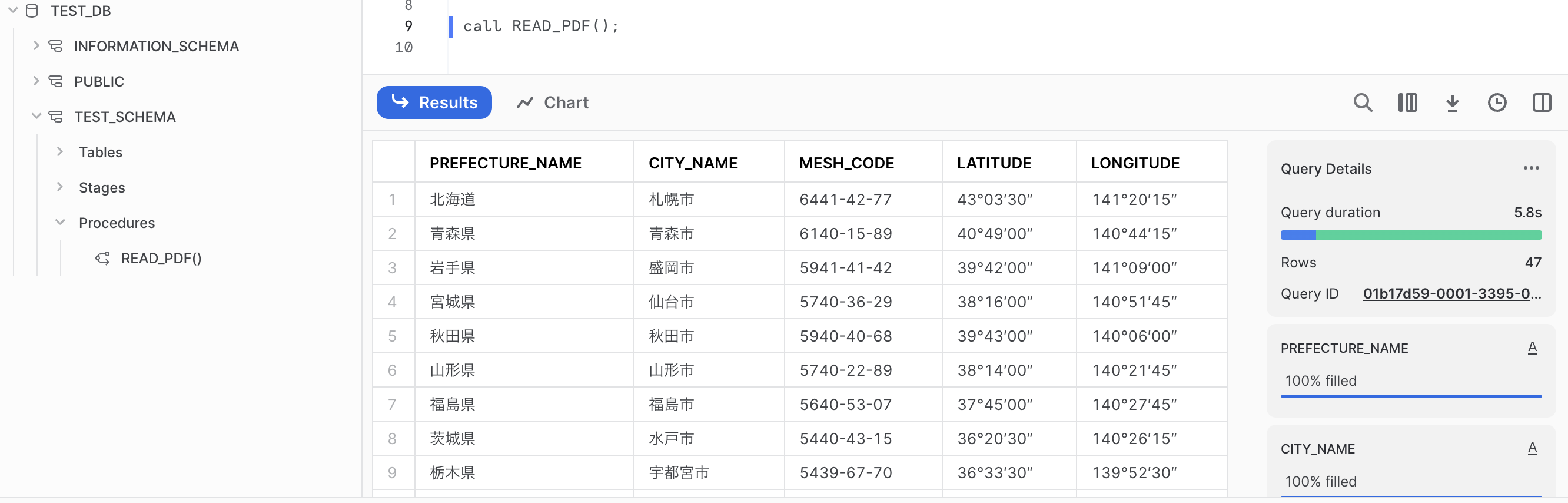
同じように実行できました!
おわりに
Snowflake上で処理を書いてそのままデータベースに取り込めてしまうのがいいですね。
DBの準備、DB接続設定などインフラ構築にまつわる諸々の考慮をスキップできて非常に楽です。
いろんな場所に、いろんな形式のファイルで散らばったデータをSnowflakeにまとめておき、分析データとして活用して新たな価値が創出できるといいなぁという思いも込めて。
以上です。