はじめに
Snowflakeに手持ちのデータ(ファイル形式)を読み込ませる(ロードする)には、内部ステージや外部ステージにそのファイルを置く必要があります。
参考 : https://docs.snowflake.com/ja/user-guide/data-load-overview
また、ロード可能なファイル形式にも条件があります。
- 区切り (csv, tsv)
- JSON
- Parquet
- ...
参考 : https://docs.snowflake.com/ja/user-guide/data-load-prepare#supported-data-types
上記参考を確認しますと...
そうです。
対応している形式の一覧には、Excel(.xlsx)が載っていません。
その壁を突破するのが本記事の内容です。
前提
読み込むファイル
以下のようなExcelファイルを想定します。
-
ファイル名 : user_list.xlsx
-
中身 : 列名含めて30行 (データ列は29行分)

構成
データベース : MY_DB
スキーマ : MY_SCHEMA
を作成し、このスキーマ配下に内部ステージを作成します。
- 内部ステージ : @MY_DB.MY_SCHEMA.MY_STAGE
こちらにExcelファイルを格納します。
Excelを読み込むための実装
Excelの読み込みはストアドプロシージャで実現します。
読み込んだデータは、MY_DB.MY_SCHEMA配下のテーブルに作成して書き出すこととします。
方法1 : SnowflakeFileを使用する
以下のストアドプロシージャを作成します。
- ストアドプロシージャ : MY_DB.MY_SCHEMA.READ_EXCEL_1
SnowflakeFileという公式のライブラリを用いて内部ステージのファイルを読み込みます。開いたファイルをpandasのread_excelを用いてデータフレーム化します。
参考 : https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/files
以下をSnowflake上のSQLワークシートで実行します。
CREATE OR REPLACE PROCEDURE MY_DB.MY_SCHEMA.READ_EXCEL_1(file_path string)
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
PACKAGES = ('snowflake-snowpark-python','pandas', 'openpyxl')
HANDLER = 'run'
AS
$$
from snowflake.snowpark.files import SnowflakeFile
import pandas as pd
def run(session, file_path):
with SnowflakeFile.open(file_path, 'rb') as file:
df = pd.read_excel(file, header=0)[["user_id", "user_name"]]
df_table = session.create_dataframe(df)
df_table.write.mode("overwrite").save_as_table("MY_DB.MY_SCHEMA.MY_TABLE_1")
return session.sql("SELECT count(*) FROM MY_DB.MY_SCHEMA.MY_TABLE_1").collect()
$$;
上記を実行してみます。
call MY_DB.MY_SCHEMA.READ_EXCEL_1(
build_scoped_file_url(@MY_DB.MY_SCHEMA.MY_STAGE, 'user_list.xlsx')
);

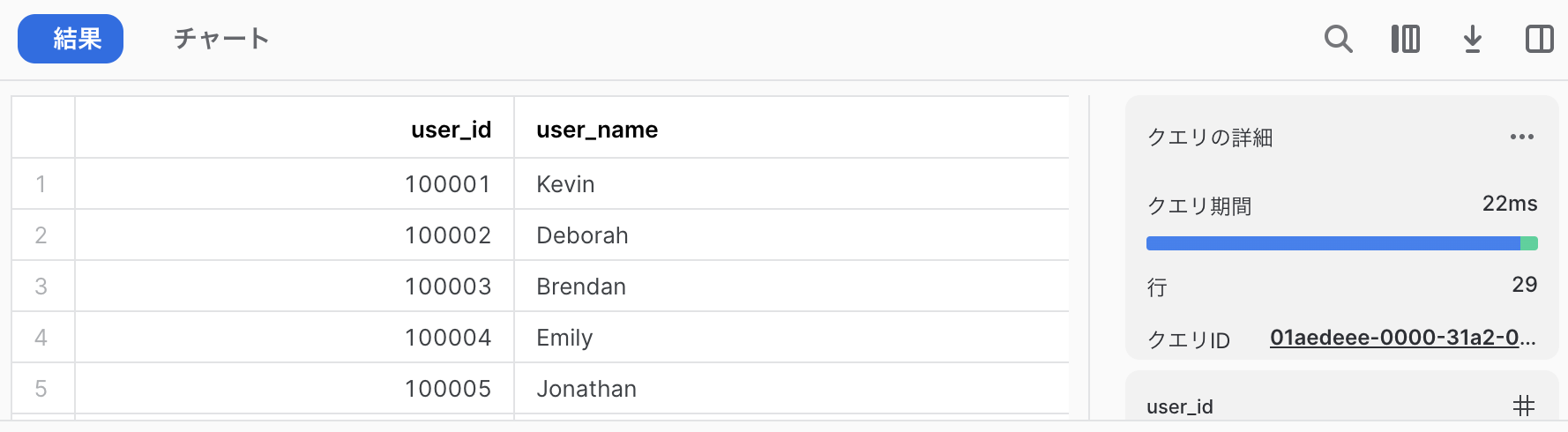
select * from MY_DB.MY_SCHEMA.MY_TABLE_1;

留意点として、上記で使用しているライブラリSnowflakeFileに問題があったらしく、しばらく使えなかった時期がありました。
-> 2023/08/31に解決済みです。
公式ライブラリが急に利用不可となる可能性を考慮して次の方法も考えてみました。
方法2 : IMPORTSを活用する
以下のストアドプロシージャを作成します。
- ストアドプロシージャ : MY_DB.MY_SCHEMA.READ_EXCEL_2
ストアドプロシージャの定義時に記述するIMPORTS部分を利用してExcelファイルを読み込み、Pythonの処理から参照する方法です。
参考 : https://docs.snowflake.com/ja/sql-reference/sql/create-procedure
これにより、自端末等で利用するのと同じ要領でpd.read_excel(<Excelファイルのパス>)が使えます。
CREATE OR REPLACE PROCEDURE MY_DB.MY_SCHEMA.READ_EXCEL_2()
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
PACKAGES = ('snowflake-snowpark-python','pandas', 'openpyxl')
IMPORTS = ('@MY_DB.MY_SCHEMA.MY_STAGE/user_list.xlsx')
HANDLER = 'run'
AS
$$
import pandas as pd
import sys
def run(session):
file_name = 'user_list.xlsx'
import_dir = sys._xoptions["snowflake_import_directory"]
df = pd.read_excel(import_dir + file_name, header=0)[["user_id", "user_name"]]
df_table = session.create_dataframe(df)
df_table.write.mode("overwrite").save_as_table("MY_DB.MY_SCHEMA.MY_TABLE_2")
return session.sql("SELECT count(*) FROM MY_DB.MY_SCHEMA.MY_TABLE_2").collect()
$$;
上記を実行してみます。
call MY_DB.MY_SCHEMA.READ_EXCEL_2();

select * from MY_DB.MY_SCHEMA.MY_TABLE_2;
この方法ではIMOPRTSでファイル名を直に指定しているため、ファイル名を引数では与えませんが、読み込むExcelファイル名が固定になるという制約があります。
参考 : https://community.snowflake.com/s/question/0D53r0000Boh3ikCQA/input-file-name-support-for-python-udf
念の為、方法1・方法2の結果(作成されたテーブル)を比較してみます。
select * from MY_DB.MY_SCHEMA.MY_TABLE_1
except
select * from MY_DB.MY_SCHEMA.MY_TABLE_2;
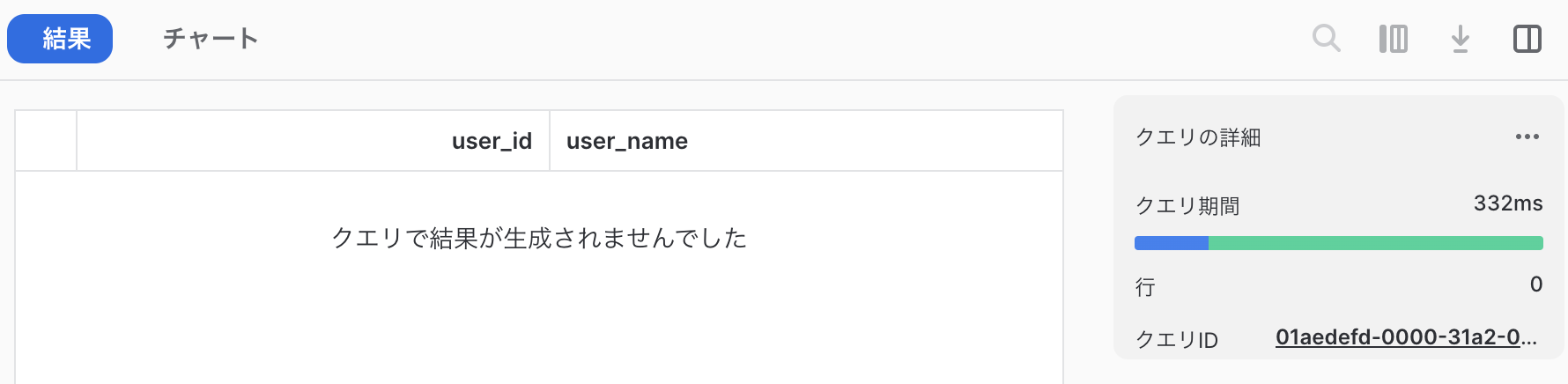
差分が出ないため、同じ結果となりました。
補足
sys._xoptions["snowflake_import_directory"] は IMPORTSで指定したファイルが格納されるディレクトリが得られます。
...
from glob import glob
def run(session):
file_name = 'user_list.xlsx'
import_dir = sys._xoptions["snowflake_import_directory"]
return glob(f"{import_dir}/*")
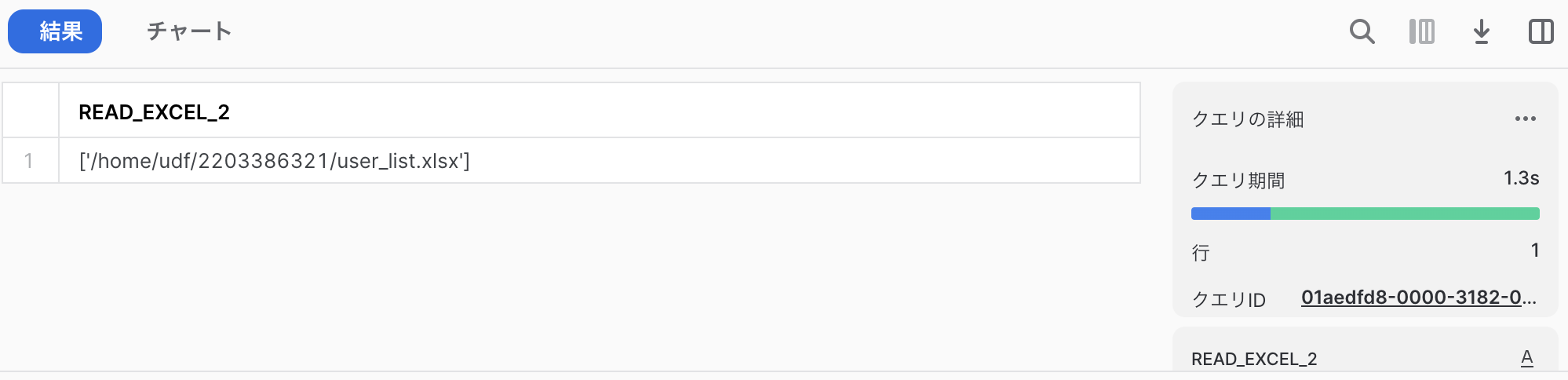
指定したExcelファイルが処理内で取得できている(=利用できる)ことが確認できます。
方法3 : session.file.getを使用する
以下のストアドプロシージャを作成します。
- ストアドプロシージャ : MY_DB.MY_SCHEMA.READ_EXCEL_3
2はIMPORTSを活用する方法で、ファイル名が固定でした。
これでは満足できない、やはり内部ステージもファイル名も指定したい...。
そんな方のために、やり方はあります。
session.file.getを用いて、ストアドプロシージャ実行中に内部ステージからファイルを読み込みます。
CREATE OR REPLACE PROCEDURE MY_DB.MY_SCHEMA.READ_EXCEL_3(stage_name string, file_path string)
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
PACKAGES = ('snowflake-snowpark-python','pandas', 'openpyxl')
HANDLER = 'run'
AS
$$
import pandas as pd
import os
work_dir = "/tmp"
def run(session, stage_name, file_path):
session.file.get(f"{stage_name}/{file_path}", work_dir)
file_name = os.path.basename(file_path)
df = pd.read_excel(f"{work_dir}/{file_name}", header=0)[["user_id", "user_name"]]
df_table = session.create_dataframe(df)
df_table.write.mode("overwrite").save_as_table("MY_DB.MY_SCHEMA.MY_TABLE_3")
return (session.sql("SELECT count(*) FROM MY_DB.MY_SCHEMA.MY_TABLE_3").collect())
$$;
上記を実行してみます。
call MY_DB.MY_SCHEMA.READ_EXCEL_3('@MY_DB.MY_SCHEMA.MY_STAGE', 'user_list.xlsx');

上記の処理内で読み込みたいファイルを格納するディレクトリを「/tmp」としている点もポイントです。
IMPORTSで指定した際は「/home/udf/2203386281/」 のようなディレクトリ(数値のディレクトリ名は勝手に決まる)にファイルが格納されますが、これを真似して「/home」配下にファイルを取り込もうとするとエラーになります。
ValueError: Only /tmp is writable, received /home
だそうです。
念の為、方法1・方法3の結果(作成されたテーブル)を比較してみます。
select * from MY_DB.MY_SCHEMA.MY_TABLE_1
except
select * from MY_DB.MY_SCHEMA.MY_TABLE_3;

差分が出ないため、同じ結果となりました。
補足
方法2でIMPORTSを用いたことを参考に、session.add_importを使って処理中に内部ステージからファイルを読み込む方法も考えられそうです。
session.add_importでステージから必要なファイルを読み込むサンプルコードも存在します。
しかし、この方法では残念ながらファイルは読み込めませんでした。
...
def run(session, stage_name, file_path):
...
session.add_import(f"{stage_name}/{file_path}")
import_dir = sys._xoptions["snowflake_import_directory"]
file_name = os.path.basename(file_path)
df = pd.read_excel(import_dir + file_name, header=0)[["user_id", "user_name"]]
...
...
session.add_importで試した実行結果は以下です。
FileNotFoundError: [Errno 2] No such file or directory: '/home/udf/2203386337/user_list.xlsx'
in function READ_EXCEL_3 with handler run
ちなみに、session.add_import自体はエラーなく実行されていました。
...
def run(session, stage_name, file_path):
...
session.add_import(f"{stage_name}/{file_path}")
return session.get_imports()

ただし、session.add_importが正常に実行されたからといって本当にimportされるわけではないようです。
...
import sys
from glob import glob
def run(session, stage_name, file_path):
...
session.add_import(f"{stage_name}/{file_path}")
import_dir = sys._xoptions["snowflake_import_directory"]
return glob(f"{import_dir}/*")
これは要注意です。
Excelファイル(.xlsx)をそのまま読み込むメリット
csv変換しなくても済む
Snowflake公式にはExcelの直接読み込みには対応していませんので、csvに変換しようという発想になると思います。
ですが、ここで紹介した方法でこの制限を突破する道が見えました。
Excelで管理されている表形式データをSnowflakeに集約したいようなケースで、都度csvに変換する手間が省けます。
また、紹介した例では1ファイルのみ対象でしたが、以下のようにすると内部ステージ内のファイル一覧が取得できるため、for文で回して複数ファイルを処理できます。
...
stage_file_list = session.sql(f"LIST {stage_name}").collect()
for stage_file in stage_file_list:
file_name = stage_file["name"]
# 上記はステージ名まで取れてしまう。
# e.g. my_stage/dir1/dir2/user_list.xlsx
#
# ステージ名を消したい場合など処理に応じて加工する。
# "/".join(stage_file["name"].split("/")[1:])
# e.g. dir1/dir2/user_list.xlsx
...
...
ファイルサイズが小さい
拡張子「.xlsx」形式は圧縮されたものだそうで、ファイルサイズが小さいです。
参考 : https://www.maruoka-digital.jp/blogcontent/3106142055/
ここで、Snowsight(GUI)を用いてファイルをアップロードする際には50MBの上限があるため、ファイルのアップロード〜データ投入ができなくなってしまいます。
同じ行数のデータでも、csvだとサイズオーバーする可能性があります。
50MB以上のファイルをアップロードするにはSnowSQL等を使用する必要がありますが、業務端末や利用環境次第では新規ソフトウェアのインストール制限がかかっているかもしれません。
そのようなケースでは大いに活用できるのではないでしょうか。
以上です。