はじめに
前回の記事で感情分析もしてみたいなぁと書きました。
いざTransformersをインストールしようとしたところ、
TransformersはPythonの仮想環境にインストールすべしに出合ってしまいました。
Docker Desktopはインストールしていたものの苦手意識があり あまり動かしていなかったため
身構えてしまいましたが、ずっと苦手なままではいけないし勿体ないと考え、
Dockerの勉強も兼ねて感情分析に入る前に
前回に引き続きBE:FIRSTの歌詞の可視化(ダジャレではない)をしてみました。
先人さまたちのおかげで克服出来たように思います(Dockerってすごい便利!の気分です)。
本当にありがとうございます。この場を借りてお礼を申し上げます。
今回も非常に長くなってしまったので、
ご興味を持っていただけましたらお読みいただけると幸いでございます。
きっと今頃、魔獣キリコと戦っている最中です。
BE:FIRSTとは
今回の完成品です

BMSGに所属する7人組ダンス&ボーカルグループです。
動作環境
・MacBook Air (Retina, 13-inch, 2020)
・Big Sur 11.4
・Python 3.8.7
・Docker(Debian)
・jupyter lab 3.0.16
・Anacondaは使用していません
今回の課題
・Dockerの苦手意識克服
-> Dockerについて再度ノートに書き起こし、いや先に触ってみよう!と決意
・新しいライブラリを使用してみる
-> 前回はMeCab、seabornを使用したため今回はJanome、WordCloudを使用
-> Janomeで単語ごとに分割、よく使われている単語をWordCloudで可視化し
そこから曲名を推測してみる。
・OpenCVをDockerに絶対にインストールしてやるぞ!という意気込み(何度か失敗済)
著作権、スクレイピングについて
・今回使用させていただく歌ネットさまの利用規約の熟読
・サーバーへの過度なアクセスを避けるためスクレイピング間隔を1秒空ける
-> 歌詞を取得できたらCSVファイルに保存し、それ以上はスクレイピングを実行しない
・歌詞は情報解析にのみ使用する
・BMSGの著作権について
この度では歌詞をWordCloudでのみ表示いたします。
1. 全曲を取得する
① Dockerの準備
こちらの方を参考にいたしました。
② DockerでMeCabもOpenCVも使えない!!!!
結論コードです。
FROM python:3
USER root
RUN apt-get update
RUN apt-get -y install locales && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
RUN apt-get upgrade -y
RUN apt-get install -y libgl1-mesa-dev
# OpenCV用のサーバのタイムゾーン
RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
RUN apt-get install -y vim less
RUN apt-get install -y sudo
RUN pip install --upgrade pip
RUN pip install --upgrade setuptools
RUN apt install -y fonts-ipaexfont
RUN python -m pip install jupyterlab
RUN pip install opencv-python
RUN python -m pip install torch torchvision torchaudio
RUN python -m pip install urllib3
RUN python -m pip install python-dotenv
RUN python -m pip install requests_oauthlib
RUN python -m pip install beautifulsoup4
RUN python -m pip install lxml
RUN python -m pip install seaborn
RUN python -m pip install japanize-matplotlib
RUN python -m pip install transformers
RUN python -m pip install fugashi
RUN python -m pip install ipadic
RUN python -m pip install mecab-python3
RUN python -m pip install janome
RUN python -m pip install wordcloud
RUN git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git && \
cd mecab-ipadic-neologd && \
./bin/install-mecab-ipadic-neologd -n -y && \
echo dicdir = `mecab-config --dicdir`"/mecab-ipadic-neologd">/etc/mecabrc && \
sudo cp /etc/mecabrc /usr/local/etc && \
cd ..
# mecabrc
WORKDIR /etc
RUN sed -i -e 's/dicdir = .*/dicdir = \/usr\/lib\/x86_64-linux-gnu\/mecab\/dic\/mecab-ipadic-neologd/g' mecabrc
RUN cp mecabrc /usr/local/etc/mecabrc
# キャッシュクリア
RUN apt-get clean \
&& rm -rf /var/lib/apt/lists/*
mecab-python3==0.996.3
③ スクレイピング前準備
(1)こちらの方を参考に、UserAgentを取得します
以下のサイトにアクセスするとUserAgentを取得することができます(画像部分です)。
IPアドレス、ユーザーエージェントの確認
Jupyter labを使用しておりますが、こちらの記述を省くと歌詞を取得できませんでした。
(2)スクレイピングしたいアーティストの歌詞一覧リストURLを取得します
BE:FIRST🔗 https://www.uta-net.com/artist/30961/
④ スクレイピング開始
(1)ライブラリのインポート
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
(2)歌詞情報を取得する
list_df = pd.DataFrame(columns=['曲名', '歌詞'])
# 歌ネットさまのURL
base_url = 'https://www.uta-net.com'
# さきほど取得したアーティストのURL
url = 'https://www.uta-net.com/artist/30961/'
# usr_agentに先ほど取得したUserAgent情報を入力
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
header = {'User-Agent': user_agent}
response = requests.get(url, headers=header)
soup = BeautifulSoup(response.text, 'lxml')
links = soup.find_all('td', class_='sp-w-100')
# 歌詞情報を取得
for link in links:
a = base_url + (link.a.get('href'))
response = requests.get(a)
soup = BeautifulSoup(response.text, 'lxml')
song_name = soup.find('h2').text
detail = soup.find('p', class_='detail').text
# 歌詞を取得
song_lyrics = soup.find('div', itemprop='lyrics')
song_lyric = song_lyrics.text
song_lyric = song_lyric.replace('\n', '')
song_lyric = song_lyric.replace('この歌詞をマイ歌ネットに登録 >このアーティストをマイ歌ネットに登録 >', ' ')
# サーバーに負荷を与えないため1秒待機
time.sleep(1)
# 取得した歌詞をデータフレームに追加
tmp_se = pd.DataFrame([[song_name], [song_lyric]], index=list_df.columns).T
list_df = list_df.append(tmp_se)
# CSVに保存
list_df.to_csv('befirst_lyrics.csv', mode='w', encoding='utf-8')
(3)データフレームに格納、確認
df = pd.read_csv('befirst_lyrics.csv')
song_lyrics = df['歌詞'].tolist()
df.info
(4)janomeで解析スタート
from janome.tokenizer import Tokenizer
import pandas as pd
import re
t = Tokenizer()
results = []
for s in song_lyrics:
tokens = t.tokenize(s)
r = []
for tok in tokens:
if tok.base_form == '*':
word = tok.surface
else:
word = tok.base_form
# part_of_speech(品詞)
ps = tok.part_of_speech
hinshi = ps.split(',')[0]
if hinshi in ['名詞', '動詞', '形容詞']:
r.append(word)
rl = (' '.join(r)).strip()
results.append(rl)
text_file = 'BF_ALL_wakachi.txt'
with open(text_file, 'w', encoding='utf-8') as fp:
fp.write('\n'.join(result))
(5)WordCloudで表示
from wordcloud import WordCloud
from matplotlib import pyplot as plt
import japanize_matplotlib
f = open('BF_ALL_wakachi', 'r', encoding='UTF-8')
# 日本語表示のためのフォントパス
fpath = '/Users/watashi/Documents/docker-python/opt/IPAexfont00401/ipaexm.ttf'
text = f.read()
# 除外ワード設定
stop_words = [
'らん',
'られ',
'さ',
'そう',
'ない',
'いる',
'する',
'せる',
'まま',
'よう',
'てる',
'なる',
'こと',
'もう',
'いい',
'ある',
'ゆく',
'れる',
'ん'
]
wordcloud = WordCloud(
font_path=fpath,
width=900, height=600,
background_color='white',
colormap='summer',
stopwords=set(stop_words),
max_words=500, # default=200
min_font_size=4, # default=4
collocations=False # default = True
).generate(text)
plt.figure(figsize=(15, 12))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('befirst_lyrics.png', dpi=300)
plt.show()
(6)どどん!

「I」が一番大きく、その周りに「it」「君」「You」「We」など人を指す言葉が多いですね。
ただ「it」が差す範囲が広く抽象的なので全曲では除外します(各曲では除外しません)。
(7)改めてどどん!

やはり「I」「君」「We」「you」が大きく、
全体的に「人」を重視している歌詞であることが分かります。
(8)BE:FIRSTにマスキングしてみました
(次章でマスキングのコードを書いております)。
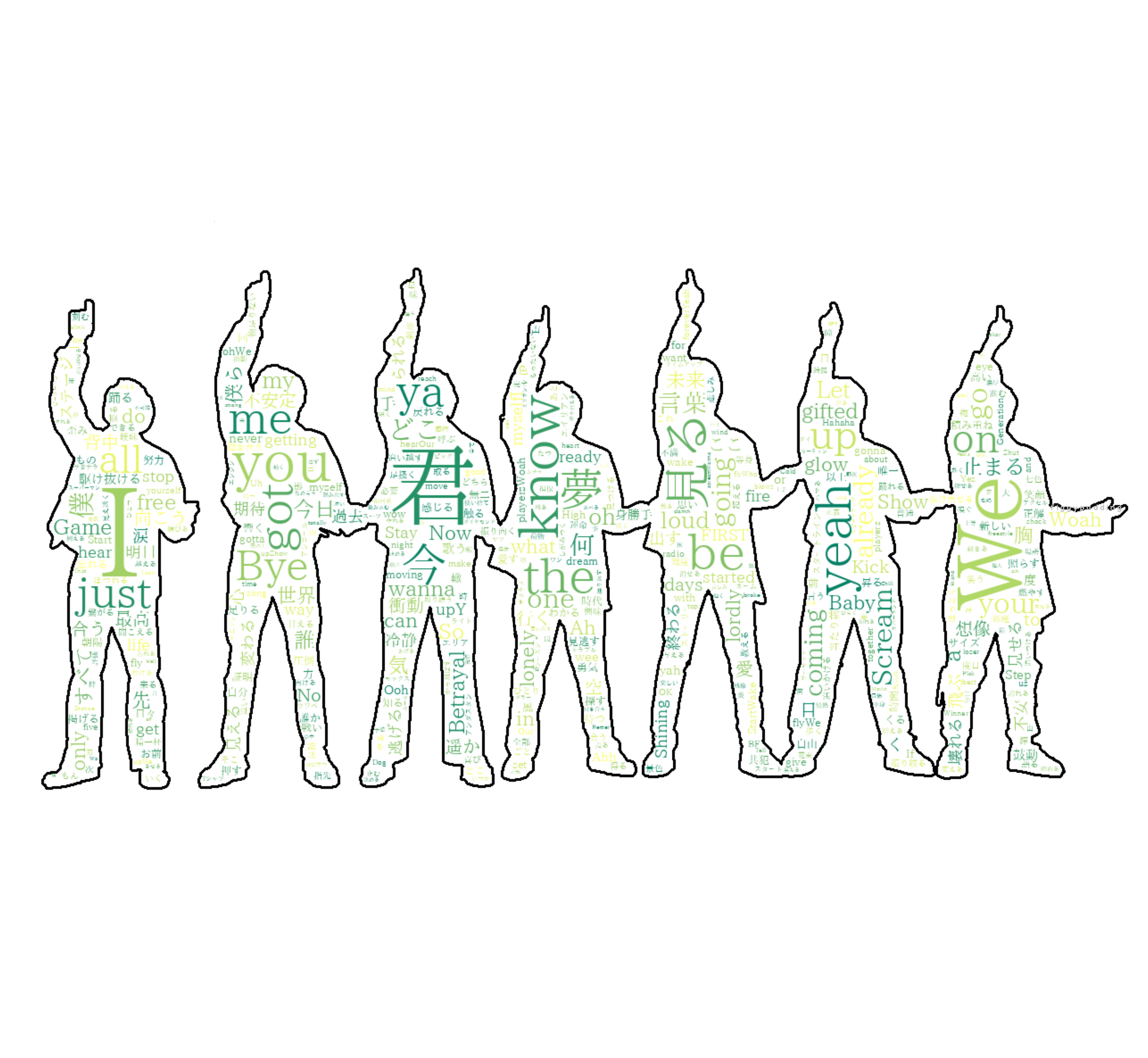
画像はShining Oneより
2. 各曲を取得、マスク画像をWordCloudに適用し曲名を推測する
本題です。曲ごとにWordCloudを実行し曲名を推測していこうと思います。
2022/08/31に発売されるアルバム「BE:1」のアー写で
各メンバーが付けている楽曲名入りのネックレスに合わせてマスキングしました。
① 各曲を取得
(1)マスキングしたい透過PNG画像を用意し同じディレクトリに保存しておきます。
(2)ライブラリのインポート
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
from janome.tokenizer import Tokenizer
import re
(3)取得した歌詞一覧を表示
# 全体で取得した歌詞一覧CSV
df = pd.read_csv('befirst_lyrics.csv')
df.info
(4)取得したい曲名の数字を入力し変数に代入する
G = df.loc[5,'歌詞']
(5)取得したい歌詞を形態素解析しつつtxtファイルに保存する
t = Tokenizer()
# 取得したい歌詞に合わせて適宜変更する①
# (4)で記述した変数
tokens = t.tokenize(G)
word_list = []
for token in tokens:
word = token.surface
partOfSpeech = token.part_of_speech.split(',')[0]
partOfSpeech2 = token.part_of_speech.split(',')[1]
if partOfSpeech in['名詞', '動詞', '形容詞']:
if (partOfSpeech != '記号'):
if (partOfSpeech2 != '非自立') and (partOfSpeech2 != '代名詞') and (partOfSpeech2 != '数'):
word_list.append(word)
words = ' '.join(word_list)
print(words)
# テキストファイルに書き込む
# 取得したい歌詞に合わせて適宜変更する②
with open('Gifted.txt', 'a', encoding='utf-8') as f:
f.write(words)
② マスク画像の作成、マスク画像をWordCloudに適用
from wordcloud import WordCloud
from matplotlib import pyplot as plt
import japanize_matplotlib
# フォントパス
fpath = '/Users/watashi/Documents/docker-python/opt/IPAexfont00401/ipaexm.ttf'
# 取得したい歌詞に合わせて適宜変更する③
# (4)で保存したtxtファイルの名前
TXT_NAME = 'Gifted'
# 取得したい歌詞に合わせて適宜変更する④
# マスキングしたい写真
IMG_PATH = 'MANATO.PNG'
def get_mask(img_path):
import cv2
# maskの条件(デフォルト)
# 黒色:文字を表示する範囲
# 白色:文字を表示しない範囲
img = cv2.imread(img_path, -1)
# A(アルファチャネル)に関する要素だけ抽出
a_img = img[:, :, 3]
# 白黒反転
result_img = cv2.bitwise_not(a_img)
# a_imgの色を反転させた画像をresult_imgに代入する
return result_img
# cv2.imwrite('SO_mask.png', result_img)とすれば対象が真っ黒になった画像が保存できます
# 除外ワード
stop_words = [
'らん',
'られ',
'さ',
'そう',
'ない',
'いる',
'する',
'せる',
'まま',
'よう',
'てる',
'なる',
'こと',
'もう',
'いい',
'ある',
'ゆく',
'れる',
'ん'
]
# テキストファイル読み込み
text = open(TXT_NAME + '.txt', encoding='utf-8').read()
# mask取得
mask = get_mask(IMG_PATH)
wordcloud = WordCloud (
font_path=fpath,
width=900, height=600,
# 背景:取得したい歌詞に合わせて適宜変更する⑤
background_color='black',
# WordCloudのカラーマップ:取得したい歌詞に合わせて適宜変更する⑥
colormap='autumn',
# マスク画像適用コード
mask=mask,
# 縁の線の太さ
contour_width=3,
# 縁取りカラー:取得したい歌詞に合わせて適宜変更する⑦
contour_color='white',
stopwords=set(stop_words),
max_words=500, # default=200
min_font_size=4, # default=4
collocations = False # default = True
).generate(text)
plt.figure(figsize=(15, 12))
plt.imshow(wordcloud,interpolation='bilinear')
plt.axis('off')
# 保存名:取得したい歌詞に合わせて適宜変更する⑧
plt.savefig('MANATO_Gifted.png', dpi=300)
plt.show()
3. 時系列ごとに推測してみます
① Shining One:プレデビュー曲(2021/08/16)
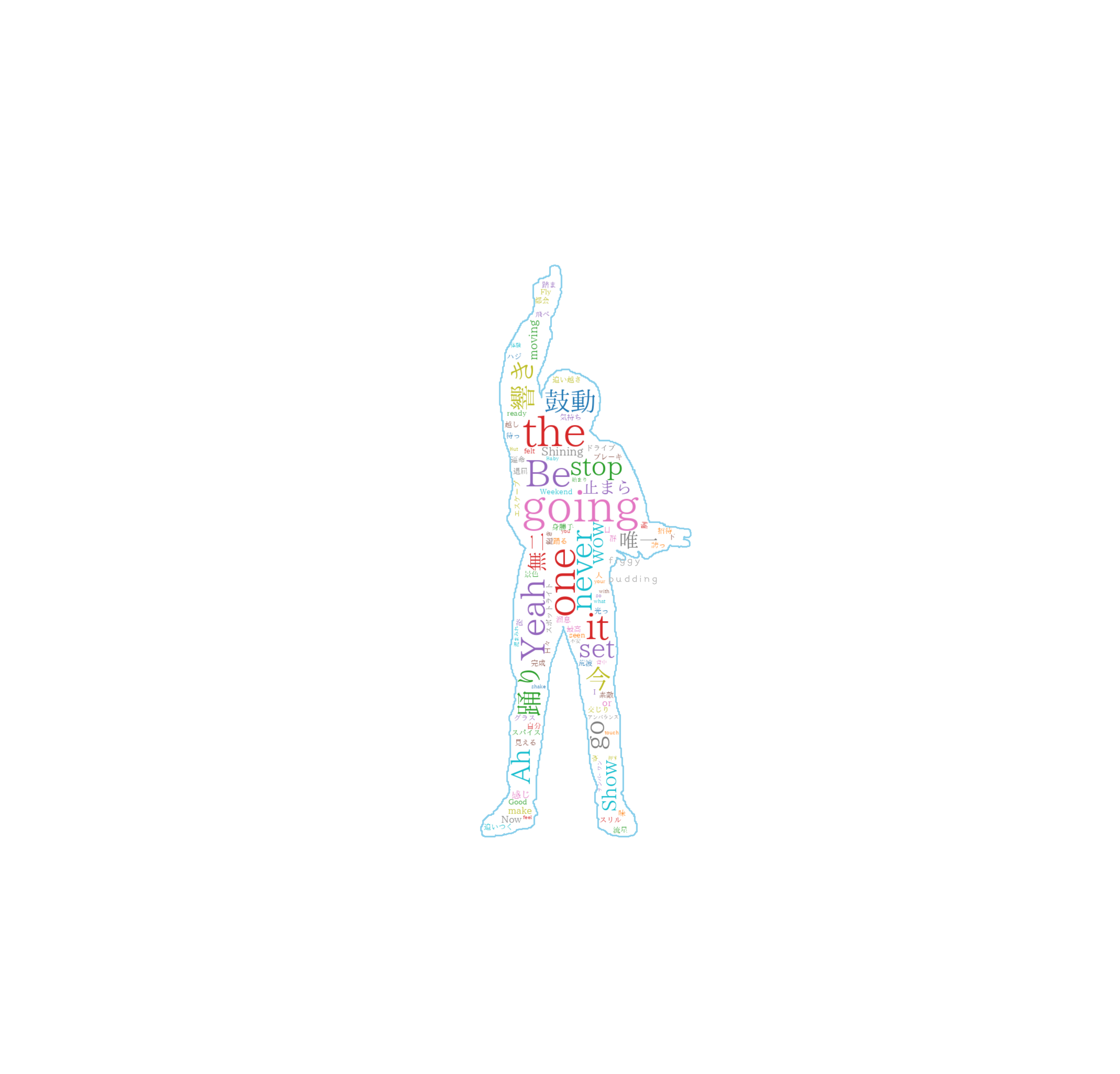
推測される(と思われる、以下略)タイトル
「Be the one」「going」「never going it」「Yeah」「鼓動」「響き」「踊り」
② Gifted.:デビュー曲(2021/11/03)

推測されるタイトル
「gifted」「we just gifted」「You just gifted」「You know」「We know」
③ Bye-Good-Bye:2nd Single リード曲(2022/05/18)
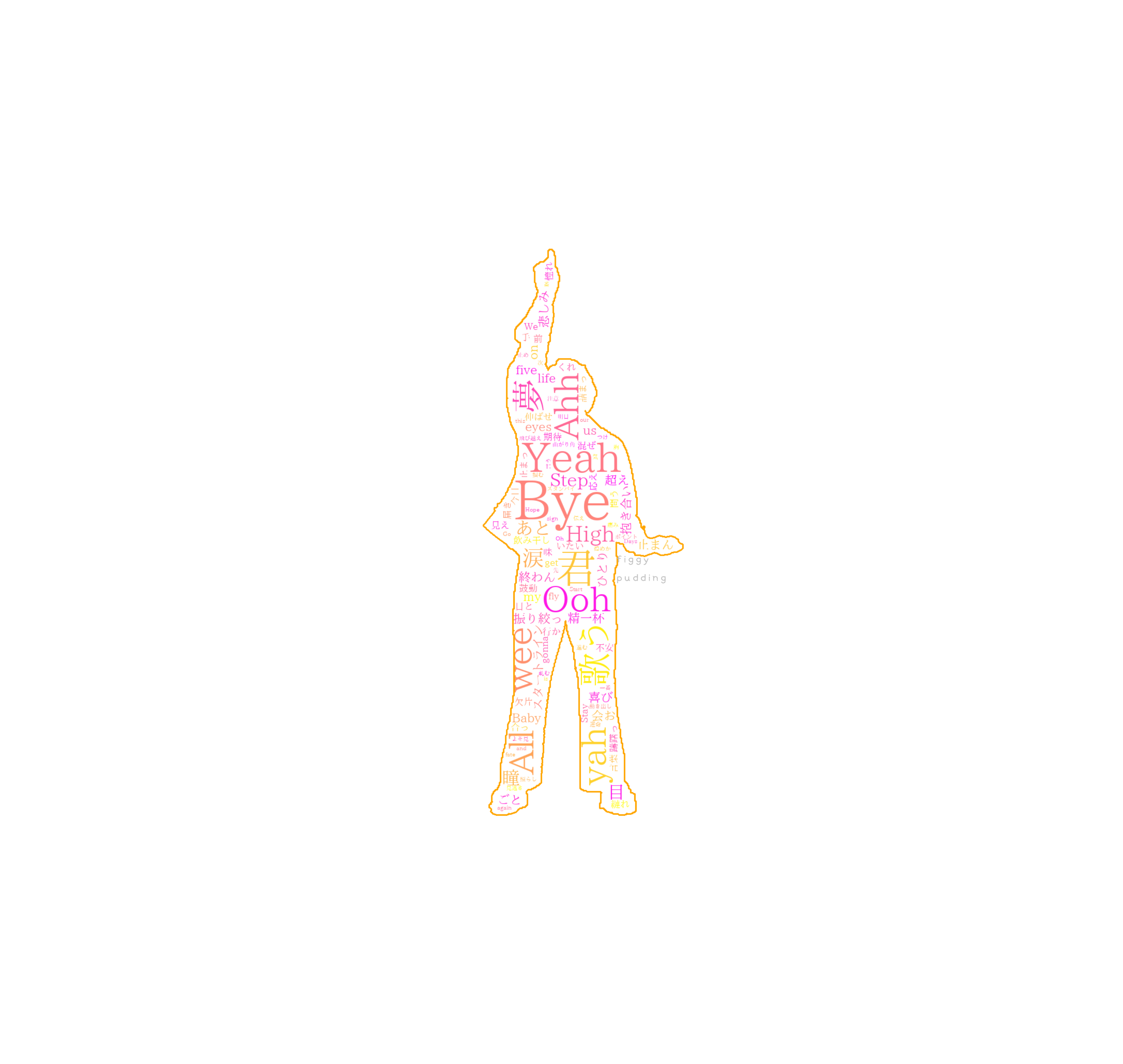
推測されるタイトル
「Bye」「君」「歌う」「夢」「Yeah」「wee」「Ooh」「Bye All」「High Step」
④ Brave Generation:JFL presents FOR THE NEXT 2022 テーマソング(2022/05/18)

推測されるタイトル
「We know 今日」「駆け抜けろ」「不満」「世界」「足掻く今日」「I」「Generation」
⑤ Betrayal Game:ドラマ「探偵が早すぎる」エンディング(2022/05/18)

推測されるタイトル
「Betrayal Game」「身勝手」「世界」「衝動」「不安定」「共犯」
⑥ Be Free:「THE FIRST」オーディション合宿審査課題曲再録(2022/08/31)

推測されるタイトル
「be free」「You can go」「So Let you go」「I can be free」「今」「夢」「自由」
⑦ Move On:「THE FIRST」オーディション合宿審査課題曲再録(2022/08/31)

推測されるタイトル
「I got myself」「今」「未来」「言葉」
4. 結論:楽曲による。
Be Free、Betrayal Game、Gifted.あたりは推測できそうでしょうか。
「今たしかにここにいる」という感情を非常に大切にしているように感じます。
また、こうやって歌詞を可視化してみると全ての曲が繋がっているようにも思います。
一番伝えたい気持ちをフックに持ってこない場合もありますよね。
楽曲や彼らのイメージ、衣装から色を選びましたが
Move OnやGifted.の色合いがすごくかっこいいですね。
SHUNTOくんとMANATOくんのダークなかっこよさを表現できた気がします。
Shining Oneの色合いも可愛いですね。RYUHEIくんぽく作成できて満足です。
私が他に好きなバンドは曲名が歌詞に出てこない場合が多いので非常に新鮮でした。
5. We Are BE:FIRST!!

カッコいい…(心の声)
6. 番外編
曲名が歌詞に出てくる好きな曲です。

曲名が推測できそうですね!
7. 課題克服点
1. 何度もbuild -> downしたためcacheが溜まってしまいbuild出来ない
かなりのキャッシュが溜まりMacの容量も圧迫されてしまい、
Macの動作が重くなってしまっていました。
#0 658.3 E: /var/cache/apt/archives/ に充分な空きスペースがありません。
参考🔗 第4章 Debian 6.0 (squeeze) からのアップグレード
(1)コンテナへ接続し自分の環境のキャッシュサイズを調べてみる
~# du -Sh /var/lib/apt/lists/
4.0K /var/lib/apt/lists/auxfiles
4.0K /var/lib/apt/lists/partial
4.0K /var/lib/apt/lists/
~# du -Sh /var/cache/apt/archives/
12K /var/cache/apt/archives/
(2)apt-get cleanを実行する
~# apt-get clean
```zsh
~# du -Sh /var/cache/apt/archives/
12K /var/cache/apt/archives/
(3)buildする前にDockerfileの最下部に以下を記述する
(途中で記述してしまうとvim等がインストールできない)
RUN apt-get clean \
&& rm -rf /var/lib/apt/lists/*
apt-get clean では /var/cache/apt/archives にキャッシュされている全てのパッケージを削除、
rm -rf /var/lib/apt/lists/* では /var/cache/apt/list にキャッシュされている全てのパッケージリストを削除します。
(4)Docker Cacheクリア
docker-python % docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 2 2 13.17GB 0B (0%)
Containers 2 1 5.962kB 0B (0%)
Local Volumes 0 0 0B 0B
Build Cache 128 0 15.71GB 15.71GB
以下のコマンドを実行する
% docker builder prune
WARNING! This will remove all dangling build cache.
Are you sure you want to continue? [y/N] y
Deleted build cache objects:
7ulvcv11zif2br1onzzrqzge9
・
・(中略)
・
ktmc7xigrkueti1nd5c390vgh
Total reclaimed space: 15.71GB
docker-python % docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 2 2 13.17GB 0B (0%)
Containers 2 1 5.962kB 0B (0%)
Local Volumes 0 0 0B 0B
Build Cache 42 0 0B 0B
2. <none>削除
(1)IMAGE IDを取得する
% docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> latest 31452dg8981b 3 days ago 15.8GB
docker-python_python3 latest dd5adko94d15 11 months ago 883MB
(2)下記を実行する
% docker rmi 31452dg8981b -f
(3)削除されているか確認する
% docker image ls
docker-python_python3 latest dd5adko94d15 11 months ago 883MB
8. あとがき
タイトルよりも課題克服に重点を置いてしまいましたが
列挙していた課題は克服できたように思います。OpenCVも使用でき感無量です。
MeCabとjanomeのどちらも使用してみて、
以下の検証通り、MeCabの方が解析速度が速いように感じました。
MeCabは瞬きする前に結果が表示され、
janomeは3回くらい瞬きする時間がありました。
実行速度は異なりますが、こういうライブラリを使わせていただけることに感謝です。
import MeCab
import time
from statistics import mean
mecab = MeCab.Tagger('-Ochasen')
data = []
# 100回実行する
for i in range(100):
start = time.time()
malist = mecab.parse('すももももものうち')
data.append(time.time() - start)
print('average:', mean(data))
average: 0.00039880990982055664
from janome.tokenizer import Tokenizer
import time
from statistics import mean
data = []
# 100回実行する
for i in range(100):
start = time.time()
t = Tokenizer()
malist = t.tokenize('すももももものうち')
data.append(time.time() - start)
print('average:', mean(data))
average: 0.024710307121276854
また、機械学習を触る中で、BMSGはBERTやspin(アルバム収録曲)モデルなど、
プログラミング用語を連想させる単語が多いのかなぁと思いました。
BUMPにもHello World!という楽曲がありますねo(`ω´ )o
初めてプログラミングに触れたとき感動した覚えがあります。
前回に引き続き大変長く、疎い記事をここまでお読みいただきありがとうございました。
参考
・本当にいつものごとくウンウン唸っていたのですが、
突如として現れた「私はからあげです」に爆笑してしまい頭がスッキリした覚えがあります
その節は本当にありがとうございました。
・Dockerに辞書のインストール
・Docker:MeCabの辞書のパス