TensorFlow:最初のステップ
TensorFlowとは機械学習のアルゴリズムを実装して実行するための、スケーラブルなマルチプラットフォームのプログラミングインターフェースである........
簡単にまとめると計算グラフと呼ばれる処理フローを作成して、実行するPackageらしい。
PyTorchとかKerasとかも追いついてきてるけど、依然としてTensorFlowの人気が高い。
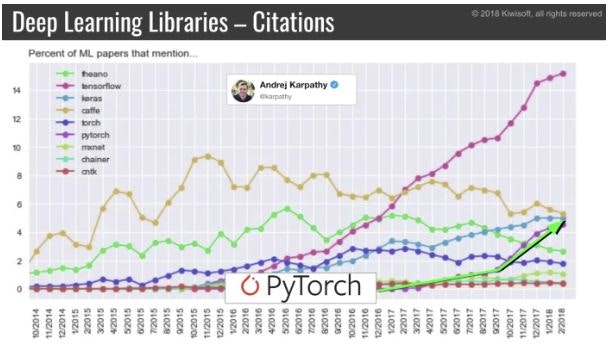
Kerasに比べるとデバッグしずらいし、分かりずらい。
実際上記の指摘も多くあってか、シンプルにかけるTensorFlow2.0をリリースした模様。
この記事では初期のTensorFlowの文法を使って記載していく。
TensorFlow2.0入れちゃったよという場合でも安心。以下のコードでコンバートできる....!
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
書き方はざっくり以下の構成になっている。

とりあえず実行してみよう。
なおTensorFlowのパッケージはインストールしていざ実行しようとすると意味不明なエラーが良く出てくるので、容赦なくアンインストール→インストールしよう。
import os
import numpy as np
import tensorflow as tf
g = tf.Graph()
with g.as_default():
x = tf.placeholder(dtype=tf.float32, shape=(None), name='x') # 引数
w = tf.Variable(2.0, name='weight') # 変数①
b = tf.Variable(0.7, name='bias') # 変数②
z=w*x + b
init=tf.global_variables_initializer() # 変数の初期化(tf.Session中で定義しても良いがここの方が扱いやすい)
with tf.Session(graph=g) as sess:
sess.run(init) # 変数の初期化の実行
for number in [1.0, 0.6, -1.8]:
z = sess.run(z, feed_dict={x:number}) # z= w * x + bの実行
print(z) # 処理結果をprint
z = sess.run(z, feed_dict={x:number})
ここの箇所だけ簡単に解説。
sess.run(アクセスしたい変数名, feed_dict={引数: 引数に渡したい値となる})
どんどん行こう。次は配列(テンソル)を操作する。
TensorFlowでは計算グラフではエッジを流れる値をテンソルと呼ぶ。まさにテンソル流れだ。
テンソルはスカラ・ベクトル・行列として解釈できる。例えば以下の要領だ。

それでは早速TensorFlowでテンソルを操作してみよう。
g = tf.Graph()
with g.as_default():
x = tf.placeholder(dtype=tf.float32, shape=(None,2,3), name='input_x') # テンソルを受け取る引数
x2 = tf.reshape(x,shape=(-1,6),name='x2') # 受け取った引数xをreshapeメソッドで変形
print(x2) # 変数の定義を出力
xsum=tf.reduce_sum(x2,axis=0,name='col_sum') # 各列の合計
xmean=tf.reduce_mean(x2,axis=0,name='col_mean') # 各列の平均
with tf.Session(graph=g) as sess:
x_array = np.arange(18).reshape(3,2,3) # 配列を作成
print('Column Sums:\n', sess.run(xsum, feed_dict={x:x_array})) # 各列の合計を出力
print('Column Means:\n', sess.run(xmean, feed_dict={x:x_array})) # 各列の平均を出力
tf.reshape(x,shape=(-1,6),name='x2')
ここでのポイントはshapeに-1が指定されていること。
これは型定義が未定でよしなに入力された配列にあわせて変換してくださいな、という意味。
TensorFlow:最小2乗線形回帰の実装
まずは最小2乗線形回帰ってなによってとこから。
①y = w * x + b の式を使って予測値を算出する
②(正解ラベル - 予測値)^2を求める
③②の平均値を求める
④③を使ってwとbを求める
⑤これをエポック数分繰り返す
結果、コスト値が大局的最小値に落ち着けば収束したといえる。
以下エクセルで手動で計算してみた様子。
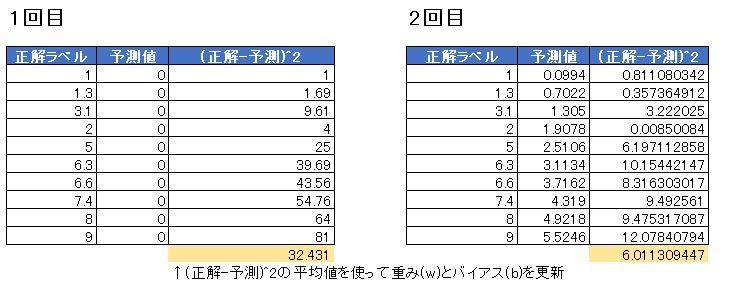
そしてよくある図。
これはコスト値(エクセルの黄色い部分)をプロットして収束していく様子を表したもの。
線形関数のコスト関数は微分可能な凸関数になる。
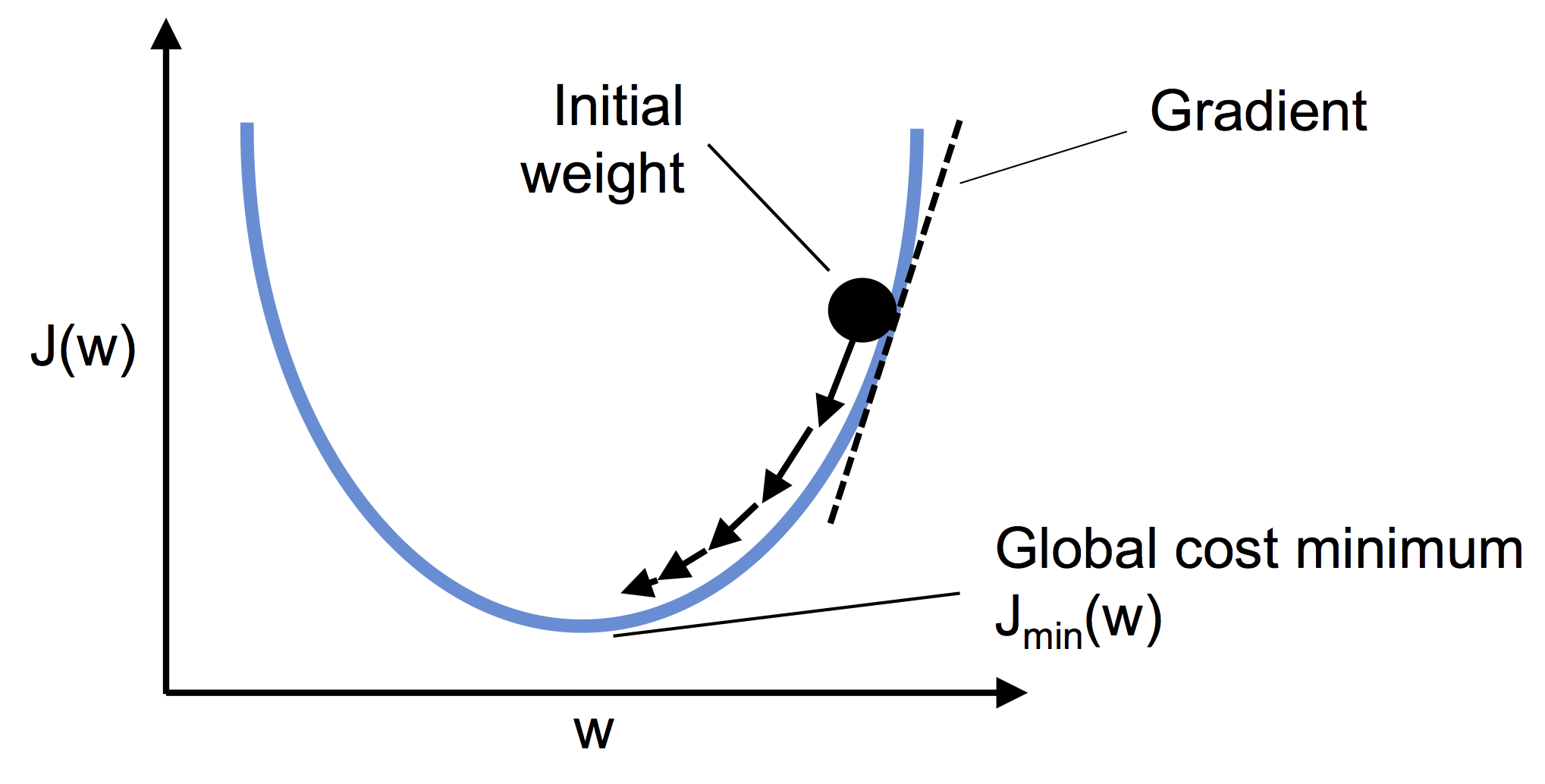
それでは実際コードを見てみよう!!
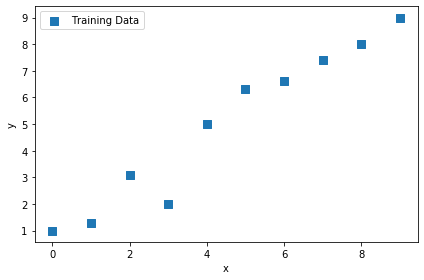
まずは訓練用のデータを用意する
# 訓練データ
X_train = np.arange(10).reshape((10, 1))
y_train = np.array([1.0, 1.3, 3.1,2.0, 5.0, 6.3, 6.6, 7.4, 8.0, 9.0])
# 線形回帰モデルのプロット
plt.scatter(X_train, y_train, marker='s', s=50,label='Training Data')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.tight_layout()
plt.show()
はい、matplotlibでプロットしてみましたー!
次にTfLinregクラスを用意する。
class TfLinreg(object):
# コンストラクタ
def __init__(self, x_dim, learning_rate=0.01, random_seed=None):
self.x_dim = x_dim
self.learning_rate = learning_rate
self.g = tf.Graph()
with self.g.as_default():
tf.set_random_seed(random_seed)
self.build()
# 変数のイニシャライザ
self.init_op = tf.global_variables_initializer()
def build(self):
# プレースホルダ―を定義
self.X = tf.placeholder(dtype=tf.float32, shape=(None,self.x_dim), name='x_input')
self.y = tf.placeholder(dtype=tf.float32, shape=(None), name='y_input')
# tf.zeros:要素が全て0の行列
# 1×1のテンソル
w = tf.Variable(tf.zeros(shape=(1)), name='weight')
b = tf.Variable(tf.zeros(shape=(1)), name='bias')
self.w = w
self.b = b
# 予測値を算出
# tf.squeeze:1の次元を削除し、テンソルを1つ下げる関数
self.test = w * self.X + b
self.z_net = tf.squeeze(w * self.X + b, name='z_net')
# 実績値-予測値
# tf.square:要素ごとに2乗をとる
sqr_errors = tf.square(self.y - self.z_net, name='sqr_errors')
self.sqr_errors = sqr_errors
# コスト関数
# tf.reduce_mean:与えたリストに入っている数値の平均値を求める関数
self.mean_cost = tf.reduce_mean(sqr_errors, name='mean_cost')
## オプティマイザを作成
# GradientDescentOptimizer:最急降下法
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=self.learning_rate,
name='GradientDescent'
)
# 損失関数の勾配(重みと傾き)を計算
self.optimizer = optimizer.minimize(self.mean_cost)
この時点ではクラスを定義しただけなので、何も具体的な数値は設定されていません。
ここでワンポイント。勾配降下法の中にはいくつか種類があります。
・最急降下法(Gradient Descent)
・確率的勾配降下法(Stochastic Gradient Descent - SDG)
・ミニバッチ確率的勾配降下法(Minibatch SGD - MSGD)
最急降下法は全ての誤差の合計をとってからパラメタ更新するのに対して
確率的勾配降下法はデータ1つごとに重みを更新していきます。
ミニバッチは2つの中間的な存在で膨大なデータをバッチ数ごとにぶった切って実行していくようなイメージ。
それじゃあ続き。
まずはコンストラクタを呼んでインスタンスを作成します。
# モデルのインスタンス化
lrmodel = TfLinreg(x_dim=X_train.shape[1], learning_rate=0.01)
続いて学習を実施
### 学習
# self.optimizer
def train_linreg(sess, model, X_train, y_train, num_epochs=10):
# 変数の初期化
sess.run(model.init_op)
training_costs=[]
# 同じX_trainを10回繰り返す
for i in range(num_epochs):
"""
model.optimizer:急速降下法を適用する
model.X:学習データ(階数2)
model.y:正解データ(階数1)
model.z_net:予測値(w * self.X + bから計算)
model.sqr_errors:実績値-予測値の2乗
model.mean_cost:2乗誤差の平均値
model.w:更新後の重み
model.b:更新後のバイアス
"""
_,X,y,z_net,sql_errors,cost,w,b= sess.run([
model.optimizer,
model.X,
model.y,
model.z_net,
model.sqr_errors,
model.mean_cost,
model.w,
model.b,
],feed_dict={model.X:X_train, model.y:y_train}) # 同じのを10回繰り返す
print(' ')
print(X)
print(y)
print(z_net)
print(sql_errors)
print(cost)
print(w)
print(b)
training_costs.append(cost)
return training_costs
model.optimizer
で最急降下法が実行されます。
結構迷ったとこがwとbには更新後の重みが設定されていること。
だから出力は、
[0.60279995]
[0.09940001]
みたいになるけど初回の予測は[0][0]で実施されています。
早速動かしてみる。
sess = tf.Session(graph=lrmodel.g)
training_costs = train_linreg(sess, lrmodel, X_train, y_train)
ほんでコスト値をプロットしてみる。
plt.plot(range(1,len(training_costs) + 1), training_costs)
plt.tight_layout()
plt.xlabel('Epoch')
plt.ylabel('Training Cost')
# plt.savefig('images/13_01.png', dpi=300)
plt.show()
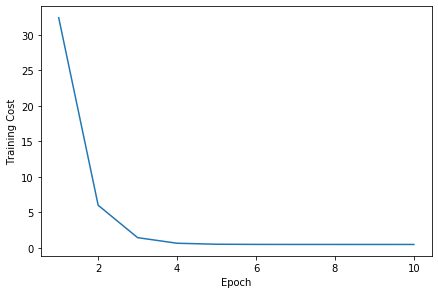
・・・!
やったね、収束したよ!!
続いては予測をしよう。
予測は予測値(z_net)を呼び出すだけなので難しくない。
引数のx_testに2階数のテンソルをぶち込めば実行される。
### 予測
# model.z_net
def predict_linreg(sess, model, X_test):
y_pred = sess.run(model.z_net, feed_dict={model.X:X_test})
return y_pred
最後に訓練データで作成したモデルを可視化してみよう。
### 線形回帰モデルのプロット
# 訓練データ
plt.scatter(X_train, y_train, marker='s', s=50,label='Training Data')
# 訓練データを使って出力した線形回帰モデル
plt.plot(range(X_train.shape[0]), predict_linreg(sess, lrmodel, X_train),color='gray'
, marker='o', markersize=6, linewidth=3,label='LinReg Model')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.tight_layout()
plt.show()
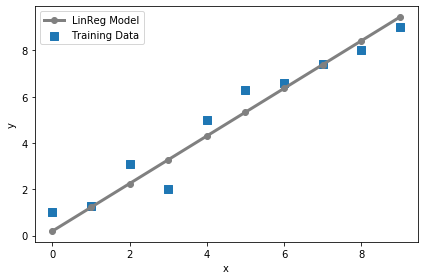
いい感じに線形が引かれている...........!
ということで今回はここまで。