はじめに
前回の記事では Python スクリプトから直接 Log Service にログを投入する方法を紹介させていただきました。Log Service は直近のログ分析を行うには良いサービスですが、一定期間で保持されたログを削除するため、長期的なデータ分析を行うためには向いておりません。OSS にログを移す機能がありますが、実際にログ分析として活用するにはさらに RDS など別のサービスへのインポートが必要となります。
そこで、今回は DataWorks を利用して OSS から ApsaraDB for RDS(MySQL) へデータをインポートする方法を紹介いたします。
DataWorks とは?
DataWorks は、Alibaba Cloud によってリリースされた大きなデータPaaSプラットフォームです。ワンストップの DW 機能プラットフォームとして、データ統合、データ開発、データ管理、データガバナンスなど、幅広い製品とサービスを提供しています。
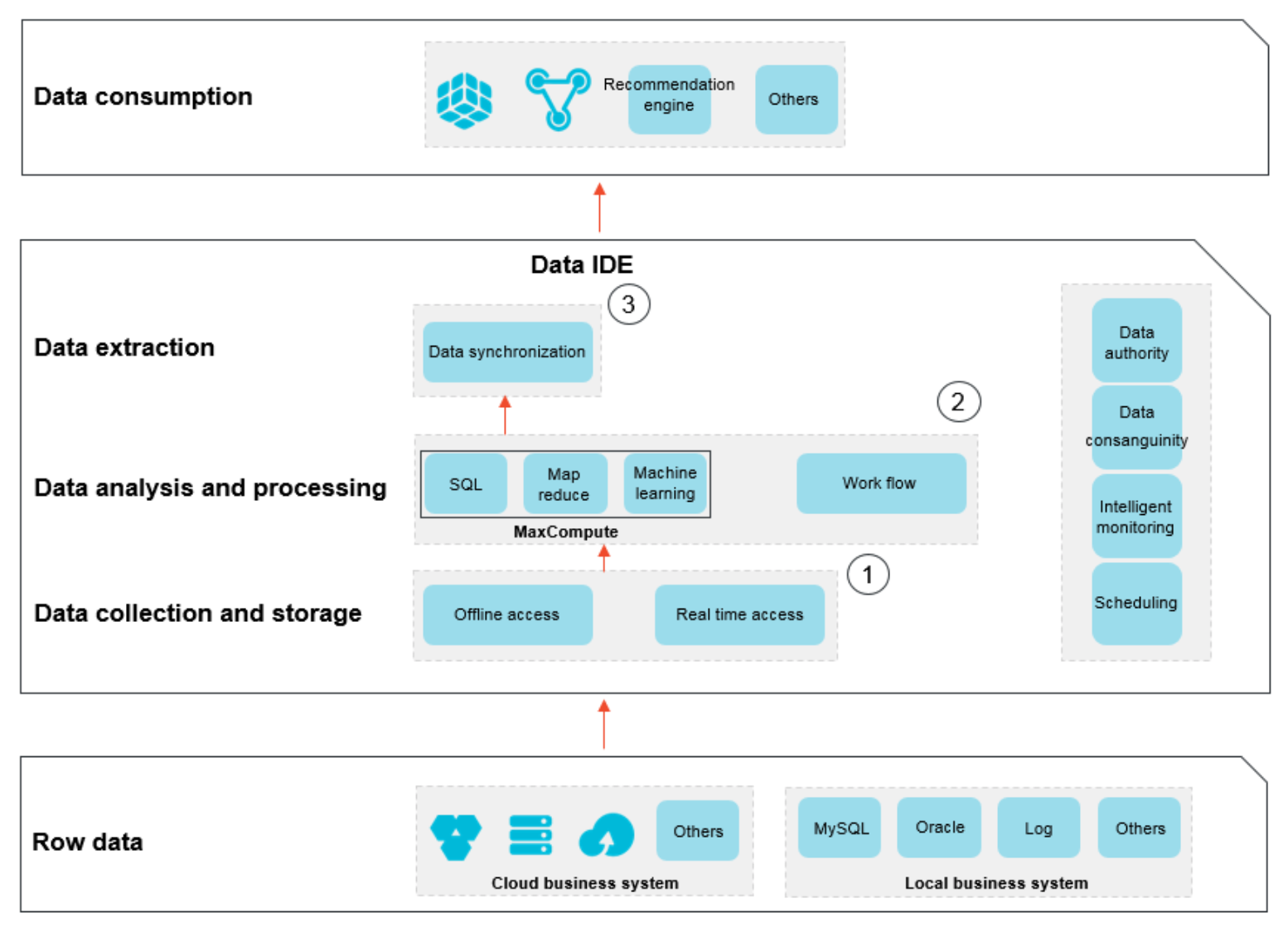
上記、公式より引用したものです。OSS から RDS,RDS から OSS などデータを移行したり、データ加工(ETL処理)などが行えるサービスというイメージですかね。
事前準備
-
Log Service へのログ投入
-
ApsaraDB for RDS(MySQL) 初期設定
- こちらの記事がわかりやすいです。
やってみる
Log Service から OSS への転送
前回、以下の様な形式でログを保存している状態でした。

上記のログを OSS LogShipper を使用し OSS に転送します。設定内容のサンプルは以下です。

ポイントとしては CSV キーがそのままテーブルのキーとなるため、ログ生成の時点でそれなりの設計を行う必要があります。また、デリミタはデフォルトでは "," となっていますが、タブに変更しています。ユーザ入力が含まれるパターンでは "," が含まれる事が多く、排除もしにくいためです。コストを考えれば圧縮すべき等ありますが、詳細はケースに合わせ変更しましょう。
以下のようなファイルが OSS 内に出力されました。

ApsaraDB for RDS(MySQL) の起動と DB, Table 等の準備
OSS ファイルのインポート先として DB, テーブルを準備します。今回は以下 DB, Table, カラム構成としています。

DataWorks 初期設定
サービスを有効化していない場合は有効化しましょう。続いてアクセスキーの作成を求められます(最初はメインアカウントで作成する必要があるかもしれません)。

アクセスキーを作成すると以下の様な画面に変わります。今回は Data Integration の機能を利用したいので、赤枠の Go Buy をクリックします。

利用対象のリージョンを選択し、購入します。

Data Integration 左のチェックボックスにチェックを付けた上で次へ進みます。

必要項目に適当に入力した上で Create Project をクリックします。私の場合、何故か1回目はアクセスキーが存在しないとのエラーが出力され失敗しました...。少し時間を置いてからもう一度クリックしたところ成功しています。

で、Project の作成が完了。
DataWorks Source 設定
続いて、DataWorks の Source 設定を行います。
Sourceとは?
DataWorks では各サービス間へデータ移行を行う機能がありますが、事前に対象サービスに接続するための設定を Source と呼んでいます。
先程、作成したプロジェクトをクリックすると以下のような画面になります。続いて、画面上部の Data Integration をクリックしましょう。

遷移した画面で左ペインの Data Source という項目をクリック。

画面右上の New Source をクリックし、Source 設定が行えます。

OSS Source 設定
色々設定可能なデータソースが表示されますが、まず OSS を選択します。入力項目は以下を参考にしてください。
| 項目名 | 値 |
|---|---|
| Name | 適当な一意となる名前をつけてください。 |
| Description | 説明文です。必須ではありません。 |
| Endpoint | OSS の Endpoint です。こちらを参照ください。 https もサポートしているとありますが、http で入力しないとエラーになりました。東京リージョンであれば http://oss-ap-northeast-1.aliyuncs.com と入力してください。 |
| Bucket | 転送元となる CSV ファイルがある Bucket を指定してください。 |
| Access Id | DataWorks が OSS アクセスに利用するアクセスキーを必要な権限を付与した上で指定してください。 |
| Access Key | 上記と同様。 |
ApsaraDB for RDS(MySQL) Source 設定
続いて RDS。以下、説明を参考にしてください。
| 項目名 | 値 |
|---|---|
| Type | 今回は ali cloud database (rds) を指定します。 |
| Name | 適当な一意となる名前をつけてください。 |
| Description | 説明文です。必須ではありません。 |
| Instance ID of RDS | RDS のインスタンス ID を指定します。 |
| Main Buyer of RDS | メインアカウントの ID です。何で必要なんだろうか? |
| Database Name | インポート先の DB 名です。 |
| Username | インポート先の DB のユーザ名です。 |
| Password | インポート先の DB のパスワードです。 |
RDS を利用する場合は事前に DataWorks が利用する IP レンジをホワイトリストに入れておく必要があります。対象の IP はこちらを参照ください(中国語のドキュメントにしか記載がない様子?)。
DataWorks Sync Tasks 作成と実行
画面左ペインの Sync Tasks をクリックします。

Wizard Mode で OSS から RDS へデータをインポートするタスクを作成しましょう。

まず、データソースとして OSS を選択。各項目を入力していきます。デリミタはタブ(\t)に変更しています。各項目入力後、data preview でインポートするデータのプレビューが閲覧可能です。

続いてデータの投入先となる RDS と Table を指定。事前に準備が済んで入ればプルダウンから選択するだけで完了です。

続いて、csv のカラムと table のキーのマッピングを行います。csv の方がわかりにくいですが、プレビューの順番通りになるので Col1 が "source",Col2 が "topic", Col3 が "message" です。

次はジョブを実行するリソースの設定。とりあえずそのままで進めます。

で、今回設定した同期タスクの命名。適当に付けて OK をクリックします。

すると、画面左ペインに今回作成したタスクが表示されるので、選択した上で "Run" をクリックします。

画面下部の log 部分にメッセージがずらずらと並びますが、処理が終わるとストップします。

今回用意したテーブルを確認したところ、ちゃんとデータが投入されていることが確認できました。

以上、簡単ではありますが、DataWorks による Data Integration の実行方法の紹介になります。
おわりに
今回は DataWorks の機能の一つである Data Integration について紹介しました。ビッグデータなど大規模なログ分析を行う上では必須となるサービスです。Alibaba Cloud には他にもログを活用する上で便利なサービスが色々あります。機会があればまた紹介させていただこうと思います。
ここまで読んでいただきありがとうございました。