はじめに
言わずと知れた鬼仏表。
ただあのサイト荒らしが多かったり~~(おもしろいからすき)~~、そもそもwebサイトを開くのがめんどうだったりしますよね。
そこで新しい鬼仏メディアを作ろうと、
鬼仏表をlinebotにしました!!
(従来の鬼仏表とは別に、新しい鬼仏表webサービスも今年誕生しました。
このlinebotは新鬼仏表を運営されている方の協力のもと、開発チームのメンバーで開発しました。)
実際に使ってみるとこんな感じです。
まず検索したい講義名を入力すると、その講義を担当している教員の一覧がずらっと表示されます。
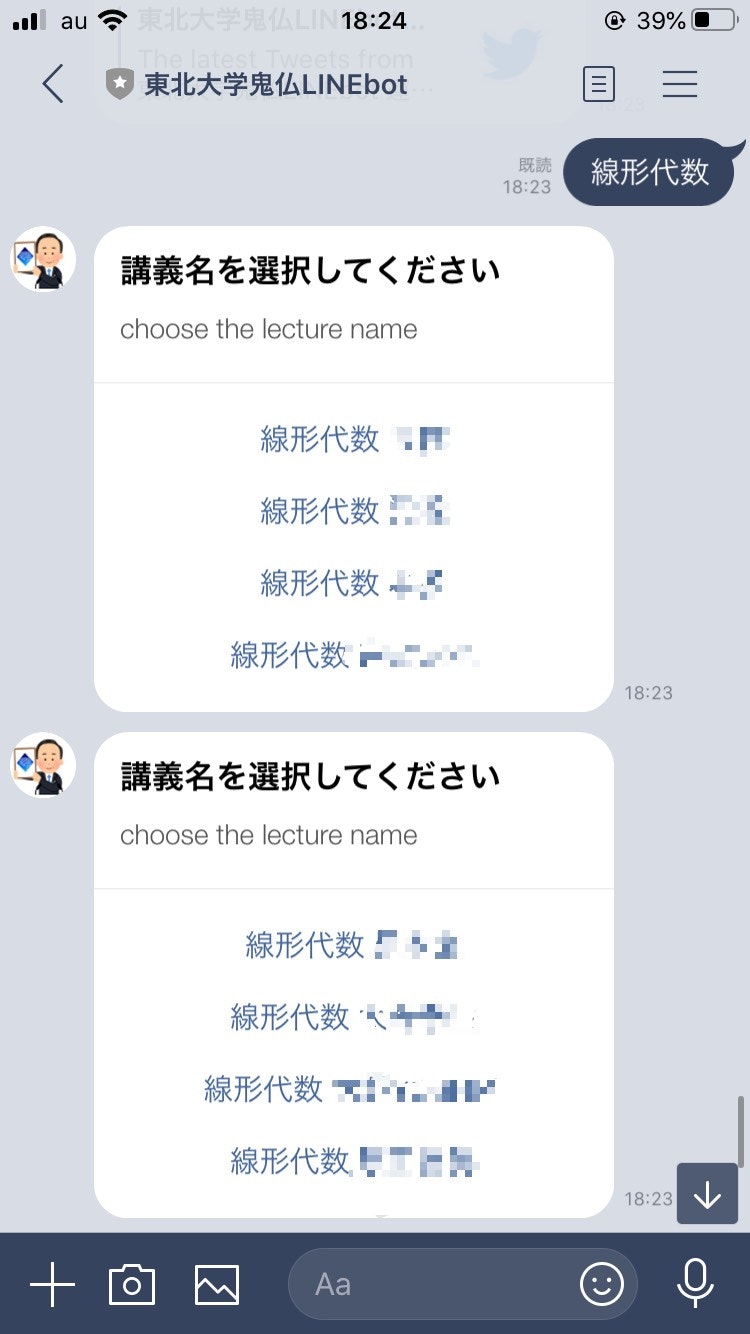
次に講義情報を見たい先生をタップすると、

その先生の講義情報が大量に送られてきます。これで楽単を簡単に探せる。すばらしい。
教員名から検索することもできます。
※講義についての情報は全て本学の学生より投稿されたものです。利用は自己責任でお願いします。
全体の実装
さっそくこのbotの構成を見ていきましょう。

まずユーザーから送信された検索ワードを、herokuサーバーに置いてあるbotが受け取る。
そしてデータベースから、検索ワードに該当する担当教員、講義名ないし講義情報を取得し、再びユーザーに返す。
というシンプルなものです。
linebot部分
まず、ユーザーとのやりとりをするlinebotのコードを軽く見ていきます。
長いので折りたたんでいます。
linebot.py
# LINEのユーザーインターフェース部分
import os
import errno
import tempfile
from random import sample
from flask import Flask, request, abort
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError, LineBotApiError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage,
SourceUser, SourceGroup, SourceRoom,
TemplateSendMessage, ConfirmTemplate, MessageAction,
ButtonsTemplate, ImageCarouselTemplate, ImageCarouselColumn, URIAction,
PostbackAction, DatetimePickerAction,
CameraAction, CameraRollAction, LocationAction,
CarouselTemplate, CarouselColumn, PostbackEvent,
StickerMessage, StickerSendMessage, LocationMessage, LocationSendMessage,
ImageMessage, VideoMessage, AudioMessage, FileMessage,
UnfollowEvent, FollowEvent, JoinEvent, LeaveEvent, BeaconEvent,
FlexSendMessage, BubbleContainer, ImageComponent, BoxComponent,
TextComponent, SpacerComponent, IconComponent, ButtonComponent,
SeparatorComponent, QuickReply, QuickReplyButton
)
from search_sql import searchLecture, searchTeacher, searchAll
from gspred import setsheet, search_last_row, record_keyword, record_error, record_notExist, record_userinfo
setsheet()
app = Flask(__name__)
line_bot_api = LineBotApi('アクセストークン') #アクセストークンを入れてください
handler = WebhookHandler('チャンネルシークレット') #Channel Secretを入れてください
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
#テキストメッセージが送信されたときの処理.
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
text = event.message.text
#教官または講義名いずれかが送信されたとき.
if "_" not in text:
teacherList = searchTeacher(text, False)#教員列からワードを検索
lectureList = searchLecture(text, False)#講義列からワードを検索
kibutsuList = []#2つのリストを結合 1つは空であるはず.
kibutsuList.extend(teacherList)
kibutsuList.extend(lectureList)
#検索結果が空でないとき,その検索結果をlabelにもつボタンを送信.
if kibutsuList:
#kibutsuListの要素数が20を超えないようにする.
if len(kibutsuList)>18:
kibutsuList = sample(kibutsuList, 18)#一応シャッフルする.何回か表示すればすべての講義を見れるように.
kibutsuList.extend(["のすべての講義"])#19個目.
kibutsuList.extend(["でもう一度探す"])#20個目
buttons_templates = []
roop = (len(kibutsuList)+3)//4 #最大4つまで表示できるテンプレートを何回表示すればいいか.
for i in range(roop):#その回数だけ回す.
if i==roop-1:#最後は4つ以下になるからスライス部分を変える必要あり.
buttons_templates.append(ButtonsTemplate(
title='講義名を選択してください', text='choose the lecture name', actions=[
MessageAction(label= text + " " + name, text= text + "_" + name) for name in kibutsuList[4*i:]
]))
break
buttons_templates.append(ButtonsTemplate(
title='講義名を選択してください', text='choose the lecture name', actions=[
MessageAction(label= text + " " + name, text= text + "_" + name) for name in kibutsuList[4*i:4*(i+1)]
]))
try:
line_bot_api.reply_message(event.reply_token,
[TemplateSendMessage(alt_text='講義を選択してください', template=buttons_template) for buttons_template in buttons_templates])
record_keyword(text)
except LineBotApiError:
line_bot_api.reply_message(event.reply_token,TextSendMessage(text="エラーのため講義情報を表示できません.エラーは報告済みです.\nhttps://twitter.com/###"))
record_error(text)
#検索結果が空だったとき、その旨をユーザーに送信
else :
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text='該当する講義情報が見つかりませんでした.\nもう一度検索名を見直してください.\
\n\nバグ,要望等がございましたら\nこちらまでご連絡ください.\n講義数が多い場合はその一部を表示しています.\nhttps://twitter.com/###'))
record_notExist(text)
#もう一度探すとき
elif "でもう一度探す" in text:
text = text.split("_")[0]
teacherList = searchTeacher(text, False)#教員列からワードを検索
lectureList = searchLecture(text, False)#講義列からワードを検索
kibutsuList = []#2つのリストを結合 1つは空であるはず.
kibutsuList.extend(teacherList)
kibutsuList.extend(lectureList)
#検索結果が空でないとき,その検索結果をlabelにもつボタンを送信.
if kibutsuList:
#kibutsuListの要素数が20を超えないようにする.
if len(kibutsuList)>18:
kibutsuList = sample(kibutsuList, 18)#一応シャッフルする.何回か表示すればすべての講義を見れるように.
kibutsuList.extend(["でもう一度探す"])#19個目
kibutsuList.extend(["のすべての講義"])#これで丁度20こ目.
buttons_templates = []
roop = (len(kibutsuList)+3)//4 #最大4つまで表示できるテンプレートを何回表示すればいいか.
for i in range(roop):#その回数だけ回す.
if i==roop-1:#最後は4つ以下になるからスライス部分を変える必要あり.
buttons_templates.append(ButtonsTemplate(
title='講義名を選択してください', text='choose the lecture name', actions=[
MessageAction(label= text + " " + name, text= text + "_" + name) for name in kibutsuList[4*i:]
]))
break
buttons_templates.append(ButtonsTemplate(
title='講義名を選択してください', text='choose the lecture name', actions=[
MessageAction(label= text + " " + name, text= text + "_" + name) for name in kibutsuList[4*i:4*(i+1)]
]))
try:
line_bot_api.reply_message(event.reply_token,
[TemplateSendMessage(alt_text='講義を選択してください', template=buttons_template) for buttons_template in buttons_templates])
record_keyword(text)
except LineBotApiError:
line_bot_api.reply_message(event.reply_token,TextSendMessage(text="エラーのため講義情報を表示できません.エラーは報告済みです.\nhttps://twitter.com/###"))
record_error(text)
#検索結果が空だったとき、その旨をユーザーに送信
else :
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text='該当する講義情報が見つかりませんでした.\nもう一度検索名を見直してください.\
\n\nバグ,要望等がございましたら\nこちらまでご連絡ください.\n講義数が多い場合はその一部を表示しています.\nhttps://twitter.com/###'))
record_notExist(text)
#『〇〇のすべての講義』のボタンが押されたとき、その〇〇の検索結果をすべて表示
elif "のすべての講義" in text:
text = text.split("_")[0]#リストになってる
teacherList = searchTeacher(text, True)#教員列からワードを検索
lectureList = searchLecture(text, True)#講義列からワードを検索
kibutsuList = []#2つのリストを結合 1つは空であるはず
kibutsuList.extend(teacherList)
kibutsuList.extend(lectureList)
messages =[]
print(len(kibutsuList))
if kibutsuList:
#フォーマットを整える
if len(kibutsuList)<5:#4件しかないときはほぼ確実に送れる
for kibutsuDict in kibutsuList:#5件まで.
message = ""
for key, value in kibutsuDict.items():
message += key + " : " + value + "\n"
message += "--------------------------\n"
messages.append(message)
else:#4件以上あるときは文字数オーバーする可能性があるため,同じ吹き出しに複数個の講義情報をのせる
message = ""
for kibutsuDict in kibutsuList:
for key, value in kibutsuDict.items():
message += key + " : " + value + "\n"
message += "--------------------------\n"
message += "\n####################\n\n"
if len(message)>1250:#一度に送れるのが2000文字までなので,一応1250文字を超えていたら別にわける.
messages.append(message)
message = ""
#最後にツイッターのリンクをつける
messages.append("バグ,要望等がありましたらこちらまでご連絡ください.\n講義数が多い場合はその一部を表示しています.\nhttps://twitter.com/###")
try:
line_bot_api.reply_message(event.reply_token, [TextSendMessage(text=message) for message in messages[-4:]])#5つだけ送信(すべてではない)
record_keyword(text)
except LineBotApiError:
line_bot_api.reply_message(event.reply_token,TextSendMessage(text="エラーのため講義情報を表示できません.エラーは報告済みです.\nhttps://twitter.com/###"))
record_error(text)
#検索結果が空だったとき、その旨をユーザーに送信
else:
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text='該当する講義情報が見つかりませんでした.\nもう一度検索名を見直してください.\
\n\nバグ,要望等がございましたら\nこちらまでご連絡ください.\n講義数が多い場合はその一部を表示しています.\nhttps://twitter.com/###'))
record_notExist(text)
#教官名と講義名のどちらも送信されたとき、その講義の鬼仏情報をユーザーに送信
elif "_" in text:
texts = text.split("_")#『教官名_講義名』 という入力を期待している
kibutsuList = searchAll(texts[0], texts[1])#特定の講義の鬼仏情報を取得
messages = []
if kibutsuList:
#フォーマットを整える
if len(kibutsuList)<5:#4件しかないときはほぼ確実に送れる
for kibutsuDict in kibutsuList:#5件まで.
message = ""
for key, value in kibutsuDict.items():
message += key + " : " + value + "\n"
message += "--------------------------\n"
messages.append(message)
else:#4件以上あるときは文字数オーバーする可能性があるため,同じ吹き出しに複数個の講義情報をのせる
message = ""
for kibutsuDict in kibutsuList:
for key, value in kibutsuDict.items():
message += key + " : " + value + "\n"
message += "--------------------------\n"
message += "\n####################\n\n"
if len(message)>1250:#一度に送れるのが2000文字までなので,一応1000文字を超えていたら別にわける.
messages.append(message)
message = ""
#最後にツイッターのリンクをつける
messages.append("バグ,要望等がありましたらこちらまでご報告ください.\n講義数が多い場合はその一部を表示しています.\nhttps://twitter.com/###")
try:
line_bot_api.reply_message(event.reply_token, [TextSendMessage(text=message) for message in messages[-5:]])
record_keyword(text)
except LineBotApiError:
line_bot_api.reply_message(event.reply_token,TextSendMessage(text="エラーのため講義情報を表示できません.エラーは報告済みです.\nhttps://twitter.com/###"))
record_error(text)
else:
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text='該当する講義情報が見つかりませんでした.\nもう一度検索名を見直してください.\
\n\nバグ,要望等がございましたら\nこちらまでご連絡ください.\n講義数が多い場合はその一部を表示しています.\nhttps://twitter.com/###'))
record_notExist(text)
else :
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text="教官名または講義名を入力してください.\
\nバグ,要望等がありましたらこちらまでご報告ください.\nhttps://twitter.com/###"))
if __name__ == "__main__":
app.debug=True
port = int(os.environ.get('PORT', 8000))
app.run(host ='0.0.0.0',port = port)
めちゃくちゃ長い。。。ユーザーに送信するメッセージの整形に苦戦しました。。
簡単に説明すると、受け取った検索ワードをもとに、searchTeacher()とsearchLecture()でデータベースを検索し、その結果をユーザーに表示しています。
それに加え、検索ワードと エラーが出た検索ワードと ヒットしなかった検索ワードを分けてGoogleスプレッドシートに記録しています。record_keyword(), record_error(), record_notExist()がその役割です。エラーは報告済みですとはこういうことだったんですね。
データベースから検索する
次はデータベースを検索する関数です。
search_database.py
# データベースから講義データを検索する
import psycopg2
import psycopg2.extras
import os
from sqlalchemy import create_engine
import neologdn
keys = ["subject", "teacher", "difficulty", "worth", "comment", "test", "report", "attendance", "post date"]
# 入力されたSQLを用いてselectを行い,リストを返却する.
def get_dict_resultset(sql):
with get_connection() as conn:
with conn.cursor(cursor_factory=psycopg2.extras.DictCursor) as cur:
cur.execute (sql)
results = cur.fetchall()
return results
def get_connection():
dsn = "postgres:###:#####@###/###"
return psycopg2.connect(dsn)
# 講義名を受け取り,その講義を担当している教授名を返す.
def searchTeacher(text, bool):
text = neologdn.normalize(text)#正規化
sql_lecture = f"select * from lecture_assessments where subject LIKE '%{text}%'"
lecture_info = get_dict_resultset(sql_lecture)#検索結果が入っている.
teacher_info_list = []
if bool:
#[{'subject': '', 'teacher': '', 'difficulty': 'ど鬼', 'worth': '', 'comment': 'Pythonに関する授業',
# 'test': '', 'report': '', 'attendance': ''},
# {'subject': '', 'teacher': '', 'difficulty': '仏', 'worth': '', 'comment': '機械学習に興味があるけどよく知らないという人にはよさそう',
# 'test': '', 'report': 'あり', 'attendance': 'あり'}] こういう辞書のリストをつくる
teacher_info_list = [{key:value for key, value in zip(keys, _lecture_info)} for _lecture_info in lecture_info]
else:
if lecture_info:
teacher_info_list = list(set([_lecture_info[1] for _lecture_info in lecture_info]))#教授名だけのリスト. 一度setにしてからlistに戻すことで,重複している要素を除いている.
if teacher_info_list[0]=="":#先頭が空であることが多いので,それを除去.
teacher_info_list = teacher_info_list[1:]
return teacher_info_list
# 教官名を受け取り,担当している講義名を返す
def searchLecture(text, bool):
text = neologdn.normalize(text)
sql_lecture = f"select * from lecture_assessments where teacher LIKE '%{text}%'"
lecture_info = get_dict_resultset(sql_lecture)#検索結果が入っている
lecture_info_list = []
if bool:
lecture_info_list = [{key:value for key, value in zip(keys, _lecture_info)} for _lecture_info in lecture_info]
else:
if lecture_info:
lecture_info_list = list(set([_lecture_info[0] for _lecture_info in lecture_info]))#教授名だけのリスト.
if lecture_info_list[0]=="":
lecture_info_list = lecture_info_list[1:]
return lecture_info_list
# 講義名と教官名を受け取る.ただし順番はわからない.
def searchAll(text1, text2):
list1 = searchTeacher(text1, True)#とりあえずどっちのワードでも検索してみて,つなげてる.
list2 = searchTeacher(text2, True)
list1.extend(list2)#講義名でヒットした講義が格納されている.
list3 = searchLecture(text1, True)#とりあえずどっちのワードでも検索してみて、つなげてる.
list4 = searchLecture(text2, True)
list3.extend(list4)#教官名でヒットした講義が格納されている.
all_info = [lec for lec in list1 if lec in list3]#共通の要素を抽出.
return all_info
searchTeacher関数とsearchLecture関数は、"subject"や"teacher"を参照し、検索ワードに該当する講義情報を取得します。
詳しくは触れませんが、これらの関数は第二引数のbool値で挙動が変わります。
リスト内包辞書内包表記をしていてホクホクです。
データベースを作成する
次は検索していたデータベースをどのように作成しているか見てみます。
gen_database_old.py
# 旧鬼仏表の全講義データをスクレイピングしてきてDataFrameに固めて、データベースにインサートする
from urllib.error import HTTPError # HTTPのエラーを抽出
from urllib.error import URLError # URLのエラーを抽出
from urllib.request import urlopen
from bs4 import BeautifulSoup as bs
import re
import pandas as pd
from sqlalchemy import create_engine
import neologdn
from time import sleep
# webサイトの講義ページのid一覧を取得
def extract_ids():
my_html = open("input/all.html",encoding="utf-8_sig").read()
pattern = r'number=(.*)&university'
matchs = re.finditer(pattern, my_html)
return [match.groups()[0] for match in matchs]
url_1= "https://www.kibutu.com/search2.php?number="
url_2 = "&university=tohoku"
ids = extract_ids()
# 順にスクレイピングしていく
describes = []
for id_num in ids:
full_url = url_1 + id_num + url_2
html_file = urlopen(full_url)
soup = bs(html_file, "html.parser")
tables = soup.find_all("table")
describes.append(tables[len(tables)-1] if tables else "")#後ろから2番目のtableがお目当て
print(id_num," done~")
sleep(0.05)
parsed = [str(each).split("</font>") for each in describes]#tableが一続きの要素になっているのでfontで分割する
limited = [[each[2*n+1] for n in range(int(len(each)/2))] for each in parsed ]#凡例を取り除き、値だけを抽出
# 余計な部分を省き、ユーザーへの出力似合わせて並び替える
completed = []
for each in limited:
_limited = []
sorted = []
for _each in each:
#正規表現でうまくcommentを取得できなかったため24文字目以降を取得するかたちに変更
gotten = _each[24:]
gotten = neologdn.normalize(gotten)
_limited.append(gotten)
_limited.append("")#worthに対応する""を追加
sorted.append(_limited[1])#出力に合わせてソートする
sorted.append(_limited[0])
sorted.append(_limited[4])
sorted.append(_limited[9])
sorted.append(_limited[8])
sorted.append(_limited[5])
sorted.append(_limited[6])
sorted.append(_limited[7])
sorted.append(_limited[3])
completed.append(sorted)
columns = [
"subject",
"teacher",
"difficulty",
"worth",
"comment",
"test",
"report",
"attendance",
"posted date"
]
df_completed = pd.DataFrame(completed, columns=columns)
print("now inserting")
# heroku postgresにテーブルを作成
engine = create_engine("postgres://###@####/###")
df_completed.to_sql("tablename", engine, if_exists="append", index=False)
print("completed")
ざっくり説明すると、従来の鬼仏表から講義情報をがんばってスクレイピングしてきて整形し、pandasのDataFrameにしてからデータベースに突っ込んでいます。
続いて、お借りした新鬼仏表のデータベースのデータを、ユーザーへの出力に合わせて整形します。そして先ほどと同じデータベースに突っ込みます。
gen_database_new.py
# 新鬼仏表のデータベースから必要なデータだけを抽出して整理し、新しいデータベースに突っ込む
import psycopg2
import psycopg2.extras
import os
from sqlalchemy import create_engine
from neologdn import normalize
import pandas as pd
import re
# DBからDFを作成
dsn = "postgres://###@####/###"
connection = psycopg2.connect(dsn)
df_ass = pd.read_sql(sql='select * tablename1;', con=connection)
df_lec = pd.read_sql(sql='select * tablename2;', con=connection)
df_merge = pd.merge(df_ass, df_lec, left_on="lecture_id", right_on="id" ,how="inner") #lecture_idとidで2つのDFを結合している
df_new = df_merge.loc[[i for i in range(len(df_merge))],["subject","teacher","difficulty","worth","comment"]] #欲しいとこだけ取り出す
# subjectとteacherを正規化
columns = ["subject","teacher"]
for column in columns:
values = df_merge.loc[list(range(len(df_merge))),[column]].values
df_new[column] = [normalize(value[0]) for value in values]
# bool値になっている列の要素を文字列に変換してから追加
columns = ["Test","report","attendance"]
for column in columns:
values = df_merge.loc[list(range(len(df_merge))),[column]].values
column = "test" if column == "Test" else column #Testだけなぜか大文字だから微修正
df_new[column] = ["あり" if value else "なし" for value in values]
# 投稿年月日の列を追加
post_date_values = df_merge.loc[list(range(len(df_merge))),["created_at_x"]].values #created_at_x列の値を格納
df_new["posted date"] = [str(pdv)[2:12] for pdv in post_date_values]
# heroku postgresにテーブルを作成
engine = create_engine("postgres://###@####/###")
df_new.to_sql("tablename3", con=engine, if_exists="append", index=False)
検索ワードやエラーをGoogleスプレッドシートに記録する
最後に、どのようなワードが検索されたのか、またエラーとなった検索ワードがないかを確認するために、それらをGoogleスプレッドシートに記録します。
googlespredsheet.py
import gspread
from oauth2client.service_account import ServiceAccountCredentials
def setsheet():
scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('JSONフfilename.json', scope)
global worksheet
gc = gspread.authorize(credentials)
gc = gc.open("sheetname")
worksheet = gc.worksheet("")#管理シートを指定
def search_last_row(num):
row_count = 1
while worksheet.cell(row_count, num).value:
row_count += 1
return row_count
def record_keyword(keyword):
worksheet.update_cell(search_last_row(1), 1, keyword)
def record_error(keyword):
worksheet.update_cell(search_last_row(2), 2, keyword)
def record_notExist(keyword):
worksheet.update_cell(search_last_row(3), 3, keyword)
最後に
まだまだ開発途上のlinebotですが、10月のリリース以降 使っていただいた約500人のみなさんに感謝です。
今後機能を追加し、来春までにアップデートしてリリースする予定です!
お楽しみに!