E資格取得のためラビットチャレンジに挑戦しています。

Section3:GRU
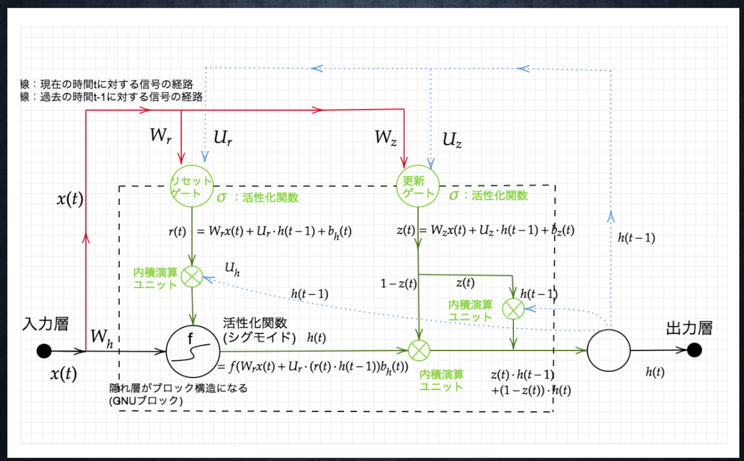
ポイント
- Gated recurrent unit
- LSTMの弱点だった、パラメータ数を大幅に削減し、精度は同等またはそれ以上が望めるようになった構造
- 計算負荷が低い
確認テスト
- LSTMとCECが抱える課題について、それぞれ簡潔に述べよ
=> LSTM: パラメータが多く計算コストが高い
CEC:入力データについて、時間依存度に関係なく重みが一律であるためニューラルネットワークの学習特性がなくなってしまうため学習が行えない。
演習チャレンジ

=>(4)
確認テスト
- LSTMとGRUの違いを簡潔に述べよ
=>LSTMはパラメータ数が多いがGRUはパラメータの数が少なく計算コストも低い
考察
パラメータの数によって計算コストに差が出る。
LSTMがGRUより優れている点をあとで調べる。
参考
Section4:双方向RNN
ポイント
- 過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデル
- 文章の推敲や、機械翻訳に使われる。

演習チャレンジ

=>(1)×
=>(4)
Section4:Seq2Seq

ポイント
- Encoder-Decoderモデル
- 機械対話や、機械翻訳に使用されている
- 一問一答しかできない
5-1 Endoder RNN

ポイント
- ユーザがインプットしたテキストデータを単語等のトークンに区切って渡す構造
- Taking:文章を単語等のトークン毎に分割し、トークン毎のIDに分割する
- Embedding:IDから、そのトークンを表す分散表現ベクトル(言語を数値化)に変換
- Encoder RNN: ベクトルを順番にRNNに入力していく
- vec1をRNNに入力し、hidden stateを出力
- hidden stateとvec2をRNNしhidden state出力を繰り返す
- 最後のVecを入力したときのhidden stateをfinal stateとする。
- final stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる。
5-2 Decoder RNN

ポイント
- システムがアウトプットデータを。単語等のトークン毎に生成する構造
- Encoder RNNのfinal state(thought vector)から、各tokenの生成確率を出力いく
- final stateをDecoderのinitial stateととして、Embeddingを入力
- sampling: 生成確率に基づいてtokenをランダムに選ぶ
- Embedding:選ばれたtokenをembeddingして次の入力とする
- Detokenize:上記を繰り返しtokenを文字列に直す
確認テスト

=>(2)
演習チャレンジ

=>(1)
5-3 HRED
ポイント
- Seq2seqの一問一答しかできない課題を解決
- 過去n-1個の発話から次の発話を生成する
- seq2seq + Context RNN
- Context RNN
- Encoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造
- 文脈もベクトル化
- 過去の発話の履歴を加味した返答ができる
- HREDは短く情報量に乏しい答えをしがち
5-4 VHRED
ポイント
- HREDに、VAE(Variational Autoencoder)の潜在変数の概念を追加したもの
- HREDno課題をVAEの潜在変数の概念を追加することによって解決した構造
確認テスト
- seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ
=> seq2seqは一問一答しかできないがHREDは過去の発話の履歴を加味した返答ができる
HREDは短く情報量に乏しい答えをしがちだがVHREDはVAEの潜在変数を追加することによって改善している。
5-5 VAE
5-5-1 オートエンコーダ
ポイント
- 教師なし学習
- 教師データは利用しない
- 入力データから潜在変数zに変換するニューラルネットワークをEncoder、逆に潜在変数zをインプットとして元画像を復元するニューラルネットワークをdecoderとする。
- 次元削減可能
- zの次元が入力データより小さい場合、次元削減とみなすことができる
- zの構造状態が不明

5-5-2 VAE
- zに確率分布z~N(0,1)を仮定してもの
- データのを潜在変数zの確率分布という構造に押し込められることを可能にする

確認テスト

=>確率分布
Section6: Word2vec

ポイント
- RNNでは、単語のような可変長文字列をNNに与えることはできない課題を解決
- 固定長形式で単語を表す必要があるったものを可変長も扱え得るようにした
- 学習データからボキャブラリーを作成する
- one-hotベクトル
- あるカラムだけ1で他のカラムは0な行列の表現
- 大規模データの分散表現学習が可能
- ボキャブラリ数×任意単語ベクトルの次元数の重みの行列
- 長い文章に対しての対応が難しい(固定次元ベクトル)
Section7: Attention Mechanism
ポイント
- 文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組み
- 入力と出力のどの単語が関連しているのかの関連度を学習する

確認テスト
- RNNとword2vec,seq2seqとseq2seq+Attentionの違いを簡潔に述べよ
=> RNNが固定長形式、Word2vecは可変長形式。
=>seq2seqは長い文章に対しての対応は難しいが、Attentionは関連度を学習することによって長い文章にも対応できるような仕組みになっている
演習チャレンジ
=>(2)w.dot(np.concatenate([left,right]))