PyTorch とかで複数GPUを使って学習する場合に DP と DDP って何が違うのか毎回調べてたのでまとめました。
本記事は下記記事やドキュメントをさらに噛み砕いたものとなっています。
特に一つ目の記事は少し前の記事ですがわかりやすいのでおすすめです。
- Distributed data parallel training using Pytorch on AWS – Telesens
- DataParallel — PyTorch 1.9.0
- Distributed Data Parallel — PyTorch 1.9.0
Q. DP と DDP どっち使えばよいの?
A. DDP 使え(DDPの方が速いし PyTorch のドキュメントでも DDP が推奨されてるから)
結論: 学習時の DP と DDP の違い
- 複数GPUがある想定で、
GPU:0とそれ以外の GPU を他GPUとします - GPU間通信(データの送信)が起きる場所を☆ + 太字で表します
- 雑に言うと DP の場合1回のパラメータ更新に対し GPU:0 を起点とした GPU 間通信(データ送信)回数が DDP より多いです
- そのため
DP の方が遅くなりやすい = DDP の方が速くなりやすいです
- そのため
| 項目 | DP | DDP |
|---|---|---|
| Dataloader | GPU:0 のみ所有 | 各GPUで所有(この時点でDatasetを分割済) |
| batch の分割(mini batch作成) | GPU:0 で行われる | なし(Dataloader 作成の時点で分割されている) |
| mini batch のGPU間共有 | ☆ GPU:0 から他GPUに送られる | なし(Dataloader 作成の時点で分割されている) |
| モデルパラメータの共有 | ☆ GPU:0 でパラメータを更新する度他GPUに送られる | 初回のみ行われる |
| forward pass 計算 | 各GPUで行われる | 各GPUで行われる |
| loss 計算 | ☆ 他GPUからGPU:0 にoutputsを送信して GPU:0 で行われる | 各GPUで行われる |
| 勾配計算 | ☆ GPU:0 から他GPUにlossを送信して各GPUで計算する | 各GPUで行われる |
| モデルパラメータ更新 | ☆ 他GPUから GPU:0 に勾配値を送信して GPU:0 でパラメータ更新される | ☆ 各GPU間で勾配を送信して集計後勾配値を得て、それを使って各GPUで更新する |
1. Single GPU での学習時の挙動について
ここでは DP と DDP の違いを説明するために、通常の Single GPU での学習の要点を記載します。
- Dataloader を一つ用意する
- 下記のように1batchあたりの学習を行う
for batch in Dataloader
inputs, targets = batch
outputs = Model(inputs) # Run forward pass = forward pass 計算
loss = Loss(outputs, targets) # Loss 計算
loss.backward() # backward pass 計算と勾配計算
Model.parameter.update() # Model のパラメータ更新
2. DP と DDP の学習時の挙動
図は Distributed data parallel training using Pytorch on AWS – Telesens より引用。
2.1 DP (Data Parallel)
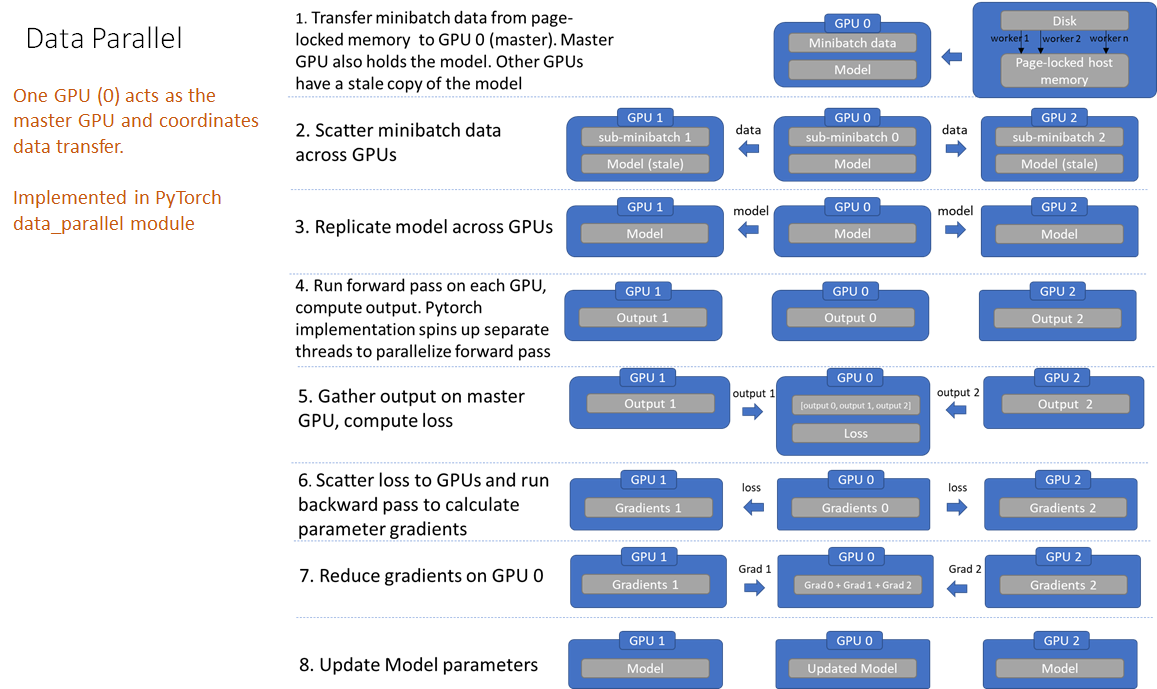
ここではGPU0 と GPU0 以外のGPUを 他GPU として説明します。
☆ + 太字 の行はGPU間通信が発生している場所を表します。
DP の場合1回のモデルパラメータ更新に対して複数回 GPU 間通信が発生していることがわかります。
-
GPU0にディスクからデータを読み込み - ☆
GPU0から他GPUに対しbatchを分割して送信する - ☆ 最新のモデル(のパラメータ) を
GPU0から他GPUに送信する - 各GPUで forward pass 計算
outputs = Model(inputs)
- ☆
他GPUからGPU0に outputs を集約して loss を計算する- loss の計算は分割前の batch で計算される
- ☆ loss を
GPU0から他GPUに送信して各 GPU でモデルの各パラメータの勾配を計算する-
他GPUでも勾配を計算するのは、各 GPU でinputsが異なるため forward pass も変わりうる可能性があるため
-
- ☆
他GPUからGPU0に各パラメータを送信して集計する -
GPU0でモデルのパラメータを更新する
2.2 DDP (Distributed Data Parallel)
図は Distributed data parallel training using Pytorch on AWS – Telesens より引用。

☆ + 太字 の行はGPU間通信が発生している場所を表します。
DDP の場合1回のモデルパラメータ更新に対して1度のみGPU間通信を行えば良いです(勾配値の共有)
(正確にはあるGPUでは 全GPU数 - 1 回だけ通信する)
DDP の方が DP よりGPU間の通信(データ送信)回数や量が少ないため、基本的に DDP の方が速いです。
- 各GPUに対し予め Dataloader を用意する
- 各Dataloader でデータが重複しないようにする
- 各GPU 担当の Dataloader がディスクからデータを読み込む
- 各GPUで forward pass 計算
outputs = Model(inputs)
- ☆ 各GPUでLossを計算し、モデルの各パラメータの勾配を計算してGPU間で勾配を集計する
- この時点で各GPUで同じ勾配値を持つ
- このとき
GPU0を介さないデータ送信も起きる(e.g. GPU1 と GPU2 間) - 例えば全 GPU が 3 つの場合、あるGPUで計算した勾配値の 1/3 を他 GPU に向けて送れば良い
- 各GPU でパラメータ更新
- 初めに一度だけ同じパラメータのモデルを共有し、後に共有される勾配値が同じ値であればパラメータ更新後も同じパラメータのモデルとなる