導入
- ここ数年(2018~2023)のLocal Feature Matching(局所特徴量マッチング、以下LFM)ってどんな感じなんだろうと気になっていたのですが、いい感じの Survey論文1 があったので読んでみました
- どちらかといえば個人用メモです
- そもそもこのタスクって何?何に使えるの?みたいな話は以下の内容とかこちらの記事2 とか読むとよいかと思います
- 応用例: マッチング結果を使った3次元復元や画像補正(位置・向き)
- 以下に記載された画像や表で特に説明のないものは元論文1から引用したものと判断してください
- 論文にない私の注釈にはなるべく※をつけるようにしてます
- 一部の章は省略しました。気になる人は元論文を読んでください
論文まとめ
0. Abstract
- LFM は幅広いところで使われている
- 画像検索・位置合わせ
- 3D再構成
- 物体認識
- しかし、視点や照明の変化などの要因により、マッチングの精度とロバスト性を向上させることに課題が残っている
- 近年では DeepLearning を用いた研究が広まっており、下記のように分類できる
-
Detector-based
- Detect-then-Describe
- Joint Detection and Description
- Describe-then-Detect
-
Detector-free
- CNN Based
- Transformer Based
- Patch Based
-
Detector-based
- 我々の研究は方法論的分析にとどまらず、一般的なデータセットの評価や、最新技術の定量的比較を容易にするためのメトリクスを組み込んでいる
- また、本論文では、動きからの構造、リモートセンシング画像登録、医療画像登録などの多様な領域における局所特徴マッチングの実用的な応用を探求し、様々な分野におけるその汎用性と重要性を強調する
- 最終的には、この領域で直面している現在の課題を概説し、今後の研究の方向性を示すことで、LFMとその関連領域に関わる研究者の参考となるよう努める
1. Introduction
- LFMの主な目的: 異なる画像間の正確な特徴相関を確立すること
- 画像特徴例
- keypoints(キーポイント)
- feature regions(特徴領域)
- straight lines(直線)
- curves(曲線)
- 画像特徴例
- 以下のようなタスクの基礎となる
- image fusion
- visual localization
- SfM(Structure from Motion)
- SLAM(Simultaneous Localization and Mapping)
- optical flow
- image retrieval(画像検索)
- しかし以下のような影響によって異なる画像内の同一の物理空間の描写はかなりの乖離を示すことがある
- scale transformations(スケール変換)
- view-point diversity(視点の多様性)
- shifts in illumination(照明の変化)
- pattern recurrences(パターンの繰り返し)
- texture variations(テクスチャの多様性)
- 上記のような課題もあるため LFM における精度と信頼性の追求は未だに難しい問題となっている
- 従来の image matching pipline
- feature detection(特徴検出)
- feature description(特徴記述)
- ※ どのように特徴を表現するかということ(主に特徴ベクトルの作り方を指す)
- ※ Deep Learning に馴染んでる場合特徴表現や特徴抽出と置き換えたほうがわかりやすい気もしますが、こちらの記事2にもあるようにLFMの分野では記述や記述子といった表記がしばしば用いられるようです
- feature matching(特徴マッチング)
- 従来のアプローチでは差分二乗和や相関などの特定のmetricsの最小化または最大化をすることが多かった
- geometric transformation estimation(幾何学的変換推定)
- 基礎となるエピポーラ幾何やホモグラフィを推定するために RANSAC のようなアルゴリズムが一般に採用されていた
- 上記の手法は特定の変換に強いがタスクに対する固有の事前知識によって本質的に制限されていた
- 近年では LFM に関連する課題(特にスケール変化、視点移動、その他の多様性)において大幅な進捗があった
- 現存する LFM は下図のように分類できる

1.1 代表的な LFM 年表

- 各色
- 青と灰色: Detector-based methods
- 灰色: Graph Based methods
- 黄色と緑: Detector-free methods
- 黄色: CNN Based
- 緑: Transformer Based
- 青と灰色: Detector-based methods
- Superpoint(2018)3 は単一ネットワーク内でのキーポイントと記述子を計算した先駆者
- 同時に NCNet(2018)6 は LFM に4次元コストボリュームを導入し、Detector-free methods として相関ベースまたはコストボリュームベースの CNN を利用し始めた
- 2020年には SuperGlue(2020)11 がタスクを2組の特徴量を含むグラフマッチング問題として設定した
- 2021年には LoFTR(2021)14 や Aspanformer(2022)15 などのアプローチが Transformer や Attention を Detecotr-free マッチングプロセスに組み込むこんだ
- self-attention と cross-attention を交互に組み込むことにより達成
- ※ ここでは2枚の画像を入力とした場合に1枚の画像内でのみ適用される attention を self-attention、2枚の画像間で適用される attention を cross-attention としている
- これにより受容野を大幅に拡大し、Deep Learning based のマッチング技術をさらに進化させた
- self-attention と cross-attention を交互に組み込むことにより達成
2. Detector-based Models
- Detector-based な手法はかなりの期間局LFMのための一般的なアプローチであった
- SIFT や ORB を含む数多くの確立された handcrafted work が3Dコンピュータビジョンの分野における様々なタスクに広く採用されている
- これらの伝統的な Detector-based な手法は通常以下の3つのStepから構成される
- feature detection(特徴検出)
- 画像から疎なキーポイントのセットが抽出される
- feature description(特徴記述)
- 上記のキーポイントは高次元ベクトルを用いて特徴付けられる
- 多くの場合、これらのキーポイントを囲む領域の特定の構造と情報をカプセル化するように設計される
- feature matching(特徴マッチング)
- 最近傍探索やより複雑なマッチングアルゴリズムによってピクセルレベルでの対応が確立される
- 注目手法
- Gms(Grid-based Motion Statistics)
- grid-based motion statistics を使って特徴対応品質を向上させマッチングを簡素化し高速化する
- OANET(Order-Aware Network)
- 「正確な対応のための spatial contexts」と「geometry estimation」を統合
- 上記によって two-view matching を最適化している
- 通常上記は異なる画像間の keypoints の高次元ベクトルを比較して類似度に基づくmatchingを行うことによって実現している
- Gms(Grid-based Motion Statistics)
- feature detection(特徴検出)
- しかし Deep Learning の時代では LIFT のような data-driven な手法が台頭している
- CNNを活用することにより、よりロバストで識別性の高い keypoint descriptor を抽出する
- その結果大きな視点変化や局所的な証明変化にも対応できるようになり大きく進歩した
- CNNを活用することにより、よりロバストで識別性の高い keypoint descriptor を抽出する
- 現在 Detector-based な手法や Detector-free な手法は下図のように分けられる
- また Detector-based な手法のうち Detect-then-Describe(検出してから記述する)・Joint Detection and Description(検出と記述をつなげる)・Describe-then-Detect(記述してから検出する)は下図のような違いがある

2.1 Detect-then-Describe
- feature matching では一般的に sparse-to-sparse feature matching が採用される
- これらの手法は「Detect-then-Describe(検出してから記述する)」を前提とすることが多い
- Detect-then-Describe は下記のようなステップを踏む
- detector により keypoints の位置検出を行う
- detector を使って各 keypoint を中心とするパッチから feature descriptors(特徴記述子)を抽出する
- これらの feature descriptor は次の feature description stage に送られる
- この手順は通常 metric learning で学習される
- 類似している点同士は近く、類似していない点同士が遠くなるような距離関数を設定して
- 効率を良くするため feature detector は小さい画像領域に焦点を当て、corners や blobs といった low-level structures を強調する
- 一方で descriptor(記述子) は keypoint を含むより大きいパッチ内でより意味のある高次の情報を捉えることを目的としている
- ※ 検出に必要な特徴量と、他の画像と LFM するために必要な特徴量は異なる
2.1.1 Fully-Supervised
- LFM の分野はアノテーションつきパッチデータセット(2010)16の出現と Deep Learning 技術の統合によって大きく進歩した
- 従来の hand-craft な手法から data-driven な手法へ
- 特に CNN は記述子の学習プロセスに革命を起こす上で極めて重要な役割を果たしてきた
- 生の局所パッチから直接エンド・ツー・エンドの学習を可能にすることで、CNNは局所特徴の階層構造の構築を容易にした
- この機能により、CNNはデータ中の複雑なパターンを捉えることができるようになり、より専門的で明確な記述子の作成につながった
- その結果としてマッチング精度も大きく進歩した
- この転換は L2Net(2017)17 のような革新的なモデルの影響を大きく受けている
- L2Netのアプローチ: 中間的な特徴マップに追加的な監視を適用しながら、記述子間の相対的な距離を強調する
baseフレームワークの時系列的進歩
- OriNet(2016)18
- CNNを使って画像の特徴点に正準方向を割り当て、特徴点のマッチングを向上させた
- Siamese network の学習アプローチを導入し新しいGHH活性化関数を提案
- 複数のデータセットにわたる特徴記述子の性能の大幅な向上を示した
- HardNet(2017)19
- L2Netをbaseとしてmetric learningに焦点を当て、auxiliary loss(補助損失項)の必要性を排除した
- 学習目的を単純化する後続のモデルの先例となった
- DOAP(2018)20
- ランク付け学習に焦点をあてた
- 最近傍マッチング用にlocal feature descriptor を最適化するため
- 特定のマッチングシナリオで成功を収め、後のモデルがランク付けベースのアプローチを検討することに影響を与えた
- ランク付け学習に焦点をあてた
- KSP(2018)21
- 不変で識別可能な記述子を学習するためにCNNを活用し、部分空間プーリング手法を導入した
- DeepBit(2018)22
- コンパクトなバイナリ記述子を学習するための教師なし深層学習フレームワークを提供する
- DeepBitは、局所記述子の回転、並進、スケール不変性などの重要な特性を2値表現にエンコードする
- Binganら(2018)23
- 正則化されたGenerative Adversarial Networks(GAN)を用いて、コンパクトな2値画像記述子を学習する手法を提案
- GLAD(2018)24
- 人体からの局所的な手がかりと大域的な手がかりの両方を考慮することで人物の再識別タスクに取り組む
- 識別可能で頑健な記述子を生成するために、4ストリームのCNNフレームワークが実装されている
- Geodescら(2018)25
- SfMアルゴリズムからの幾何学的制約を統合することで、記述子計算を進歩させる
- サンプルの硬さを測定するために、幾何学的情報を用いて学習データを構築
- ここで硬さは、同じ3D点の画素ブロック間のばらつきと、異なる点の均一性によって定義される
- 幾何学的類似性損失関数が考案され、同じ3D点に対応するピクセルブロック間の近さを促進
- サンプルの硬さを測定するために、幾何学的情報を用いて学習データを構築
- これらの技術革新により、Geodescらは3D再構成タスクにおける記述子の有効性を大幅に向上させた
- SfMアルゴリズムからの幾何学的制約を統合することで、記述子計算を進歩させる
- GIFT(2019)26とCOLD(2021)27
上記フレームワークの洗練化
- SOSNet(2019)28
- HardNet(2017)を拡張
- 記述子の頑健性を強化する傾向を継続し、記述子の学習に2次の類似性正則化項を導入することで、
- この拡張は、2次類似性制約を学習プロセスに統合することで、ロバストな記述子の学習性能を強化するものである
- 2次類似度」とは、訓練バッチ内の記述子ペア間の相対距離の一貫性を評価する指標を示す
- これは、記述子ペア間の類似性を直接測定するだけでなく、同じバッチ内の他の記述子ペアとの相対距離を考慮することによっても測定する
- Ebelら(2019)29
- スケール不変性を達成するために、対数極サンプリングスキームに基づく局所特徴記述子を提案
- このユニークなアプローチは、異なるスケール間でのキーポイントマッチングを可能にし、オクルージョンや背景の動きに対してロバストにした
- HyNet(2020)30
- 上記のトリプレットマージン損失に対して混合類似度尺度を導入
- 記述子規範を制約する正則化項を実装することで、バランスのとれた効果的な学習フレームワークを確立
- CNDesc(2022)31
- L2正規化を研究し、革新的な密な局所記述子学習アプローチを提示した
- L2正規化の代わりに特殊な交差正規化手法を用い、特徴ベクトルを正規化する新しい方法を導入
- Key.Net(2019)32
- handcrafted featureとlearned CNN featureを組み合わせた keypoint detector を提案
- 異なるレベルのキーポイントを抽出するために、ネットワーク内のスケール空間表現を利用
- ALIKE(2022)33
- キーポイント検出手法における非微分性の問題に対処するため、スコアマップに基づく微分可能なキーポイント検出(DKD)モジュールを提供
- 非最大抑制(NMS)に依存する手法とは対照的に、DKDは勾配を逆伝播しサブピクセルレベルでキーポイントを生成することができる
- 上記によりキーポイントの位置を直接最適化することができる
- ZippyPoint(2023)34
- KP2D(2020)35に基づいて設計
- 抽出とマッチングを加速する技術一式を導入
- バイナリ記述子正規化レイヤーの使用を提案
- ユニークで長さ不変のバイナリ記述子の生成を可能にした
特徴記述子に対するコンテキスト情報の埋め込み
コンテキスト情報を特徴記述子に実装することは、局所特徴マッチング手法の進歩において上昇傾向にある。
- ContextDesc(2019)36
- 既製の局所特徴記述子を改良するためにコンテキスト認識を導入
- キーポイントの位置、生の局所特徴、および高レベルの領域特徴を入力として使用
- 幾何学的および視覚的コンテキストの両方をencode
- この学習プロセスの新しい側面
- self-adaptive でパラメータチューニング不要な N-pair lossを使用
- より効率的な学習プロセスを可能にした
- MTLDesc(2022)37
- CNN の領域で直面する固有の局所性の問題に対処
- 以下のモジュールを導入することで離れた特徴間の高レベルな依存関係を効率的に学習可能にした
- adaptive global context enhancement module
- multiple local context enhancement modules
- AWDesc(2023)38
- MTLDescをベースに teacher-student 学習を適用
- 計算を大幅に高速化し、モデルが精度と速度の最適なバランスを達成することを可能にした
これらの手法におけるコンテキスト認識への注目は、局所的な特徴を記述する際に、よりグローバルな情報を考慮することの重要性を強調している。
周波数領域ベースや深度ベースの特徴記述子
- 従来の画像特徴記述子(勾配、グレースケールなど)に内在する限界を考慮すると、異なるモーダル画像タイプ間の幾何学的およびラジオメトリックな不一致を扱うのに苦労しており、周波数領域ベースの特徴記述子に新たな注目が集まっている
- ※ 【図解】衛星データの前処理とは~概要、レベル別の処理内容と解説~ | 宙畑
- これらの記述子は、クロスモーダル画像のマッチングにおいて改善された熟練度を示す
- RIFT(2019)39
- FAST(2006)40 を利用して、位相一致(PC)マップ上の繰り返し可能な特徴点を抽出し
- その後、周波数領域の情報を使用してロバストな記述子を構築し、マルチモーダル画像特徴マッチングの課題に対処
- FAST(2006)40 を利用して、位相一致(PC)マップ上の繰り返し可能な特徴点を抽出し
- SRIFT(2020)41
- RIFT ベース
- 非線形拡散スケール(NDS)空間を確立することでこのアプローチをさらに改良
- スケールと回転の不変性を達成
- RIFTに関連する推論速度の遅さの問題にも対処
- ディープラーニング技術の進化に伴い、深度ベースの手法は特徴抽出において大きな実力を発揮している
- SemLA(2023)42
- registration と fusion process においてセマンティック・ガイダンスを使用している
- image fusionタスクに最も正確なレジストレーション効果を提供するために、特徴マッチングはセマンティック・センシング領域に限定される
- SemLA(2023)42
2.1.2 Weakly Supervised and Others
弱教師付き学習は、密なアノテーションを必要とせずにロバストな特徴を学習するモデルの機会を提供し、ディープラーニングモデルの学習における最大の課題の1つに対する解決策を提供する。
下記ではカメラのポーズから容易に得られる幾何学的情報を活用した、いくつかの弱い教師ありの局所特徴学習手法が登場している。
- AffNet(2018)43
- 弱教師付き局所特徴学習における重要な進歩であり、局所特徴のアフィン形状の学習に焦点を当てている
- アフィン領域のマッチング可能性と幾何学的精度を向上させるために、hard negative-constant loss を導入
- 特にワイドベースラインマッチングや画像検索において、アフィン共変検出器の性能を向上させるのに効果的であることが証明されている
- このアプローチは、より効果的な局所特徴検出器を開発するために、記述子の一致性と再現性の両方を考慮する必要性を強調している
- GLAMpoints(2019)44
- 強化学習の損失定式化から創造的な洞察を引き出した、半教師付きキーポイント検出法を提示
- 最終的なアライメントの品質に基づいて、キーポイントを検出することの重要性を計算するために報酬が使用される
- この方法は、最終的な画像のマッチングとレジストレーションの品質に大きな影響を与えることが指摘されている
- CAPS(2020)45
- 画像ペア間の相対的なカメラポーズを利用して特徴記述子を学習する弱教師あり学習のフレームワークを導入
- エピポーラ幾何拘束を監督信号として採用することで、微分可能なマッチング層と粗から細へのアーキテクチャを設計し、高密度の記述子を生成
- DISK(2020)46
- 政策勾配を用いたエンド・ツー・エンドのDetectorベースのパイプラインに弱監視学習を統合
- 強化学習を最大限に利用
- この弱教師付き学習と強化学習の統合的アプローチは、よりロバストな学習信号を提供し、効果的な最適化を達成
- 政策勾配を用いたエンド・ツー・エンドのDetectorベースのパイプラインに弱監視学習を統合
- J. Leeら(2023)47
- group-equivariant CNN を活用したアプローチ
- これらのCNNは、識別可能な回転不変の局所記述子を効率的に抽出する
- より良い方向推定と効率的な局所記述子抽出のために、self-supervised loss を採用
- group-equivariant CNN を活用したアプローチ
カメラポーズ監視やその他の技術を用いた弱教師付き手法や半教師付き手法は、ロバストな局所特徴手法の学習という課題に取り組むための有用な戦略を提供し、この領域におけるより効率的でスケーラブルな学習手法への道を開く可能性がある
2.2 Joint Detection and Description
- Sparse local feature matching は様々な環境条件下で非常に有効だが、極端な変化の下では性能が落ちる場合がある(昼夜の変化、異なる季節、弱いテクスチャのシーンなど)
- この限界は、キーポイント検出器と局所記述子の性質に起因している可能性がある
- キーポイントの検出は多くの場合画像の小さな領域に焦点を当て、画素強度のような低レベルの情報に大きく依存する
- この手順により、キーポイント検出器は、低レベルの画像統計量の変動の影響を受けやすくなる
- その結果照明や天候、その他の環境要因の変化の影響を受けやすくなる
- またキーポイント検出器や特徴記述子を個別に学習・訓練しようとする場合、個々のコンポーネントを注意深く最適化した後でも、それらを特徴マッチングパイプラインに統合すると、情報の損失や不整合が生じる可能性がある
- 個々のコンポーネントの最適化が、コンポーネント間の依存関係や情報共有を十分に考慮していない可能性があるため
- このような問題に対処するために、「検出と記述の共同化」というアプローチが提案されている(下図(b))
- キーポイントの検出と記述のタスクが統合され、単一のモデル内で同時に学習される
- これにより、最適化の際に両タスクからの情報を融合し、特定のタスクやデータによりよく適応し、CNNを通してより深い特徴マッピングを可能にする
- このような統一されたアプローチは、検出と記述のプロセスが、画像の構造的特徴や形状関連特徴のような、より高いレベルの情報の影響を受けることを可能にすることで、タスクに利益をもたらすことができる
画像全体を入力とし、FCNを利用して高密度の記述子を生成する画像ベースの記述子手法は、近年大きな進歩を遂げている。これらの手法は、検出と記述のプロセスを統合することが多く、両タスクの性能向上につながる。
- SuperPoint(2018)48
- ピクセルレベルでのキーポイント位置とその記述子を同時に決定するために、自己教師ありアプローチを採用
- 最初に、モデルはランダムなホモグラフを適用することで、合成図形と画像に対して学習を行う
- この手法の重要な点は、実画像を用いたセルフアノテーション処理
- このプロセスでは、モデルが実世界の画像との関連性を高めるためにホモグラフを適合させ、MS-COCOデータセットを追加学習に用いる
- これらの画像のグランドトゥルースのキーポイントは、様々なホモグラフィ変換によって生成され、キーポイント抽出はMagicPointモデルを用いて実行される
- 複数のキーポイントヒートマップを集約するこの戦略により、実画像上のキーポイント位置の正確な決定が保証される
- LF-Net(2018)49
- Q学習から着想を得た
- 既存のSfMモデルを用いて、マッチングした画像ペア間の相対的な深度やカメラポーズなどの幾何学的関係を予測する
- asymmetric gradient backpropagation を採用し、手動アノテーションを必要とせずに画像ペアを検出するネットワークを学習する
- RF-Net(2019)50
- LF-Net をベースにしている
- 受容野ベースのキーポイント検出器を導入し、パッチ選択の学習を容易にする「近傍マスク」と呼ばれる一般的な損失関数項を設計
- Reinforced SP(2020)51
- キーポイント選択と記述子マッチングにおける離散性を扱うために、強化学習の原理を採用
- これは特徴検出器を完全な視覚パイプラインに統合し、学習可能なパラメータをエンドツーエンドで学習する
- R2D2(2019)52
- L2-Netアーキテクチャの高密度版を採用
- グリッドピーク検出と記述子の信頼性予測を組み合わせ、スパースで反復可能かつ信頼性の高いキーポイントを生成
- D2Net(2019)53
- スパース特徴抽出のために、検出と記述のジョイントアプローチを採用
- Superpointとは異なり、検出と記述のプロセス間で全てのパラメータを共有し、両方のタスクを同時に最適化する共同定式化を用いる
- キーポイントは、深度特徴マップのチャンネル内およびチャンネルをまたがる局所最大値として定義される
これらの手法は、検出と記述のタスクを統一モデルで統合することで、より効率的な学習と、異なる撮像条件下での局所特徴抽出の優れた性能につながることを示している。
- RoRD(2021)54
- バニラと回転に頑健な特徴対応を組み合わせた極端な視点変化に対処
- 対応アンサンブルを持つ双頭D2Netモデルを提示
- HDD-Net(2020)55
- 対話的に学習可能な検出器と記述子の融合ネットワークを設計し、検出器と記述子のコンポーネントを独立に扱い
- 学習過程におけるそれらの相互作用に注目する
- MLIFeat(2020)56
- キーポイントの検出と記述子の生成に使用される2つの軽量モジュールを考案
- キーポイントの検出と記述子の抽出を共同で行うためにマルチレベル情報融合が利用される
- LLF(2021)57
- キーポイント検出を監督するために低レベル特徴を利用することを提案する
- 記述子のバックボーンから単一のCNNレイヤーを検出器として拡張
- 記述子のマッチングを最大化するために記述子と共学習させる
- キーポイント検出を監督するために低レベル特徴を利用することを提案する
- FeatureBooster(2023)58
- 従来の特徴マッチングパイプラインに記述子拡張ステージを導入
- オリジナルの記述子とキーポイントの幾何学的属性を入力とする、汎用的な軽量記述子強調フレームワークを確立
- MLPに基づくself-enhancementと、Transformer に基づくcross-enhancementを採用
- ASLFeat(2020)59
- multi-level feature map上のchannelとspatial peakを用いてD2Netを改善
- マルチレベル接続とDCNだけでなく、正確な検出器と不変記述子を導入
- 密な予測フレームワークは、低解像度特徴マップからのキーポイント抽出による制限を緩和するためにDCNを採用
- SeLF(2022)60
- Aslfeatアーキテクチャをベース
- leverage semantic information from pre-trained semantic segmentation networks used to learn semantically aware feature mapping
- 学習された対応関係を意識した特徴記述子と意味的特徴を組み合わせることで、長期的なローカライゼーションのための局所的特徴マッチングのロバスト性を高める
- SFD2(2023)61
- 高レベルのセマンティクスを検出と記述のプロセスに暗黙的に埋め込む
- 信頼性の低い領域(例えば、空、車)を抑制しながら
- グローバルな領域(例えば、建物、交通車線)から信頼性の高い特徴を抽出する
- これにより、このモデルは単一のネットワークからend2endでグローバルに信頼できる特徴を抽出することができる
- 高レベルのセマンティクスを検出と記述のプロセスに暗黙的に埋め込む
2.3 Describe-then-Detect
- 記述子を記述してから、検出する手順
- 下図の(3)
- D2D(2020)62
- Describe-to-Detect (D2D)と呼ばれるキーポイント検出のための新しいフレームワークを提示
- 特徴記述フェーズに内在する豊富な情報を強調
- 高密度な特徴記述子の膨大なコレクションの生成と、このデータセットからのキーポイントの選択を含む
- キーポイントを定義するために、局所的な深度特徴マップの相対的および絶対的な顕著性測定を導入
- PoSFeat(2022)63
- 弱教師付きの局所特徴学習用に特別に設計された記述→検出パイプラインにおいて、分離された学習アプローチを提示
- 検出と記述の段階間の損失を区別することができない弱教師から生じる課題のため
- 記述ネットワークを検出ネットワークから分離し、性能を向上させる記述子学習のためにカメラのポーズ情報を活用
- 新しい探索戦略により、記述子学習プロセスはカメラのポーズ情報をより巧みに利用
- 弱教師付きの局所特徴学習用に特別に設計された記述→検出パイプラインにおいて、分離された学習アプローチを提示
- ReDFeat(2022)64
- マルチモーダル特徴学習の検出と記述の側面を組み合わせるために、相互重み付け戦略を使用する
- SCFeat(2022)65
- 弱教師付き局所特徴学習のための共有結合ブリッジ戦略を提案
- 共有結合ブリッジと交差正規化レイヤーを通して、このフレームワークは記述ネットワークと検出ネットワークの個別の最適な学習を保証する
- この分離により、記述子の頑健性と全体的な性能が向上
2.4 Graph Based
- 従来のfeature matching pipeline
- 特徴記述子の最近傍(NN)探索によって対応関係を確立
- マッチングスコアや相互NN検証に基づいて外れ値を排除
- 最近では、attentionベースのグラフニューラルネットワーク(GNN)が、局所的な特徴マッチングを得るための効果的な手段として登場
- キーポイントをノードとするGNNを作成し
- トランスフォーマーのself-attentionとcross-attentionを利用
- ノード間でグローバルな視覚情報と幾何学的情報を交換
- 上記交換により、局所的な特徴記述子のみがもたらす課題を克服
- 最終的な結果は、ソフト割り当て行列に基づくマッチの生成

- SuperGlue(2020)66
- attention GNNと最適輸送法を採用し、部分割り当て問題に対処する
- これは、2組の(keypoint, その記述子)を入力として処理
- 2組の記述子の間でメッセージを交換するためself-attentionとcross-attentionを活用
- この手法の複雑さは、キーポイントの数によって二次関数的に増大する
- 後続の研究でさらなる探求が促された
- これは、2組の(keypoint, その記述子)を入力として処理
- attention GNNと最適輸送法を採用し、部分割り当て問題に対処する
- SGMNet(2021)67
- SuperGlueをベース
- 一致する点のサブセットのみをseedとして処理するSeeding Moduleを追加した
- 完全連結グラフは放棄され、疎な連結グラフとなる
- seed GNNは、情報を集約するためのアテンションメカニズムとともに設計される
- キーポイントは通常、数個の点と強い相関を示す
- その結果ほとんどのキーポイントの隣接行列は疎結合になる
- ClusterGNN(2022)68
- グラフ・ノードのクラスタリング・アルゴリズムを利用してグラフ内のノードを複数のクラスタに分割
- attention GNN layers with clustering を採用
- 2組のキーポイントとその関連記述子の間の特徴マッチングを学習するため
- 冗長な情報伝播を減らすために部分グラフを学習
- MaKeGNN(2023)69
- スパースな注意GNNアーキテクチャに対し下記を導入
- bilateral context-aware sampling
- keypoint-assisted context aggregation
- スパースな注意GNNアーキテクチャに対し下記を導入
- GlueStick(2023)70
- SuperGlueにインスパイアされた
- 点記述子と線記述子をジョイント・マッチングのフレームワークに組み込み
- マッチングした画像から線をつなぐために点間の関係を活用
- LightGlue(2023)71
- SuperGlueを計算の複雑さをadaptiveなものにするため下記のように対処
- 各画像ペア間のマッチングの難易度に基づいて、ネットワークの深さと幅を動的に変更
- 状態割り当てを予測し、改良するために、軽量の信頼度分類器を考案
- SuperGlueを計算の複雑さをadaptiveなものにするため下記のように対処
- DenseGAP(2022)72
- anchor point を利用したグラフ構造を考案
- anchor point は画像間および画像内のコンテキストに対する、疎でありながら信頼できるpriorとして利用
- この情報は、有向エッジを通じてすべての画像点に伝搬される
- anchor point を利用したグラフ構造を考案
- HTMatch(2023)73とParaformer(2023)74
- 対話的混合への注意の応用を研究し、効率と効果のバランスをとるアーキテクチャを探求
- ResMatch(2023)75
- 特徴マッチングのためのresidual attention learningのアイデアを提示
- self-attentionとcross-attentionを再定義
- 相対位置参照と記述子の類似性のlearned residual functionsとして
- self-attentionとcross-attentionを再定義
- 下記2つの間の溝を埋めることを目的としている
- 解釈可能なマッチングとフィルタリングのパイプライン
- 経験的手段によって本質的に不確実性を持つattentionベースの特徴マッチングネットワーク
- 特徴マッチングのためのresidual attention learningのアイデアを提示
3. Detector-free Models
- feature detection stageは、マッチングのための探索空間の縮小を可能にする
- しかし検出ベースのアプローチを使用する場合、完全な記述子やマッチング手法にもかかわらず、以下のような極端な状況で困難であることが判明している76
- 大幅な視点変更
- テクスチャのない領域を含む画像ペアなど
- しかし検出ベースのアプローチを使用する場合、完全な記述子やマッチング手法にもかかわらず、以下のような極端な状況で困難であることが判明している76
- Detector-free の手法は、feature detectors を排除し、画像全体に広がる密なグリッド上の視覚的記述子を直接抽出して、密なマッチングを生成する
- Detector-based と比較して、画像ペア間で反復可能なキーポイントを捉えることができる
- ※ 大雑把に言えば pipeline の途中で keypoints を明示しなければ Detetor-free と言ってよいと思います
3.1 CNN Based
- 初期の段階ではDetector-freeマッチング手法は、潜在的な近傍の一致を識別するために相関やコストボリュームを使用するCNNに頼ることが多かった
- 下図は 4D correspondence volume の基本的な構造を示している
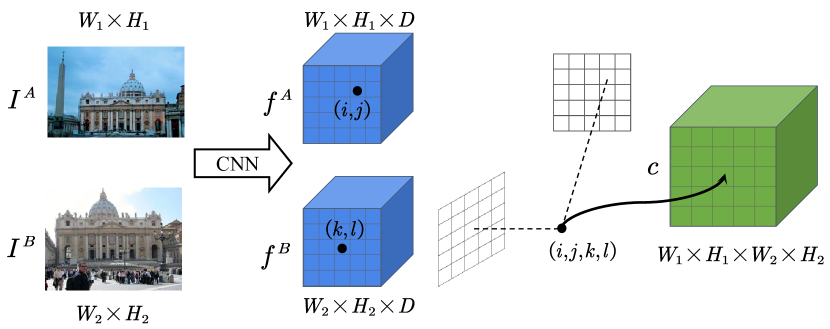
- NCNet(2018)77
- 1組の画像間のすべての可能な対応点の4次元空間における近傍整合性を分析
- グローバルな幾何学モデルを必要とせずにマッチングを得る
- Sparse-NCNet(2020)78
- スパース相関テンソル上の4次元畳み込みニューラルネットワークを利用
- メモリ消費と実行時間を大幅に削減するために submanifold sparse convolution を利用
- DualRC-Net(2020)79
- 画像ペア間の密なピクセル単位の対応を粗から細へ確立する革新的な手法を導入
- 特徴ピラミッドネットワーク(FPN)のようなバックボーンを持つ二重解像度戦略を利用
- 粗解像度特徴マップから4次元相関テンソルを生成
- 学習可能な近傍コンセンサスモジュールを通してそれを精製
- マッチングの信頼性とローカリゼーションの精度を向上
- GLU-Net(2020)80
- グローバル-ローカル・ユニバーサル・ネットワークを導入
- 幾何学的マッチング、意味的マッチング、オプティカルフローのための密な対応関係の推定に適用可能
- 自己教師ありの方法でネットワークを学習
- グローバル-ローカル・ユニバーサル・ネットワークを導入
- GOCor(2020)81
- 2つの深度特徴マップ間の大域的最適化マッチング信頼度を予測する完全微分可能な密なマッチングモジュールを提示
- 特徴相関層を直接置き換えるために、最先端のネットワークに統合可能
- PDCNet(2021)82
- 画像間の密な対応とそれに関連する信頼度推定を推定する確率的深度ネットワークを提案
- 一般化可能なロバストな不確実性予測をするためのアーキテクチャと改良された自己教師付き学習戦略を導入
- PDC-Net+(2023)83
- 密な画像間対応とそれに関連する信頼度推定値を推定するように設計された確率的深層ネットワークを導入
- 予測分布のパラメータ化に制約付き混合モデルを採用
- 外れ値を処理するためのモデリング能力を高めている
- PUMP(2022)84
- 教師なし損失と標準的な教師あり損失を組み合わせて、合成画像を補強する
- 4次元相関ボリュームを利用することでDeepMatching85のノンパラメトリックなピラミッド構造を活用
- 教師なし記述子を学習する
- DFM(2021)86
- 特徴抽出器として事前に訓練されたVGGアーキテクチャを利用
- VGGネットワークの最深層から抽出された特徴のロバストなパワーを実証している
- 追加の訓練ストラテジを必要とせずにマッチングをキャプチャすることで
3.2 Transformer Based
Transformerを用いたメジャーなモデル
- COTR(2021)87
- 両方のアプローチの利点を兼ね備えている
- sparse matching と dense matching
- 上記の違いがクエリするポイントの量であると仮定するならば
- COTRは self-attention を用いて2つのマッチング画像を同時に学習する
- いくつかのキーポイントをクエリとして使用し
- 対応するニューラル・ネットワークを通じて
- もう一方の画像のマッチングを再帰的にrefineしながら
- この統合は、両方のマッチングを1つのパラメータ最適化された問題に統合する
- 両方のアプローチの利点を兼ね備えている
- ECO-TR(2022)88
- 以下によってCOTRを高速化するend2endモデルを提案
- 以下を用いて予測された座標を coarse-to-fine へと段階的に精緻化することで
- 複数の transformer block を使った
- shared multi-scale feature extraction network
- 以下を用いて予測された座標を coarse-to-fine へと段階的に精緻化することで
- 以下によってCOTRを高速化するend2endモデルを提案
- LoFTR(2021)89
- 以下の点が画期的
- キーポイントをノードとするGNNを作成
- 2つの画像の特徴記述子を得るために self-attention と cross-attentionを利用
- テクスチャの少ない領域で密なマッチングを生成
- 以下の点が画期的
- Aspanformer(2022)90
- LoFTRにおける local attention の相互作用を改善
- フロー予測の確率的モデリングに基づく uncertainty-driven 方式を提案
- 異なる位置に対して異なるコンテキストサイズを割り当てるため adaptive local attention span を採用
- SE2-LoFTR(2022)91
- 上記をさらに発展させたモデル
- 特徴マッチングにおける回転の課題に対処する重要な進歩を提示
- 従来のLoFTRモデルに対し CNN を steerable CNN に変更
- 平行移動と画像回転の両方に対して等変量となり、回転変動に対するロバスト性を向上
- steerable CNN に基づく特徴抽出と、平面の平行化マッチングなどの技術との融合は、このアプローチの多用途性と広範な応用可能性を示している
dense matchingにおける課題に対処したモデル
dense matchingの場合類似したkeypointsが多数存在することと、linear transformer 自身の限界のよってもたらされる課題がある。
- Quadtree(2022)92
- quadtree attentionを導入
- 視覚変換の計算複雑度を2次から線形に低減
- より細かいレベルの無関係な領域での計算をスキップ
- quadtree attentionを導入
- OETR(2022)93
- Overlap Regression を導入
- Transformerデコーダを使用して、画像内の境界ボックス間の重なり度合いを推定
- symmetric center consistency loss を使用
- 重なり領域の空間的一貫性を保証するため
- OETRは、任意のLFMパイプラインに前処理モジュールとして挿入することができる
- Overlap Regression を導入
- MatchFormer(2022)94
- 以下を考案
- hierarchical transformer encoder
- lightweight decoder
- 階層構造の各段階で cross-attention と self-attention module を挿入し最適な組み合わせパスを提供
- マルチスケール特徴を強化
- 以下を考案
- CAT(2022)95
- 自己注意メカニズムに基づくコンテキスト対応ネットワークを提案
- attention layer は以下のいずれかのように適用することができる
- より高い効率のために空間次元に沿って
- より高い精度とストレージ負担の軽減のためにチャネル次元に沿って
- TopicFM(2022)96
- トピック・モデリング・アプローチを利用して、画像中の高レベルのコンテキストを符号化する
- 画像内の意味的に類似した領域に焦点を当てる
- マッチングのロバスト性が向上
- トピック・モデリング・アプローチを利用して、画像中の高レベルのコンテキストを符号化する
- ASTR(2023)97
- Adaptive Spot-guided Transformerを導入
- ポイント・ガイド集約モジュールが含む
- ほとんどの画素が無関係な領域の影響を回避できるようにするため
- 計算された深度情報を使用して、絞り込み段階でグリッドのサイズを適応的に調整
- ポイント・ガイド集約モジュールが含む
- Adaptive Spot-guided Transformerを導入
- DeepMatcher(2023)98
- CNNから抽出された局所的に集約された特徴量を、Transformerから抽出されたグローバルな受容野を持つ特徴量にスムーズに移行するための特徴量変換モジュールを導入
- 残差ブロック内の情報交換を適応的に吸収し、人間のような挙動をシミュレートする階層的戦略を採用して、ディープネットワークを構築するSlimFormerも紹介
- OAMatcher(2023)99
- Overlapping Areas Prediction Moduleを提案
- 人間が画像全体から重複領域にフォーカスを移す方法をシミュレート
- 共視可能領域のキーポイントを捕捉し、それらの間で特徴強調を行う
- マッチングラベルウェイト戦略を提案
- マッチングラベルが正しいかどうかを判断するために確率を用いて
- 真のマッチングラベルの信頼性を評価するための係数を生成する
- Overlapping Areas Prediction Moduleを提案
- CasMTR(2023)100
- Transformer based のマッチングパイプラインを強化することを提案
- カスケードマッチングとNMS検出の新しい段階を組み込むことで
- Transformer based のマッチングパイプラインを強化することを提案
2023頃のSOTA
- PMatch(2023)101
- LoFTR module を利用
- paired masked image modeling pretext task による transformer の事前学習を実施
- 幾何学的マッチング性能を向上
- SEM(2023)102
- structured feature extractor を導入
- 以下2つの相対的な位置関係をモデル化
- ピクセル
- 信頼性の高い anchor points
- 幾何学的事前分布を効果的に活用
- 以下2つの相対的な位置関係をモデル化
- epipolar attention と matching 技術を組み込み
- エピポーラ制約に基づいて無関係な領域をフィルタリングするため
- structured feature extractor を導入
- DKM(2023)103
- 密な特徴マッチング手法を考案することで、2視点幾何学的推定問題に対処
- 以下を含むロバストな global matcher を提案
- kernel regressor
- embedded decoder
- 上記は stacked feature maps に対し large depth-wise kernel による warp refinement を可能とする
- RoMa(2023)104
- ※ CVPR2024にも採択されている
- 上記をベースにマルコフ連鎖のフレームワークを適用してマッチングプロセスを分析・改善
- dense feature matching を大きく前進させた
- 2段階のアプローチを導入
- すなわち、大域的に一貫したマッチングのための粗い段階
- 正確なローカライゼーションのための洗練段階
- 最初のマッチングを精密化プロセスから分離し、より高い精度のためにロバストな回帰損失を用いるという仕組み
- マッチング性能を著しく向上
3.3 Patch Based
- Patch Based マッチング手法は局所的な画像領域をマッチングすることで点の対応を強化する
- これは画像をパッチに分割
- それぞれの記述子ベクトルを抽出
- これらのベクトルをマッチングさせて対応関係を確立
- この技法は大きな変化に対応し、様々なコンピュータビジョンアプリケーションで有用
- 下図は Patch Based マッチング手法の一般的なアーキテクチャ

代表モデル
- Patch2Pix(2021)105
- 画像ペア間の極端な幾何学変換と一致する対応関係を学習する弱教師あり手法を提案
- 対応関係を予測するためにtwo-stage detection-refinementを採用
- 第1段階: captures semantic information
- 第2段階: handles local details
- novel refinement network を導入
- utilizes weak supervision from extreme geometric transformations
- outputs confidence in match positions and outlier rejection
- 一致位置の信頼度の出力 & 外れ値除去
- 幾何学的に一貫した対応予測を可能とした
- AdaMatcher(2023)106
- Patch level matchingで1:1の割り当て基準を適用することで生じる幾何学的不整合の問題に対処
- 画像間のスケールを推定しながらパッチレベルのマッチングを適応的に割り当てることによって
- 極端なケースにおけるdense feature matchingの性能を向上
- Patch level matchingで1:1の割り当て基準を適用することで生じる幾何学的不整合の問題に対処
- PATS(2023)107
- 自己教師ありの方法でスケール差を学習する手法を提案
- Patch Area Transportation with Subdivision (PATS)
- 1:1のマッチングしか扱えない二分割グラフマッチングとは異なり、複数対複数の関係を扱うことが可能
- 自己教師ありの方法でスケール差を学習する手法を提案
- SGAM(2023)108
- 階層的特徴マッチングフレームワークを提案
- 意味的手がかり(semantic clues)に基づいてregion matching を行うことで検索空間を絞り込む
- feature matchingの検索空間を画像間で有意な意味分布を持つregion matchingに絞り込む
- 幾何学的整合性によってregion matchesを絞り込み、正確なpoints matchesを得る
- 意味的手がかり(semantic clues)に基づいてregion matching を行うことで検索空間を絞り込む
- 階層的特徴マッチングフレームワークを提案
4. Local Feature Matching Applications
4.1 Structure from Motion(SfM)
- SfMは基礎的な計算ビジョンプロセスであり、多様なシーン画像の配列からカメラの方向、固有パラメータ、および体積点群を推論するために不可欠である
- このプロセスは、視覚的な定位、多視点ステレオ、革新的な視点の合成などの試みを実証している
- 従来のSfM手法
- 多様な視点に分散したまばらな特徴点の同定と相関に依存
- この方法はテクスチャーの特徴が乏しい領域ではキーポイントの同定が厄介な課題となる
- Lindenbergerら(2021)109
- 最初のキーポイントを入念に精緻化し、その後のポスト処理でポイントとカメラの向きの両方を調整することで改善
- 提案されたアプローチは以下のバランスを戦略的にとることで、困難な条件下での精度を高めている
- 局所的な疎な特徴による最初の初歩的な推定
- 局所的に精度の高い密な特徴によるその後の微調整
- SfMにおける最近の進歩は以下のような全体論的アプローチへと移行している
- Heら(2023)114
- 検出器を使わない革新的なSfMパラダイムを導入
- 検出器を使わないマッチャーを利用して、キーポイントの決定を延期
- この戦略は、検出器フリーのマッチャーで一般的なマルチビューの不整合に巧みに対処
- 従来の検出器中心のシステムと比較して、テクスチャの乏しいシーンで優れた有効性を示す
- 検出器を使わない革新的なSfMパラダイムを導入
4.2 Remote Sensing Image registration(位置合わせ)
- リモートセンシングの領域では、ディープラーニングの出現が、マルチモーダルリモートセンシング画像登録(MRSIR)の多大な影響を及ぼした
- 従来のエリアベースおよびフィーチャーベースの技術を学習ベースパイプライン(LBP)で補強している
- このLBPはいくつかの先駆的なアプローチに分岐している
- ディープラーニングと従来のレジストレーション手法の融合
- モダリティ変換によるマルチモーダルキャズムの橋渡し
- 包括的なMRSIRフレームワークのための変換パラメータの直接回帰
- Siamese networks や GANなどのは幾何学的歪みや非線形のラジオメトリック視差の管理を容易にした
- 例: 条件付きGANの利用は擬似画像の作成を可能にし、NCCやSIFTのような確立された手法の精度を高めている
(以下略)
4.3 Medical Image Registration
- 医用画像レジストレーションの分野は、特に動き推定と2D-3Dレジストレーションにおいて、高度なディープラーニング技術の統合によって大きな進化を遂げている
- これらの進歩は技術的な飛躍を意味するだけでなく、様々な医療アプリケーションに新たな展望を開くものでもある
(以下略)
5. Local Feature Matching Datasets
5.1 Image Matching Datasets
-
HPatches
- 画像マッチングを試みる際の重要な基準となっている
- このベンチマークは、視点と輝度の変動によって区別される116のシーン・シーケンスで構成される
- 各シーン内には5組の画像があり
- 最初の画像が参照点
- シーケンス内の後続の画像は徐々に複雑さを増していく
- 各シーン内には5組の画像があり
- このデータセットは、2つの異なる領域に二分される
- 視点: 視点の大幅な変更が見られる59のシーケンス
- 証明: 自然および人工的な輝度条件の両方にまたがる、照度の大幅な変動が見られる57のシーケンス
- 各テストシーケンスでは、1つの参照画像が残りの5つの画像と対になっている
- D2Netの評価方法によると、ネットワークの性能評価には通常以下が使用されることは注目に値する
- 視点の変化が大きい56シーケンスと
- 照明の変化が大きい52シーケンス
- SuperPoint[61]ではHPatchesデータセットも、ホモグラフィ推定タスクにおける局所記述子の性能を評価するために使用されている
-
Roto-360
- 360の画像ペアからなる評価データセット
- これらのペアは、10°間隔で0°から350°までの平面内の回転を特徴としている
- 10枚のHPatches画像をランダムに選択し、回転させることで生成されている
- 回転不変性の観点から記述子の性能を評価するのに貴重なデータセットとなっている
5.2 Relative Pose Estimation Datasets
-
ScanNet
- 1,613のシーンから得られた約2億3千万の明確な画像ペアからなる
- 明確に定義されたトレーニング、検証、テスト分割を持つ大規模な屋内データセット
- GT画像と深度画像が含まれ、Hpatchesデータセットと比較して、反復的で弱いテクスチャを持つ領域がより多く含まれる
- 1,613のシーンから得られた約2億3千万の明確な画像ペアからなる
-
YFCC100M
- 様々な観光名所のインターネット画像を集めた膨大なデータセット
- このデータセットは1億のメディアオブジェクトで構成される
- そのうち約9,920万が写真、約80万が動画
- 各メディアオブジェクトは以下の例などの複数のメタデータで表される
- Flickr識別子, 所有者名, カメラ情報, タイトル
- タグ, ジオロケーション, メディアソース
- 通常、評価にはYFCC100Mのサブセットが使用される
- テストセットは過去研究の慣例にしたがった下記の4,000ペアが使用される
- 4つの人気ランドマーク画像セットそれぞれから1,000画像ペアを抽出した合計4,000ペア
-
MegaDepth
- 極端な視点変更と繰り返しパターン下でのマッチングという難題に取り組むために設計されたデータセット
- 196の異なる屋外シーンからの100万の画像ペアで構成される
- それぞれが既知のポーズと深度情報を持つ
- 屋外シナリオにおけるポーズ推定の有効性を検証するために使用できる
- それぞれが既知のポーズと深度情報を持つ
- COLMAP[12]を用いたスパース再構成と多視点ステレオ計算から生成された深度マップも提供している
-
Extreme Viewpoint Dataset(EVD)
- 極端な視点変更のシナリオ下で2視点マッチングアルゴリズムを評価するために特別に開発された
- 綿密にキュレーションされたデータセット
- 一般にアクセス可能なさまざまなデータセットから画像ペアを統合したもの
- 複雑な幾何学的構成によって区別されている
- EVDの作成モチベーション
- 視点の顕著な変化を特徴とする文脈におけるマッチング手法の回復力を評価する必要性
- 極端な視点変更のシナリオ下で2視点マッチングアルゴリズムを評価するために特別に開発された
-
Wide multiple Baseline Stereo(WxBS)
- ワイドベースラインステレオマッチングの領域において以下のような画像取得の複数の側面における格差を包含する、より広範な課題を扱っている
- 視点、照明、センサーの種類、視覚的変化など
- 37の画像ペアで構成されている
- 様々な複雑な要因の存在に基づいて体系的に分類された、都市環境と自然環境のブレンドを特徴とする
- グランドトゥルースは、両方の画像で見えるシーンのセグメントをキャプチャし、手動で選択された対応関係のコレクションによって確立される
- WxBSは様々な厳しい条件下での画像マッチング用に調整されたアルゴリズムを評価するための極めて重要なデータセット
- ワイドベースラインステレオマッチングの領域において以下のような画像取得の複数の側面における格差を包含する、より広範な課題を扱っている
5.3 Visual Localization Datasets
クエリ画像の位置を推定するタスク用データセット。
-
Aachen Day-Night
- v1.0 は昼間の画像4,328枚と夜間の画像98枚からなる
- 昼間の画像と夜間の画像のマッチングに挑戦しており、作業しがいのあるデータセットとなっている
- Aachen Day-Night v1.1
- は、Aachen Day-Nightデータセットの更新版
- 6,697枚の昼間画像と1,015枚のクエリ画像(昼間824枚、夜間191枚)が収録されている
- 照明や視点の変化が大きいため、扱いにくいデータセットとなっている
-
InLoc
- 9,972枚のRGBD画像を含む屋内データセット
- そこから329枚のRGB画像が、長期的な屋内視覚定位アルゴリズムの性能をテストするためのクエリとして使用されている
- このデータセットは様々な課題を提供している
- サイズが大きいこと(2つのビルをカバーする約1万枚の画像)
- データベースとクエリ画像の間に視点や照明の大きな違いがあること
- シーンの時間的変化があること
- 3Dスキャナからの深度マップの大規模なコレクションも提供している
- 9,972枚のRGBD画像を含む屋内データセット
-
RobotCar-Seasons(RoCaS)
- 26,121枚の参照画像と11,934枚のクエリ画像を含む難易度の高いデータセット
- このデータセットは様々な環境条件を設定している
- 雨、雪、夕暮れ、冬、郊外の不十分な照明など
- これらの要因は、特徴照合と視覚的位置特定を困難にしている
-
LaMAR
- 拡張現実(AR)におけるローカライゼーションとマッピングの基礎技術に取り組んでいる
- 現実的なARシナリオのための新しいベンチマークを導入している
- 多様な環境でARデバイスを使用してキャプチャされたもの
- 動的なオブジェクトや様々な照明のある屋内外のシーンを含む
- HoloLens 2やiPhone/iPadなどのデバイスからのマルチセンサーデータストリーム(画像、深度、IMUなど)を特徴としており、45,000平方メートル以上をカバーしている
- グラウンド・トゥルース・パイプラインはARの軌跡をレーザースキャンに対して自動的に整列させ、異種デバイスからのデータをロバストに扱う
- このベンチマークは、ARに特化したローカライゼーションやマッピング手法を評価する上で極めて重要
- ARデバイスにおける無線信号のような追加データストリームを考慮することの重要性を強調
- LaMARは、ARのための現実的で包括的なデータセットを提供
- 拡張現実(AR)におけるローカライゼーションとマッピングの基礎技術に取り組んでいる
5.4 Optical Flow Estimation Datasets
-
KITTI
- 都市交通シナリオで収集された画像マッチングデータセット
- 2012年版と2015年版がある
- KITTI-2012: 解像度1226×370の194のトレーニング画像ペアと195のテスト画像ペア
- KITTI-2015: 解像度1242×375の200のトレーニング画像ペアと200のテスト画像ペア
- このデータセットには、レーザースキャナーを使用して得られた疎なグランドトゥルース視差が含まれる
- KITTI-2012のシーンは比較的単純であるのに対して、KITTI-2015データセットは動的なシーンと複雑なシナリオとなっている
5.5 Structure from Motion Datasets
-
ETH
- SfMタスク用の記述子を評価するために設計されたデータセット
- 利用可能な2D画像セットから3Dモデルを構築することにより
- D2Netに続いて、3つの中規模データセットが評価される
- マドリード・メトロポリス(Madrid Metropolis)
- ジャンダルメンマルクト(Gendarmenmarkt)
- ロンドン塔(Tower of London)
- ETHデータセットには様々なカメラと条件が含まれている
- 異なる手法の性能を比較するための困難なベンチマークを提供する
- SfMタスク用の記述子を評価するために設計されたデータセット
-
ETH3D
- マルチビューステレオアルゴリズムの包括的なベンチマーク
- 下記によって撮影された屋内外の幅広いシーンを網羅
- 高解像度のデジタル一眼レフカメラ
- 同期された低解像度のステレオビデオ
- このデータセットの特徴は、高い空間解像度と時間解像度の組み合わせ
- シナリオは自然環境から人工環境まで多岐にわたり、ステレオビジョンシナリオにおけるハンドヘルドモバイルデバイスのアプリケーションに特に焦点を当て、詳細な3D再構成のための新しい課題を紹介
- 下記に対応する多様な評価プロトコルを提供
- 高解像度マルチビューステレオ
- ビデオデータ上の低解像度マルチビュー
- 2ビューステレオ
- その結果、ETH3Dは高密度3D再構成分野の研究を推進するための貴重な資産となっている
5.6 Dataset Gaps and Future Needs
- 上記のデータセットは、LFMを評価するための貴重なデータセットだが、対処すべき重要なギャップがある
-
ギャップ1: 極端な環境条件をシミュレートしたデータセットの欠如
- RoCaSのようなデータセットの存在は、多様な天候シナリオや照明条件など、環境条件におけるある程度の可変性を提供しますが、下記のような困難なシナリオに特化したデータセットも必要
- 豪雨、霧、雪など
- このような条件は、特徴マッチングにユニークな課題をもたらし、気候の影響を受けやすい分野でのアプリケーションにとって極めて重要
- RoCaSのようなデータセットの存在は、多様な天候シナリオや照明条件など、環境条件におけるある程度の可変性を提供しますが、下記のような困難なシナリオに特化したデータセットも必要
-
ギャップ2: 非常に動的な環境の表現が限られていること
- 広く使用されているHPatchesを含む現在のデータセットは視点や照明の変化を調べる上では包括的
- しかし混雑した都市部や動きの速いシーンの複雑さを十分に捉えていない
- この限界は、人口密集地でのリアルタイムのモニタリングや監視を必要とするアプリケーションにとって重要
- このような環境のダイナミクスを模倣できるデータセットは、このような状況における特徴照合技術の進歩に不可欠
- 広く使用されているHPatchesを含む現在のデータセットは視点や照明の変化を調べる上では包括的
-
ギャップ3: 特定の用途に特化したデータセットの不足
- 例: 水中画像や航空画像、海洋生物学やドローンによるモニタリングなど
- これらの領域には、ETHやAachen Day-Nightのようなデータセットでは対応できない独自の特性と課題がある
- 例: 水中画像や航空画像、海洋生物学やドローンによるモニタリングなど
- 結論
- 既存のデータセットは局所特徴マッチングの分野に大きく貢献してきたが、より専門的なデータセットが必要
- これらのデータセットは、既存のギャップを埋め、様々なアプリケーションドメインの進化するニーズに対応することを目指すべきであり、それによって局所特徴マッチング技術の更なる進歩を可能にする
6. Performance Review
6.1 Metrics For Matching Models
6.1.1 Image Matching
-
Repeatability
- 2つの画像を比較するための再現性の指標
- 画像間で見つかった一致する特徴領域のカウントを取り、どちらかの画像内で見つかった特徴領域の少ないカウントで割ることによって計算されます。
- この定量評価は異なる幾何学的変化を受けたときの特徴検出器の一貫性を測るために不可欠
- 各変数
- $M$: number of matching feature areas between the two images
- $F_1$: total number of feature areas detected in the first image
- $F_2$: total number of feature areas detected in the second image
$$
\rm{Repeatability} = \frac{M}{min(F_1, F_2)} \times 100
$$
-
Matching score(M-score)
- 2つの画像の重複領域で検出された全特徴に対する、正しくマッチングされた特徴の平均比率を計算
- 特徴検出・記述パイプラインの有効性を定量化する
-
Mean Matching Accuracy(MMA)
- 複数のピクセル誤差閾値を考慮して、画像ペア間の特徴マッチングがどの程度うまく行われたかを測定
- 複数のピクセル誤差しきい値を考慮した画像ペアにおける、平均的な正しいマッチングのパーセンテージ
- 手順
- 相互に最近傍のマッチングのみを考慮
- 提供されたホモグラフィを用いて推定された再投影誤差を計算
- 誤差が与えられたマッチング閾値以下であれば,マッチングは正しいと判定
-
Features and Matches
- 特徴記述子の性能を評価
- Featuresは、画像ごとに検出された特徴の平均数
- Matchesは、特徴のマッチングに成功した平均数
-
Percentage of Correct Keypoints(PCK)
- 密なマッチングの性能を測定するために一般的に使用される
- 画像グリッド上の1枚目の画像からキーポイントを抽出し、完全な2枚目の画像でそれらの最近傍を見つける
- クエリーポイントの予測マッチングは、GTのあるピクセル閾値内に収まれば正しいと判定
6.1.2 Homography Estimation
- angular correctness metric(角度の正しさの指標)は特徴マッチングアルゴリズムの性能を評価するために一般的に使用される
- 異なるマッチ数を生成する手法間で公平な比較をするため以下のような手順で計算する
- 2つの画像間のホモグラフィ $H$ を推定する(推論されたマッチを用いて)
- 推定ホモグラフィを使ってコーナー位置を変換(ワープ)する
- ground-truth ホモグラフィによって計算されたコーナーと比較
- 4つのコーナーの平均誤差が、指定されたピクセルの閾値より小さい場合正解と判定
- 通常は1~10ピクセルの範囲
- 閾値ごと上記の正解・不正解判定を集約してAUCを計算
- AUC: Area Under Curve
- AUC値は総合的なマッチング性能を表し、値が大きいほど性能が高いことを示す
6.1.3 Relative Pose Estimation
- 推定されたカメラの姿勢を評価する典型的な方法は、回転と並進の角度偏差を測定すること
- Angular deviations in rotations and translations
- 角度偏差がある閾値より小さければ、回転または並進は正しく推定されているとみなす
- その閾値における平均精度が計算できる
- フレーム間の間隔は$d_{frame}$で表され、値が大きいほどマッチングが難しい画像ペアであることを示す
- 複数の閾値で計算した結果を集約する方法
- AUC、マッチング精度、マッチングスコアなど
- 通常、並進誤差と角度誤差の最大値がポーズ誤差として注目される
6.1.4 Visual Localization
- 評価プロセスは通常下記に概説されている一般的な評価プロトコルに従う
- 手順
- Custom features を入力として使用
- COLMAPのようなフレームワークを使用して画像レジストレーションプロセスを実行
- あらかじめ定義された許容範囲内にうまく配置された画像の割合を計算
- 評価された手法の性能を報告するために、異なる閾値における姿勢誤差の累積AUCがしばしば使用される
6.1.5 Optical Flow Estimation
-
Average End-point Error(AEPE)
- mean Euclidean separation between the pred and GT correspondence map
-
flow outlier ratio(Fl)
- average percentage of outliers across all pixels
- outliers are defined as flow errors exceeding threshold
- 3 pixels or 5% of the GT flows
- outliers are defined as flow errors exceeding threshold
- average percentage of outliers across all pixels
-
Percentage of Correct Keypoints(PCK)
- 対応するGT点から指定された閾値(ピクセル単位)内に位置する適切にマッチした推定点の割合を計算
6.1.6 Structure from Motion
-
ETH metrics
- ETHで規定された評価フレームワークによって定義されている
- 再構成プロセスの忠実度を厳密に評価するために重要な指標
- 含まれている metrics
- 再構成の包括性の指標となる登録画像数
- シーンの描写の深さと複雑さについての洞察を提供する疎点メトリック
- 画像内の総観測量メトリック
- カメラのキャリブレーションと三角測量プロセスにとって極めて重要であり
- スパースポイントの画像投影が確認されたことを示す
- 平均特徴トラック長
- スパースポイントあたりの確認された画像観測の平均カウントを示す
- 正確なキャリブレーションとロバストな三角測量に重要な役割を果たす
- 平均再投影誤差
- バンドル調整で観測された累積再投影誤差を包含
- キーポイント検出の精度と同様に入力データの完全性に影響される
- 再構成の精度を評価するための重要な尺度
-
ETH3D metrics
- ETH3Dの主要なメトリクスは、様々なSfM手法の有効性を評価する上で非常に重要
- 含まれている metrics
- 異なる閾値におけるポーズエラーのAUC
- マルチビューカメラのポーズ推定の精度を評価するために使用される
- この指標は、GTに対する推定カメラポーズの精度を反映する
- 異なる距離の閾値における精度と網羅性の割合
- 3D三角測量タスクを評価する
- 精度: GTから一定の距離内に再構成された点の割合
- 網羅性: 再構成された点群内で適切に表現されたGT点の割合
- 異なる閾値におけるポーズエラーのAUC
6.2 Quantitative Performance(定量評価)
- このセクションでは、セクション6.1で提供された評価スコアの観点から、いくつかの主要な手法の性能を分析する
- 一般的なベンチマークでの性能を表にまとめた
- データは原著者、または同じ評価条件下で他の著者が報告した最良の結果のいずれかを使用
- 出版物によっては、非標準的なベンチマーク/データベースでの性能を報告していたり、一般的なベンチマークのテストセットの特定のサブセットのみを対象としていたりする。これらの手法の性能は示さない
HPatchesデータセットに対するホモグラフィ推定性能評価

ScanNetデータセットに対するTwo-viewカメラ姿勢推定性能評価

YFCC100Mデータセットに対するoutdoor pose推定性能評価

MegaDepthデータセットに対するTwo-viewカメラ姿勢推定性能評価

Aachen Day-Nightデータセットに対するカメラ姿勢推定性能評価

InLocデータセットに対するカメラ姿勢推定性能評価

7. Challenges and Opportunities(省略)
8. Conclusions
- LFM は、Detector-based Models と Detector-free Models に大別できる
- 特徴検出器の応用は、マッチングの範囲を狭め、キーポイント検出と特徴記述のプロセスに依存する
- 一方、Detector-free Models は、生画像からより豊かなコンテキストを直接取り込み、密なマッチングを生成する
- 次に、既存の局所特徴マッチングアルゴリズムの長所と短所を議論し、一般的なデータセットと評価基準を紹介し、HPatches、ScanNet、YFCC100M、MegaDepth、Aachen Day-Nightデータセットなどの一般的なベンチマークにおけるこれらのモデルの定量的な性能分析を要約する
- 最後に、局所特徴マッチングの分野が今後数年間で遭遇する可能性のある未解決の課題と潜在的な研究手段を探る
- 我々の目的は、局所特徴マッチングに関する研究者の理解を深めるだけでなく、この領域における将来の研究努力を鼓舞し導くことである
※おまけ: CVPR2024 に採択された LFM 系 paper
- Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
- RoMa: Robust Dense Feature Matching
- OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
- MESA: Matching Everything by Segmenting Anything
- XFeat: Accelerated Features for Lightweight Image Matching
その他参考記事・論文
- 【論文読み】SuperGlue - ロボティクスに欠かせない、GNNによる特徴マッチング手法
- 第三回 全日本コンピュータビジョン勉強会(前編) | SuperGlue;Learning Feature Matching with Graph Neural Networks (CVPR'20)
- cvpaper.challenge | SuperGlue: Learning Feature Matching With Graph Neural Networks
-
[2401.17592] Local Feature Matching Using Deep Learning: A Survey ↩ ↩2
-
画像からの3次元シーン理解に向けて、局所特徴量に基づく画像マッチング | 日経Robotics(日経ロボティクス) ↩ ↩2
-
D. DeTone, T. Malisiewicz, A. Rabinovich, Superpoint: Self-supervised interest point detection and description, in: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236. ↩
-
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, T. Sat- tler, D2-net: A trainable cnn for joint description and detection of local features, in: Proceedings of the ieee/cvf conference on computer vision and pattern recognition, 2019, pp. 8092–8101. ↩
-
J. Revaud, P. Weinzaepfel, C. De Souza, N. Pion, G. Csurka, Y. Cabon, M. Humenberger, R2d2: repeatable and reliable detector and descriptor, arXiv preprint arXiv:1906.06195 (2019). ↩
-
I. Rocco, M. Cimpoi, R. Arandjelovic ́, A. Torii, T. Pajdla, J. Sivic, Neighbourhood consensus networks, Advances in neural information processing systems 31 (2018). ↩
-
I. Rocco, R. Arandjelovic ́, J. Sivic, Efficient neighbourhood consensus networks via submanifold sparse convolutions, in: Computer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16, Springer, 2020, pp. 605–621. ↩
-
X. Li, K. Han, S. Li, V. Prisacariu, Dual-resolution correspondence net- works, Advances in Neural Information Processing Systems 33 (2020) 17346–17357. ↩
-
P. Truong, M. Danelljan, R. Timofte, Glu-net: Global-local univer- sal network for dense flow and correspondences, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6258–6268. ↩
-
P. Truong, M. Danelljan, L. Van Gool, R. Timofte, Learning accurate dense correspondences and when to trust them, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 5714–5724. ↩
-
P.-E. Sarlin, D. DeTone, T. Malisiewicz, A. Rabinovich, Superglue: Learning feature matching with graph neural networks, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, 2020, pp. 4938–4947. ↩
-
H. Chen, Z. Luo, J. Zhang, L. Zhou, X. Bai, Z. Hu, C.-L. Tai, L. Quan, Learning to match features with seeded graph matching network, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6301–6310. ↩
-
Y. Shi, J.-X. Cai, Y. Shavit, T.-J. Mu, W. Feng, K. Zhang, Clustergnn: Cluster-based coarse-to-fine graph neural network for efficient feature matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12517–12526. ↩
-
J. Sun, Z. Shen, Y. Wang, H. Bao, X. Zhou, Loftr: Detector-free local feature matching with transformers, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8922– 8931. ↩
-
H. Chen, Z. Luo, L. Zhou, Y. Tian, M. Zhen, T. Fang, D. McKinnon, Y. Tsin, L. Quan, Aspanformer: Detector-free image matching with adaptive span transformer, in: Computer Vision–ECCV 2022: 17th Eu- ropean Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXII, Springer, 2022, pp. 20–36. ↩
-
M. Brown, G. Hua, S. Winder, Discriminative learning of local image descriptors, IEEE transactions on pattern analysis and machine intelligence 33 (1) (2010) 43–57. ↩
-
Y. Tian, B. Fan, F. Wu, L2-net: Deep learning of discriminative patch descriptor in euclidean space, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 661–669. ↩
-
K. M. Yi, Y. Verdie, P. Fua, V. Lepetit, Learning to assign orientations to feature points, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 107–116. ↩
-
A. Mishchuk, D. Mishkin, F. Radenovic, J. Matas, Working hard to know your neighbor’s margins: Local descriptor learning loss, Advances in neural information processing systems 30 (2017). ↩
-
K. He, Y. Lu, S. Sclaroff, Local descriptors optimized for average precision, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 596–605. ↩
-
X. Wei, Y. Zhang, Y. Gong, N. Zheng, Kernelized subspace pooling for deep local descriptors, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1867–1875. ↩
-
K. Lin, J. Lu, C.-S. Chen, J. Zhou, M.-T. Sun, Unsupervised deep learning of compact binary descriptors, IEEE transactions on pattern analysis and machine intelligence 41 (6) (2018) 1501–1514. ↩
-
M. Zieba, P. Semberecki, T. El-Gaaly, T. Trzcinski, Bingan: Learning compact binary descriptors with a regularized gan, Advances in neural information processing systems 31 (2018). ↩
-
L. Wei, S. Zhang, H. Yao, W. Gao, Q. Tian, Glad: Global–local-alignment descriptor for scalable person re-identification, IEEE Transactions on Multimedia 21 (4) (2018) 986–999. ↩
-
Z. Luo, T. Shen, L. Zhou, S. Zhu, R. Zhang, Y. Yao, T. Fang, L. Quan, Geodesc: Learning local descriptors by integrating geometry constraints, in: Proceedings of the European conference on computer vision (ECCV), 2018, pp. 168–183. ↩
-
Y. Liu, Z. Shen, Z. Lin, S. Peng, H. Bao, X. Zhou, Gift: Learning transformation-invariant dense visual descriptors via group cnns, Advances in Neural Information Processing Systems 32 (2019). ↩ ↩2
-
J. Lee, Y. Jeong, S. Kim, J. Min, M. Cho, Learning to distill convolutional features into compact local descriptors, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 898–908. ↩ ↩2
-
Y. Tian, X. Yu, B. Fan, F. Wu, H. Heijnen, V. Balntas, Sosnet: Second order similarity regularization for local descriptor learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11016–11025.× ↩
-
P. Ebel, A. Mishchuk, K. M. Yi, P. Fua, E. Trulls, Beyond cartesian representations for local descriptors, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 253–262. ↩
-
Y. Tian, A. Barroso Laguna, T. Ng, V. Balntas, K. Mikolajczyk, Hynet: Learning local descriptor with hybrid similarity measure and triplet loss, Advances in neural information processing systems 33 (2020) 7401–7412. ↩
-
C. Wang, R. Xu, S. Xu, W. Meng, X. Zhang, Cndesc: Cross normalization for local descriptors learning, IEEE Transactions on Multimedia (2022). ↩
-
A. Barroso-Laguna, E. Riba, D. Ponsa, K. Mikolajczyk, Key. net: Keypoint detection by handcrafted and learned cnn filters, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5836–5844. ↩
-
X. Zhao, X. Wu, J. Miao, W. Chen, P. C. Chen, Z. Li, Alike: Accurate and lightweight keypoint detection and descriptor extraction, IEEE Transactions on Multimedia (2022). ↩
-
M. Kanakis, S. Maurer, M. Spallanzani, A. Chhatkuli, L. Van Gool, Zippypoint: Fast interest point detection, description, and matching through mixed precision discretization, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6113–6122. ↩
-
J. Tang, H. Kim, V. Guizilini, S. Pillai, A. Rares, Neural outlier rejection for self-supervised keypoint learning, in: 8th International Conference on Learning Representations, ICLR 2020, International Conference on Learning Representations, ICLR, 2020. ↩
-
Z. Luo, T. Shen, L. Zhou, J. Zhang, Y. Yao, S. Li, T. Fang, L. Quan, Contextdesc: Local descriptor augmentation with cross-modality context, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 2527–2536. ↩
-
C. Wang, R. Xu, Y. Zhang, S. Xu, W. Meng, B. Fan, X. Zhang, Mtldesc: Looking wider to describe better, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36, 2022, pp. 2388–2396. ↩
-
C. Wang, R. Xu, K. Lv, S. Xu, W. Meng, Y. Zhang, B. Fan, X. Zhang, Attention weighted local descriptors, IEEE Transactions on Pattern Analysis and Machine Intelligence (2023). ↩
-
J. Li, Q. Hu, M. Ai, Rift: Multi-modal image matching based on radiation-variation insensitive feature transform, IEEE Transactions on Image Processing 29 (2019) 3296–3310. ↩
-
E. Rosten, T. Drummond, Machine learning for high-speed corner detection, in: Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, May 7-13, 2006. Proceedings, Part I 9, Springer, 2006, pp. 430–443. ↩
-
S. Cui, M. Xu, A. Ma, Y. Zhong, Modality-free feature detector and descriptor for multimodal remote sensing image registration, Remote Sensing 12 (18) (2020) 2937. ↩
-
H. Xie, Y. Zhang, J. Qiu, X. Zhai, X. Liu, Y. Yang, S. Zhao, Y. Luo, J. Zhong, Semantics lead all: Towards unified image registration and fusion from a semantic perspective, Information Fusion 98 (2023) 101835. ↩
-
D. Mishkin, F. Radenovic, J. Matas, Repeatability is not enough: Learning affine regions via discriminability, in: Proceedings of the European conference on computer vision (ECCV), 2018, pp. 284–300. ↩
-
P. Truong, S. Apostolopoulos, A. Mosinska, S. Stucky, C. Ciller, S. D. Zanet, Glampoints: Greedily learned accurate match points, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 10732–10741. ↩
-
Q. Wang, X. Zhou, B. Hariharan, N. Snavely, Learning feature descriptors using camera pose supervision, in: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, Springer, 2020, pp. 757–774. ↩
-
M. Tyszkiewicz, P. Fua, E. Trulls, Disk: Learning local features with policy gradient, Advances in Neural Information Processing Systems 33 (2020) 14254–14265. ↩
-
J. Lee, B. Kim, S. Kim, M. Cho, Learning rotation-equivariant features for visual correspondence, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21887–21897. ↩
-
D. DeTone, T. Malisiewicz, A. Rabinovich, Superpoint: Self-supervised interest point detection and description, in: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 224–236. ↩
-
Y. Ono, E. Trulls, P. Fua, K. M. Yi, Lf-net: Learning local features from images, Advances in neural information processing systems 31 (2018). ↩
-
X. Shen, C. Wang, X. Li, Z. Yu, J. Li, C. Wen, M. Cheng, Z. He, Rf-net: An end-to-end image matching network based on receptive field, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8132–8140. ↩
-
A. Bhowmik, S. Gumhold, C. Rother, E. Brachmann, Reinforced feature points: Optimizing feature detection and description for a high-level task, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4948–4957. ↩
-
J. Revaud, P. Weinzaepfel, C. De Souza, N. Pion, G. Csurka, Y. Cabon, M. Humenberger, R2d2: repeatable and reliable detector and descriptor, arXiv preprint arXiv:1906.06195 (2019). ↩
-
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, T. Sattler, D2-net: A trainable cnn for joint description and detection of local features, in: Proceedings of the ieee/cvf conference on computer vision and pattern recognition, 2019, pp. 8092–8101. ↩
-
U. S. Parihar, A. Gujarathi, K. Mehta, S. Tourani, S. Garg, M. Milford, K. M. Krishna, Rord: Rotation-robust descriptors and orthographic views for local feature matching, in: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, pp. 1593–1600. ↩
-
A. Barroso-Laguna, Y. Verdie, B. Busam, K. Mikolajczyk, Hdd-net: Hybrid detector descriptor with mutual interactive learning, in: Proceedings of the Asian Conference on Computer Vision, 2020. ↩
-
Y. Zhang, J. Wang, S. Xu, X. Liu, X. Zhang, Mlifeat: Multi-level information fusion based deep local features, in: Proceedings of the Asian Conference on Computer Vision, 2020. ↩
-
S. Suwanwimolkul, S. Komorita, K. Tasaka, Learning of low-level feature keypoints for accurate and robust detection, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 2262–2271. ↩
-
X. Wang, Z. Liu, Y. Hu, W. Xi, W. Yu, D. Zou, Featurebooster: Boosting feature descriptors with a lightweight neural network, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7630–7639. ↩
-
Z. Luo, L. Zhou, X. Bai, H. Chen, J. Zhang, Y. Yao, S. Li, T. Fang, L. Quan, Aslfeat: Learning local features of accurate shape and localization, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6589–6598. ↩
-
B. Fan, J. Zhou, W. Feng, H. Pu, Y. Yang, Q. Kong, F. Wu, H. Liu, Learning semantic-aware local features for long term visual localization, IEEE Transactions on Image Processing 31 (2022) 4842–4855. ↩
-
F. Xue, I. Budvytis, R. Cipolla, Sfd2: Semantic-guided feature detection and description, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5206–5216. ↩
-
Y. Tian, V. Balntas, T. Ng, A. Barroso-Laguna, Y. Demiris, K. Mikolajczyk, D2d: Keypoint extraction with describe to detect approach, in: Proceedings of the Asian conference on computer vision, 2020. ↩
-
K. Li, L. Wang, L. Liu, Q. Ran, K. Xu, Y. Guo, Decoupling makes weakly supervised local feature better, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 15838–15848. ↩
-
Y. Deng, J. Ma, Redfeat: Recoupling detection and description for multimodal feature learning, IEEE Transactions on Image Processing 32 (2022) 591–602. ↩
-
J. Sun, J. Zhu, L. Ji, Shared coupling-bridge for weakly supervised local feature learning, arXiv preprint arXiv:2212.07047 (2022). ↩
-
P.-E. Sarlin, D. DeTone, T. Malisiewicz, A. Rabinovich, Superglue: Learning feature matching with graph neural networks, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4938–4947. ↩
-
H. Chen, Z. Luo, J. Zhang, L. Zhou, X. Bai, Z. Hu, C.-L. Tai, L. Quan, Learning to match features with seeded graph matching network, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6301–6310. ↩
-
Y. Shi, J.-X. Cai, Y. Shavit, T.-J. Mu, W. Feng, K. Zhang, Clustergnn: Cluster-based coarse-to-fine graph neural network for efficient feature matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12517–12526. ↩
-
Z. Li, J. Ma, Learning feature matching via matchable keypoint-assisted graph neural network, arXiv preprint arXiv:2307.01447 (2023). ↩
-
R. Pautrat, I. Suárez, Y. Yu, M. Pollefeys, V. Larsson, Gluestick: Robust image matching by sticking points and lines together, arXiv preprint arXiv:2304.02008 (2023). ↩
-
P. Lindenberger, P.-E. Sarlin, M. Pollefeys, Lightglue: Local feature matching at light speed, arXiv preprint arXiv:2306.13643 (2023). ↩
-
Z. Kuang, J. Li, M. He, T. Wang, Y. Zhao, Densegap: graph-structured dense correspondence learning with anchor points, in: 2022 26th International Conference on Pattern Recognition (ICPR), IEEE, 2022, pp. 542–549. ↩
-
Y. Cai, L. Li, D. Wang, X. Li, X. Liu, Htmatch: An efficient hybrid transformer based graph neural network for local feature matching, Signal Processing 204 (2023) 108859. ↩
-
X. Lu, Y. Yan, B. Kang, S. Du, Paraformer: Parallel attention transformer for efficient feature matching, arXiv preprint arXiv:2303.00941 (2023). ↩
-
Y. Deng, J. Ma, Resmatch: Residual attention learning for local feature matching, arXiv preprint arXiv:2307.05180 (2023). ↩
-
T. Xie, K. Dai, K. Wang, R. Li, L. Zhao, Deepmatcher: a deep transformer-based network for robust and accurate local feature matching, arXiv preprint arXiv:2301.02993 (2023). ↩
-
I. Rocco, M. Cimpoi, R. Arandjelović, A. Torii, T. Pajdla, J. Sivic, Neighbourhood consensus networks, Advances in neural information processing systems 31 (2018). ↩
-
I. Rocco, R. Arandjelović, J. Sivic, Efficient neighbourhood consensus networks via submanifold sparse convolutions, in: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16, Springer, 2020, pp. 605–621. ↩
-
X. Li, K. Han, S. Li, V. Prisacariu, Dual-resolution correspondence networks, Advances in Neural Information Processing Systems 33 (2020) 17346–17357. ↩
-
P. Truong, M. Danelljan, R. Timofte, Glu-net: Global-local universal network for dense flow and correspondences, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6258–6268. ↩
-
P. Truong, M. Danelljan, L. V. Gool, R. Timofte, Gocor: Bringing globally optimized correspondence volumes into your neural network, Advances in Neural Information Processing Systems 33 (2020) 14278–14290. ↩
-
P. Truong, M. Danelljan, L. Van Gool, R. Timofte, Learning accurate dense correspondences and when to trust them, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 5714–5724. ↩
-
P. Truong, M. Danelljan, R. Timofte, L. Van Gool, Pdc-net+: Enhanced probabilistic dense correspondence network, IEEE Transactions on Pattern Analysis and Machine Intelligence (2023). ↩
-
J. Revaud, V. Leroy, P. Weinzaepfel, B. Chidlovskii, Pump: Pyramidal and uniqueness matching priors for unsupervised learning of local descriptors, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3926–3936. ↩
-
J. Revaud, P. Weinzaepfel, Z. Harchaoui, C. Schmid, Deepmatching: Hierarchical deformable dense matching, International Journal of Computer Vision 120 (2016) 300–323. ↩
-
U. Efe, K. G. Ince, A. Alatan, Dfm: A performance baseline for deep feature matching, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4284–4293. ↩
-
W. Jiang, E. Trulls, J. Hosang, A. Tagliasacchi, K. M. Yi, Cotr: Correspondence transformer for matching across images, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6207–6217. ↩
-
D. Tan, J.-J. Liu, X. Chen, C. Chen, R. Zhang, Y. Shen, S. Ding, R. Ji, Eco-tr: Efficient correspondences finding via coarse-to-fine refinement, in: European Conference on Computer Vision, Springer, 2022, pp. 317–334. ↩
-
J. Sun, Z. Shen, Y. Wang, H. Bao, X. Zhou, Loftr: Detector-free local feature matching with transformers, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8922–8931. ↩
-
H. Chen, Z. Luo, L. Zhou, Y. Tian, M. Zhen, T. Fang, D. McKinnon, Y. Tsin, L. Quan, Aspanformer: Detector-free image matching with adaptive span transformer, in: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXII, Springer, 2022, pp. 20–36. ↩
-
G. Bökman, F. Kahl, A case for using rotation invariant features in state of the art feature matchers, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5110–5119. ↩
-
S. Tang, J. Zhang, S. Zhu, P. Tan, Quadtree attention for vision transformers, arXiv preprint arXiv:2201.02767 (2022). ↩
-
Y. Chen, D. Huang, S. Xu, J. Liu, Y. Liu, Guide local feature matching by overlap estimation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36, 2022, pp. 365–373. ↩
-
Q. Wang, J. Zhang, K. Yang, K. Peng, R. Stiefelhagen, Matchformer: Interleaving attention in transformers for feature matching, in: Proceedings of the Asian Conference on Computer Vision, 2022, pp. 2746–2762. ↩
-
J. Ma, Y. Wang, A. Fan, G. Xiao, R. Chen, Correspondence attention transformer: A context-sensitive network for two-view correspondence learning, IEEE Transactions on Multimedia (2022). ↩
-
K. T. Giang, S. Song, S. Jo, Topicfm: robust and interpretable feature matching with topic-assisted, arXiv preprint arXiv:2207.00328 (2022). ↩
-
J. Yu, J. Chang, J. He, T. Zhang, J. Yu, F. Wu, Adaptive spot-guided transformer for consistent local feature matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21898–21908. ↩
-
T. Xie, K. Dai, K. Wang, R. Li, L. Zhao, Deepmatcher: a deep transformer-based network for robust and accurate local feature matching, arXiv preprint arXiv:2301.02993 (2023). ↩
-
K. Dai, T. Xie, K. Wang, Z. Jiang, R. Li, L. Zhao, Oamatcher: An overlapping areas-based network for accurate local feature matching, arXiv preprint arXiv:2302.05846 (2023). ↩
-
C. Cao, Y. Fu, Improving transformer-based image matching by cascaded capturing spatially informative keypoints, arXiv preprint arXiv:2303.02885 (2023). ↩
-
S. Zhu, X. Liu, Pmatch: Paired masked image modeling for dense geometric matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21909–21918. ↩
-
J. Chang, J. Yu, T. Zhang, Structured epipolar matcher for local feature matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6176–6185. ↩
-
J. Edstedt, I. Athanasiadis, M. Wadenbäck, M. Felsberg, Dkm: Dense kernelized feature matching for geometry estimation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17765–17775. ↩
-
J. Edstedt, Q. Sun, G. Bökman, M. Wadenbäck, M. Felsberg, Roma: Revisiting robust losses for dense feature matching, arXiv preprint arXiv:2305.15404 (2023). ↩
-
Q. Zhou, T. Sattler, L. Leal-Taixe, Patch2pix: Epipolar-guided pixel-level correspondences, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4669–4678. ↩
-
D. Huang, Y. Chen, Y. Liu, J. Liu, S. Xu, W. Wu, Y. Ding, F. Tang, C. Wang, Adaptive assignment for geometry aware local feature matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5425–5434. ↩
-
J. Ni, Y. Li, Z. Huang, H. Li, H. Bao, Z. Cui, G. Zhang, Pats: Patch area transportation with subdivision for local feature matching, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17776–17786. ↩
-
Y. Zhang, X. Zhao, D. Qian, Searching from area to point: A hierarchical framework for semantic-geometric combined feature matching, arXiv preprint arXiv:2305.00194 (2023). ↩
-
P. Lindenberger, P.-E. Sarlin, V. Larsson, M. Pollefeys, Pixel-perfect structure-from-motion with featuremetric refinement, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 5987–5997. ↩
-
C. M. Parameshwara, G. Hari, C. Fermüller, N. J. Sanket, Y. Aloimonos, Diffposenet: direct differentiable camera pose estimation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6845–6854. ↩
-
J. Y. Zhang, D. Ramanan, S. Tulsiani, Relpose: Predicting probabilistic relative rotation for single objects in the wild, in: European Conference on Computer Vision, Springer, 2022, pp. 592–611. ↩
-
C. Tang, P. Tan, Ba-net: Dense bundle adjustment network, arXiv preprint arXiv:1806.04807 (2018). ↩
-
X. Gu, W. Yuan, Z. Dai, C. Tang, S. Zhu, P. Tan, Dro: Deep recurrent optimizer for structure-from-motion, arXiv preprint arXiv:2103.13201 (2021). ↩
-
X. He, J. Sun, Y. Wang, S. Peng, Q. Huang, H. Bao, X. Zhou, Detector-free structure from motion, arXiv preprint arXiv:2306.15669 (2023). ↩