概要
Flask を使って機械学習 API をサクッと作ります。
下記のような結果を返すことが目標です。
$ curl http://0.0.0.0:5000/predict -X POST -H 'Content-Type:application/json' -d '{"feature":[1, 1, 1, 1]}'
{"Content-Type":"application/json","prediction":[2],"success":true}
対象
- なんとなく API は知っているけど、実装しようとすると「???」ってなる人
- 機械学習 API を作ってみたい人
- 既存のサービスに機械学習の処理を加えてみたい人
- 高負荷は想定していません
API について
ここでは REST API を想定しています。
REST API って何
詳細は私も詳しくないので下記リンク参照してください。
本稿では URL 越しに機能(今回でいうと学習後モデルによる分類)を使えるようにしたもの 程度の認識で良いです。
API にすると何が嬉しいのか
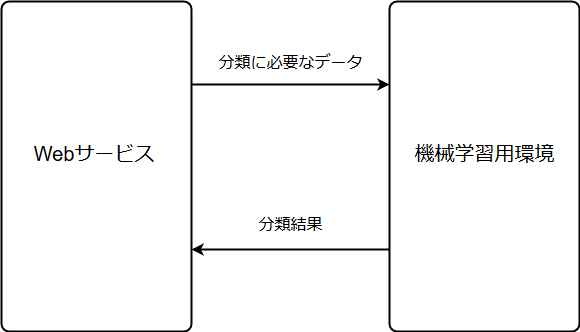
-
既存サービスへの影響が少ない
- 環境を分けられる
- 言語が違っても良い
- コードがそこまで混在しない
- 外部の機械学習サービス(AWS とか GCP で提供されているもの)に移行しやすい
作成手順
1. 環境構築
Flask と学習・予測に必要なライブラリが既に入っている人はスキップ
今回は pyenv-virtualenv を使って仮想環境を構築しますが、
各自の方法に任せます。
1.1 仮想環境
$ pyenv install 3.7.0
$ pyenv virtualenv 3.7.0 test3.7.0
$ pyenv local test3.7.0
(test3.7.0) $ pyenv versions
system
3.6.3
3.7.0
3.7.0/envs/test3.7.0
* test3.7.0 (set by ~~~)
1.2 Python パッケージインストール
(test3.7.0) $ pip install Flask
(test3.7.0) $ pip install scikit-learn
(test3.7.0) $ pip install numpy
(test3.7.0) $ pip install scipy
2. 学習用スクリプト
今回は機械学習のモデルは重視していないので、
サクッと scikit-learn 内のモデルとデータ(iris)を使って学習済モデルを作成します。
iris データについて詳細は省略しますが、
一言でいうと 草の形(4パラメータ)とその草の種類(3種類)がまとまっているデータ です。
train.py
from sklearn import svm
from sklearn import datasets
from sklearn.externals import joblib
def main():
# classifier
clf = svm.SVC()
# data(iris)
iris = datasets.load_iris()
# Split train_x, train_y
X, y = iris.data, iris.target
# train
clf.fit(X, y)
# save model
joblib.dump(clf, './trained-model/sample-model.pkl')
if __name__ == '__main__':
main()
実行
(test3.7.0) $ python train.py
/Users/fujimotoyuusuke/.pyenv/versions/test3.7.0/lib/python3.7/site-packages/sklearn/feature_extraction/text.py:17: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Mapping, defaultdict
(test3.7.0) $ ls trained-model
sample-model.pkl
sample-model.pkl が作られていれば OK です。
3. Flask 本体
サクッと作るためにあまり凝ったことはしませんできません。
ただし要求の度にモデルを読み込む必要はないので、load_model() を定義してそこで読み込むようにしています。
run_server.py
from sklearn.externals import joblib
import flask
import numpy as np
# initialize our Flask application and pre-trained model
app = flask.Flask(__name__)
model = None
def load_model():
global model
print(" * Loading pre-trained model ...")
model = joblib.load("./trained-model/sample-model.pkl")
print(' * Loading end')
@app.route("/predict", methods=["POST"])
def predict():
response = {
"success": False,
"Content-Type": "application/json"
}
# ensure an feature was properly uploaded to our endpoint
if flask.request.method == "POST":
if flask.request.get_json().get("feature"):
# read feature from json
feature = flask.request.get_json().get("feature")
# preprocess for classification
# list -> np.ndarray
feature = np.array(feature).reshape((1, -1))
# classify the input feature
response["prediction"] = model.predict(feature).tolist()
# indicate that the request was a success
response["success"] = True
# return the data dictionary as a JSON response
return flask.jsonify(response)
if __name__ == "__main__":
load_model()
print(" * Flask starting server...")
app.run()
4. 確認
4.1 API サーバー起動
下記のようなメッセージが出れば起動できています。
(test3.7.0) $ python run_server.py
* Loading pre-trained model ...
* Loading end
* Flask starting server...
* Serving Flask app "run_server" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
4.2 cURL コマンドで確認
ここでもう一つターミナル等を開いて下記コマンドを打ちます。
curlコマンドで確認
$ curl http://0.0.0.0:5000/predict -X POST -H 'Content-Type:application/json' -d '{"feature":[1, 1, 1, 1]}'
予測結果
{"Content-Type":"application/json","prediction":[2],"success":true}
success:true となって予測結果が返ってくれば成功です!
そのうち機会があれば、Keras の画像処理モデルを使って簡単な Web サービス作ってみようと思います。
参考資料
- Building a simple Keras + deep learning REST API - The Keras Blog
-
A scalable Keras + deep learning REST API - PyImageSearch
- Redis キューイングを使ったスケーラブルな REST API を構築するらしい…
-
https://github.com/yukkyo/simple-ml-api
- 今回作ったコード