概要
京大生専用の大学ポータルでは、留学や奨学金情報が掲載されています。しかし、毎回そこにログインしてアクセスするのが面倒なので、Twitter Botをつくりました。
↓作ったTwitter Bot
https://twitter.com/AAJhGLyq6z2rxzc?lang=ja
例えば、こんなツイート
2020年度 日本人対象アメリカ留学フルブライト奨学生の募集
— 京大留学・奨学金情報Bot (@AAJhGLyq6z2rxzc) 2019年5月10日
標記について、日米教育委員会事務局長より案内がありましたのでお知らせします。
個人応募ですので希望者は直接応募してください。
下記URLより募集要項等のダウンロードができます。https://t.co/co3g5wxNGd
京大生フォローしてほしい(切実
京大生ならわかるのですが、下記のような学生ポータルのようなものがある。
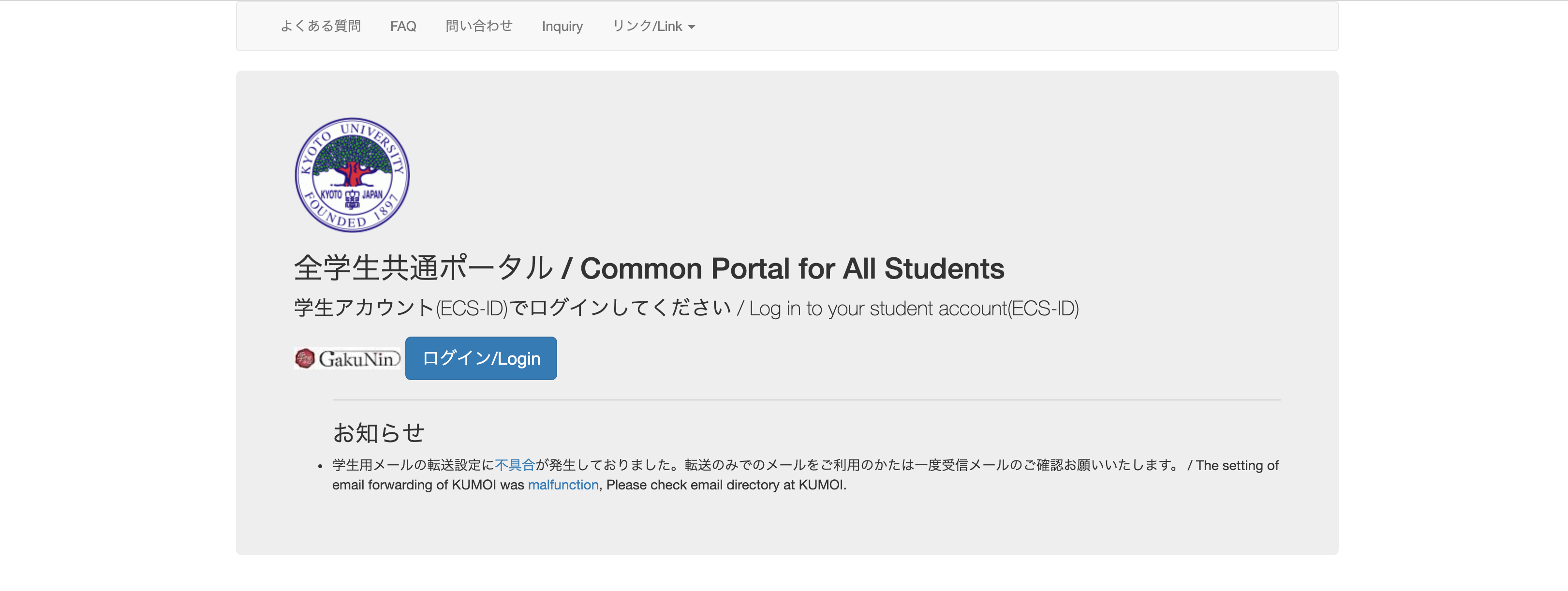
ログインするとこのように毎週のように留学情報や奨学金情報が掲載されたページに入れる

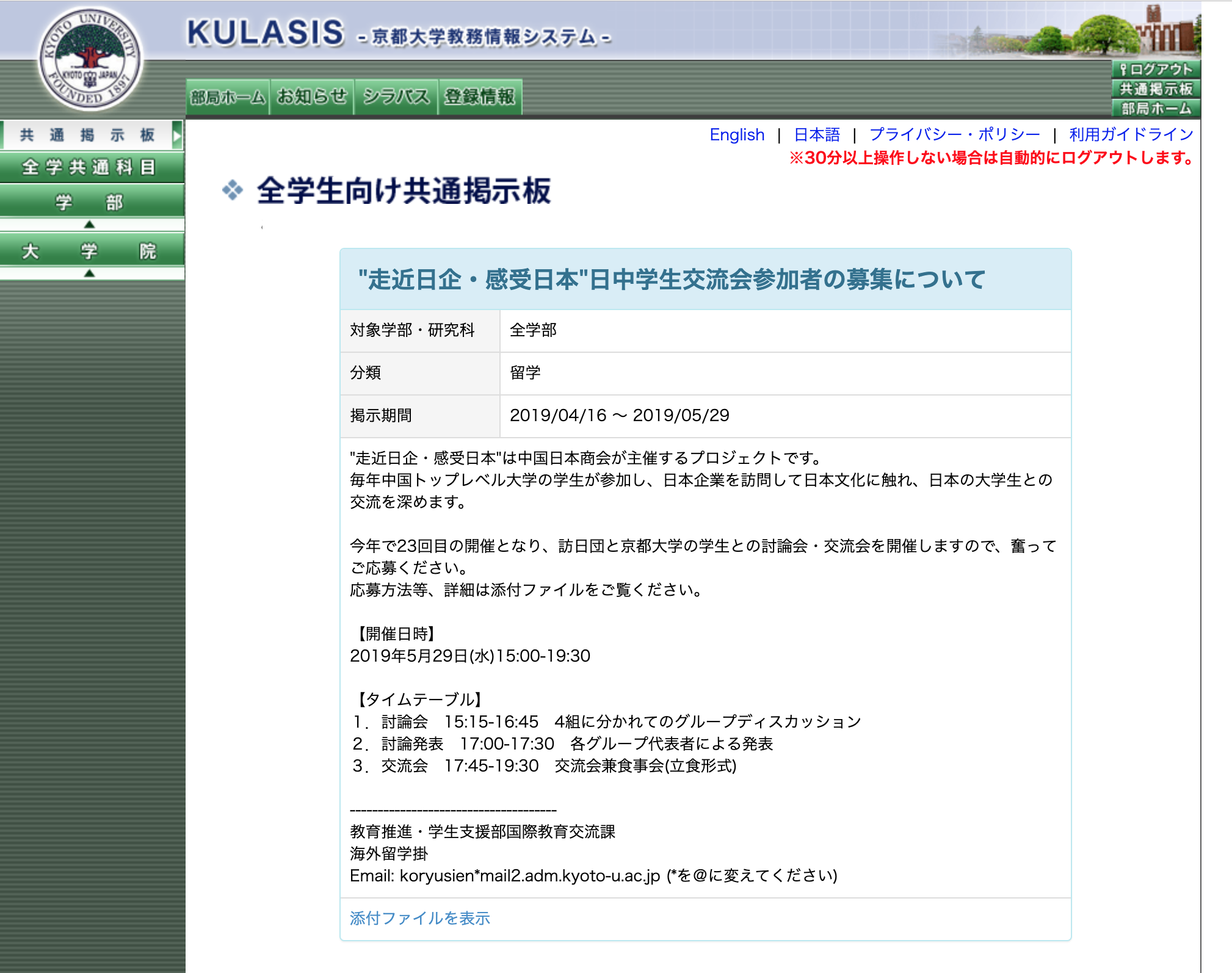
この奨学金・留学情報はかなりよく、
例えば、航空券・ホテル代・食費・プログラム費用すべてタダでサンフランシスコやワシントンに行けるプログラムとか20万円くらいもらって好きな国にいけるプログラムなどがある
つまり、京大生はこのページを見れば、「タダで海外に数週間いける」ことが全然可能なのだ。
ただ、毎回この掲示板にアクセスして、新しく募集がないか?と調べるのは非常に面倒。
ということで、更新情報を定期的に配信するTwitter Botを作った。
やり方
こんな手順でやりました。ね、簡単でしょ。
1, Twitter APIを申請・取得
2, Selenium ChromeDriver + Python で自動ログインをする
3, スクレイピングをして、最新の募集情報を取得
4, Twitter APIで取得データをツイートする。
1, Twitter APIの取得
ここからできます。
https://developer.twitter.com/en/docs.html
ただ、注意としてTwitter社のガイドラインの変更で、
最近からAPIの申請が非常にきびしくなっています。理由や用途をしっかり書かないと、却下されます。
(適当な文字列とかだと自動で弾いているようです)
2, Selenium ChromeDriver + Python で自動ログインをする
Selenium ChromeDriverをつかえば、勝手にブラウザを開いて、ページ遷移をしたり、クリックしたりという作業を自動で行うことができます。
まぁ便利!
下記がコードです。
自動でログインをし、driver.get()で募集ページに遷移しています。
def scrape():
chrome_options = Options()
driver = webdriver.Chrome(executable_path='####', chrome_options=chrome_options)
print('ログイン中')
driver.get('https://student.iimc.kyoto-u.ac.jp/login.html')
#ログイン処理
driver.find_element_by_id('username').send_keys(ID)
driver.find_element_by_id('password').send_keys(PASS)
driver.find_element_by_name('_eventId_proceed').click()
print('ログイン成功')
driver.get("https://www.k.kyoto-u.ac.jp/student/la/information_list?no[0]=5")
#募集の数
row_count = len(driver.find_elements_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div[2]/table/tbody/tr"))
3, スクレイピングをして、募集情報を取得
driver.find_element_by_xpathを使えば、スクレイピングも簡単です。
要素を選択して、.text()をするだけ。
要素のパスは右クリックで取得すればいいです。
for i in range(1,row_count):
driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div[2]/table/tbody/tr["+str(i)+"]/td/a").click()
title = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div/h2").text
term = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/table/tbody/tr[3]/td[2]").text
main = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/table/tbody/tr[4]/td/div").text
url = driver.current_url
classやidなどでも取得できます。
https://kurozumi.github.io/selenium-python/locating-elements.html
4, APIで取得データをTweetする。
ツイート部分は簡単で、オブジェクトを作成して、 api.update_status(status)
とするだけデス。
# Twitterオブジェクトの生成
auth = tweepy.OAuthHandler(CK, CS)
auth.set_access_token(AT, AS)
api = tweepy.API(auth)
for i in range(1,row_count):
driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div[2]/table/tbody/tr["+str(i)+"]/td/a").click()
title = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div/h2").text
term = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/table/tbody/tr[3]/td[2]").text
main = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/table/tbody/tr[4]/td/div").text
url = driver.current_url
#urlを短縮化
url = get_shortenURL(url)
count_main = 140 - len(url) - len(title)
main_tw = main[:count_main] #本文の文字数を加工
#ツイート
status= title + "\n" +main_tw + url
api.update_status(status)
#一覧ページに戻る
driver.get("https://www.k.kyoto-u.ac.jp/student/la/information_list?no[0]=5")
少々手こずったところは、ツイッターは140文字という文字数があることで、募集内容の文章がすべて入らない。
そのため、BitlyというURL短縮サービスのAPIを使って、URLを短縮化していたり(下記のコード)、
URLや本文の長さを測定して、文字数がオーバーしてツイートしないようにしている
def get_shortenURL(longUrl):
url = 'https://api-ssl.bitly.com/v3/shorten'
#bitly access_token
access_token = "######"
query = {
'access_token': access_token,
'longurl':longUrl
}
r = requests.get(url,params=query).json()['data']['url']
return r
コード
※プログラミングは初心者なので、間違いあったら指摘ください。コードをはかなり雑ですがご容赦を。
↓↓みんなフォローしてね!
https://twitter.com/AAJhGLyq6z2rxzc?lang=ja
2020年度 日本人対象アメリカ留学フルブライト奨学生の募集
— 京大留学・奨学金情報Bot (@AAJhGLyq6z2rxzc) 2019年5月10日
標記について、日米教育委員会事務局長より案内がありましたのでお知らせします。
個人応募ですので希望者は直接応募してください。
下記URLより募集要項等のダウンロードができます。https://t.co/co3g5wxNGd
import sys
import requests
import schedule
import time
import csv
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import tweepy
import twitter
import json #標準のjsonモジュールとconfig.pyの読み込み
from requests_oauthlib import OAuth1Session #OAuthのライブラリの読み込み
# ログイン情報
ID = "#######"
PASS = "######"
# twitter api key
CK="######"
CS="######"
AT="######"
AS="######"
def get_shortenURL(longUrl):
url = 'https://api-ssl.bitly.com/v3/shorten'
#bitly access_token
access_token = "######"
query = {
'access_token': access_token,
'longurl':longUrl
}
r = requests.get(url,params=query).json()['data']['url']
return r
def scrape():
chrome_options = Options()
driver = webdriver.Chrome(executable_path='####', chrome_options=chrome_options)
print('ログイン中')
driver.get('https://student.iimc.kyoto-u.ac.jp/login.html')
#ログイン処理
driver.find_element_by_id('username').send_keys(ID)
driver.find_element_by_id('password').send_keys(PASS)
driver.find_element_by_name('_eventId_proceed').click()
print('ログイン成功')
driver.get("https://www.k.kyoto-u.ac.jp/student/la/information_list?no[0]=5")
#募集の数
row_count = len(driver.find_elements_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div[2]/table/tbody/tr"))
# Twitterオブジェクトの生成
auth = tweepy.OAuthHandler(CK, CS)
auth.set_access_token(AT, AS)
api = tweepy.API(auth)
for i in range(1,row_count):
driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div[2]/table/tbody/tr["+str(i)+"]/td/a").click()
title = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/div/h2").text
term = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/table/tbody/tr[3]/td[2]").text
main = driver.find_element_by_xpath("//*[@id='wrapper']/div[2]/div[5]/div/table/tbody/tr[4]/td/div").text
url = driver.current_url
#urlを短縮化
url = get_shortenURL(url)
count_main = 140 - len(url) - len(title)
main_tw = main[:count_main] #本文の文字数を加工
#ツイート
status= title + "\n" +main_tw + url
api.update_status(status)
#一覧ページに戻る
driver.get("https://www.k.kyoto-u.ac.jp/student/la/information_list?no[0]=5")
#すべて終わったらchromeを閉じる
driver.close()
if __name__ == "__main__":
scrape()