概要
文字コードの違いで、「文字化け」や「読み込みエラー」に悩んだ経験はありませんか?本記事では、主に文字コードの「UTF-8」「UTF-16」の違いや、BOMの有無、Pythonで取り扱う場合の注意事項について解説します。
はじめに
この記事を書いたきっかけは、UTF-16エンコードのタブ区切りCSVファイルからデータを抽出するプログラムのPytest実装を試みたことです。
これまでcsvデータをcp932で読み込めるケースが多かったこともあり、UTF-16のテストデータや正解データの作成に苦戦しました。文字コードは今まであまり意識していなかったですが、ハマりやすいポイントと感じました。
この記事が文字コードで悩む方の助けになれば幸いです。
検証条件
- 環境
- Windows 11
- 使用エディタ
- メモ帳
UTF-8とは?
- 世界のあらゆる文字を表現できるエンコーディング
- 可変長の方式で、文字によって1〜4バイトを使い分ける
- 英数字のみのテキストはASCIIと完全互換
- 日本語などの多バイト文字は2〜3バイト以上で表現
- Web、テキストファイル、API、ログなどで広く利用
UTF-16とは?
- 基本は2バイトで表現(一部文字は4バイト)
- ASCIIでも2バイトになることが多く、日本語は基本的に2バイト
- Windowsの内部の文字列や、Java/C#、JavaScriptなどのランタイム内部表現で利用
UTF-8-sigとは?
-
utf-8の先頭にBOM(Byte Order Mark)を付与したエンコーディング - ExcelやWindowsが正しくutf-8として認識するための文字化け対策
- Python上では
utf-8-sigとして扱う
BOMとは?
- テキストファイル先頭に付与される特殊なバイト列
- 文字コードやバイト順(エンディアン)を示す役割
-
utf-8:必須ではないが、MicrosoftアプリやExcelで文字化け防止のため付与されることが多い -
utf-16:BOMがないとエンディアン(LE:リトルエンディアン/BE:ビッグエンディアン)判別不可。仕様上必須ではないが実務では必須扱い
BOMあり・なしで起きる問題
- BOMなしUTF-8:Linux系やWebでは一般的だが、Excelやメモ帳で開くと文字化けの可能性
- BOMありUTF-8(utf-8-sig):WindowsやExcelでは正常に表示される。Pythonで読み込む際は
utf-8-sig指定が必要 - UTF-16:BOMなしではエンディアン誤認による文字化けやエラーの原因
Windowsメモ帳での注意点
- メモ帳で「名前を付けて保存」する際、文字コード選択に注意
- デフォルトは
utf-8(BOM付き) -
utf-16 LEやutf-16 BE選択時はBOMが自動付与
- デフォルトは
- Pythonでの読み込み
- encoding='utf-8-sig':BOM付きUTF-8を安全に処理
- encoding='utf-16':BOMを自動判別して読み込み
-
utf-8(BOMなし)で保存する場合
エンコードでUTF-8を選択して保存
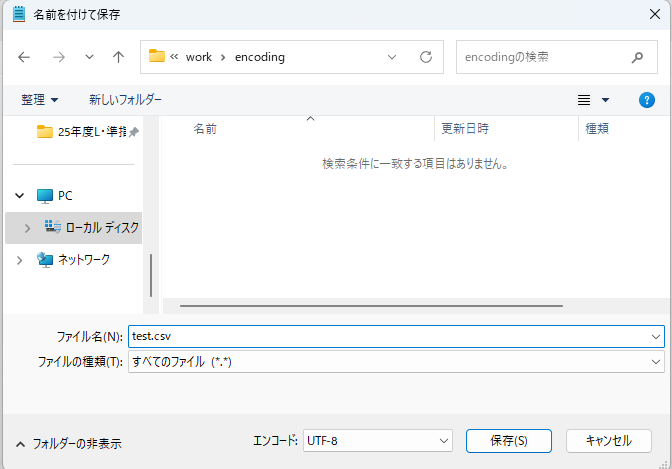
-
utf-8(BOM付き)で保存する場合
エンコードでUTF-8(BOM 付き)を選択して保存
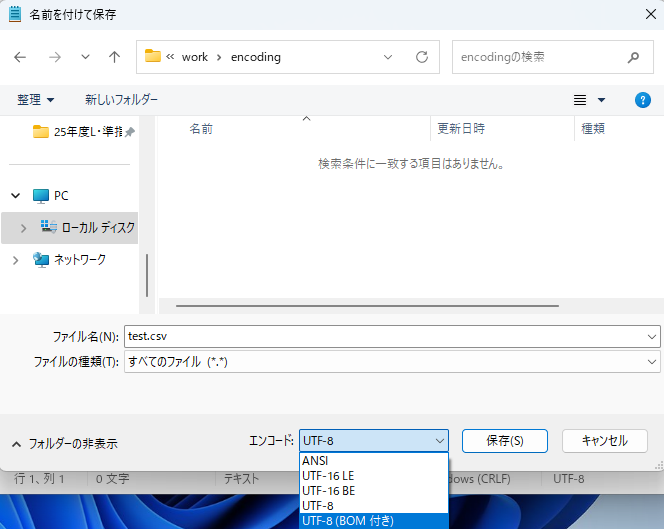
-
utf-16(BOM付き)で保存する場合
エンコードでUTF-16 LEやUTF-16 BEを選択して保存
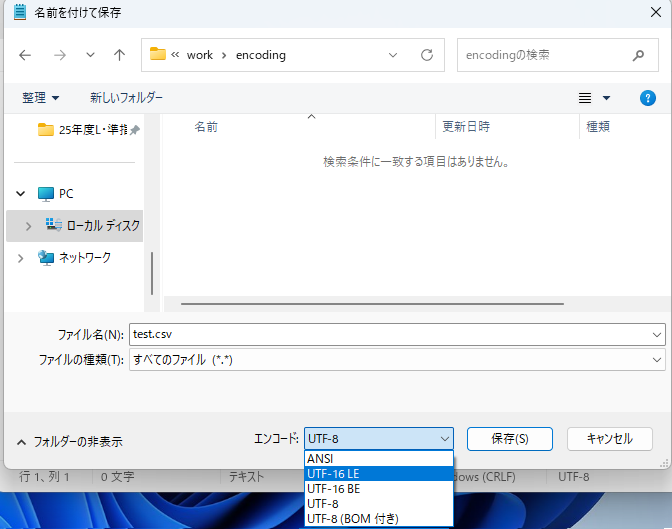
-
ANSIで保存する場合
エンコードでANSIを選択して保存(日本語環境ではShift_JIS)
※Pythonで読み込む場合は、encoding='cp932'もしくはencoding='shift_jis'を指定
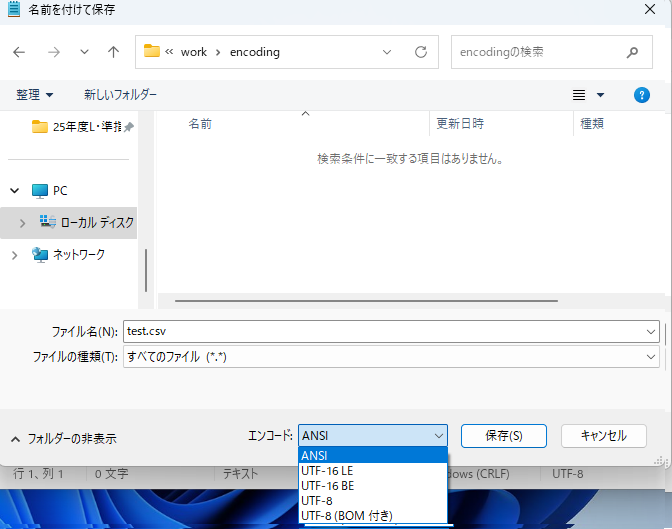
Pythonでの取り扱いポイント
- 書き込み時にBOMをつけたい場合
with open('output.csv', 'w', encoding='utf-8-sig') as f:
f.write('名前,年齢\n')
- 読み込み時にBOMを除去したい場合
with open('output.csv', 'r', encoding='utf-8-sig') as f:
content = f.read()
- UTF-16の場合
with open('output.csv', 'r', encoding='utf-16') as f:
content = f.read()
BOMがあれば自動判別されるが、エンディアンを誤認するリスク有
テストデータ作成時の落とし穴
- Pytestにおいて、出力ファイル内容のassertでBOMが原因で上手くいかないことがある
正解データと実際の出力でBOMの有無が異なると、文字列比較で失敗 - 対策:
- テストデータは必ず 同じエンコード(BOM設定含む) で作成
- 特に、csvでテストデータを作成する際は文字コードのドツボにハマりやすいので、メモ帳かもしくはVisual Studio Code上で必ずエンコーディング指定(今回はVisual Studio Codeでの保存方法に関しては割愛)
あとがき
この記事が少しでも文字コードで悩む方の助けになれば幸いです。
最後までお読みいただき、ありがとうございました。