はじめに
大規模データについて、巷ではいろいろと情報が溢れ出していますけど、
実際にはどうやるの?何がよいの?使える情報は何なの?
って、思ったり探したりしていませんか?
(自分だけですかね?)
と言うことで、今秋より、大規模データについて、実際に
検証、開発、運用、といった研究ミッションを担うことになりましたので、
この場をお借りしまして、いろんなこと試してみたいと思います!
インターネットサービスは設計~開発~運用全てが順調に
回ることによって成り立つと考えています。
このような視点も織り交ぜて書いて行ければと思っています。
紹介
今後の連載として以下をアップしました。
いまやっているデータ処理について
さて、本題に入りまして先ず、本連載で扱う 大規模データ処理 とは
どのような処理か?
それについて説明させていただきたいと思います。
大規模データ処理とは
明確な定義があるというわけではないのですが、
入力データとして 1GB以上 の整形済み(csv、ltsv)データを読み込み、
数時間以内 に処理を完了させる必要があるもの。
1GB程度の読み込みデータで、1時間以内に処理を
終わらせるような処理は本連載では扱いません。
ツールについて
次に、大規模データ処理に使うツールについて紹介します。
大規模データ処理では主に Hadoop を使っています。
実行環境によって EMR(AWSのクラウドサービス) 、
オンプレミス(データセンタでの自社サーバ運用) に大別できます。
割合としては、現状以下になっています。
- EMR(利用割合90%)
- オンプレHadoop、hive(利用割合10%)
運用面の利点(詳しくはEMRの回で)からオンプレ処理を削減しており、
将来的にはオンプレ廃止を目指しています。
また、データ分析の更なる効率化を目指して
Redshift 導入に向けて検証を行ってます。
データフローについて
データの流れを主軸とした概要図は以下になります。
ログを生成する配信サーバの構成図は先日公開した配信サーバの構成図をご参照ください。
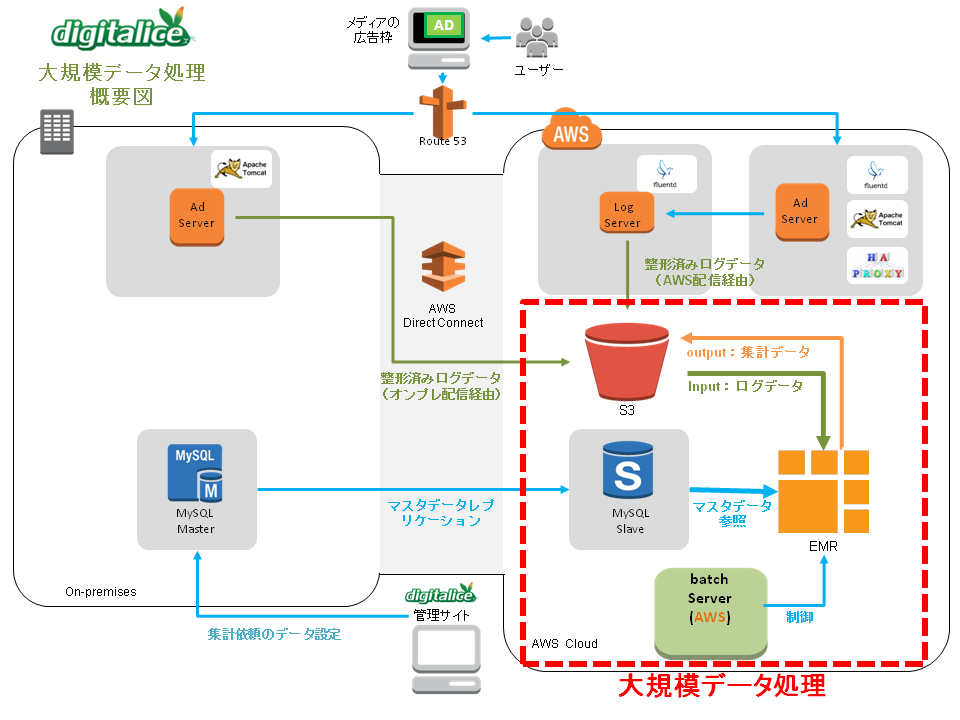
- 入力データ(整形済みログデータ)
- 配信ログ
- 効果計測ログ
- 上記ログを生成した中間データ
基本的な処理として、入力データをEMRで処理し、S3へ結果データが出力されます。
次にバッチサーバで出力データを後処理してDB登録、または成果物ファイルへの変換処理をする流れです。
代表的な集計処理
- 処理単位ごとに訪問ユーザのフリークエンシーを集計(freq)
指定された期間のユーザアクティビティをフリークエンシー、処理単位(クライアント、ユニット)毎に集計。
出力:処理単位のid、フリークエンシーカウント、アクティビティ(click,cv,ビュースルーcv、ビュースルーサーチcv)
- 処理単位ごとに訪問ユーザのUU数を集計(uu)
指定された期間のUU数を処理単位(クライアント、ユニット)毎に集計(オプションでクロス集計)。
- 処理単位ごとに訪問ユーザの行動履歴を抽出(cvpath)
指定された期間のユーザの行動履歴を時系列で抽出。
あとがき
今回の投稿は以上となります。
今回は第1回ということで、先ずは大規模データ処理の
概要のみをザックリと紹介いたしました。
次回以降では、大規模データ処理の具体的なところを
ピックアップしてお伝えできればと考えております。
今後とも、よろしくお願いいたします。