これは何か
Vertex AI Pipelines でパイプラインを組む際に「これってどうやるんだっけ」となった時に参照するためのメモです。基本的には Kubeflow のドキュメント や Vertex AI Pipelines のドキュメントに書いてあることのはずです。
コンポーネントに名前をつける
コンポーネントにメソッドチェーンのような形で set_display_name を付加します。
@component()
def print_op(msg: str):
print(msg)
@dsl.pipeline(name="test")
def pipeline():
print_op("hello").set_display_name("test1")
print_op("world").set_display_name("test2")
実行結果

ジョブを実行するマシンスペックを指定する
コンポーネントのジョブはデフォルトではe2-standard-4 (4 vCPU, 16GB) のマシンが起動します。指定したリソースの通りにマシンが設定されるわけではなく、「指定したリソースに近いマシン」が自動的に選定されます。
ここの例ではそれぞれ以下のマシンが起動します。
| display name | 起動するマシン |
|---|---|
test1 |
e2-highcpu-16 |
test2 |
e2-highmem-2 |
test3 |
n1-highmem-2 (with 2 GPUs) |
@component()
def print_op(msg: str):
print(msg)
@component()
def check_nvidia():
import subprocess
subprocess.run("nvidia-smi", shell=True)
@dsl.pipeline(name="test")
def pipeline():
print_op("hello").set_display_name("test1").set_cpu_limit("10")
print_op("world").set_display_name("test2").set_memory_limit("20")
check_nvidia().set_display_name("test3").add_node_selector_constraint("cloud.google.com/gke-accelerator", "NVIDIA_TESLA_T4").set_gpu_limit(2)
ちなみに GPU を使用するように指定すれば自動的に NVIDIA ドライバーがインストールされるはずですが、 nvidia-smi コマンドは使えません。
ジョブの実行順序を指定する
以下の3つのパターンのどれかでジョブの前後関係を指定できます。
-
set_display_nameと同様にメソッドチェーンのような形での指定 - コンポーネントの出力を渡して暗黙的に前後関係を持たせる
- コンポーネントを先に定義して最後に前後関係を記述
@component()
def print_op(msg: str):
print(msg)
@component()
def produce_msg(name: str) -> str:
return f"hello, {name}"
@dsl.pipeline(name="test")
def pipeline():
msg_task = produce_msg("world")
print_msg_task = print_op(msg_task.output) # パターンその2
print_op("test").after(print_msg_task) # パターンその1
Airflow に慣れていればパターン3の方がしっくり来るかもしれません。
@dsl.pipeline(name="test")
def pipeline():
msg_task = produce_msg("world")
print_msg_task = print_op(msg_task.output) # パターンその2
print_msg_task2 = print_op("test")
# パターンその3
print_msg_task.after(msg_task)
print_msg_task2.after(print_msg_task)
実行結果
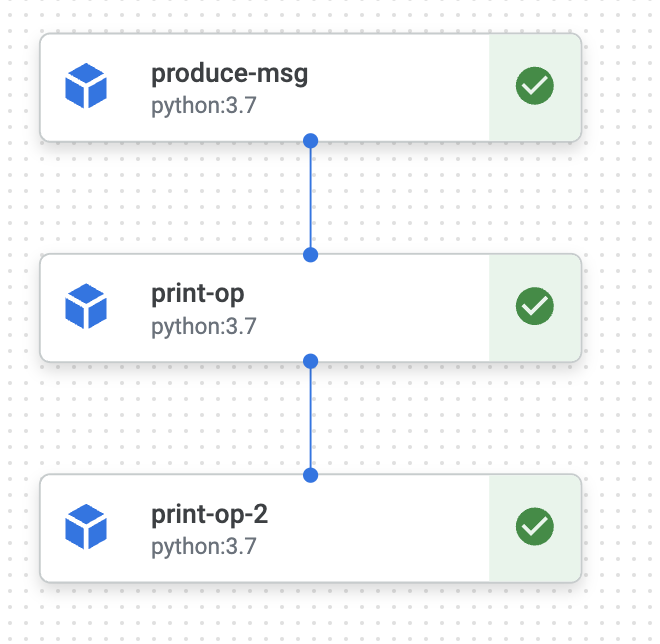
全てのジョブが終了した時に特定のジョブを実行する
kfp.v2.dsl.ExitHandler を使うと、その構文に囲まれたコンポーネントの実行が完了した後に特定のコンポーネントを実行できます。
また kfp.v2.dsl.PipelineTaskFinalStatus を使うとパイプライン終了時のステータスを参照できるため、「パイプラインの実行が失敗した時のみ特定のタスクを実行する」という構成も実現できます。
from kfp.v2.dsl import PipelineTaskFinalStatus
@component()
def exit_op(msg: str, status: PipelineTaskFinalStatus):
print(msg)
print(status.state)
print(status.error_code)
print(status.error_message)
@component()
def throw_error():
raise ValueError("Component error is occurred.")
@dsl.pipeline(name="test")
def pipeline():
exit_task = exit_op("test")
with dsl.ExitHandler(exit_op=exit_task):
throw_error()
ExitHandler で囲まれたジョブが失敗し、exit-op ジョブが実行されていることがわかります。
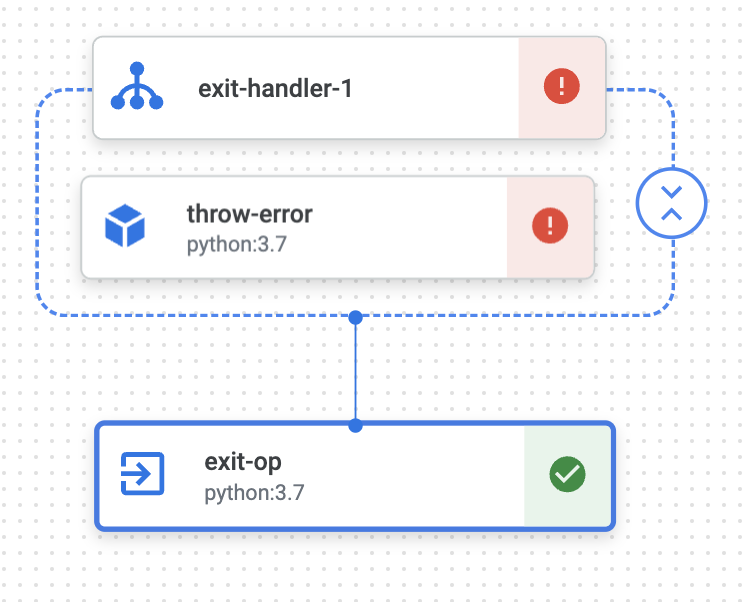
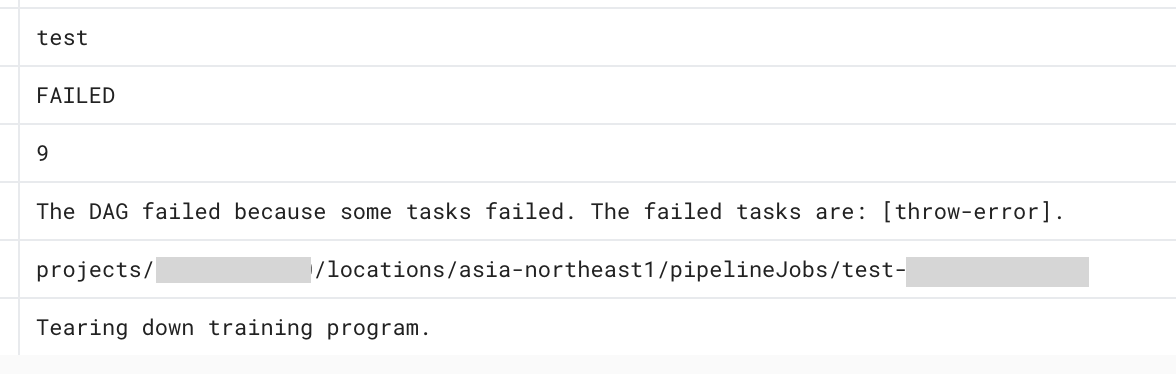
exit-op ジョブの中での出力は以下のようになっています。タスクの成否と実行していたパイプラインのジョブ名を参照できるため、「パイプラインが失敗した場合はパイプラインの URL を添付して Slack 通知する」といった構成をとることができます。
条件分岐
コンポーネントの出力を参照して次に実行するコンポーネントを制御します。やっていることは if 文の働きですが else 文の働きをする構文がないため、 else と等価な動きをさせたい場合は if-not な構文を作る必要があります。
@component()
def produce_op() -> float:
import random
return random.random()
@component()
def show_op(val: float):
print(val)
@component()
def throw_error(val: float):
raise ValueError(f"Value {val} must be greater than 0.5.")
@dsl.pipeline(name="test")
def pipeline():
produce_task = produce_op()
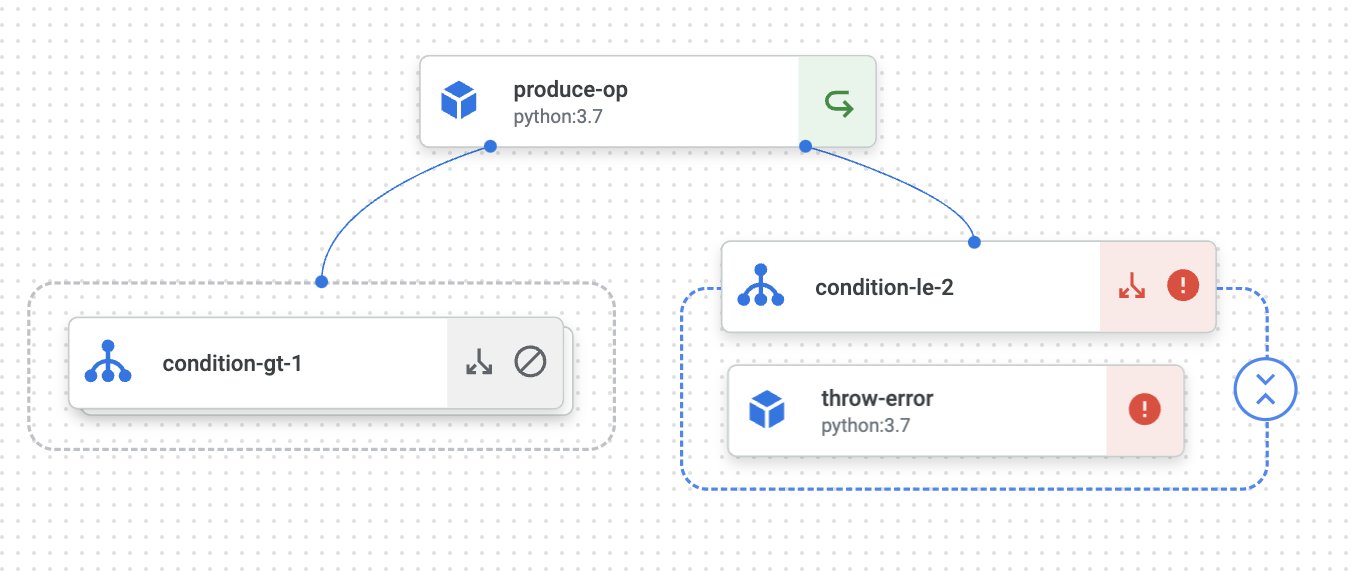
with dsl.Condition(produce_task.output>0.5, name="gt"):
show_op(produce_task.output)
# else ができないので逆になる条件にする
with dsl.Condition(produce_task.output<=0.5, name="le"):
throw_error(produce_task.output)
実行結果
ジョブの並列化
「引数が異なる同じコンポーネントを複数実行したい」という、処理の並列化をする状況を考えます。並列化する方法は二つあります。
-
dsl.ParallelForを使う - for ループを使う
各ジョブは1つの Custom Training Job として実行されるため、どちらの方法で書いても同じ実行結果が得られます。ただし、UI 上での見た目は大きく異なります。
1. dsl.ParallelFor を使う
Kubeflow Pipelines SDK で提供されている実行方法です。 10 個のタスクを並列で実行しています。
@component()
def produce_op(val: int) -> float:
import random
return val * random.random()
@dsl.pipeline(name="test")
def pipeline():
tasks = [i for i in range(10)]
with dsl.ParallelFor(tasks) as v:
produce_op(v)
一つのコンポーネントのようにジョブの実行結果が集約されています。プルダウンから各ジョブの実行結果を参照できます。
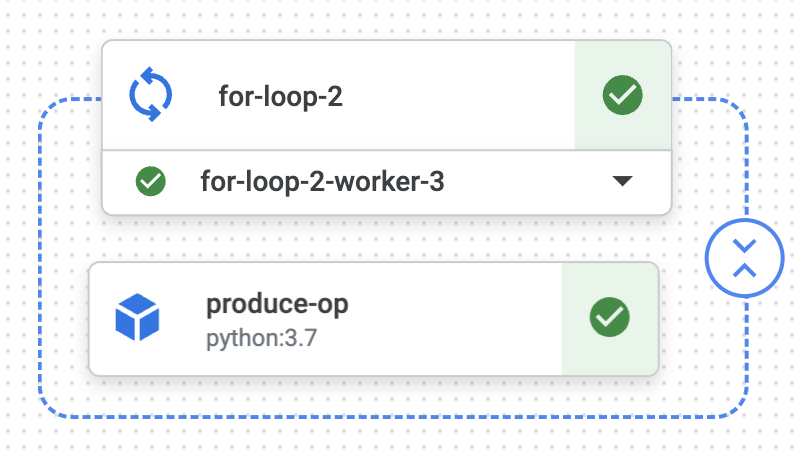
2. for ループを使う
同じジョブを for ループを使って書いてみます。
@component()
def produce_op(val: int) -> float:
import random
return val * random.random()
@component()
def print_op(msg: str):
print(msg)
@dsl.pipeline(name="test")
def pipeline():
tasks = [i for i in range(10)]
for v in tasks:
produce_op(v)
実行結果は以下のようになっています。横に展開されすぎてて全てをスクショすることはできませんでしたが、このように個別のジョブとして表示されるため、「引数だけが異なる同じジョブを何個も実行している」ことはこの実行結果から読み取ることはできません。

並列実行した結果を集約する
いわゆる fan-in です。こちらは if-else と同様に公式な方法は 2022年12月時点では存在していないため、以下が現実的な実現方法と考えています。
- 共通の出力先を指定する
- 並列実行したコンポーネントの出力結果を
pipeline_rootから走査する
上記の方法について、「ParallelFor で適当な DataFrame を生成してそれを集約した DataFrame の shape を表示する」というパイプラインを構成してみます。ちなみにいずれの方法もあまりスマートな方法とは言えないため、この点についてより良い方法をしている人がいれば是非教えていただきたいです。。
1. 共通の出力先を指定する
一番愚直で確実なやり方です。並列実行するコンポーネントの成果物の出力先をコンポーネントの入力として渡してやります。
@component(packages_to_install=["pandas", "numpy"])
def produce_op(size: int, output_gcs_dir: str):
import pandas as pd
import numpy as np
from pathlib import Path
df = pd.DataFrame(np.random.randint(1, 10, size=(size, 3)), columns=["col1", "col2", "col3"])
df.to_csv(Path(output_gcs_dir)/f"result_{size}.csv", index=False)
@component(packages_to_install=["pandas"])
def agg_op(gcs_dir: str):
import pandas as pd
from pathlib import Path
agg = pd.concat(pd.read_csv(p) for p in Path(gcs_dir).glob("*.csv"))
print(agg.shape)
@dsl.pipeline(name="test")
def pipeline():
gcs_dir = f'{pipeline_root.replace("gs://", "/gcs/")}/output_dir'
tasks = [i+1 for i in range(5)]
with dsl.ParallelFor(tasks) as v:
# 適当な DataFrame を生成
produce_task = produce_op(v, gcs_dir)
agg_op(gcs_dir).after(produce_task)
pros/cons
この方法を採用することのメリットは「何をしているかわかりやすい」ことでしょうか。{pipeline_root}/output_dir 配下に実行結果を集約していることがパイプラインの定義から察することができます。
一方でデメリットは、まず「パイプラインの出力とアーチファクトを1対1で紐付けられない」ことが挙げられます。Vertex AI Pipelines で ML パイプラインを構成することのメリットの一つとして、アーチファクト管理の容易さがあります。 ML パイプラインで実行されるコンポーネントの出力結果はパイプラインの実行結果と1対1で参照できることが望ましく、それは Vertex AI Pipelines の機能を使えば容易に実現できます。
この方法はシンプルではあるものの、 Vertex AI Pipelines を使うことのメリットをあまり使えていない方法とも言えそうです。
2. 並列実行したコンポーネントの出力結果を pipeline_root から走査する
Vertex AI Pipelines では、コンポーネント名を prefix として持つディレクトリ配下にアーチファクトが生成されるルールがあります。
例えばコンポーネント名が produce_op であれば、このコンポーネントが生成するアーチファクトは produce-op_{JOB_ID} という名称のディレクトリ配下に出力されます。この性質を利用して、特定の prefix を持つアーチファクトを全て参照する、という方法になります。
from kfp.v2.dsl import Input, Output, Artifact
@component()
def dummy_op(output_gcs_path: Output[Artifact]):
with open(output_gcs_path.path, "w") as f:
f.write("dummy output")
@component(packages_to_install=["pandas", "numpy"])
def produce_op(size: int, output_gcs_path: Output[Artifact]):
import pandas as pd
import numpy as np
from pathlib import Path
df = pd.DataFrame(np.random.randint(1, 10, size=(size, 3)), columns=["col1", "col2", "col3"])
df.to_csv(f"{output_gcs_path.path}.csv", index=False)
@component(packages_to_install=["pandas"])
def agg_op(gcs_dir: Input[Artifact]):
import pandas as pd
from pathlib import Path
# 前段で ParallelFor で実行されたコンポーネントの出力を参照する
files = [list(d.glob("*.csv"))[0] for d in Path(gcs_dir.path).parent.parent.glob("produce-op*")]
agg = pd.concat(pd.read_csv(f) for f in files)
print(agg.shape)
@dsl.pipeline(name="test")
def pipeline():
dummy_task = dummy_op()
tasks = [i+1 for i in range(5)]
with dsl.ParallelFor(tasks) as v:
produce_task = produce_op(v)
agg_op(gcs_dir=dummy_task.outputs["output_gcs_path"]).after(produce_task)
各コンポーネントの実行結果は以下のように、アーチファクトとして pipeline_root 配下に出力されています。agg_op ではこのアーチファクト群の中で特定の prefix を持つアーチファクトを参照して集約しています。
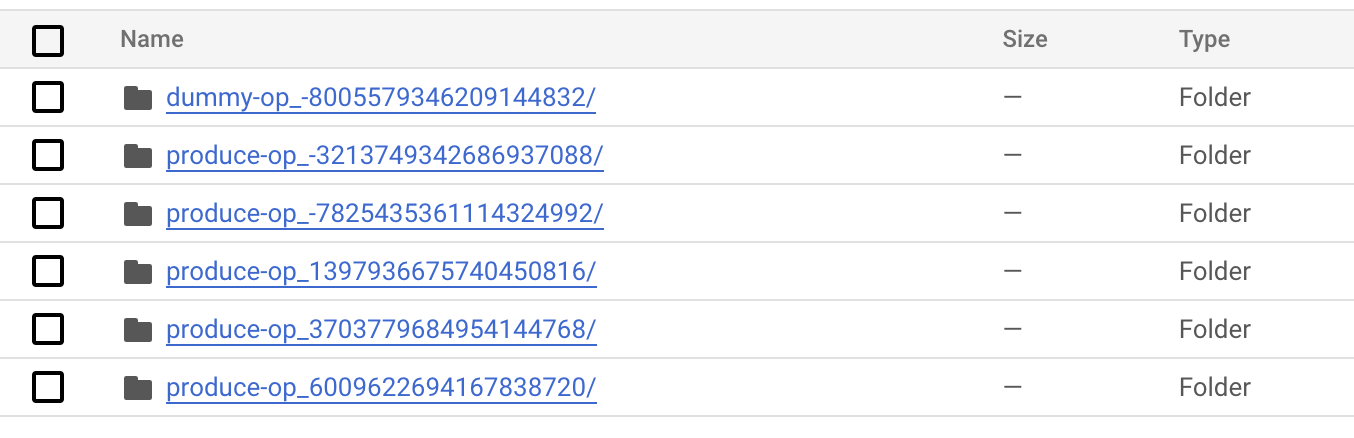
pros/cons
この方法のメリットは、全てのコンポーネントの実行結果をアーチファクトとして残しておける点が挙げられます。あるパイプライン・あるコンポーネントの実行結果を UI 上から容易に追跡できるため、同じようなパイプラインを1日に何度も回すようなケースで有用でしょう。
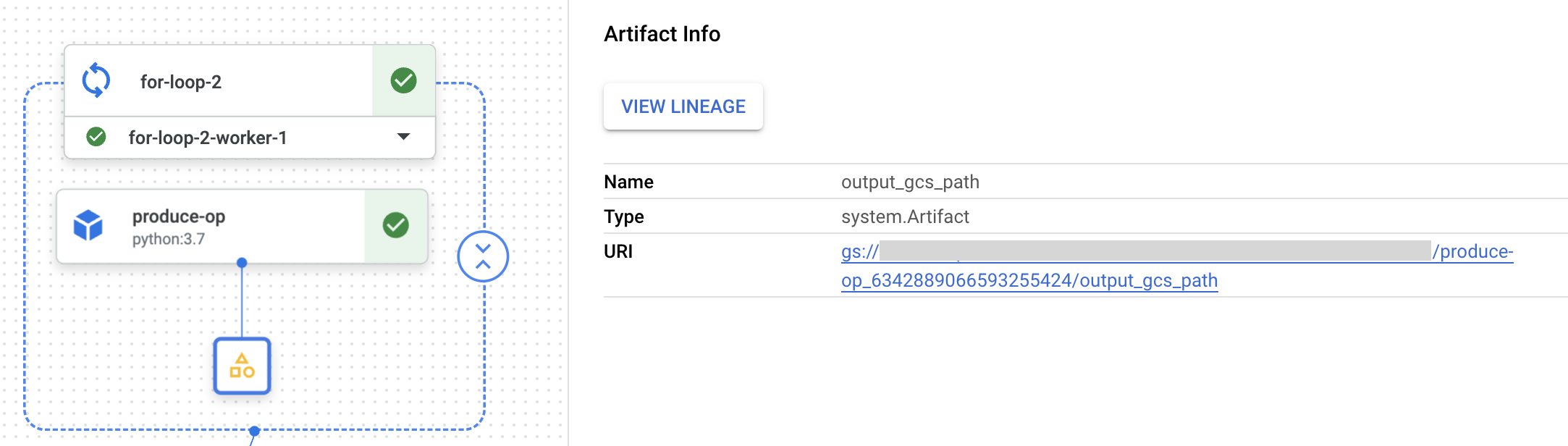
一方、デメリットとして以下が挙げられます。
- 集約を行うコンポーネントでの処理が前段のコンポーネント名に依存する
- 別なコンポーネントから pipeline_root を参照しているため、処理がわかりにくい
一点目はコードを見れば明らかです。produce_opというコンポーネント名であることが前提となっているため、別なコンポーネントに変えた場合は動かなくなってしまいます。
二点目は ParallelFor の出力を直接参照できないことに起因します。例えば以下のようなパイプラインは AssertionError: component_input_artifact: pipelineparam--produce-op-output_gcs_path not found. All inputs: とエラーで実行してしまいます。
@dsl.pipeline(name="test")
def pipeline():
dummy_task = dummy_op()
tasks = [i+1 for i in range(5)]
with dsl.ParallelFor(tasks) as v:
produce_task = produce_op(v)
# ParallelFor で実行されたコンポーネントの出力を参照しようとしている
agg_op(gcs_dir=produce_task.outputs["output_gcs_path"])
これに対応するために、本来参照したいのは produce_task の出力ですがサンプルコードでは dummy_op という適当なジョブを作り、そのジョブの出力を参照させています。
これはコンポーネント内の処理を見れば何を意図したものなのか分かることではありますが、逆に言うとコンポーネント側のコードを見ないと処理の意図がわからなくなってしまうので、使い方には注意が必要です。
まとめ
Kubeflow Pipelines は Vertex AI Pipelines というマネージドサービスとして公開されたことでドキュメントの質が格段に良くなった印象です。しかしまだまだこのサービスを利用している現場の知見が十分に共有される土壌は無いように感じるため、自分が当たり前に使っている実装方法であっても誰かの役に立つと思いたいです。