はじめまして。4月1日に入社した新人エンジニアです。
AIエンジニアになるため、AIの概念からAIエージェントまで勉強した内容を記事としてまとめ、自分の考えを書いてみたいと思い、この記事を作成しました。
初心者AIエンジニアの視点で理解した内容として、温かく見守っていただければ幸いです。
目次
-
導入
-
AIの基礎概念
-
AIとは?
-
生成AIとは?
-
LLMとは?
-
-
非推論LLMと推論LLM
-
LLMとAIエージェント
-
AIオーケストレーションとは?
-
おわりに
導入
最近は非常に多様な生成AI(ChatGPT、Gemini、Copilot、Claude)が市場に出ており、複数のAIを使いながら性能を比較し、実生活に適用するケースが増えました。

非常に便利な 「AIアシスタント」 というわけですね。
このようなAIアシスタントはどのように発展してきたのか、そしてAIエージェントとは何なのか?
私はAIの始まりからAIエージェントに至るまで、どのような流れになっているのかを説明してみたいと思います。
AIの基礎的な部分から一緒に見ていきましょう。
AIの基礎概念
AIとは?

説明する部分の中で、最も巨大な概念と言えるでしょう。
「人間のように考えるコンピュータ」と言われたりもしますが、正確な定義としては、コンピュータが人間のように学習し、予測し、知覚能力を持てるように(模倣して)プログラミングしたものを指します。
初期のAIは、プログラマーが事前に定義したルールに従って、「〇〇が入ってきたら△△を出力しろ」という方式でした。しかし現代のAIは、大量のデータを機械学習(マシンラーニング)やディープラーニングを通じて分類し、判別します。
機械学習とは?(伝統的な)
ユーザーがコンピュータに多くのデータを与え、アルゴリズムを通じて学習させることで、その中からパターンや規則を見つけ出し、予測や分類を行わせる手法です。
- 核心原理(人間の介入): 学習を始める前に、エンジニアや科学者がデータの特徴をヒントとして抽出してあげる必要があります。

例: 犬と猫を区別するモデルであれば、「耳が尖っているか、尻尾の長さ、ひげの形」などを特徴として分類するように設定し、機械はその特徴をもとに学習します。
ディープラーニングとは?
機械学習方法の一つです、人間の脳の神経網構造を模倣した人工ニューラルネットワークを何層にも(Deepに)深く積み重ねて学習する手法です。
- 核心原理(機械自らが判断): 大量のデータを丸ごと入力すると、モデルが自ら「どの特徴を見るべきか」を把握します。
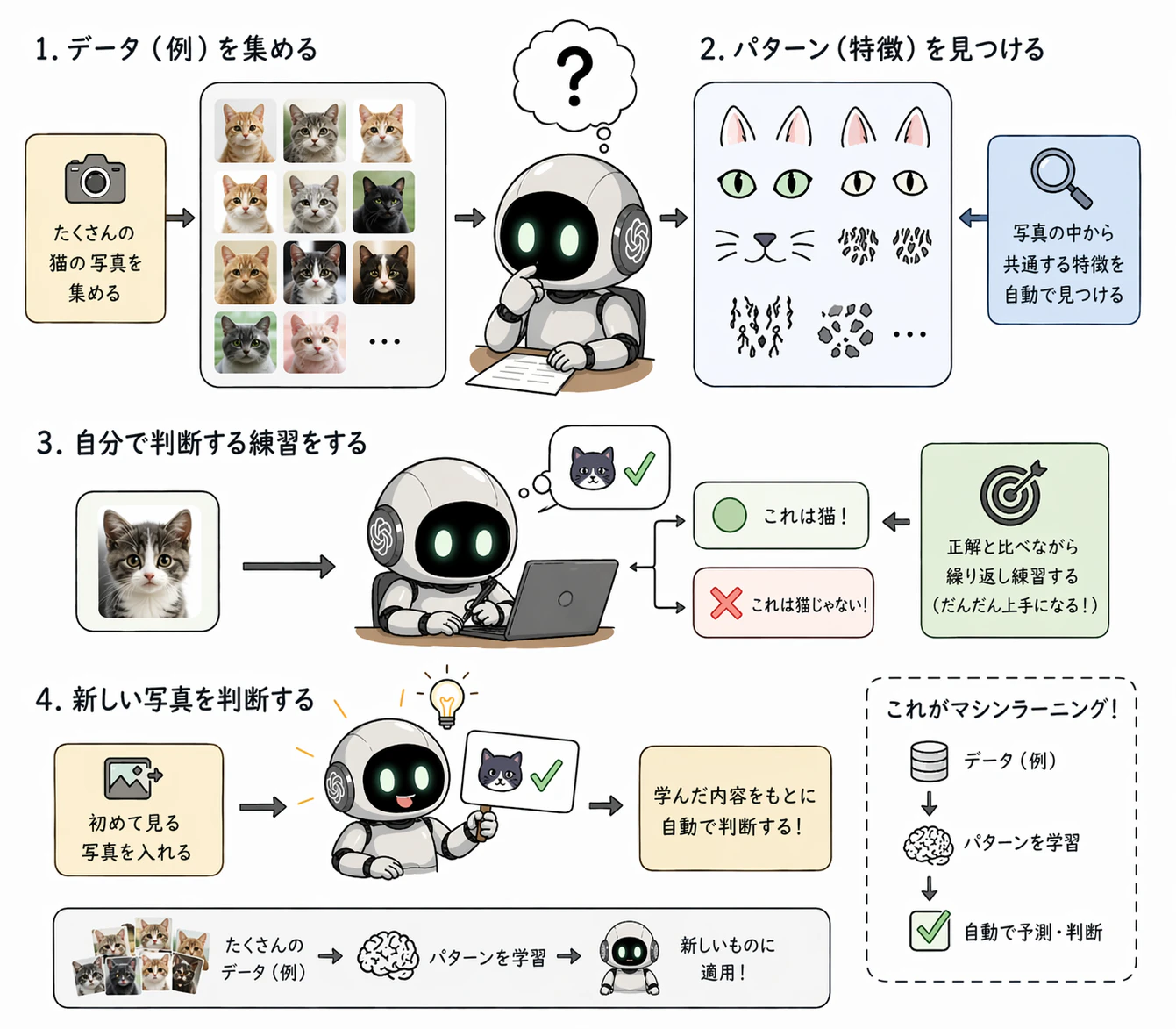
例: 猫と犬の写真を数十万枚そのまま入力すれば、ディープラーニングモデルが無数のピクセルデータを細かく分け、階層を経て分析し、「ああ、猫の耳はこんな形で、尻尾はこのくらいの長さで、ひげはこんな感じなんだな」という規則を自ら見つけ出して分類します。
AWSでは、使用に適した用途として次のように説明しています。
ディープラーニングと機械学習 - AWS
-
機械学習: 定型データ(Excel、DB)など、あらかじめ決められた形式や構造に従ったデータを処理するのに適している。
-
ディープラーニング: 非定型データ(SNS、メール)など、決まった構造を持たずに保存されたデータの処理に適している。
生成AI(Generative AI)とは?
AI、特にディープラーニングの下位分野であり、学習データの固有のパターンや構造を把握し、元のデータと類似しつつも既存には存在しなかった 「新しいデータを出力するモデル」 です。
- 核心原理:
既存のAIが入力データをもとに分類や判別(例:画像が猫か犬かを判断)を行っていたのに対し、
生成AIは「正解を探す」モデルではありません。
入力されたプロンプトとそれまでの文脈をもとに、
次に出るトークンの確率分布を計算し、
その分布からトークンを確率的にサンプリングすることで出力を生成します。
そのため、同じプロンプトを入力した場合でも、
出力結果が毎回わずかに異なることがあります。
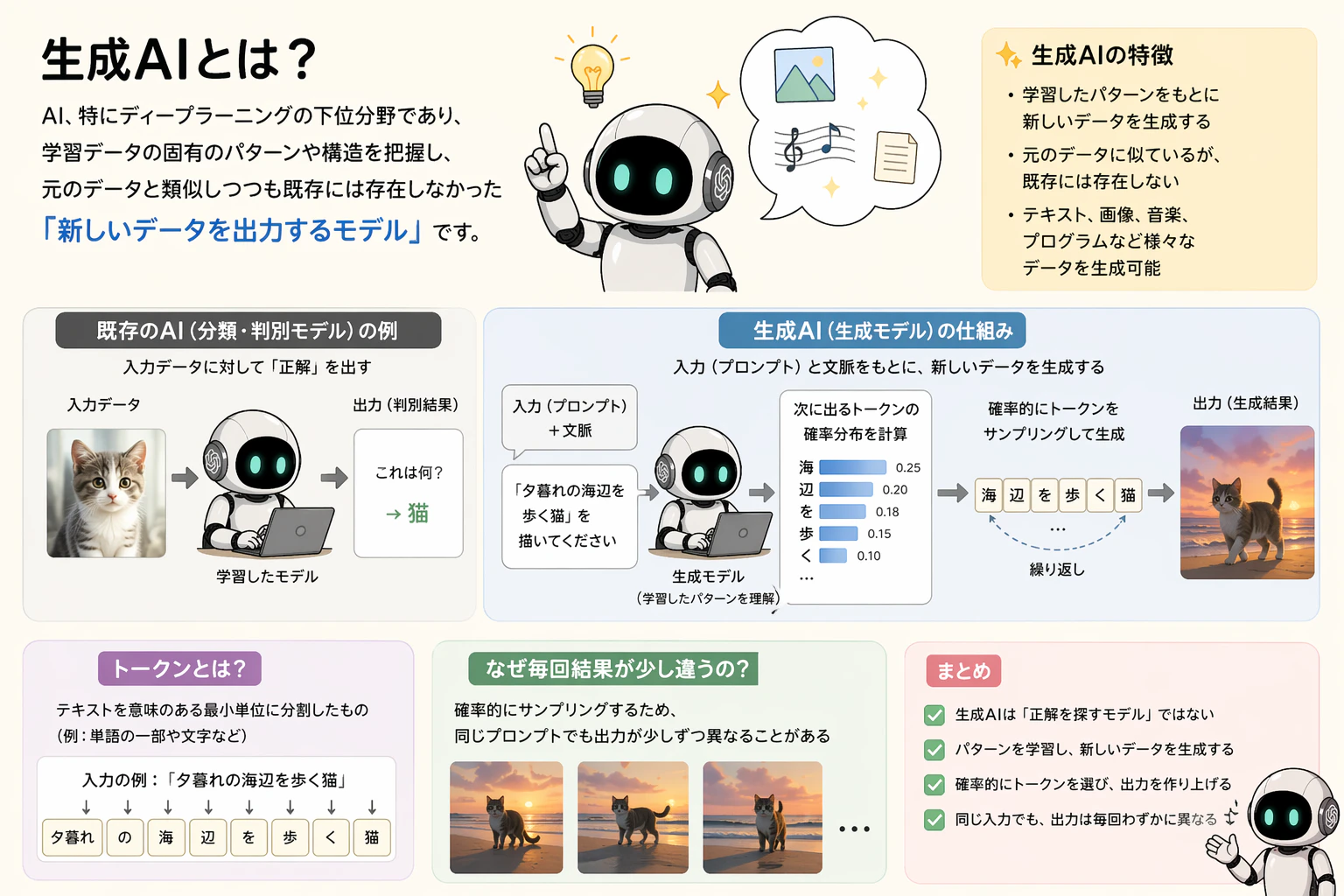
LLM(Large Language Model)とは?
生成AIモデルの中で自然言語の処理と生成に特化しており、数十億から数兆個にも及ぶ膨大な数のパラメータを備えた巨大な人工ニューラルネットワークです。ChatGPTやGeminiのようなチャットボットが、このLLMを脳として使用しています。
ユーザーのプロンプトを理解し、自然言語で入力された命令を各パーツが理解できるように翻訳して伝える役割を果たします。
- 核心原理(2017年以降のGoogleのTransformer基盤): 文章内の単語を互いに関連付け、その後に続く回答を予測することです。
「今日はお腹が空いたので〇〇を食べた」と言えば、〇〇に入る答えをトークン単位で分割し、正解に近い回答を選択するのです。
-
ご飯9%
-
りんご 7%
-
スパゲッティ 5%
-
バス 0.000001%
ハルシネーション(幻覚)現象について
生成AIモデルを使用する中で、ハルシネーション現象を経験した方も多いと思いますが、常に正解に近い答えのみを予測して出力する構造に従っているため、「そもそも正解がない場合でもAIはとりあえず出力してしまう」ことによって生じる現象と言えます。
プロンプトでこの現象を減らしたい場合は、正解がない場合は不確実性を認めることを明示的に許可する、RAG(検索拡張生成)などの外部情報や検証プロセスを組み合わせることが有効とされています。
概念の大きさ
AI > 生成AI > LLM
すべてのLLMは生成AIか?
一般に「LLM」と呼ばれる場合、
多くは自動回帰型でテキスト生成を行う生成中心のモデル(GPT系)を指します。
BERTのようなモデルも大規模な言語モデルではあるが、
主な用途は文章生成ではなく、理解・分類であり、
エンコーダ型言語モデルとして区別されるのが一般的です。
シンプルに考えて、プロンプトを入力した時に以前のデータをもとに新しいものを作り出しているか(生成)、それとも判断しているか(判別)を基準に区分すると理解しやすいです。
現在のAI時代は、このような判別型モデルが培ってきた自然言語理解能力を基盤として、パラメータサイズを大きくした生成型モデルが主導権を握っている形だと言えます。
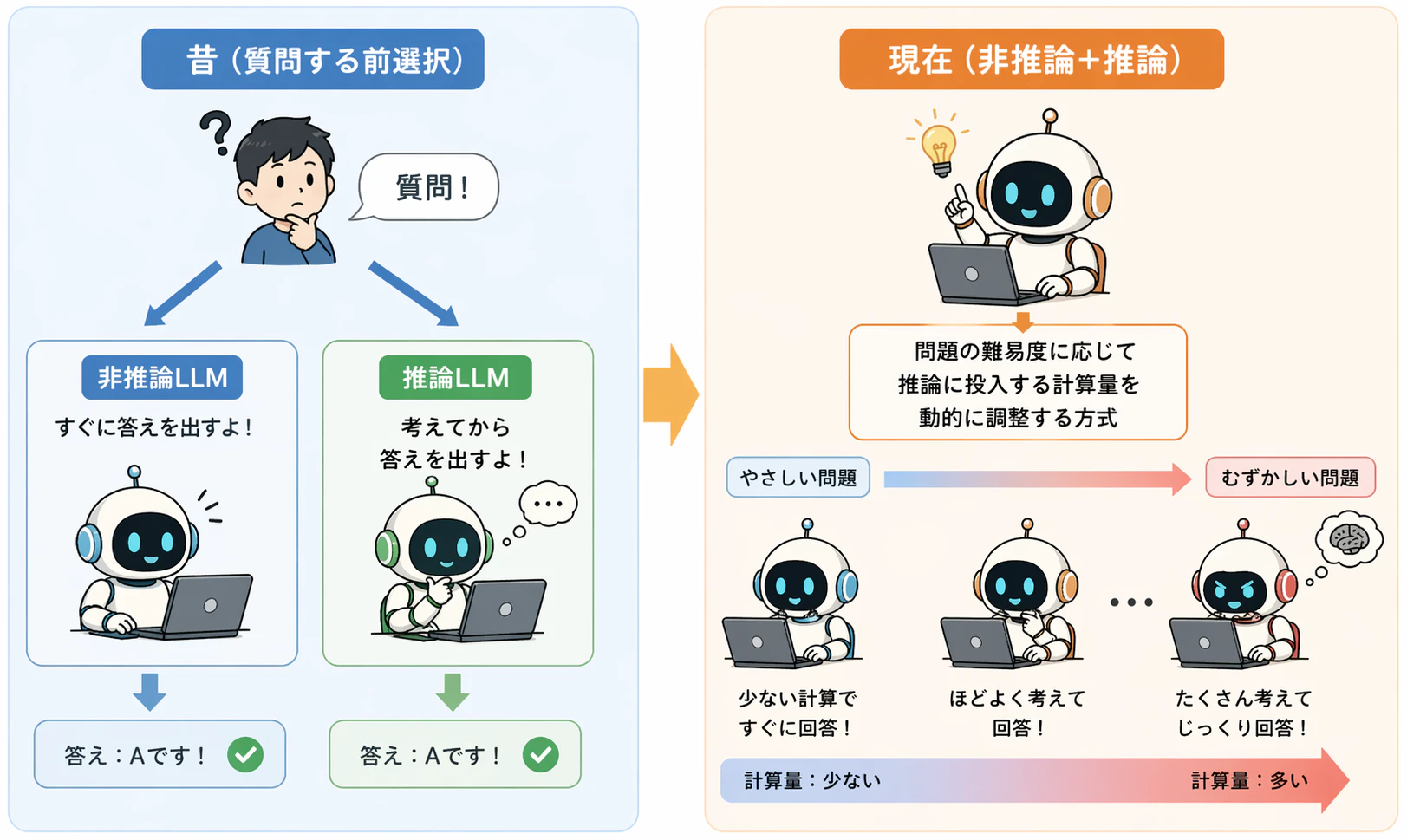
非推論LLMと推論LLM、そして現在
かつては、高速に応答する一般的な生成モデルと、
低速だが高精度な推論特化モデルを分けて考える傾向がありました。
しかし近年の大規模モデルでは、
問題の難易度に応じて推論に投入する計算量
(inference-time compute)を動的に調整する方式が主流となっている。
そのため、推論能力は特定のモデルに固定された特性ではなく、
モデル構造、プロンプト設計、実行ポリシーの組み合わせとして理解されます。
LLMとAIエージェントの違い
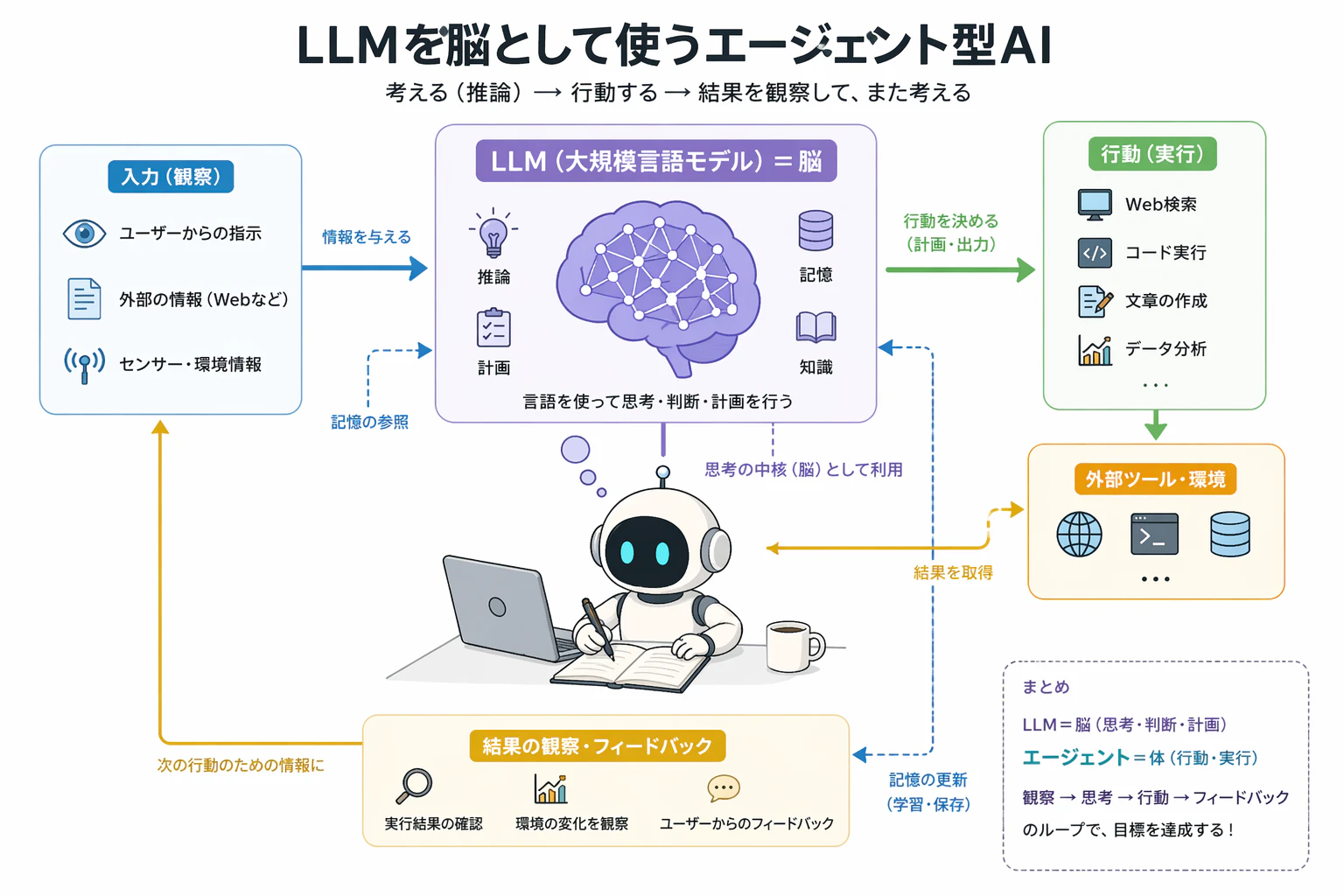
まず、AIエージェントの定義 です
ユーザーの目標を実現するために、動的に処理方法を計画し、実行する機能を備えた、
生成AIを活用したアプリケーション
LLMだけを使用する場合、
外部環境との相互作用や状態管理には限界があります。
AIエージェントは、LLMを推論エンジンとして利用しつつ、
状態保持、反復実行、ツール呼び出しをシステムレベルで管理し、
目標達成までのプロセス全体を制御します。
モデル vs エージェント、何が違うのか?
| 区分 | LLM(一般モデル) | AIエージェント(Reasoning Agent) |
|---|---|---|
| 知識の限界 | 学習データ(過去)に閉じ込められている。 | 外部ツール(検索など)でリアルタイムに知識を拡張。 |
| 推論方式 | 単一推論(Single-turn): 目標達成までループする構造を持たず、一度応答したら終了。 | マルチターン推論(Multi-turn): 目標達成まで無限ループ。 |
| アーキテクチャ | テキスト生成器(基本的なロジックレイヤーなし) | **コグニティブ・アーキテクチャ(Cognitive Architecture)**を保有 |
| ツール使用 | 単体では制限がある | 可能(基本的にツールが搭載され、連携される) |
初めてLLMベースのサービスに触れた(GPT-3など)当時であれば、表の左側の内容に近かったでしょう。しかし、現在のLLMサービス(最新GPTモデル、Claudeモデルなど)を使ってみると、単なる会話型AIを超えて、深く思考して複雑な数学の問題を解いてくれたり、絵を描いたり、天気を調べたり、メール作成やコード実行に至るまで、その領域が大きく拡大しています。
用語では 「ツール拡張型AI(Tool-Augmented LLM)」 とも呼ばれますが、上で説明したエージェントの定義の通り、すでにAIエージェントは私たちの実生活にかなり近づいているのです。
では、エージェントが内部的にどのように動作しているのかを見ていきましょう。
ReAct エージェントとは? | IBM
エージェントを動かす内部メカニズム:ReActフレームワーク
現在の最も進歩したエージェントは、ReAct(Reasoning and Acting) というフレームワークに従って動いています。 ReActとは、思考(Reasoning)と行動(Acting)を交互に繰り返す仕組みであり、推論をもとに行動し、その結果を見てまた推論するサイクルを目標達成まで繰り返します。人間が問題を解決するプロセスをそのまま模倣しています。
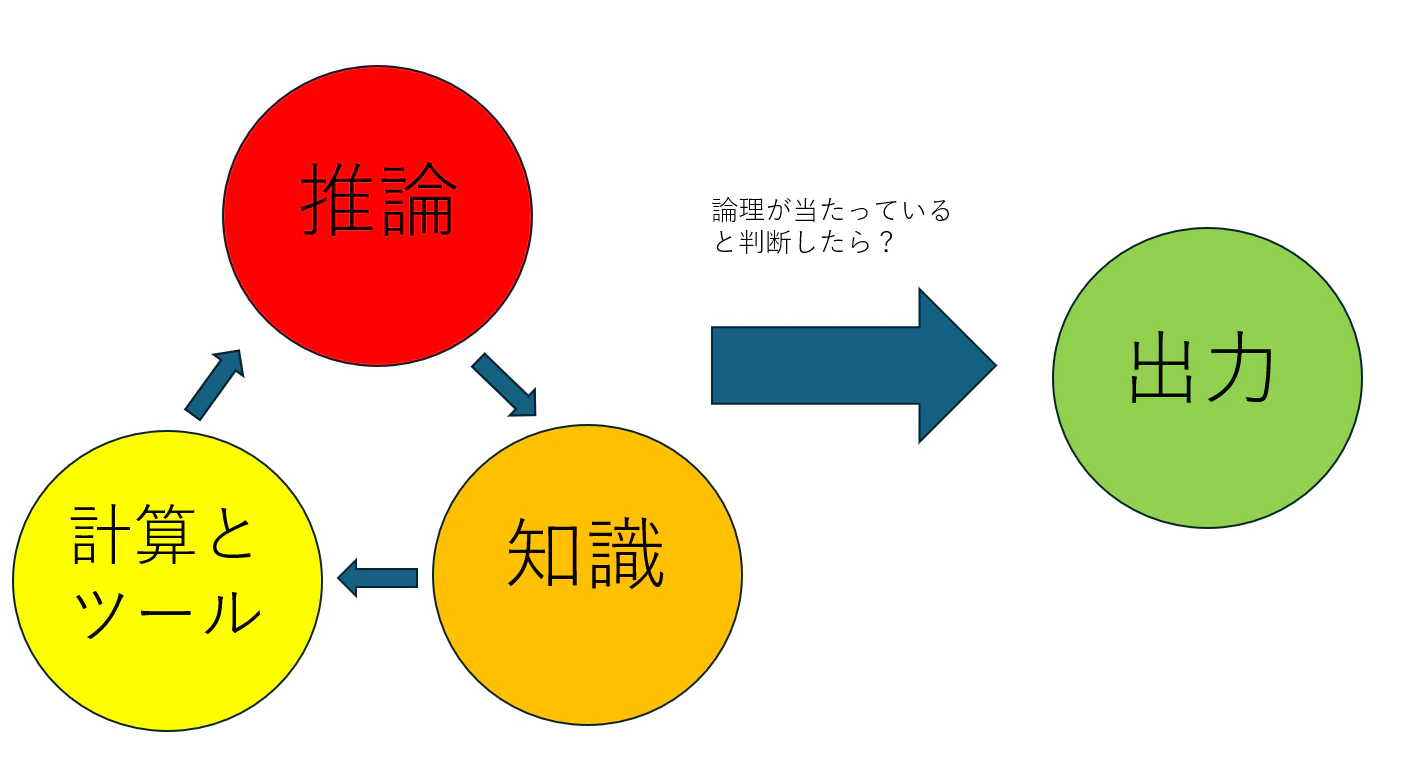
エージェント実行のための3大必須要件
このReActを完璧に動作させるため、システム内部には大きく3つの要件が備わっています。
-
推論(Reasoning): 複雑な質問を解決するための論理的思考能力。(例:段階的に計算するCoTや、巨大なタスクを分割するTask Decompositionなど)
-
知識(Knowledge): 過去の学習データだけでなく、RAG(検索拡張生成)技術を活用して、外部ソース(データベース、ウェブ検索、ドキュメントなど)からリアルタイムで最新情報を取得する能力。
-
計算とツール(Computation & Tool Use): LLM自身は計算やシステム制御ができないため、外部の厳密なツール(天気APIやPythonコードインタープリタなど)を呼び出し、その結果を受け取る能力。
AIエージェントの4つの核心デザインパターン
このようにReActアーキテクチャを持つAIエージェントの性能を極大化し、実際に実装するために、世界的なAI権威であるAndrew Ng(アンドリュー・ン)教授は4つの主要なデザインパターンを提示しました。
What's next for AI agentic workflows ft. Andrew Ng
1. Reflection(反省 / 自己修正)
AIが最初に生成した結果をそのまま出力せず、自分自身や他の検証モデルを通じてレビューし修正するパターンです。
- 例: コードを作成した後、自らエラーになりそうな部分を見つけ出して修正する「セルフコードレビュー」プロセス。このプロセスを通じてハルシネーション(幻覚)現象を画期的に減らすことができます。
2. Tool Use(ツール使用)
単語予測モデルであるLLMに、関数(Function Calling)やAPIを呼び出せる権限を与え、外部の世界とやり取りさせるパターンです。
- 例: 「今日の天気を調べて、雨が降るなら今日の予定をキャンセルして」というプロンプトが入ってきたとき、エージェントは「天気を調べて」という言葉を判断し、天気APIを呼び出して結果を受け取り、「雨なら予定キャンセル」という次の行動まで自律的に実行します。テキストモデルという脳に手足をつなげたわけです。
3. Planning(計画立案)
複雑な要求が入ってきた時にいきなり実行するのではなく、問題を小さく分割し(Task Decomposition)、順次的な実行計画を立てるパターンです。
-
例: 企業分析レポートを作成して =>
1. 財務データの検索=>2. ニュースの要約=>3. 最終的な取りまとめと文書化、の順にサブタスクを分けて処理します。
4. Multi-Agent Collaboration(マルチエージェント協調)
それぞれ異なるペルソナと専門ツールを持つ複数のエージェントがやり取りしながら、一つの巨大な目標を達成するパターンです。
エージェントの中でも、コーディングに特化したエージェント、テスト特化エージェント、資料調査エージェントなどが互いに協調し、一つの開発チームのように協業するのですが、これらを調整するシステムをAIオーケストレーション(AI Orchestration) と呼びます。
AIオーケストレーションとは?(=プロジェクトマネージャー(PM))
AI オーケストレーションとは? | IBM
AIエージェントを複数集めたからといって、望む結果が自動的に得られるわけではありません。誰かが作業の枠組みを作り、交通整理をする必要があります。この枠組みを作り、全体の流れを統制するシステムこそが「AIオーケストレーション」です。
-
タスクの分割と割り当て (Task Routing): ユーザーが複雑な要求をした際、オーケストレーターが目標を細かく分割し、最も適した特技を持つエージェントに仕事を割り振ります。(例:「資料調査は検索エージェント、コーディングは開発エージェント、検証はテストエージェントに任せる」)
-
データパイプラインと状態管理 (State Management): エージェントAが作業した結果を、エージェントBが理解できる形に整えて渡します。また、現在のプロジェクトがどこまで進んでいるか(状態)を中央で記憶し管理します。
-
競合解決および例外処理 (Conflict Resolution): エージェント同士が導き出した結果が衝突したり、途中でエラーが発生した場合、無限ループに陥らないよう仲裁し、再び作業方向を修正します。

おわりに
AIの基礎からエージェントまで勉強したことをまとめて見ましたが,
Andrew Ng教授の「4つのデザインパターン」をはじめとする様々な手法は、エージェントを強力にする有用なフレームワークです。しかし、これらがどのような状況においても「絶対的な正解」になるわけではありません。
例えば、単なる天気の照会に対して綿密なPlanningやMulti-Agentを適用すれば、レスポンスの遅延や無駄なAPIコスト(トークン消費)が発生するだけです。単純なタスクにはTool Useのみを適用するなど、解決すべき課題の複雑さに応じて必要なパターンを取捨選択し、コストとパフォーマンスのトレードオフを最適化することが実際の開発では重要になります。
4月に入社したばかりで、まだ理論をなぞっている段階ですが、今後は実際にAIエージェントを構築しながら、実務的な設計スキルを身につけていきたいと思います。
最後までお読みいただき、ありがとうございました。