今回はローカル言語モデルを直接使ってみます。
なぜGemmaを選んだのか

ローカルで動作するモデルにはQwenなど複数の選択肢がありますが、
今回はGemmaを選択しました。
理由として大きかったのは以下の3点です。
- Gemma 4からApache 2.0ライセンスで公開されたこと
- Google系LLMアーキテクチャを試しやすいこと
- E2B / E4Bといった軽量モデルが提供されていること
特にE2B / E4Bモデルは、スマートフォンや低スペック環境でも動作しやすいよう最適化されており、ローカルAIを試す上で扱いやすい印象があります。
![[要求パラメータ.png]]
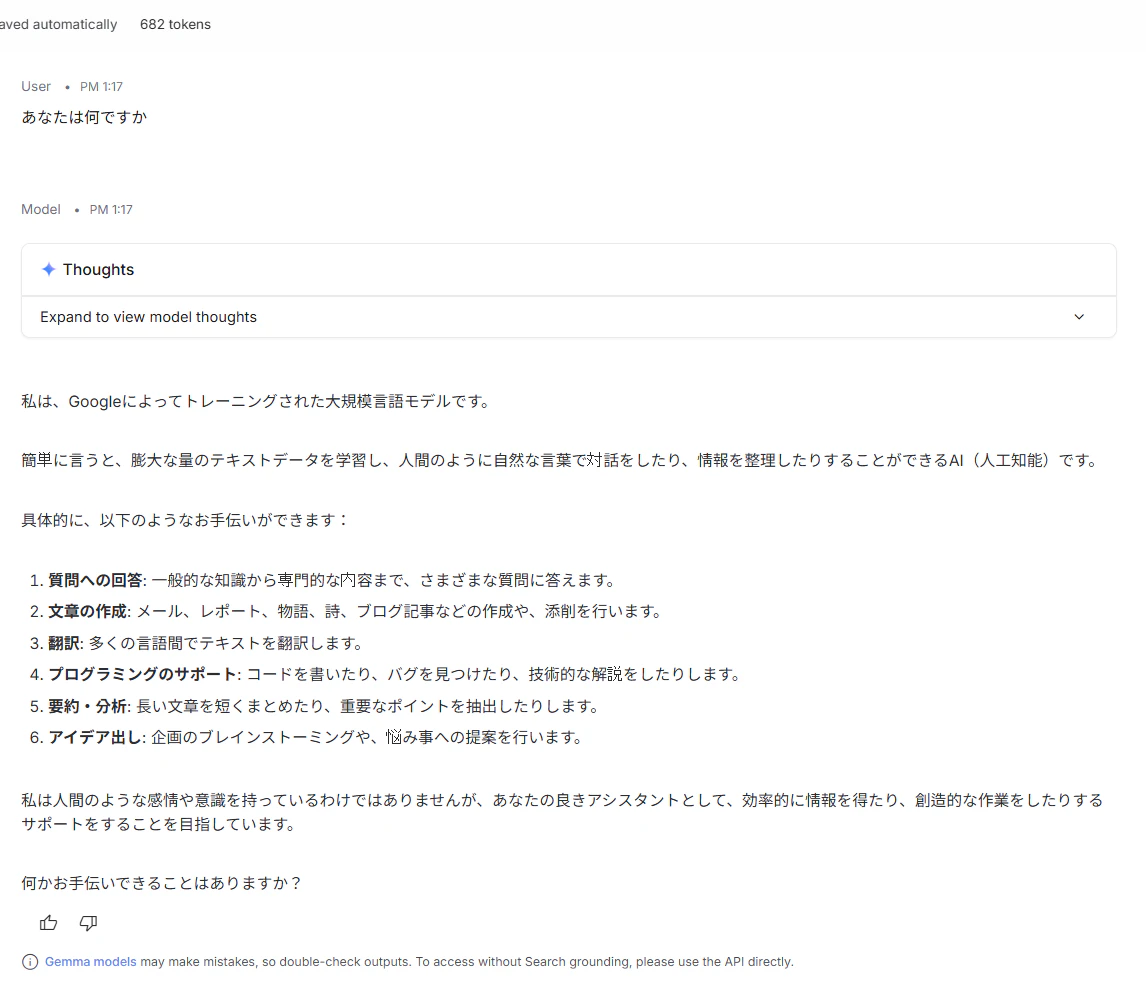
Gemma 4 モデルの概要 | Google AI for Developers

Gemma 4 31Bモデルは、テキスト系ベンチマークにおいてQwen 3.5-397b-a17bと同水準の結果を示しており、
Gemini 2.5 Proに匹敵、あるいは一部項目では上回る結果も見られ、ローカル動作モデルとしては非常に高い性能を示しました。
実際に使ってみよう
とはいえ、ベンチマークだけでは実際の使用感は分からないため、
実際に試してみることにします。
ここでは、インストール不要でテストする方法と、
多くの方が試しやすいスマートフォンや低スペック向けのモデル(E2B・E4B)を実際に動かしてみる様子をご紹介します。
インストールなし
試したモデル:Gemma 4-31b
まず、インストールやハイスペックなPCなしですぐに体験してみたい方は、Google AI StudioでGemma 4 26B A4BモデルおよびGemma 4 31Bモデルをすぐに試すことができます。
Google検索機能も組み込まれているため、質疑応答やコーディングテストをさせてみるのも良いでしょう。
では、続いて自分のデバイスで動かしてみましょう。
駆動環境(モバイル)
- Snapdragon gen2 12GB RAM
- Google AI Edge Gallery(APP)
試したモデル:Gemma 4-e2b
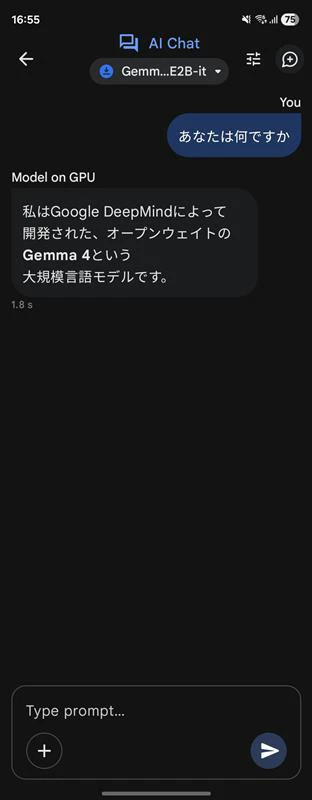
モバイルで直接試してみたい方は、Google AI Edge Gallery(Android/iOS)からダウンロードしてすぐに実行できます。
応答速度は非常に速く(応答終了まで約1.8秒)、モバイル環境向けに最適化されたLiteモデルです。
モデル情報
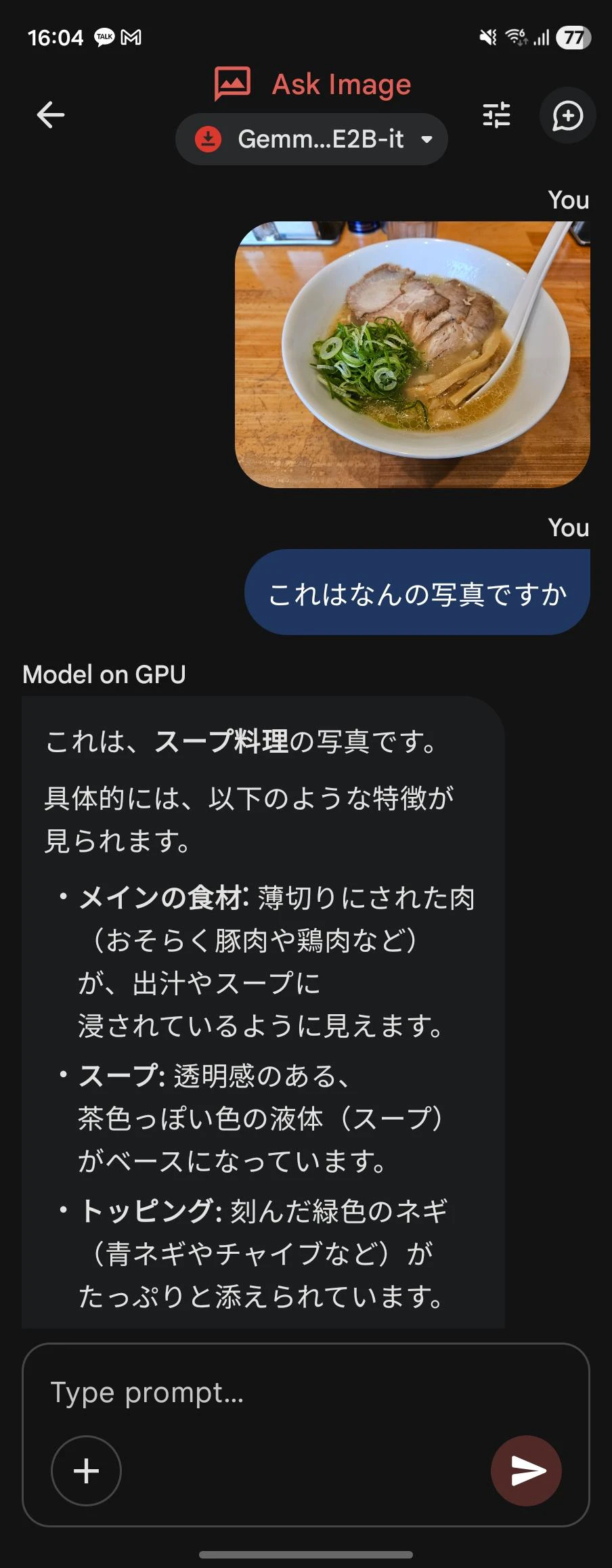

gemma4はマルチモーダルAIで画像認識や音声認識なども可能です。
※音声機能はE2B、E4Bのみ
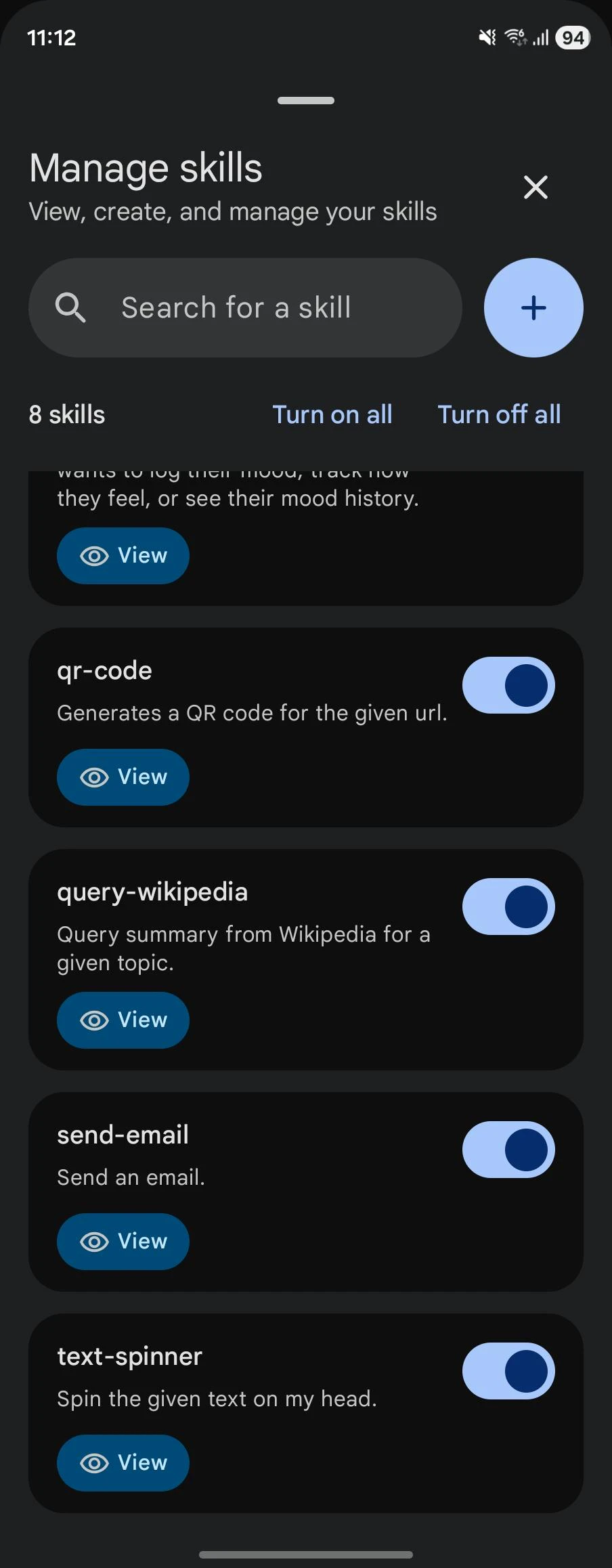
Google AI Studioにはデフォルトで準備されたエージェント機能も搭載されているため、すぐに試すことができます。
駆動環境(パソコン)
- AMD AI 5 Pro / Radeon 840M / 32GB RAM
- LM Studio
- Thinkingモード(システムプロンプトに<|think|>入力)
- Temperature 0.8
試したモデル:Gemma 4-e2b


1秒あたり20トークン前後で出力されました。
試したモデル:Gemma 4-e4b

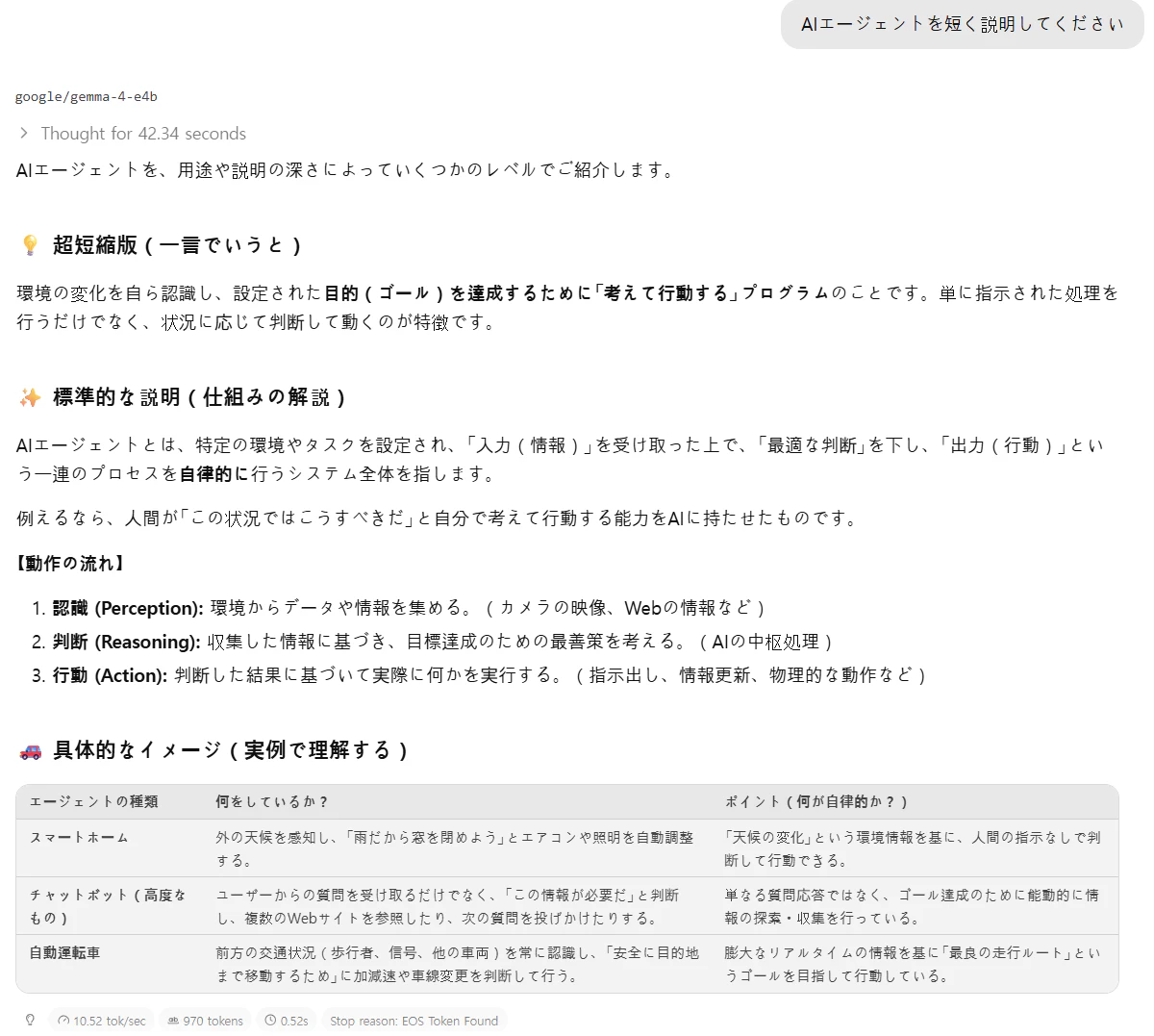
1秒あたり10トークン前後で出力されました。
2つの軽量化モデルに同じ質問をした際の回答の違いです。
e2bモデルの場合は非常に速いですがシンプルな回答となりました。
e4bモデルは遅いですがより詳細な返答を出力してくれました。
Qwenモデルとの比較(Qwen 3.5 4B)

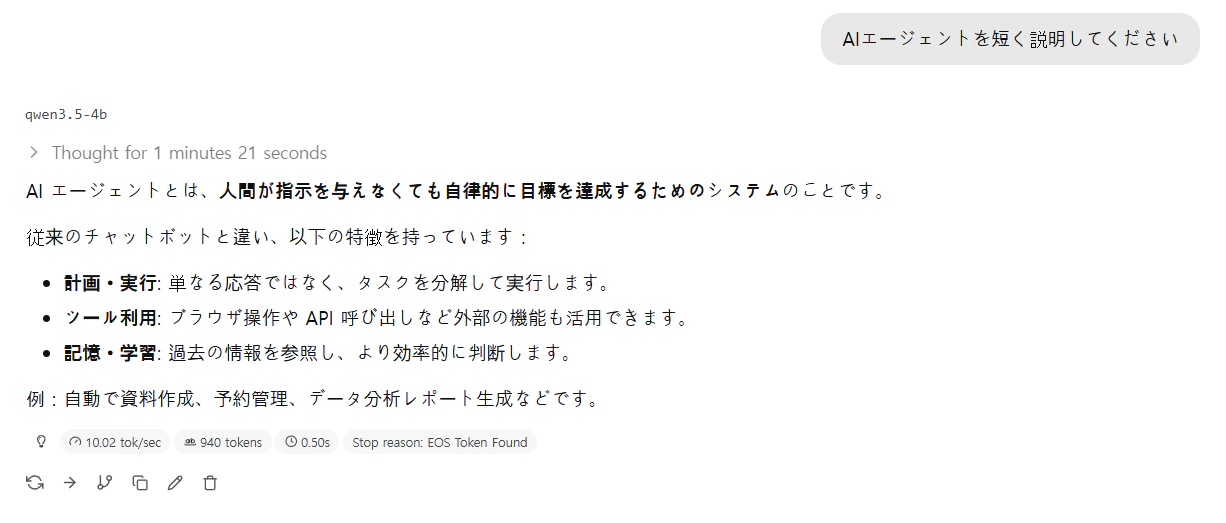
Qwen 3.5 4Bモデルとも比較してみました。
同じ質問を行った場合、Qwen 3.5 4Bの方が「短く説明する」という意図を汲み取った出力をする印象がありました。
生成速度はGemma 4 E4Bと同様に、1秒あたり10トークン前後を示しました。
どちらも「4B」と付いているため、この結果自体はそこまで不思議ではありません。
しかし、ここで面白いのがVRAM使用量です。
Gemma 4 E2BとQwen 3.5 4Bの実際のVRAM使用量は、どちらも5GB前後と近い値でした。(E4Bの場合は約7.5GB前後)
一般的に、生成速度はVRAM使用量そのものではなく、実際に演算へ使用されるパラメータ量の影響を受けます。
Gemma 4 E系モデルの「E」は Effective(有効) を意味します。
デバイス上にはe2bの場合5B全体を保持しますが、推論時に毎回すべてのパラメータを計算しているわけではありません。
基本的なDense構造にPLE(Per-Layer Embeddings)という技術が適用されており、パラメータの半分以上(約2.8B)は参照テーブルとして利用されます。
そのため、実際の演算規模は約2.3B相当に抑えられています。
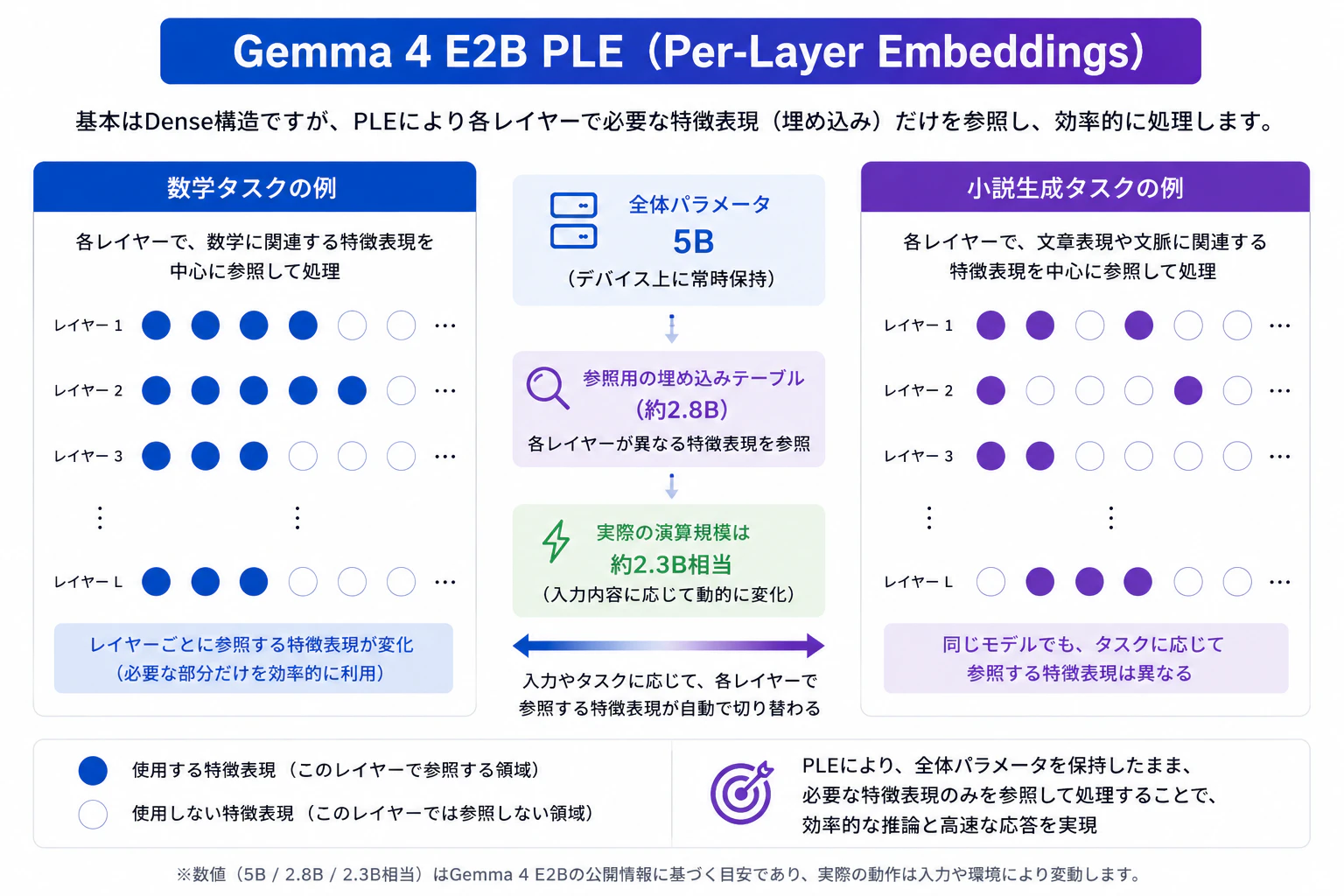
入力された情報は各レイヤーで異なる特徴表現を参照しながら、段階的に推論結果を洗練していきます。
このような構造により、Gemma E系は比較的大きなモデル規模を維持しながらも、実際の演算量を抑えることで、軽量環境でも高速に動作しやすいよう最適化されています。
今回試した軽量モデル同士で比較すると、Gemma E系は応答速度や即応性が高く、Qwen 3.5 4Bは長文推論や複雑なタスクで安定した出力をする印象がありました。
結局モデル全体の優劣というよりも、用途に応じて使い分けることが重要だと思います。
エージェントとしての役割を試す
次に、E4Bモデルに検索エンジンをツールとして組み合わせ、エージェントとしての役割を少し試してみました。
DuckDuckGoを使用してe4bモデルに外部検索機能を入れてみた場合(約2分)
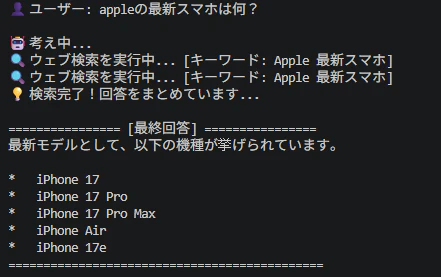
Gemma 4の場合、2025年1月までの情報を学習しているため、当然知らないはずのiPhone 17について調べてきた様子です。
もし私がコンピュータ内部の検索機能を追加したなら、AIに対して
「会社の今年の売上や顧客情報を整理してください」と頼むこともできるでしょう。
外部のAIにこんな情報を読ませるわけにはいきませんからね。
しかし、内部システムで読ませるとしても、インストールしたライブラリ自体が本当に安全なのかは未知数です。また、自社の今年の売上を整理してPDFなどで保存されること自体が問題になる可能性もあるので、そこは留意すべき点だと思います。
次回の記事では、エージェントを設計する上で重要だと感じた点について取り上げていきます。