AWSのAmazon Redshiftを読み書きするPythonプログラムのテストを自動化してみた
そのときの工夫の記録
使用した環境
- Amazon Redshift
- Python3.7
- pytest>=5.3.2
- pandas>=1.0.0
- psycopg2>=2.8.4
データベースとしてRedshiftを使用しているが、他のデータベースプロダクトでも同じ方式で工夫できると思われる
実現したかったこと
プログラムがデータベース(Redshift)に書き込んだ結果データを検証したかった
つまりDAOを使用せずデータベースに接続した状態で、Java/JunitのDBUnitのようなことをしたかった
自動テスト方式
自動テストの流れ
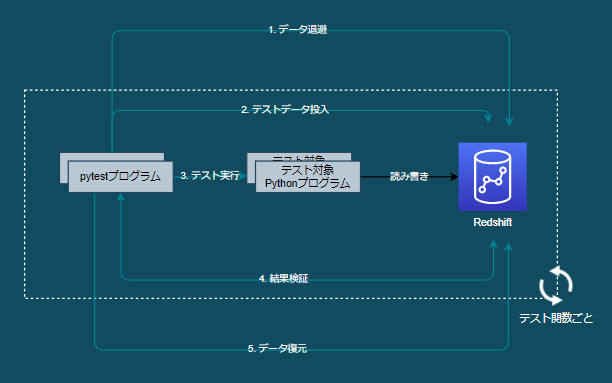
以下のフェーズがある
- データ退避
- テストデータ投入
- テスト実行
- 結果検証
- データ復元
これを実現するために今回は主にpytestのfixture関数を作成した
フェーズ詳解
1. データ退避/5. データ復元
Redshiftを読み書きするテスト対象プログラム(Python)をpytest実行する前に、Redshiftに保存されているデータが壊れさないよう全データをS3に退避する
pytest実行が一通り完了したら全データを復元し、Redshiftをpytest実行前の状態にする
実装例
import pytest
# 'session'を指定することで一連のpytest実行前後で処理できるようにする
@pytest.fixture(scope='session')
def fixture_session():
# Redshiftから全データをS3にUNLOADする処理
yield
# 全データをS3からRedshiftにCOPYする処理
pytestを途中でキャンセルしてもyield以降は処理されるため、安全にデータは復元される
すでにRedshiftに大量のデータが存在する場合、退避と復元に時間がかかりpytest実行がスムーズでなくなる
Spectrumのケース
- S3にある実体のデータオブジェクトをそのままのプリフィクス/パーティション構造で別のS3パスへ移動し退避する
- SpectrumテーブルのS3パスは"SVV_EXTERNAL_TABLES"テーブルの"location"カラムから取得する
- S3オブジェクトを移動する際に、S3オブジェクトのACL権限がデフォルト設定になってしまうので注意
2. テストデータ投入/3. テスト実行
テスト関数(テスト対象プログラム)を実行するたび実行前にRedshiftの全データを削除し、Redshiftに残ったテストデータをクリーンする
テスト関数の実行前に、使用するテストデータをRedshiftを投入する
実装例
import pytest
# 'function'を指定することでテスト関数実行前に処理できるようにする
@pytest.fixture(scope='function')
def fixture_function():
# Redshiftから全データを削除する処理
@pytest.fixture
def load_redshift_1_1():
# csvフォーマットのテストデータをRedshiftにCOPYする処理
# テスト関数実行前にテストデータが投入される
def test_1_1(load_redshift_1_1):
# テスト対象プログラムを実行する処理
Spectrumのケース
- テストデータをそのままのプリフィクス/パーティション構造でS3の該当locationパスにアップロードする
4. 結果検証
テスト対象プログラムの実行結果を検証する
テスト対象プログラムがRedshiftを参照(SELECT)する場合は、Redshiftに入っているデータを検証する必要はない
テスト対象プログラムがRedshiftを変更(INSERT, UPDATE, DELETE)した場合は、Redshiftの結果(現実)データとあらかじめ用意した予想データを比較検証する
Redshiftの結果データを検証する実装例
import pandas as pd
def test_1_1(load_redshift_1_1):
# テスト対象プログラムを実行する処理
# ex_df = csvフォーマットの予想データをpandas DataFrameで取得する処理
# ac_df = 現実データをRedshiftからpandas DataFrameで取得する処理
# 2つのDataFrameを比較検証する
assert pd.testing.assert_frame_equal(
# 主キー(id)をindexにする
ex_df.set_index('id'),
ac_df.set_index('id'),
# index, columnの順序を気にしない
check_like=True
) is None
Spectrumのケース
- Spectrumのテーブルを変更することはできないので、S3にあるデータオブジェクトを検証することはない
課題
- (再掲)すでにRedshiftに大量のデータが存在する場合、退避と復元に時間がかかりpytest実行がスムーズでなくなる
- 1つのデータベースを使用するためpytestの同時実行ができず、同時実行制御が必要になる
自動テスト方式別案
見送った自動テスト方式の別案
データベースコピー方式
イメージ
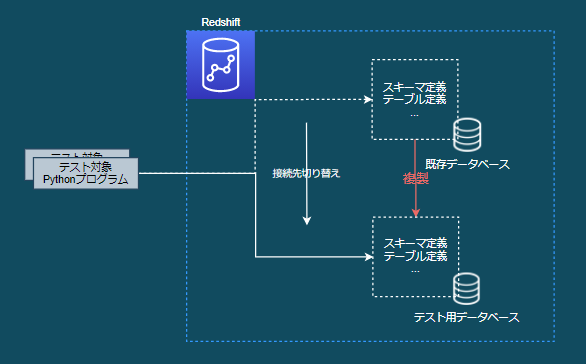
- 既存のデータベースを使わずに、そのデータベース内の定義を複製したデータベースを使用する
- テスト対象プログラムはpytest実行時に複製したデータベースに接続して処理する
- 既存のデータが壊れないように退避/復元する必要がない
- pytestの同時実行が可能
- 以下のコストが高そうであったため見送り
- データベースをデータベース内の定義ごと複製する方法
テスト用新規データベース作成方式
イメージ
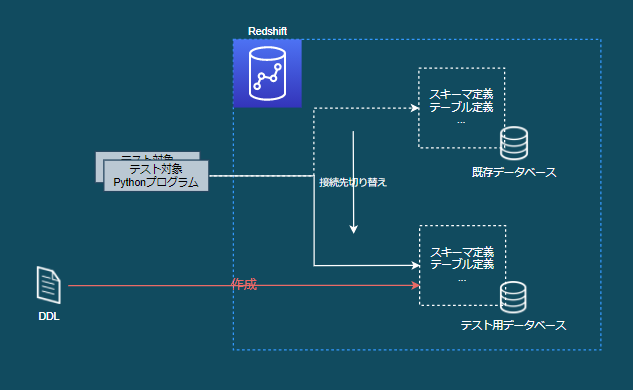
- 既存のデータベースを使わずに、既存のデータベースと同じ定義の新規データベースを作成する
- テスト対象プログラムはpytest実行時に新規作成したデータベースに接続して処理する
- DDLは管理されているGitリポジトリ等から取得する
- 既存のデータが壊れないように退避/復元する必要がない
- pytestの同時実行が可能
- 以下のコストが高そうであったため見送り
- 管理されたDDLを取得して新規データベースを作成する方法