この記事を読まれるpython初心者の方への注意事項(2019/10/03追記)
この記事はプログラミングの環境構築経験が少なめの方へ向けて書いた記事です。そのため、複数の候補があるpython環境について特に説明することはせず、差し当たってAnacondaを使う方法について説明しました。
しかし、この記事を投稿してから約3年経過し、python+tensorflowを取り巻く環境も変わってきました。この記事を書いた当初はAnacondaを使うのが一番手っ取り早いかと考えていましたが、ほかの環境の選択肢としてWSLやWindows版Docker、公式のWindows版Pythonが使いやすくなったこともあり、現状ではAnacondaを使うのが最適とは言いづらい状況かと思うようになりました。Anacondaについては誤解も多く1、ウェブ上に正しい情報が少ないこともあり、トラブルに対処しにくい気がします。
ですので、TensorFlowを試そうと思って最初にこの記事にたどり着いた方はほかの環境構築の選択肢についても十分検討したうえで、選んでいただければと思います。特に初心者の方は、上司や先輩など周りの人にできる限りpython環境についてのアドバイスをもらうのがベターだと思います。
そのうえでAnacondaを選択された場合はこの記事が役に立てるかと思いますが、インストール対象のバージョンも執筆時点から大きく変わっていることはご留意ください。(Pythonや機械学習ライブラリは更新頻度が高いのでできる限り最新の情報を探すのが無難です。)
目的
Googleの学習フレームワークTensorFlowのWindows版がリリースされたということで、手元の環境にインストールしてみました。
Anacondaを使わないWindowsへのTensorFlowインストール方法は下記の投稿をご参照ください。
検証環境
OS : Windows 10 Home (64bit)
Python 3.5
Anaconda 4.2.0
TensorFlow 0.12.0
Anacondaインストール
Anacondaの説明は参考ページに任せて、ここではインストール方法だけ簡単に記載します。
ダウンロードページからWindows版のインストーラをダウンロードして実行します。基本的にはインストーラの指示に従えば問題ないです。
インストールできれば、プログラムの一覧にAnaconda Navigatorがあるはずなので、それを起動します。
仮想環境作成
2018/02/17追記
TensorFlow用の仮想環境が不要な場合はこの章の作業は不要です。
Anacondaの機能で仮想環境を作ることができます。pyenvとかvirtualenvをご存じであれば同じようなものと考えてください。ライブラリとかPythonのバージョンを個別に管理して環境を切り替えられるようになります。
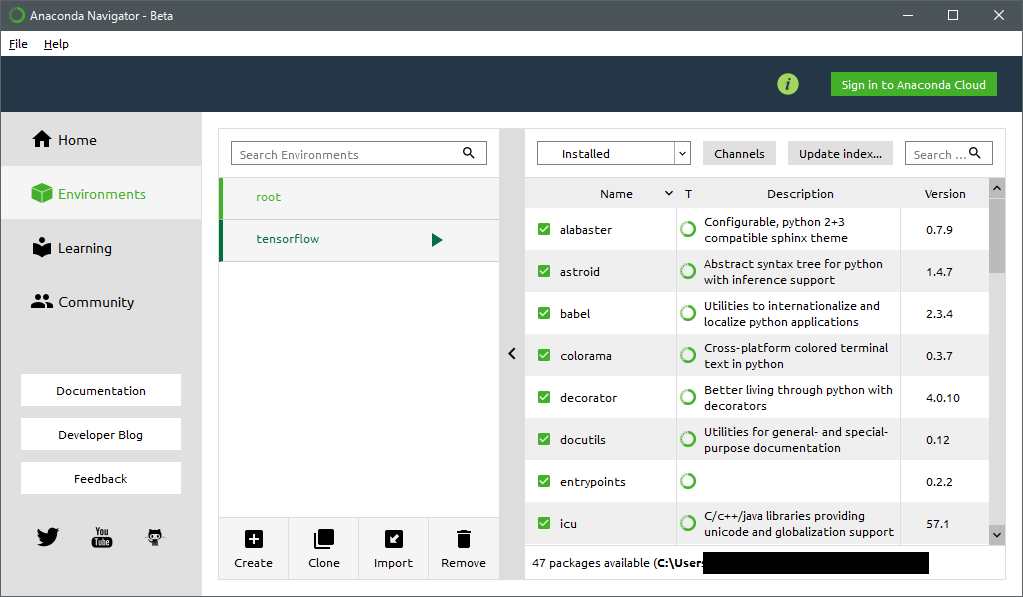
左のメニューのEnvironmentsを選択すると、仮想環境一覧が表示されますが、デフォルトではrootという仮想環境のみが表示されています。
下側のCreateをクリックすると仮想環境作成のポッポアップが表示されるので、わかりやすい名前を入れて作成してください。ここではtensorflowという名前にしました。
rootの下に新しく作った環境tensorflowが表示されるので、それを選択すると右側にその環境で使えるライブラリやツールが表示されます。Anacondaのパッケージとして提供されるライブラリなどはここでインストールすることも可能です。
TensorFlowインストール
ここからはCUIの操作が必要なので、Anaconda Navigatorからコマンドプロンプトを起動します。
Anaconda Navigator上で、rootもしくは、先ほど作った仮想環境tensorflowの横に三角のボタンが表示されているので、それをクリックして、メニューからOpen Terminalを選択します。
コマンドプロンプトが起動したら次のコマンドでtensorflowをインストールします。"Successfully installed..."と表示されたら成功です。
pip install tensorflow
コマンドプロンプトで次のコマンドを実行して"0.12.0"のように、バージョンが表示されたらOKです。
python -c "import tensorflow as tf; print(tf.__version__)"
イントロダクション確認
動作確認として、公式のTensorFlowのイントロダクションを実行します。
リンク先のソースコードをそのままコピーしたファイル(ここではtensorflow_intro.pyという名前にします)を作って、
2017/06/24追記
リンク先の内容が変更されていて、ソースコードがなくなっていましたので、本記事にも載せておきます。
import tensorflow as tf
import numpy as np
# Create 100 phony x, y data points in NumPy, y = x * 0.1 + 0.3
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
# Try to find values for W and b that compute y_data = W * x_data + b
# (We know that W should be 0.1 and b 0.3, but TensorFlow will
# figure that out for us.)
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# Before starting, initialize the variables. We will 'run' this first.
init = tf.global_variables_initializer()
# Launch the graph.
sess = tf.Session()
sess.run(init)
# Fit the line.
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
# Learns best fit is W: [0.1], b: [0.3]
こちらでは日本語に翻訳されたコメントが見れます。
次のコマンドで実行してください。
python tensorflow_intro.py
出力は次のようになります。
0 [ 0.23083703] [ 0.3141903]
20 [ 0.1220311] [ 0.28817284]
40 [ 0.10507432] [ 0.2972759]
60 [ 0.10116876] [ 0.29937258]
80 [ 0.10026918] [ 0.2998555]
100 [ 0.100062] [ 0.29996672]
120 [ 0.10001428] [ 0.29999235]
140 [ 0.1000033] [ 0.29999822]
160 [ 0.10000077] [ 0.29999959]
180 [ 0.10000017] [ 0.29999992]
200 [ 0.1000001] [ 0.29999995]
左から、学習回数、Wの推定値、bの推定値が表示されています。学習を繰り返すことで、Wとbの値がそれぞれ真の値である0.1, 0.3に近づいていくことが確認できます。
まとめ
今回はインストールと簡単な動作確認までを記事にしてみました。
機会があれば、実際にディープラーニングで何かを学習させてみようかと思ってます。