Fast Online Object Tracking and Segmentation: A Unifying Approach
- Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, Philip H.S. Torr
- CVPR 2019
-
https://arxiv.org/abs/1812.05050
- 本記事で読んでいるのはv2
- コード

ひとことまとめ
-
どんなもの?
- visual object tracking(=VOT.動画の最初のフレームと追跡するべき物体の位置を与えられて,それ以降のすべてのフレームで対象の位置を推定するタスク)をリアルタイムで行うfully-convolutional Siamese network手法の提案
-
先行研究と比べてどこがすごい?
- VOTだけでなく,semi-supervised video object segmentation(=VOS.物体に属する領域をピクセルレベルで示す二値マスクを出力する)も同時に解ける
- VOSは基本的にリアルタイム処理にならない物が多いが,本手法はリアルタイムであり,従来手法より4倍以上高速
-
技術や手法のキモはどこ?
- SiamFCおよびSiamRPNという先行研究のモデルに,二値マスクを担当する出力ブランチを付加して拡張(box位置,スコア,マスクの3つの出力を持つ)
- 出力した二値マスクから,VOTの予測であるbounding boxを作成する.回転したboxを作成可能であり,その他の方法でboxを出すよりも精度が上がる
-
どうやって有効だと検証した?
- VOT(VOT-2016, VOT-2018)でのIOU, AP,EAO(Expected Average Overlap)の他手法との比較
- VOS(DAVIS-2016, DAVIS-2017)でのJaccard index, F-measureの他手法との比較
- アブレーションスタディ
-
議論はある?
- なし
-
次に読むべき論文は?
- [44]:
- モデル内で高解像度と低解像度の特徴のマージに使用しているrefinement moduleを提案
- SiamFC[3], SiamRPN[28]:
- 本モデルのベースとなった手法
- Region Proposal Network[46, 28]
- 本モデルのベースとなった手法
- [54]:
- 回転したbounding boxを二値マスクから作成する最適化手法.実験で使用されている.計算コストが高い
- [44]:
abst
- visual object trackingとsemi-supervised video object segmentationをリアルタイムに行う手法を提案する
- SiamMaskと呼ぶ本手法はobject trackingでポピュラーなfully-convolutional Siameseの誤差をbinary segmentation taskで改善したもの
- 訓練後は,一つのbounding boxで初期化するだけで,クラスにとらわれずにobject segmentation maskと回転したbounding boxを55fpsでオンラインに生成する
- VOT-2018のreal-time trackerでsotaを記録
5. 結論
- SiamMaskには2つの変種があり,bounding boxで初期化するとテストsequenceに対してadaptationの必要なく,オンラインにリアルタイム処理できる
1. イントロ
- visual object trackingの目的はビデオの最初のフレーム内で任意の対象の位置を与えられて,その対象の位置を残りすべてのフレームで出来るだけ良い精度で予測すること[48]
- 応用においてはビデオがストリーミングなので,オンラインにトラッキングできることが重要
- したがってtrackereは現在の物体位置の予測に将来のフレームの情報を使ってはならない
- ベンチマークでは対象物体はシンプルなbox[56, 52]や回転したbox[26, 27]で表現されている
- ラベリングコストを下げるとともに,ターゲットの初期化がしやすい
- 応用においてはビデオがストリーミングなので,オンラインにトラッキングできることが重要
- semi-supervised video object segmentaiton(VOS)はobject tracking同様に位置を予測するが,物体がboxではなく二値セグメンテーションマスクで表現される
- これはその位置のピクセルがターゲットに属するかどうかを示す[40]
- boxよりも計算コストが高いため,伝統的にVOS手法はフレームごとに数枚程度の速度で遅い.([55, 50, 39, 1])
- 近年は高速な手法[59, 36, 57, 8, 7, 22, 21]に注目が集まっているが,それでもリアルタイム処理はできない
- SiamMaskは任意のobject trackingとVOSのどちらにも使えるmulti-task learningでそれらの境界を狭める
- fully-convolutional Siamese network[3]をYouTuve-VOS[58]のようなピクセルごとのアノテーションがある大規模ビデオデータで訓練
- Siamese networkを次の3つのタスクで同時訓練
- sliding windowのやり方で,ターゲットと複数の候補との類似度を測ること学習する
- 出力は物体位置だけを示した密なresponse map
- Region Proposal Network[46, 28]を使ったbouding box回帰
- クラスに無関係な二値セグメンテーション[43]
- 二値ラベルはoffline訓練のときだけ必要.online でsegmentaion/trackingするときは不要
- sliding windowのやり方で,ターゲットと複数の候補との類似度を測ること学習する
- これらのタスクは共有CNNから出力する3つの分岐で計算し,最後のlossで加算する
- 訓練できたら,推定の最初に与えられる一つのbounding boxによる初期化だけで,回転したbounding boxとsegmentation maskを55fpsでonlineに出力できる
- シンプルで高速だが,VOT-2018でsota達成
- DAVIS-2016, 2017で最高速度を達成しながら近年のsemi-supervised VOS手法と同等の結果
- シンプルなbouding boxによる初期化を採用したことと,VOSでよく使われるfine-tuningやaugmentation, optical flowを利用していないことが寄与している
2. 関連研究
Visual object tracking
- ビデオの最初で与えられる正解情報から,識別器を排他的にオンライン訓練する方法が最近になるまでの主流だった
- ここ数年はBolmeら[4]によりCorrelation Filterという高速な手法が導入され注目された
- これは任意物体のテンプレートとそれに2D変換を施したものとを識別できるシンプルなアルゴリズム
- 近年はビデオフレームのペア間の類似度関数をオフラインで学習する手法が導入された[3, 19, 49]
- テスト時には,学習された関数をフレームごとにシンプルに適用する
- 特にfully-convolutional Siamese 手法[3]がtracking 性能を押し上げた
- この手法はregion proposals[28], hard negative mining[63], ensembling[15], memory networks[60]を利用している
- 近年の手法はすべて,ターゲットの初期化とそれ以降の推定で矩形のbounding boxを使う
- 物体を表現するのに失敗することがよくあるため,二値セグメンテーションを扱う動機となっている
- Yeoら[61]が初期化にbox,それ以降にはマスクを扱っていて本手法と類似だが,4fpsであり,その高速版でも本手法よりずっと遅い
- Perazziら[39], Ciら[10]も類似だが,テスト時にfine-tuningを必要とするため低速.
- 物体を表現するのに失敗することがよくあるため,二値セグメンテーションを扱う動機となっている
Semi-supervised video object segmentatinon
- object trackingのベンチマーク([48, 26, 56]など)はtrackerが入力フレームをsequentialに受け取ることを想定している
- このことをonlineまたはcausal[26]と呼ぶ
- ビデオのフレームレートを超えるスピードを出すことが重要視される
- [55, 41, 40, 36, 1]
- ビデオフレーム間の一貫性を利用するため,最初のフレームの教師セグメンテーションマスクを時間的に隣接するフレームに,graph labelingで伝播する
- Baoら[1]はspatio-temporal MRFを使った高精度な手法
- [35, 39, 53]
- ビデオフレームを独立に処理する方法
- 事前訓練されたfully-conv netをfine-tuningするなど
- ビデオフレームを独立に処理する方法
- VOSのテスト時には精度を重視するため,計算コストが高い物が多い
- fine-tuning, data augmentation, optical flowなど
- 当然fpsは下がる
- Yang ら[59],Wug ら[57]
- VOS用の高速手法で,sotaと同等の性能
- 前者はmeta-networkのモジュレータでテスト時にsegmentaion networkのパラメタを高速に適応させる
- 後者はencoder-decoder Siamese構造を多段訓練しており,fine-tuneは使用しない
- いずれも10fps以下であり,本手法は彼らの6倍高速で,boxによる初期化のみ使用する
3. 提案手法
- オンラインでの操作性とスピードのためにfully-convolutional Siamese framework [3]を使う
- SiamFC [3] と SiamRPN [28]を例として使い,特定のfully-convolutional手法に依存しないことを示す
3.1. Fully-convolutional Siamese networks
SiamFC
- exemplar(テンプレート)画像$z$をそれより大きい探索画像$x$と比較し,密なresponse mapを得る
- $z$は対象物体を中心に$w \times h$でcropされ,$x$は最後に推定された対象の位置を中心にそれより大きいcropを適用されている
- 2つの入力は同じCNN$f_{\theta}$で処理され,相互に相関のある2つのfeature mapを出力する
- $g_{\theta}(z, x) = f_{\theta}(z) \star f_{\theta}(x) \tag{1}$
- response mapの各空間要素(1式での左辺)をresponse of a candidate window(RoW)と呼ぶ
- $g_{\theta}^n(z, x)$はexamplar zとx内のn番目の候補ウィンドウとの類似度をencodeしている
- SiamFCのゴールは,response mapの最大値が探索領域$x$中のターゲット位置と対応するようにすること
- RoWがよりターゲット物体に関する豊かな情報をencodeできるように,式1のcross-correlationをdepth-wise cross-correlation[2]に拡張し,multi-channel response mapを出力する
- SiamFCはlogistic loss[3]$L_{sim}$を使って数百万のビデオフレームでオフラインに訓練される
- response mapの各空間要素(1式での左辺)をresponse of a candidate window(RoW)と呼ぶ
SiamRPN
- Li ら[28]はregion proposal network(RPN)[46, 14]を用いてSiamFCを大きく改善した
- RPNは可変アスペクト比のboxでターゲット位置を推定する
- SiamRPNでは各RoWがk個のアンカーbox 候補とそれに対応するobject/background スコアをエンコードする
- 2つの出力ブランチはsmooth $L_1$誤差($L_{box}$)とcross-entropy誤差($L_{score}$)で訓練[28]
3.2. SiamMask
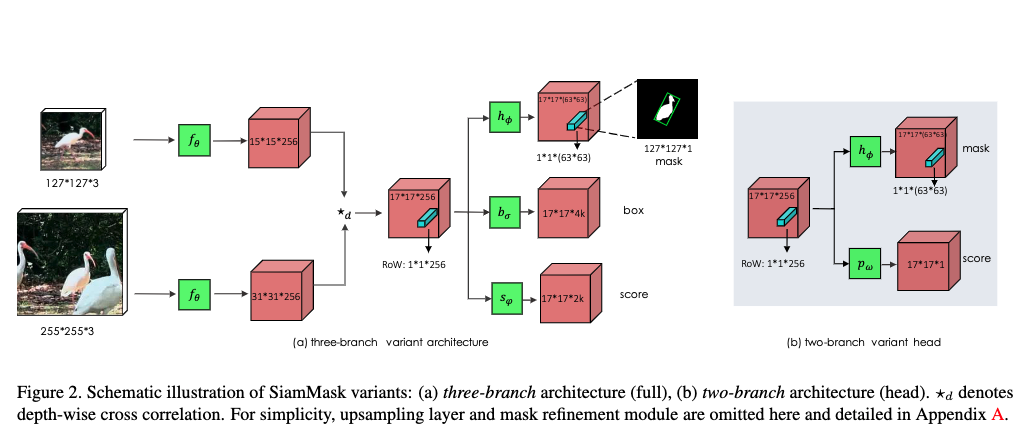
- 従来手法と異なりフレームごとに二値セグメンテーションマスクを出力することの重要性について述べる
- fully-convolutional Siamese networkのRoWは,類似度とbounding box座標に加えて,ピクセルワイズ二値マスクを生成するのに必要な情報もエンコードできる
- 既存のネットワークに拡張ブランチと誤差を導入すればよい
- 各RoWについて,シンプルな2レイヤニューラルネット$h_{\phi}$を使って$w \times h$の二値マスクを予測する
- $\phi$は学習可能パラメータ
- $m_n$がn番目のRoWに対応する予測されたマスクであるとする
- $m_n = h_{\phi}(g_{\theta}^n(z, x)) \tag{2}$
- 2式からマスク予測はセグメントするべきxとターゲットz両方の関数であり,zはセグメンテーション処理をガイドする参照として使用できる
- つまり,別の画像が与えられれば,ネットワークは異なるセグメンテーションマスクを出力できる
- 2式からマスク予測はセグメントするべきxとターゲットz両方の関数であり,zはセグメンテーション処理をガイドする参照として使用できる
- 各RoWについて,シンプルな2レイヤニューラルネット$h_{\phi}$を使って$w \times h$の二値マスクを予測する
- 既存のネットワークに拡張ブランチと誤差を導入すればよい
- fully-convolutional Siamese networkのRoWは,類似度とbounding box座標に加えて,ピクセルワイズ二値マスクを生成するのに必要な情報もエンコードできる
Loss function
- 訓練中,各RoWは正解二値ラベル$y_n \in {\pm 1}$でラベル付けされており,サイズ$w \times h$のピクセルワイズ正解マスク$c_n$と関連づいている
- $c_{n}^{ij} \in {\pm 1}$がn番目のRoWの物体マスクのピクセル$(i, j)$に対応するラベルだとする
- マスク予測に対する誤差関数$L_{mask}$はすべてのRoWに対する二値ロジスティック回帰
- $L_{mask}(\theta, \phi) = \sum_{n}(\frac{1+y_n}{2wh} \sum_{ij} log(1 + e^{-c_{n}^{ij}m_{n}^{ij}})) \tag{3}$
- $h_{\phi}$の分類レイヤは$w \times h$の分類器からなり(出力がwh個ある),それぞれが与えられたピクセルが候補windowの物体に属しているかどうかを示す
- $L_mask$はRoWの正例($y_n = 1$)にしか考慮されない(負例は$y_n = -1$なので(3)式の括弧内がゼロになる)
- $L_{mask}(\theta, \phi) = \sum_{n}(\frac{1+y_n}{2wh} \sum_{ij} log(1 + e^{-c_{n}^{ij}m_{n}^{ij}})) \tag{3}$
- マスク予測に対する誤差関数$L_{mask}$はすべてのRoWに対する二値ロジスティック回帰
- $c_{n}^{ij} \in {\pm 1}$がn番目のRoWの物体マスクのピクセル$(i, j)$に対応するラベルだとする
Mask表現
- FCN[32]やMask R-CNN[17]とは対照的に本手法は[43, 44]同様flattenされたobject表現からマスクを生成する
- この表現は$f_{\theta}$と$f_{\phi}$のdepth-wise cross-correlationで生成された(17x17)のRoWの一つに対応する
- セグメンテーションタスクのネットワーク$h_{\phi}$は2つの1x1畳み込みレイヤで構成され,そのうち1つは256, もうひとつは$63^2$のチャネル数を持つ
- 更に正確なマスクを生成するため,[44]に従い低解像度と高解像度の特徴を複数のrefinement moduleでマージする
- モジュールはupsamplingとskip connectionで構成される(付録A)
2つの変種
- SiamFC[3]とSiamRPN[28]をセグメンテーションブランチと$L_{mask}$誤差で拡張し,SiamMaskの2ブランチおよび3ブランチの変種を得た
- それぞれ$L_{2B}$誤差と$L_{3B}$誤差を最適化する
- $L_{2B} = \lambda_{1} \cdot L_{mask} + \lambda_2 \cdot L_{sim} \tag{4}$
- $L_{3B} = \lambda_{1} \cdot L_{mask} + \lambda_2 \cdot L_{score} + \lambda_3 \cdot L_{box} \tag{5}$
- $L_{sim}$については[3, section 2.2],$L_{box}$, $L_{score}$については[28, section 3.2]を参照
- $L_{3B}$では,RoWが正例($y_n = 1$)であるためには,アンカーボックスの一つで正解boxとのIOUが0.6以上であること.それ以外は負例($y_n = -1$)となる
- $L_{2B}$では正例と負例の定義は[3]に従った
- ハイパーパラメータ$\lambda$は探索せず,[43]同様$\lambda_1 = 32$,$\lambda_2 = \lambda_3 = 1$
- boxとスコア用のブランチの出力は2つの1x1畳み込みレイヤで構成される
- それぞれ$L_{2B}$誤差と$L_{3B}$誤差を最適化する
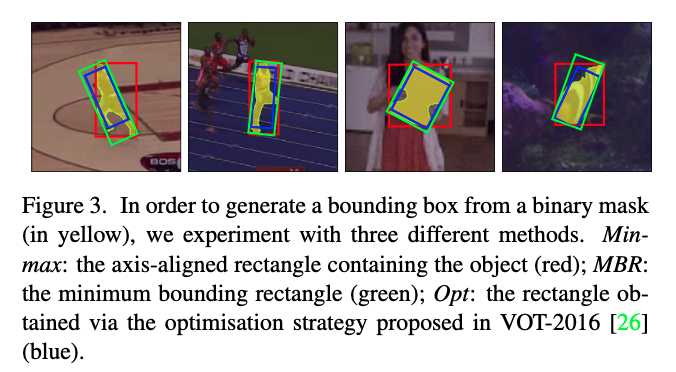
Box生成
- VOSは二値マスクを要求するが,VOTのようなベンチマークはboxを要求する
- マスクからboxを生成する3つの戦略を考えた
- 座標軸に揃えたbox(Min-max).(傾いていないboxのこと)
- 回転した最小矩形(MBR)
- VOT-2016[26]で使用されている自動box生成のための最適化戦略
- マスクからboxを生成する3つの戦略を考えた
3.3. 実装の詳細
ネットワーク構造
- どちらの変種でも,4番目のステージの最後のconvレイヤに到達するまでの部分で,ResNet-50[18]を$f_{\theta}$のバックボーンとして使った
- 深いレイヤでも空間解像度を上げるために,ストライド1の畳み込みを使って出力ストライドを8に減らした
- dilated convolutions[6]で受容野を増やした
- 共有のバックボーン$f_{\theta}$に共有ではない調節レイヤ(256出力の1x1 conv)を加えた
- 式(1)では省略している
- 詳細は付録A
- 深いレイヤでも空間解像度を上げるために,ストライド1の畳み込みを使って出力ストライドを8に減らした
訓練
- SiamFC同様,examplarと探索画像のパッチはそれぞれ127x127, 255x255 pixel
- 訓練中,ランダムにこれらにゆらぎを与えた
- ランダム変形(±8ピクセルまで),リスケーリング(それぞれ$2^{\pm \frac{1}{8}}$と$2^{\pm \frac{1}{4}}$)
- 訓練中,ランダムにこれらにゆらぎを与えた
- ネットワークのバックボーンはImageNet-1k分類タスクで事前訓練
- SGDを使用
- 最初の5epochs は学習率が線形に$10^{-3}$から$5 \times 10^{-3}$に上昇する最初のwarmup フェーズ
- それ以降は15以上のepochの間,対数スケールで$5 \times 10^{-4}$まで減少する
- すべてのモデルはCOCO[31], ImageNet-VID[47], YouTube-VOS[58]で訓練
- SGDを使用
推定
- tracking中,SiamMaskはフレームごとに1度評価される.adaptation手法は使わない
- 2つの変種両方で,分類ブランチの最大スコアを達成している場所を使って出力マスクを選ぶ
- ピクセルごとにsigmoidを適用したあと,マスクブランチの出力をしきい値0.5で二値化する
- 2ブランチの変種では,最初のフレーム以外のフレームでは出力マスクをMin-max boxでfitし,次のフレームの探索領域の参照とする
- 3ブランチでは,box ブランチの最もスコアが高い出力を参照として使うのが効率的
- 2つの変種両方で,分類ブランチの最大スコアを達成している場所を使って出力マスクを選ぶ
4. 実験
- visual object tracking(VOT-2016, VOT-2018)とsemi-supervised video object segmentaion(DAVIS-2016, DAVIS-2017)で評価を行う
- 2ブランチと2ブランチをそれぞれSiamMask-2B, SiamMaskと呼ぶ
4.1. visual object trackingでの評価
データセットと設定
- VOT-2016, VOT-2018はどちらも回転したboxでアノテーションされている
- boxの表現方法によりどれくらい性能が影響するか理解するためVOT-2016で実験を行う
- mean intersection over union(IOU),Average Precision(AP)@{0.5, 0.7} IOUで評価する
- その後VOT-2018でのsotaと比較する
- VOT toolkitのExpected Average Overlap(EAO)で評価する
- trackerの精度とロバストネスを考慮した指標である[27]
- VOT toolkitのExpected Average Overlap(EAO)で評価する
- boxの表現方法によりどれくらい性能が影響するか理解するためVOT-2016で実験を行う
物体の表現方法がどれくらい影響するのか?
- フレームごとに二値マスクを出力することがどれくらいtrackingを改善したか理解したい
- この実験では時系列の側面を無視して,ビデオフレームをランダムにサンプルする
- 以降の結果はVOT-2016のシーケンスからランダムにクロップした探索パッチ(±16ピクセルのランダムシフトと$2^{1\pm 0.25}$のスケールdeformation)でテストされている
- この実験では時系列の側面を無視して,ビデオフレームをランダムにサンプルする
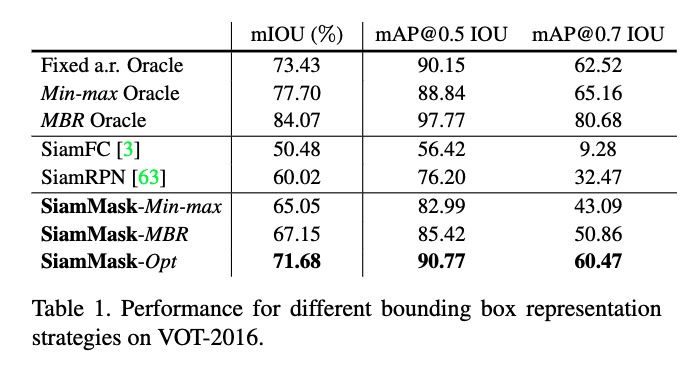
- 表1で,3ブランチの変種として,Min-max, MBR, Optを比較した
- 異なる表現方法で得られる性能の上限値として,各フレームで正解情報にアクセスできる3つの「神託」を比較に入れている
- 固定アスペクト比の神託
- フレームごとの正解エリアと中心位置を使っているが,最初のフレームからアスペクト比が変更しない.boxは回転しない
- Min-maxの神託
- 回転ありの正解boxを囲う最小のboxで回転していないboxを作る
- MBRの神託
- 正解を囲む,回転ありの最小のbounding矩形
- 固定アスペクト比の神託
- これらの3つはそれぞれ,SiamFC, SiamRPN, SiamMaskの達成可能な上限値だと考えることができる
- 異なる表現方法で得られる性能の上限値として,各フレームで正解情報にアクセスできる3つの「神託」を比較に入れている
- 表1から,boxの表現方法に関わらず本手法が最も良いmIOUを示している事がわかる
- SiamMask-OptはIOUとmAPは最高だが,計算コストが非常に高い
- boxの表現方法を変えるだけで非常に大きな改善が見込める可能性があることがわかる(固定アスペクト比とMBRの神託とでは+ 10.6% mIOUの開きがある)
VOT-2018とVOT-2016の結果
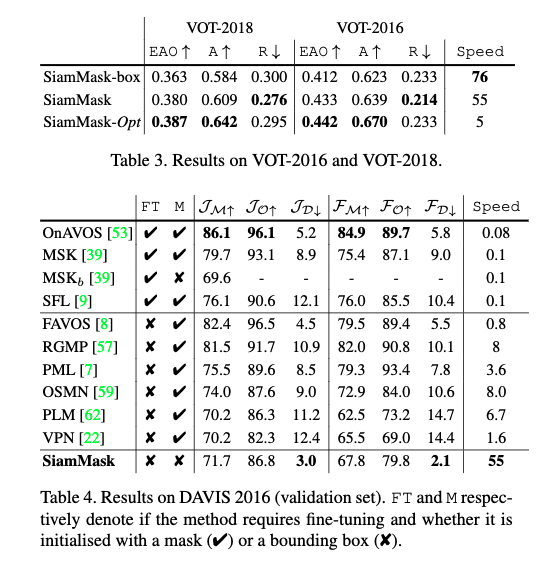
- 表2でMBR戦略を使ったSiamMask,SiamMask-Optとsota手法のVOT-2018における比較を示す
- SiamMaskは3ブランチでMBR戦略のことを意味する
- [54]で提案された戦略を使ったSiamMask-Optは2値マスクから回転したboxを作成でき,最も良い性能を示しているが,計算コストが高い
- 本手法はaccuracyに強みがあり,CSRDCF[33]のようなCorrelation Filter-based trackerを遥かに凌ぐ
- 表3は異なるbox生成戦略でVOT-2018, 2016での結果を示した
- SiamMask-boxはSaimMaskのboxブランチを使って推定したもの.maskブランチも訓練している
- maskブランチをbox生成に使ったほうがすべての評価指標が改善することがわかる
- SiamMask-boxはSaimMaskのboxブランチを使って推定したもの.maskブランチも訓練している

4.2. semi-supervised VOSでの評価
- 多くのVOS手法とは異なり,本手法はオンラインで動作し,リアルタイムで実行できる.シンプルなbounding box初期化だけを必要とする
データセットと設定
- DAVIS-2016[40], DAVIS-2017[45], YouTube-VOS[58]のベンチマークでの結果を報告する
- 両方のデータセットで,公式の性能指標を使う.
- Jaccard index($J$).領域の類似度を示す
- F-measure($F$).輪郭の精度を示す
- 各指標$C \in { J, F }$について,3つの統計量が考えられる
- 平均$C_M$, リコール$C_O$, および時間経過による性能の増加・減少を示す減衰$C_D$[40]
- Xuら[58]に従い,YouTube-VOSについては平均Jacard indexとF-measureを,既知のカテゴリ($J_S, F_S$),未知のカテゴリ($J_U, F_U$)両方について報告する
- $O$はこれらの4つの指標の平均である
- 両方のデータセットで,公式の性能指標を使う.
- 多くのVOS手法と同様,複数の物体が同じビデオ(DAVIS-2017)にある場合はシンプルに複数回推定を行う
DAVISとYouTube-VOSでの結果
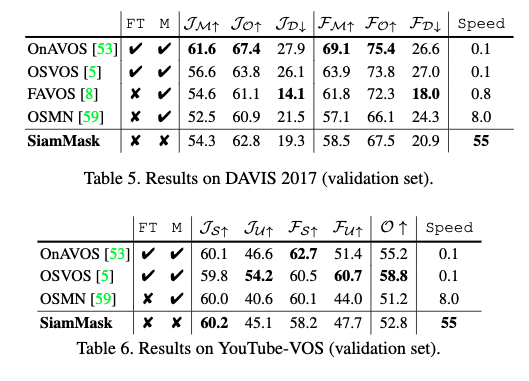
- 表4, 5, 6
- 本手法はOnAVOS[53]やSFL[9]より2桁オーダーで高速
- fine-tuningを必要としない近年のVOS手法と同等の精度で,4倍効率的
- 本手法は,領域類似度($J_D$)および輪郭精度($F_D$)両方についてdecayが非常に少ない
- 本手法が時系列に渡ってロバストであることを示している
- 図4, 9, 10から,障害があってもSaimMaskが正確なセグメンテーションマスクを生成できることがわかる

4.3. さらなる解析
ネットワーク構造
- 表7で,ANとRNは,$f_{\theta}$の共有バックボーンがAlexNetかResNet-50かを表す
- w/o RはPinherioら[44]のrefinement strategyを使用していないことを表す
- 表7より以下がわかる
- $f_{\theta}$の構成を変えると性能改善しうるが,計算コストも上がりうる
- SiamMask-2BとSiamMaskは,それらのベースラインであるSiamFCとSiamRPNよりも大きく改善している.$f_{\theta}$には同じものを使っている
- rifinement approachの効果は$F_M$については大きい
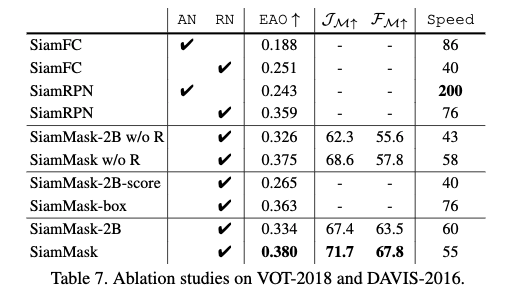
マルチタスク訓練
- マルチタスク訓練の効果を分離して理解するために実験を行った
- 表7で,SiamMaskの2つの変種を使用した.これらはマスクブランチの訓練もしているが,boxの推定に使用していない
- SiamMask-2B-score:
- axis-alignedなbounding boxをスコアブランチから選択する
- SiamMask-box:
- box branchから選択する
- SiamMask-2B-score:
- VOT2018で,どちらも,その対応するモデル(SiamFCとSiamRPN)から少し改善が見られた
- 2ブランチ:EAOで0.251から0.265
- 3ブランチ:EAOで0.359から0.363
時間について
- NVIDIA RTX 2080 GPU1個で,平均速度が55fps,および60fps.それぞれ2ブランチと3ブランチの結果
- 最も計算負荷が重いのは$f_{\theta}$
失敗例
- SiamMaskが失敗するケースとして,モーションブラーとnon-objectがある
- これらは類似する訓練例が訓練データにないという状況を引き起こす
