はじめに
原作者様: Javaで湯婆婆を実装してみる - Qiita
各言語版の実装が流行していますが、もう列挙できないほど広まってしまったのでこちらをどうぞ。
【毎日自動更新】湯婆婆 LGTMランキング! - Qiita
もう自分の使ったことのある言語は出尽くしてしまった…かと思ったのですが、HSP (Hot Soup Processor) は誰もやっていないっぽい!
ということで、HSP3で書いてみました。このネタをやりたいがためにHSP3.51をインストールしました。
15年くらい触っていなかったこともあり(当時はHSP2.55とか2.6とか…)、言語仕様が変わっていたり単純に忘れていたりしたので、意外に苦労しました。
コード
QiitaはHSPのシンタックスハイライトに対応していないらしい。。。
# uselib "kernel32.dll"
# cfunc lstrlenW "lstrlenW" var ; Windows API
randomize ; 乱数シードの初期化
screen 0, 1000, 400 ; ウィンドウサイズの指定
font "", 24 ; フォントの指定
objmode 2 ; コントロールのフォントも変更する
mes "契約書だよ。そこに名前を書きな。"
name = ""
input name, 500, 30, 30 ; テキストボックス作成
objsize 100, 30
button "送信", *clicked ; ボタン作成
stop
*clicked
sdim nameUnicode, 64 ; 文字列バッファを初期化
cnvstow nameUnicode, name ; マルチバイト文字列操作のためUnicodeに変換
mes "フン。" + name + "というのかい。贅沢な名だねぇ。"
newNameIndex = rnd(lstrlenW(nameUnicode))
sdim newNameUnicode ; Unicodeベースで1文字取り出す
memcpy newNameUnicode, nameUnicode, 2, 0, newNameIndex * 2
newName = cnvwtos(newNameUnicode) ; 通常の文字列に変換
mes "今からお前の名前は" + newName + "だ。いいかい、" + newName + "だよ。分かったら返事をするんだ、" + newName + "!!"
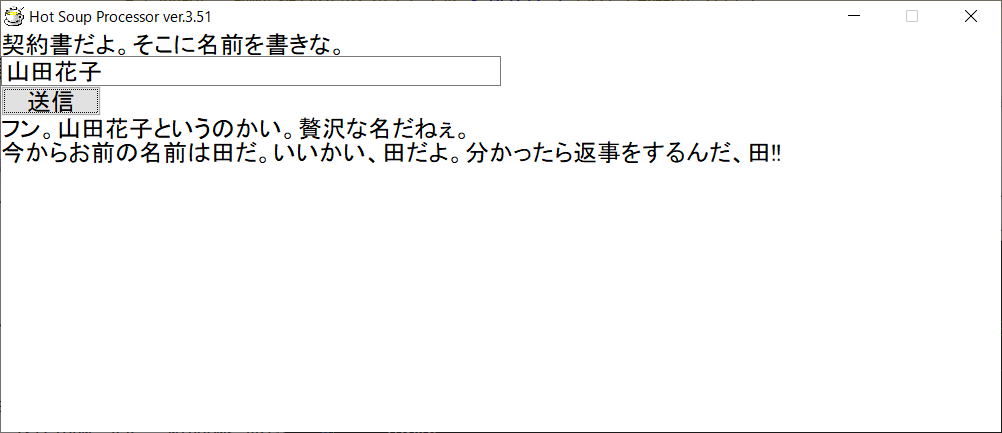
実行例
テキストボックスに名前を入れ、「送信」ボタンを押すと、湯婆婆が答えてくれます。
コードの注意点(特にマルチバイト関連)
令和にもなればHSPでもUnicode (UTF-16) なんて当たり前に使えるようになっていると思っていましたが、割と面倒でした。
マルチバイト文字を考慮して文字列の切り出しを行うために、目的の文字列をまずUnicodeに変換します。
cnvstow nameUnicode, name ; 文字数操作のためUnicodeに変換
続いて、入力された名前の文字数をカウントして、取ってくる文字のインデックスを選択します。文字数カウントの部分でWindows APIを使っています。
newNameIndex = rnd(lstrlenW(nameUnicode))
関連: lstrlenW function (winbase.h) - Win32 apps | Microsoft Docs
lstrlenW を使うために、スクリプトの先頭で以下のように宣言しています。
# uselib "kernel32.dll"
# cfunc lstrlenW "lstrlenW" var
関連: HSP3 プログラミング・マニュアル 「4.9. API呼び出し」
そして選んだインデックスで1文字を取ります。Unicodeは1文字あたり2バイトなので、文字数と転送元のインデックスを2倍します。
memcpy newNameUnicode, nameUnicode, 2, 0, newNameIndex * 2
ここで strmid を使いたくなるのですが、Unicode文字列では終端以外にNULL文字 (C言語でいうところの \0) が現れる場合があるため、正しく動作しません。
最後に、取ってきた文字を通常の文字列に戻します。
newName = cnvwtos(newNameUnicode) ; 通常の文字列に変換
お約束
名前を入れないで送信すると落ちます。原作リスペクト