Kubernetes 1.26がリリースされましたね ![]()
今回もKubernetes v1.26のCHANGELOGをベースにSIG Scheduling(kube-scheduler)に関する機能について紹介していきます。
過去の変更内容
1.26変更点の所感
今回の目玉は下記の2つの新機能です。
- KEP-3521: Pod Scheduling Readiness
-
KEP-3063: Dynamic resource allocation
-
Kubernetes 1.26: SIG-Node (kubelet) 変更内容
に解説がありますのでここでは割愛します
-
Kubernetes 1.26: SIG-Node (kubelet) 変更内容
その他は細かな修正ばかりです。
 What's new! (新情報)
What's new! (新情報)
![]() 1.26のリリースノートにはWhat's newのセクション自体がなかったのですが、v1.26のリリースBlogエントリであるKubernetes v1.26: Electrifyingから、Pod Scheduling Readinessを紹介します。
1.26のリリースノートにはWhat's newのセクション自体がなかったのですが、v1.26のリリースBlogエントリであるKubernetes v1.26: Electrifyingから、Pod Scheduling Readinessを紹介します。
 Pod Scheduling Readiness
Pod Scheduling Readiness
| KEP | KEP-3521: Pod Scheduling Readiness |
|---|---|
| feature gate | PodSchedulingReadiness |
| feature state | alpha |
この機能はPodのAPIに.spec.schedulingGatesフィールドを追加します。このフィールドは Podをスケジュールしてよいか?そうでないか? を定義します。外部のユーザやコントローラがこのフィールドを制御することで、それぞれのポリシーや要求に応じて、Podがスケジュールされないように制御出来ます。
そもそもなんで必要なのか?
現在、Kubernetesクラスタ上のPodは、クラスタ上で実行されているべきワークロードの最小単位として解釈されています。つまりPodが作成された瞬間からそのPodはどこかのノードで動いているべきという解釈です。なので、kube-schedulerは全てのPending Podをnodeに割り当てようとします。
また、kube-schedulerは、一度Podがスケジュール不可能と判断されると次にスケジュールの試行をするまでbackoffするのですが、何らかのクラスター内の状態変化などをきっかけに、その都度、スケジューラーのキューに戻されてスケジュールが試行されます。つまり、スケジュール出来ないと最初からわかっているPodが多いと効率が悪いのです。また、不要なスケジュール試行はPodが実際にnodeにbindされるまでのlatencyを増やしてしまうことにも繋がります。
どんなふうに使う?
そこで、spec.schedulingGates というフィールドを導入して、そもそも「このPodはスケジュールされているべきかそうでないか?」をAPIレベルで定義できるようにします。また、このAPIによってスケジューラーの無駄な試行を減らして、パフォーマンスの向上にも寄与できます。ただし、少し複雑な更新制約があるので注意してください。
apiVersion: v1
kind: Pod
spec:
# schedulingGatesの要素が空でない限りschedulerのキューには入らない(finalizerの動作に似ている)
# 注意:一度空になるまでは追加OK、変更NG、削除OK。ただし、一度でも空になったら変更ができなくなります。
# なのでまず最初はadmission webhookとかで何かを追加する必要があります。
schedulingGates:
- name: foo
- name: bar
どんなことに使えそうなのか?
KEP-3521: Pod Scheduling Readinessには下記の4つのUser Storyが想定されています。
- Dynamic Quota Managerのようなカスタムオーケストレータ(mutating webhookでgateを追加して、schedule readyになったら外す)
- 複数のカスタムオーケストレータによるscheduling readinessの合意(
schedulingGatesが複数になっているのはそのため??) - 高度なadmission enqueueロジックの実装
- カスタムコントローラを変更せずに、Pod作成後にschedule制約を変更する(disruptionを防いだり、affinity/anti-affinityを制御したり)
実装はどうなってるのか?
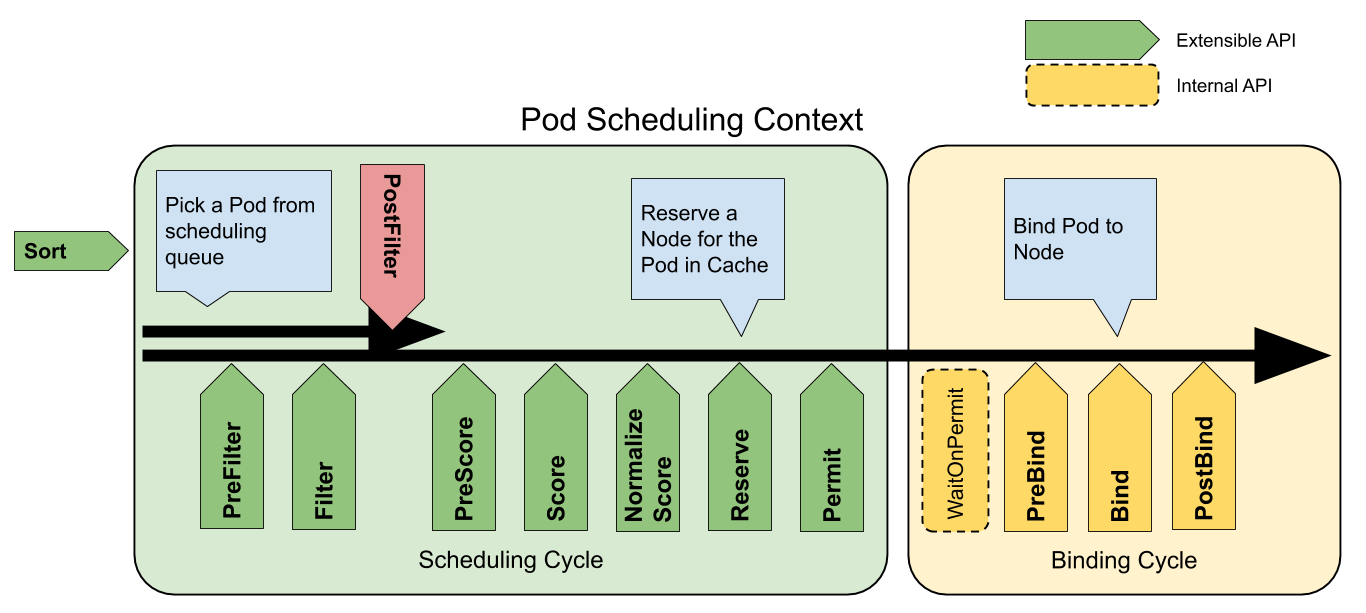
Scheduling Frameworkの拡張点に、新しくPreEnqueueという拡張点が追加されます。.spec.schedulingGatesの機能はPreEnqueue拡張点を実装するSchedulingGatesプラグインとして実装されています。
PreEnqueueはkube-schedulerの内部キュー(正確にはactiveQ)にPodを追加される前に常に実行されます。PreEnqueue拡張点がSuccessではないステータスを返すと、そのPodは内部キューに追加されず結果としてスケジューリングが試みられません。
schedulingGatesが一旦空になったら変更不能という制約もこの実装処理から来ています。一旦内部キューに入ってしまうと、Scheduling Cycleでのスケジュール判断とschedulingGatesの追加がraceを起こしてしまって、schedulingGatesのセマンティクスが保てなくなってしまうからです。
 Urgent Upgrade Notes(必ず一読してからアップグレードしなければならない事項)
Urgent Upgrade Notes(必ず一読してからアップグレードしなければならない事項)
![]() ありません
ありません
 Deprecation(非推奨)
Deprecation(非推奨)
![]() ありません
ありません
 API Changes(API変更)
API Changes(API変更)
-
preEnqueueという新しい拡張点(extension point)がscheduler component configv1beta2/v1beta3/v1に追加されました. (#113275, @Huang-Wei)-
Pod Scheduling Readiness を実現するために導入された拡張点です。
-
-
ResourceClaimAPI(resource.k8s.io/v1alpha1内)が追加されました(DynamicResourceAllocationfeature gateが必要です)。この新しいAPIは、これまでのDevice Pluginに比べ、ノード単位、クラスタ単位などユーザ定義の階層ごとに特別なリソースの種類を定義できるので、より柔軟性があります。(#111023, @pohly)-
解説はKubernetes 1.26: SIG-Node (kubelet) 変更内容を参照ください🙇
-
-
podTopologySpreadプラグインのNodeInclusionPolicyがデフォルトで有効になります。(#113500, @kerthcet) - ( SchedulerConfigの)
v1にプロファイルレベルのパラメータとしてpercentageOfNodesToScoreが追加されました。プロファイルレベルのパラメータが設定されている場合、グローバルレベルのpercentageOfNodesToScoreはオーバーライドされます。(#112521, @yuanchen8911)-
スケジューラはスケジュール先のノードをFilter➔Socreすることで決定します。Scoreはノード毎に並列に計算されますが、実際にはすべてのノードに対して計算されず、
percentageOfNodesToScore分のノードだけ計算しその中から一番Scoreが高いものが選択されます(並列に計算して十分な数のScoreが集まったらshortcut) -
これまではスケジューラのグローバルなパラメータでしたが、プロファイル毎に選択できるようになります。
-
percentageOfNodesToScoreのデフォルト値は固定ではなくクラスタのノード数から算出されるようになっています-
ノード数が100未満だったら100%。100以上の場合は
max(50 - #nodes/125, 5)% (50%から緩やかに5%まで下がっていく) -
ただし、対象ノード数が100未満だったら最低100ノードは評価
-
-
- "Retriable and non-retriable pod failures for jobs" 機能がBetaになります。(#113360, @mimowo)
- 新しいPod APIフィールド
.spec.schedulingGatesが導入され、ユーザがPodをスケジュールreadyとマークできるようになりました。(#113274, @Huang-Wei)
 FEATURE(機能追加)
FEATURE(機能追加)
-
preemption_victimsメトリクスのバケット( ゲージ)がLinearBucketsからExponentialBucketsに変更されました。(#112939, @lengrongfu)-
これまで:
metrics.LinearBuckets(5, 5, 10) // 5から5刻みで10個(50まで) -
これから:
metrics: ExponentialBuckets(1, 2, 7) // 1から2倍刻みで7個(64まで) -
これまで最小値が5だったので、それpreemptionされるpodの個数が5未満だと解像度が低かったのが改善されます。
-
- スケジューラがPod statusを更新する際、
net.ConnectionRefusedエラーだけでなく、ServiceUnavailable,InternalErrorエラーでもリトライするようになりました。(#111809, @Huang-Wei) -
goroutinesメトリクスがスケジューラに追加されました。これはscheduler_goroutinesメトリクスの代替で、より正確にgoroutine数をカウントします。(#112003, @sanposhiho)-
これまで
schedulersubsystemの中にscheduler_goroutineってメトリクスがありました(なのでprometheusではscheduler_scheduler_goroutineとなってしまっていた)。加えて、goroutineのカウントされていない箇所がありました(具体的にはスケジューラ内のparallelizerというutil)。 -
それを修正しつつ、互換性を加味して、リネームじゃなくて、追加されました。
-
-
ComponentSLIsfeature gateが有効な時、kube-schedulerで/metrics/slisendpointが利用可能になり、health checkメトリクスをscrapeできるようになりました。(#113026, @Richabanker) [sig/scheduling]
 バグ修正
バグ修正
-
podTopologySpreadプラグインでの計算ミスが修正されました。これにより想定外のスケジュール結果を防ぐことが出来ます。(#112507, @kerthcet)-
1.25にbackportされています
-
-
PodTopologySpreadpluginのTaint評価ロジックをTaintTolerationプラグインのTaint評価ロジックと整合するようにしました。(#112357, @SataQiu)-
別々に実装されていた評価ロジックを共通化する変更です。
-
- Podのスケジュール処理がエラーにった場合に、Pod Conditionのreasonを
UnschedulableではなくScheduleErrorで更新します。(#111999, @kerthcet)-
v1.22以降のすべてのバージョンにbackportされています。
-
-
kube-scheduler,kube-controller-managerでpod disruption関係のconditionをセットする際にServer Side Applyを使うようになります。(#113304, @mimowo) - ( メトリクスの話です) スケジュール試行の結果が失敗またはスケジュール不能な場合の実行時間に、Unreserveオペレーションが含まれるようになり、長い時間が記録されるようになります。(#113113, @kerthcet)
-
scheduling_attempt_duration_secondsメトリクスについての修正です。
-
 Other (その他の修正)
Other (その他の修正)
- kube-schedulerのComponent Config
v1beta3がv1.26で非推奨になり、v1.29で削除予定です。また、v1beta2はv1.28で削除予定です。(#112257, @kerthcet) - v1.24でGAとなった
DefaultPodTopologySpread,NonPreemptingPriority,PodAffinityNamespaceSelector,PreferNominatedNodefeature gateがv1.26で削除されました。(#112567, @SataQiu) [sig/scheduling] - v1.24でGAとなった
PodOverheadfeature gateが削除されました。(#112579, @SergeyKanzhelev) - スケジューラのdumperが各内部キューのpending pod数をサマリとして出力するようになります。(#111726, @Huang-Wei)
-
kube-schedulerは
USR2シグナルを送ると内部キューの状態をダンプする機能(dumperと呼ばれます)がありますが、これまではPodの情報がすべてダンプされていて、キュー内のPod数が分かりづらい状況でした。 -
が、この変更で
activeQ:100; backoffQ:1000; unschedulablePods:1500のように各内部キューのPod数も一緒にダンプされるようになり少し読みやすくなりました。
-