はじめに
この記事では、フレームワーク(PyTorchやTensorFlow)を使わずに、NumPyだけでDeep Neural Network (DNN) 2層ニューラルネットワークを実装し、為替レート(USD/JPY)から日経平均株価を予測するモデルを作成します。 「誤差逆伝播法」や「勾配降下法」の仕組みをコードレベルで理解することを目的としています。前回、yfinaceを使った統計処理の続きになります。
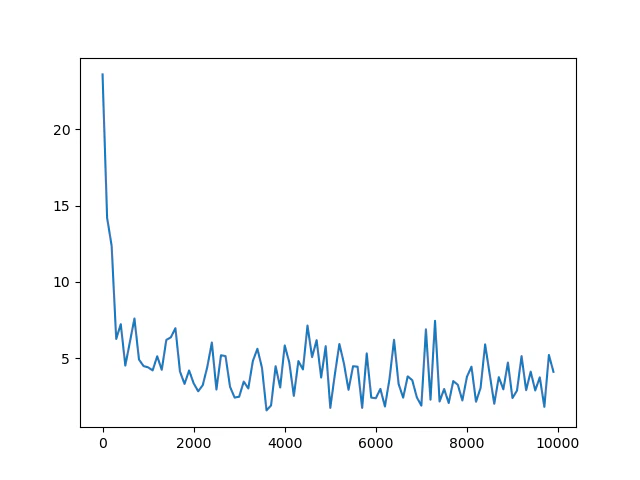
損失値の推移
イテレーション10000回後のパラメータと、実データと、推論値の誤差率。
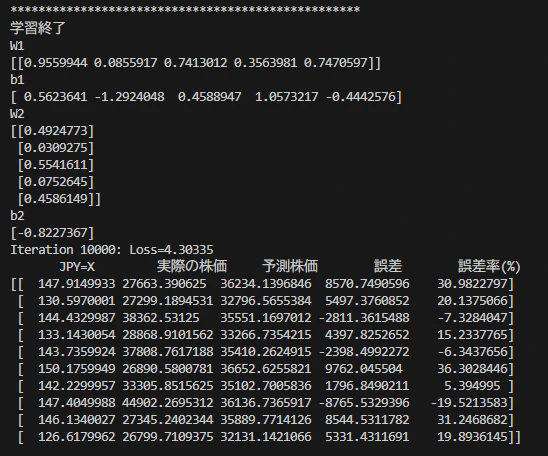
本モデルは入力変数をドル円レートのみに限定しているため、実運用に耐えうる予測精度を求める設計ではありません。しかし、学習対象とした直近4年間は「円安=株高」という強い相関関係が市場を支配していた時期にあたります。そのため、データに含まれるトレンドが明確であり、単純なネットワーク構成でもその特徴を十分に捕捉でき、損失関数の収束に至ったと推察されます。
モデルアーキテクチャ 以下のような構成の2層ニューラルネットワークを採用しました。
入力層 (Input Layer):1ノード(USD/JPY)
隠れ層 (Hidden Layer):5ノード / 活性化関数:シグモイド
出力層 (Output Layer):1ノード / 活性化関数:恒等関数(回帰用)(日経平均株価推定値)
コードの解説
1. 活性化関数と損失関数の定義
ニューラルネットワークの基礎部品となる関数群です。
今回は 回帰問題(数値を予測する問題) なので、以下の組み合わせを使用します。
・中間層の活性化: sigmoid(シグモイド関数)
・出力層の活性化: identify_function(恒等関数:入力をそのまま出力)
・損失関数: mean_squared_error(二乗和誤差)

(上:二乗和誤差の計算グラフ)
※コード内には分類問題用の softmax や cross_entropy_error も定義されていますが、今回の株価予測では使用しません。
2. レイヤーの実装(クラス化)
各層をクラスとして定義し、順伝播(forward)と逆伝播(backward)をメソッドとして持たせています。これにより、レゴブロックのように層を組み合わせることが可能です。
Affineレイヤー(全結合層)
行列の積($X \cdot W + b$)を計算する層です。backward では、勾配 dout を用いて重み dW とバイアス db の勾配を計算します。
Sigmoidレイヤー
活性化関数シグモイドを通す層です。逆伝播の計算 $y(1-y)$ を効率的に行います。
meanSquaredLossレイヤー(出力層+損失)
ここは少し工夫されています。回帰問題と分類問題の両方に対応できるようになっています。
def backward(self, dout=1):
batch_size = self.t.shape[0]
# 教師データ t が、推論データ y と同じ形状(shape)をしている場合
# (One-Hot Vector、または回帰問題の実数値データなどが該当)
if self.t.size == self.y.size:
dx = (self.y - self.t)/batch_size
else:
# ... (分類問題でラベル表現の場合の処理) ...
今回の回帰問題ではy(予測株価)と t(正解株価)の形状が一致するため、if のブロックが実行され、単純な差分が逆伝播されます。
3. ネットワーク構成 (twoLayerNetクラス)
モデルの全体像を定義するクラスです。
入力層: 1ノード(ドル円)
隠れ層: 5ノード(Affine -> Sigmoid)
出力層: 1ノード(Affine -> meanSquaredLoss)
OrderedDict を使うことで、追加した順序通りにレイヤーを処理できるため、predict や gradient(勾配計算)の記述が非常にシンプルになっています。
4. データの前処理(標準化)
ここが精度を出すための重要なポイントです。 生の株価データ(2万円台)と為替(100円台)をそのまま使うと、桁が違いすぎて学習がうまく進みません。そのため、標準化(平均0、分散1) を行っています。
# 平均を引いて標準偏差で割る
x_train = (x_train - meanJPY) / stdJPY
t_train = (t_train - meanNikkei) / stdNikkei
これにより、データのスケールが統一され、勾配降下法がスムーズに収束します。
標準化の式:$$z = \frac{x - \mu}{\sigma}(x: 元の値、\mu: 平均、\sigma: 標準偏差)$$
逆変換の式:$$x = z \times \sigma + \mu$$
5. 学習ループ(ミニバッチSGD)
データセットからランダムに小さなデータの塊(ミニバッチ)を取り出し、繰り返し学習させます。
1.ミニバッチの取得: np.random.choice でランダムに選択2.勾配の計算: net.gradient で誤差逆伝播法を実行
3.パラメータ更新: 重み $W$ とバイアス $b$ を学習率 learning_ratio に従って更新
6. 結果の評価と逆標準化
学習が終わった後、モデルが出力するのは「標準化された値」です。これを人間が理解できる「円」の単位に戻すために、逆標準化(逆変換) を行います。
# 予測値 * 標準偏差 + 平均
predicted_n225_price = (predicted_n225 * stdNikkei) + meanNikkei
最後に、実際の株価と予測株価、および誤差率を表示し、損失関数の推移をグラフ化して学習が順調に進んだかを確認します。
7. 実行コード Python
Tow layer NN (nikkei vs JPY=X)
import sys ,os
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
import pandas as pd
from pathlib import Path
import os, sys
np.set_printoptions(linewidth=200)
#**************************************
#中間処理関数
#**************************************
# 活性化関数:シグモイド関数
def sigmoid(x):
return 1/(1+ np.exp(-x))
# ソフトマックス関数
# x:最終段
def softmax(x):
if x.shape[1]==1:
x=x.squeeze() #意味のない 長さ1の次元を消す
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis = 0)
y = np.exp(x)/np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x)
y = np.exp(x)/np.sum(np.exp(x))
return y
# 損失関数:交差エントロピー
# y:予測値
# t:正解ラベル
def cross_entropy_error(y,t):
if y.ndim == 1:
t = t.reshape(1,t.size)
y = y.reshape(1,y.size)
if t.size == y.size: #教師データがhot-one
t = t.argmax(axis = 1)
print(t)
batch_size = y.shape[0]
print(y[np.arange(batch_size), t])
print(np.log(y[np.arange(batch_size), t]))
return -np.sum(np.log(y[np.arange(batch_size), t]+1e-7)) / batch_size
# 恒等関数 (回帰問題用)
# x:最終段予測値
def identify_function(x):
return x
# 損失関数:二乗和誤差
# y:予測値
# t:正解ラベル
def mean_squared_error(y,t):
return 0.5 * np.sum((y-t)**2)
#******************************************
# BP各レイヤー
#******************************************
# Affineレイヤー
class Affine:
def __init__(self, W,b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self,x):
self.x = x
out = np.dot(self.x,self.W) +self.b
return out
def backward(self,dout):
dx = np.dot(dout,self.W.T)
self.dW = np.dot(self.x.T,dout)
self.db = np.sum(dout, axis=0)
return dx
# Reluレイヤー(活性化レイヤー)
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x<0) #[[false,true,[false,true]]]
out = x.copy()
out[self.mask] =0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
# Sigmoidレイヤー(活性化レイヤー)
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self,dout):
dx = dout*self.out*(1.0-self.out)
return dx
# 二乗和誤差レイヤー
class meanSquaredLoss:
def __init__(self):
self.loss = None
self.t = None
self.y = None
def forward(self, y, t):
self.t = t
self.y = identify_function(y)
self.loss = mean_squared_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
# 教師データ t が、推論データ y と同じ形状(shape)をしている場合
# (One-Hot Vector、または回帰問題の実数値データなどが該当)
if self.t.size == self.y.size:
dx = (self.y - self.t)/batch_size
else:
dx = self.y.copy()#ont-Hotをラベルで管理しているとき
#メモリ節約などで。やっていることは、上と同じ。
dx[np.arrange(batch_size), self.t] -=1
dx = dx / batch_size
if dx.ndim == 1:
dx = dx.reshape(dx.shape[0],1)
return dx
#**********************************************************
# DNN 2層レイヤー クラス 全体の統括*************************
#**********************************************************
class twoLayerNet:
def __init__(self, inputSize, hiddenSize1, outputSize):
scale = 1.0
#重み初期化
self.params = {}
#1層目 W1(1,5) ,b1(5,)
self.params['W1'] = scale * np.random.rand(inputSize, hiddenSize1)
self.params['b1'] = np.random.randn(hiddenSize1) #0.0~1.0 一様分布
#1層目 W1(5,1) ,b1(1,)
self.params['W2'] = scale * np.random.rand(hiddenSize1, outputSize)
self.params['b2'] = np.random.randn(outputSize) #0.0~1.0 一様分布
#レイヤー初期化
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Sigmoid1']= Sigmoid()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
#最終レイヤー初期化
self.lastLayer = meanSquaredLoss()
# 順方向計算
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
# 損失関数の評価
def loss(self, x, t):
y = self.predict(x) #推論値
return self.lastLayer.forward(y,t)
# 微分値計算
def gradient(self, x, t):
#forward
loss = self.loss(x,t)
#backward
dout=1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())#インスタンスの参照を取得、リスト化
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return loss, grads
#*********************************************************
# main
#*********************************************************
# データの準備 ----------------------
# 現在のフォルダ('.')の中で、パターンに合うファイルを探す
files = list(Path('.').glob('market_comparison_*.csv'))
if files:
# 見つかったファイルのうち、一番新しいもの(または最初の一つ)を使う
# ファイル名に日付が入っているので、ソートすると最新が最後(-1)に来ます
targetFile = sorted(files)[-1]
print(f"✅ファイルが見つかりました。{targetFile}")
else:
print(f"✖ ファイルが見つかりませんでした。")
sys.exit()
if targetFile.exists():
# index_col=0 で1列目(Date)をインデックスにし、
# parse_dates=True で日付型として認識させる
df_NJPY = pd.read_csv(targetFile, index_col=0, parse_dates=True)
print(type(df_NJPY)) # 型の確認
print(df_NJPY.head()) # 先頭5行を表示
print(df_NJPY.info()) # 各列の型や欠損値の状況を表示
# 戻り値は、pandas dataframe
print(f"ローカルファイル{targetFile}から取り込み完了")
else:
print("ファイルが見つかりません")
sys.exit()
# データの格納 Cleansing---------------------
#DataFrame 変数名の取得
dfName = df_NJPY.columns.tolist()
print("DataFrame Index:", dfName)
#欠損データの除去
df_NJPYf = df_NJPY.dropna().copy()
df_NJPY = df_NJPYf.copy()
print(df_NJPY[:5])
#サンプルデータ総数
trainSize = len(df_NJPY)
print('データ数:',trainSize)
#平均、標準偏差
meanJPY = df_NJPY[dfName[0]].mean()
stdJPY = df_NJPY[dfName[0]].std()
meanNikkei = df_NJPY[dfName[1]].mean()
stdNikkei = df_NJPY[dfName[1]].std()
#入力データ(JPY=X) numpy配列化、標準化
x_train = df_NJPY[dfName[0]].to_numpy().copy()
x_train = (x_train-meanJPY)/stdJPY
#正解データ(Nikkei n225) numpy配列化、標準化
t_train = df_NJPY[dfName[1]].to_numpy().copy()
t_train = (t_train - meanNikkei)/stdNikkei
print(x_train[:5])
print(x_train[:5])
# DNN ********************************************
# DNNネットワーク初期化 ----------------------
inputSize = 1
hiddenSize1 = 5
outputSize = 1
net = twoLayerNet(inputSize, hiddenSize1, outputSize)
# 学習ループの初期化
iterNum = 10000 #イテレーション回数
batchSize = 10 #バッチサイズ
learning_ratio = 0.001 #学習率
data = np.zeros((batchSize,5)) #表示用バッファ
train_loss_list = [] #loss値記録リスト
# 学習ループ---------------------------------------
print("学習開始........")
for itnum in range(iterNum):
batchMask = np.random.choice(trainSize,batchSize)
x_batch = x_train[batchMask].reshape(batchSize,1)
t_batch = t_train[batchMask].reshape(batchSize,1)
loss, grads = net.gradient(x_batch,t_batch)
for key in ('W1','b1','W2', 'b2'):
net.params[key] -= learning_ratio * grads[key]
if itnum % 100 == 0:
train_loss_list.append(loss)
print(f"loss {loss:.6f}")
#学習終了後処理------------------------------------
print('*'*50); print("学習終了")
np.set_printoptions(precision= 7, suppress = True)
for key in ('W1','b1','W2', 'b2'):
print(key)
print(net.params[key])
#標準化データを元に戻す 逆標準化
#学習データをもとに日経平均を推定。
predicted_n225 = net.predict(x_batch) #学習データをもとに計算
predicted_n225_price = (predicted_n225 *stdNikkei) + meanNikkei
#ドル円を元に戻す。
jpy = (x_batch * stdJPY) + meanJPY
#教師データとして使用した、リアル日経平均を元に戻す。
actual_n225_price = (t_batch * stdNikkei) + meanNikkei
#表示用dataにまとめる
data[:,0] = jpy.flatten()
data[:,1] = actual_n225_price.flatten()
data[:,2] = predicted_n225_price.flatten()
data[:,3] = data[:,2] - data[:,1]
data[:,4] = data[:,3]/data[:,1]*100
#最終イテレーションでの損失値
loss = net.loss(x_batch, t_batch)
print(f"Iteration {itnum+1}: Loss={loss:.5f}")
#最終結果一覧
print(" JPY=X 実際の株価 予測株価 誤差 誤差率(%)")
print(data)
x = np.arange(iterNum/100)
plt.plot(x*100, train_loss_list)
plt.show()