3層DNNを使って、日経平均の上昇、下降をドル円レートから推論します。
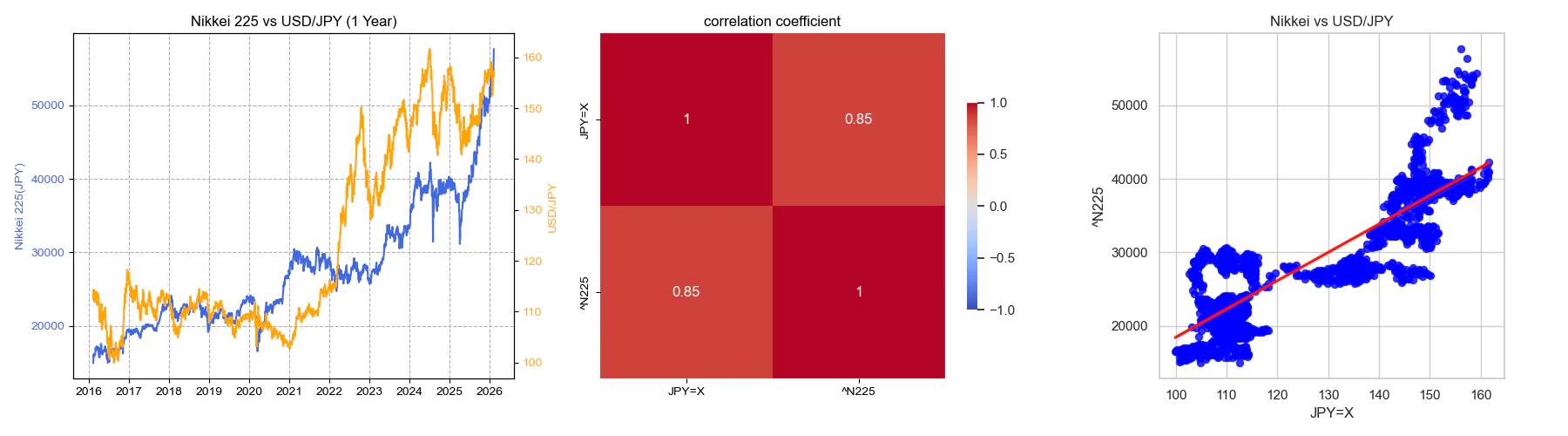
(上図 過去10年分の 日経平均とドル円の相関)
Geminiの作成した文章を、加筆し、再構成しています。
1. プロジェクトの目的
ゴール:
Python(NumPyのみ)でゼロからDeep Neural Network(DNN)を構築し、為替(USD/JPY)から日経平均(Nikkei 225)の変動を予測する。
最終目標:
学習済みの重みをC言語のヘッダファイルとして書き出し、STM32マイコン上で推論エンジンを動作させること。
そもそも、円ドル為替だけで、日経平均株価を推論すること自体無理がありますが、
そこは、おしきって、実行あるのみです。
2.まずは、2層ニューラルネットワークで推論。
1-5-1の2層ニューラルネットで推論。入力:ドル円、出力:日経平均
金融時系列データに関する補足
学習自体は動作しますが、金融データ(為替と株価)は非定常(Non-stationary) なデータであるため、単純な JPY -> Nikkei の回帰は、期間によって相関が逆転したり、トレンドに引きずられて過学習(Overfitting)しやすいです。
絶対値(価格そのもの)ではなく、「前日比(変化率)」 または 「対数収益率」 を入力・出力にすると、より汎用的なモデルにします。
入力: (今日のドル円 - 前日のドル円) / 前日のドル円
出力: (今日の日経 - 前日の日経) / 前日の日経
3.絶対値(価格)から、変化率で、推論する準備。
pct_change()
Pandas(Pythonのデータ解析ライブラリ)で提供されている、「現在の要素と前の要素との間の変化率」 を計算するための非常に便利な関数です。金融データの分析では「昨日に比べて何%動いたか」が重要になるため、必須級のメソッドと言えます。以下の計算を自動で行っています。$$\text{変化率} = \frac{\text{今回の値} - \text{前回の値}}{\text{前回の値}}$$
なぜニューラルネットワークにこれが必要なのか?
今回のように「ドル円」から「日経平均」を予測する場合、そのままの価格(150円や38,000円)を学習させるよりも、pct_change() を使う方が圧倒的に有利な理由が2つあります。
データの「定常化」:
価格そのものは、時間が経つにつれてどんどん上昇(または下落)していく傾向がありますが、変化率は常に「0付近」で上下します。AIにとって、**「常に同じような範囲(-0.05〜+0.05など)で動くデータ」**は非常に学習しやすいのです。
スケールの統一:
「150(ドル円)」と「38000(日経平均)」では数字の桁が違いすぎますが、変化率にすればどちらも「0.01(1%)」のような同じ規模の数字になり、重みの計算が安定します。
活性化関数(Sigmoid)との相性:
今回のコードでは活性化関数に Sigmoid を使っています。シグモイド関数は、入力が $0$ 付近のときが最も勾配(傾き)が強く、学習が活発に進みます。 入力が $0$ から大きく外れる(例えば $5.0$ や $-5.0$ など)と、グラフが平らになり、学習が止まってしまう「勾配消失」が起きやすくなります。標準化によってデータを $0$ 付近に密集させることは、シグモイド関数を活かすために非常に重要です。
※さらに、変化率に変換したデータセットを、標準化(スタンダーダイゼーション)を行い、平均0,分散1のデータセットに変換します。
あとあと、データの加工過程で、ネットワークの動きが、よくわかるようになります。
4.2層ニューラルネット、入力一つ、で実行
1-5-1のトポロジーを使い、変化率で、推論した結果。
入力に、変化率を一つ。
バッチサイズは、64。
方向正解率(Directional Accuracy)でモデルを評価します。
金額のズレよりも、「上がるか下がるか(プラスかマイナスか)」が当たっているかを見ます。トレーディングではこちらの方が重要です。
#全データの方向正解率
all_predictions = net.predict(x_train_win)#学習ずみパラメータで推論
#推論値と、実データの変化率の符号の向きをチェック
#同じならば1を返し、全データの方向正解の平均を取る。
total_accuracy = np.mean(np.sign(all_predictions) == np.sign(t_train_win))*100
print("ファイル:",targetFile)
print(f"全データ 方向正解率:{total_accuracy:3.3f}%")
※推定値と、リアルデータの符号の一致をもって、正解とする評価法です。loss値が収束しても、この方向正解率が低ければ、そのモデルは、不採用ということになります。

1. なぜ「Loss = 32」付近で止まるのか?
この数字にはカラクリがあります。
バッチサイズ: 64
損失関数: 二乗和誤差(0.5 * sum((y - t)**2))
データ: 標準化済み(平均 0、分散 1)
もし、AIが 「何も分からないから、とりあえず全部 0(平均値)と予想しておこう」 と判断した場合、計算はどうなるでしょうか?
予測 $y = 0$正解 $t$ は標準偏差 1 のデータなので、
$(y - t)^2 = (0 - t)^2 = t^2$
$t^2$ の平均値は、分散そのものなので「1」です。
$$Loss = $0.5 \times \text{バッチサイズ(64)} \times \text{平均誤差(1)} = \mathbf{32}$$
グラフのLossが30〜40を行き来しているのは、まさに 「AIが標準化されたデータの平均値(変化なし)を予測し続けている」証拠です。
今の入力データ(昨日のドル円の変化率 1個)だけでは、今日の日経平均を予測するのに情報が足りず、AIにとって「平均値を答えるのが一番安全(Lossが爆発しない)」という結論に達してしまったのです。
loss値のボラティリティが小さく、収束しているので、ネットワークの学習はこれ以上改善しない状態です。
このloss値の推移だけで、判断できない状態があるということ、これが、今回の新しい展開です。
情報が足りない、この膠着状態を、解決するために、スライディングウィンドウ法を用います。
5.スライディングウィンドウ法で、推論。
突破口:入力データを「点」から「線」にする
「昨日のドル円」という点の情報だけで予測するのは、人間でも不可能です。 「過去5日間のドル円の動き」という線(トレンド) の情報を入力すれば、AIは「上がり続けているから、明日も上がるかも」といった文脈を理解できるようになります。
これを 「スライディングウィンドウ法」 と呼びます。
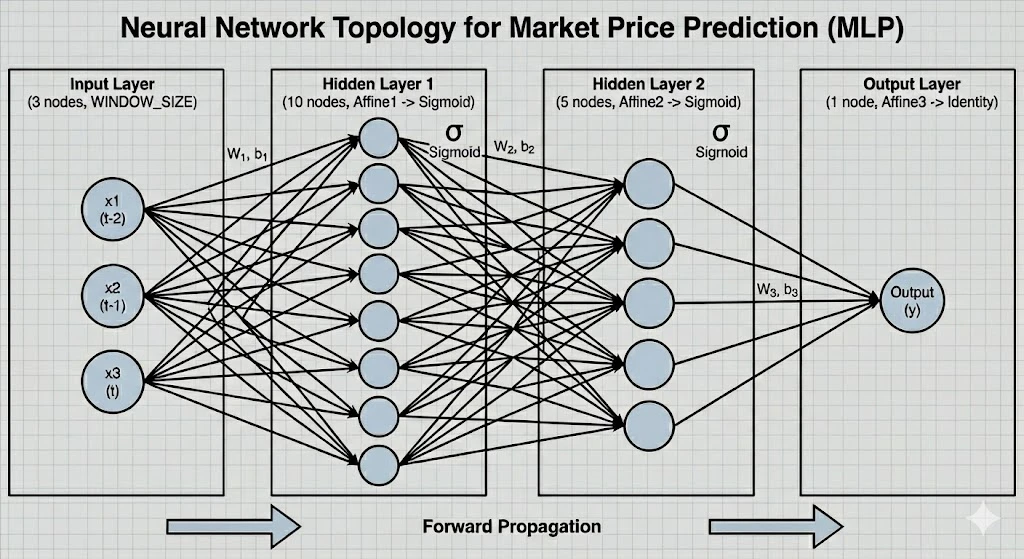
DNNを、5-10-5-1のトポロジーに組みなおして、学習推論した結果。
windowサイズは、5。変化率を連続5個を入力します。(10日分データ)
バッチサイズは、64。
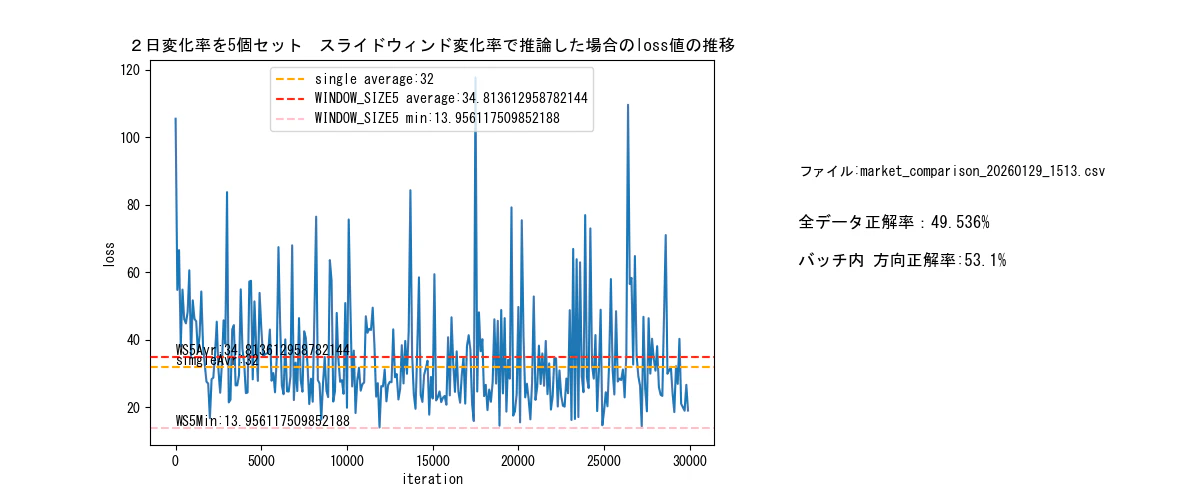
- 「32の壁」を突き破った
以前の Batch=64 のとき、Lossは 32.0 で下げ止まっていました。 今回のグラフは、グラフの底(ベースライン): 15.0 〜 18.0 付近まで下がっています。
意味: 「32 → 16」と、誤差が約半分になっています。これはAIが「ただ平均値を答える」のをやめて、「過去5日の動きから、明日の動きをある程度当てにいっている」 証拠です。
- スパイク(ヒゲ)は「市場のノイズ」
グラフがまだギザギザして、時々 Loss が 80 や 100 に跳ね上がっていますが、これは正常です。
低いところ (Loss 16): 「過去のパターン通りに動いた日」です。AIは正解しました。
高いところ (Loss 80): 「突発的なニュースなどで、過去の動きとは無関係に動いた日」です。
金融市場には「ランダムな動き(ノイズ)」が必ず含まれます。AIがこれを予測できないのは当然です。
重要なのは、「予測できる日(底の部分)」のLossがしっかりと下がっていることです。
グラフのボラティリティ(変動幅)が、大きすぎるのが気になります。
ボラティリティの小さい、1入力のDNNで実行すると、上述のように、途中で推論をあきらめ、バッチデータの半分の値をloss値としたのままの状態が続きます。
5セットスライディングウィンドウを実行した結果、全データの正答率が、50%を切っているため、モデルとしては、不採用になります。
6.方向正解率(Accuracy)の改善。
方向正解率(Accuracy)
50.0% 以下: まだランダム(学習不足、またはモデル構成の見直しが必要)。
51% 〜 53%: わずかに優位性あり(カジノの胴元レベル)。
54% 以上: 金融予測としては非常に優秀。
先ほどは、変化率を5個入力した結果、方向正解率が50%を切ってしまいました。
そこで、トポロジーを変えてみます。
windowサイズを3に減らします。
変化率3つを一組の入力データ(6日分のデータ)に変更してみます。
DNNを、3-10-5-1のトポロジーに組みなおして、学習推論した結果。
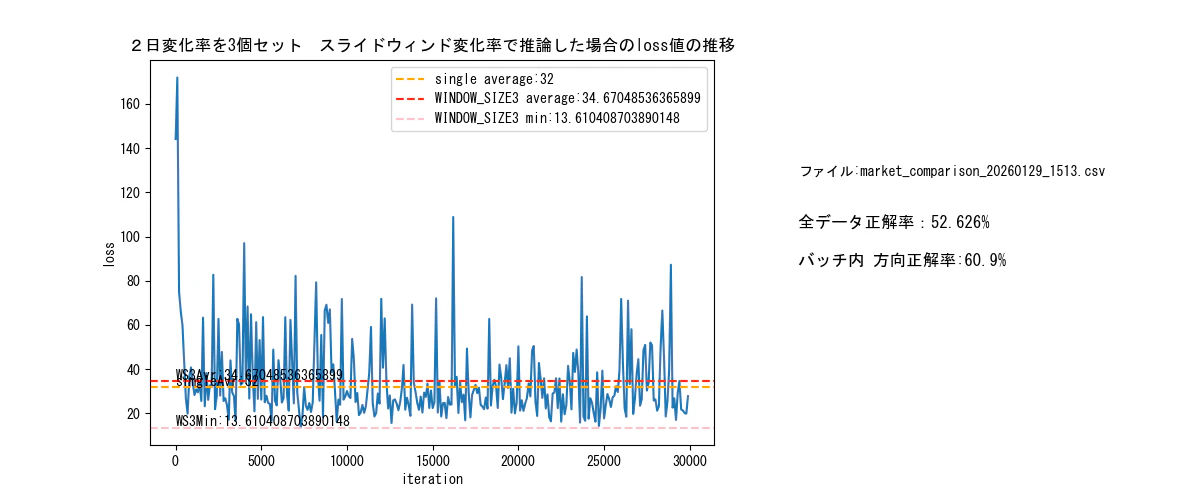
正答率が、約52%。に改善。
そもそも、ドル円だけで、推論することに無理があるので、これで良しとします。
7.実行コード仕様
為替変動による日経平均予測AI学習・組込みコード生成システム 仕様書
7.1 概要
過去の為替レート(USD/JPY)の変動データを入力とし、翌日の日経平均株価(Nikkei 225)の変動率を予測する多層パーセプトロン(MLP)モデルを構築・学習するPythonプログラムです。
NumPyを用いたスクラッチ実装のバックプロパゲーションにより学習を行い、学習後のパラメータをSTM32等のマイクロコントローラへ移植可能なC言語ヘッダファイル形式(weights.h 相当)として出力する機能を有する。
1. 動作環境
開発言語: Python 3.x
必須ライブラリ:
numpy: 行列演算、ニューラルネットワーク計算
pandas: CSVデータ読み込み、時系列データ処理
matplotlib: 損失関数の推移グラフ描画
入力ファイル: market_comparison_*.csv
カレントディレクトリ内の、ファイル名でソートして最後(最新)のものを使用。
2. データ処理仕様
2.1. データ読み込み
ファイル形式: CSV
インデックス: 1列目(日付)
対象データ:
2列目以降を使用。
列0: USD/JPY(入力特徴量)
列1: Nikkei 225(正解ラベル)
3. 前処理(Pre-processing)
欠損値除去: dropna() により欠損を含む行を削除。
変化率算出: pct_change() を使用し、前日比の変化率に変換。再度 dropna() を実施。
標準化(Standardization):
入力(USD/JPY)、正解(Nikkei 225)それぞれに対し、平均0、分散1になるよう正規化を実施。
数式: $x' = \frac{x - \mu}{\sigma}$
スライディングウィンドウ処理:
ウィンドウサイズ: 3(過去3日分)
過去3日分のUSD/JPY変化率を1つの入力セットとし、その翌日のNikkei 225変化率を正解ラベルとする。
4. ニューラルネットワーク構成
モデルアーキテクチャ
NumPyによるフルスクラッチ実装の全結合層ニューラルネットワーク。
| 層 | 種類 | ノード数 | 活性化関数 | パラメータ | 備考 |
|---|---|---|---|---|---|
| 入力層 | Input | 3 | - | - | ウィンドウサイズ(過去3日分) |
| 隠れ層1 | Affine | 10 | Sigmoid | W1, b1 | |
| 隠れ層2 | Affine | 5 | Sigmoid | W2, b2 | |
| 出力層 | Affine | 1 | Identity | W3, b3 | 回帰問題として実装 |
5. 損失関数 (Loss Function)
二乗和誤差 (Mean Squared Error)
回帰問題として、予測値と正解値の差の二乗和を最小化する。
6. 学習アルゴリズム
最適化手法: 確率的勾配降下法 (SGD)
学習率 (Learning Rate):
初期値: 0.001
減衰: イテレーションごとに learning_ratio *= 0.99995
重み初期化: 正規分布 (np.random.randn) × scale(1.0)
乱数シード: np.random.seed(33) (再現性確保のため固定)
7. 学習プロセス仕様
イテレーション数: 最大 30,000回
バッチサイズ: 64
早期終了 (Early Stopping):
条件: 全工程の90%以上経過 (27,000回以降) かつ Loss < 0.7 を満たした場合。
パラメータ更新: 誤差逆伝播法(Backpropagation)により勾配を算出。
8. 出力機能仕様
6.1. コンソール出力(学習経過)
ファイル読み込み状況、データ形状。
学習終了後のLoss値。
精度評価:
バッチ内 方向正解率(予測と実測のプラスマイナス符号が一致した割合)。
全データ 方向正解率。
予測結果サンプル: JPY変化率、実測Nikkei変化率、予測Nikkei変化率、方向一致フラグのテーブル表示。
6.2. グラフ描画 (matplotlib)
Loss推移グラフ:
イテレーションごとのLoss低下をプロット。
比較用ライン: 単純平均(Single Average)、今回の学習の平均(Average)、最小値(Min)。
テキスト情報: ファイル名、最終正解率を表示。
6.3. C言語ソースコード生成(標準出力)
STM32等の組込みマイコンで推論を行うためのヘッダファイル形式を出力する。
出力フォーマット詳細
ガード: #ifndef WEIGHTS_H ~ #endif
データ型: const float (末尾に f を付与)
配列構造: 多次元配列を1次元(Flatten)化して出力。
コメントにてインデックス計算式 W[i][j] -> W_flat[i * NEXT_NODE + j] を記載。
出力定数一覧
標準化パラメータ:
MEAN_JPY, STD_JPY (入力正規化用)
MEAN_NIKKEI, STD_NIKKEI (出力逆正規化用)
学習済み重み・バイアス:
val_W1, val_b1 (入力層 -> 隠れ層1)
val_W2, val_b2 (隠れ層1 -> 隠れ層2)
val_W3, val_b3 (隠れ層2 -> 出力層)
検証用データ:
sample_input: 学習データの最初の1セット。
Pythonでの推論結果(コメントとして出力): 実機実装時の正解値合わせに使用。
7. クラス設計概略
クラス名
役割
Affine
全結合層の順伝播・逆伝播計算 ($Y = X \cdot W + B$)
Sigmoid
シグモイド活性化関数の順伝播・逆伝播
meanSquaredLoss
二乗和誤差の計算および最終層の勾配計算
NNLayerInfo
ネットワーク層構成(ノード数)の定義とパラメータ名管理
neuralNetWork
ネットワーク全体の構築、パラメータ管理、推論(predict)、学習(gradient)の統括
- 制約事項
入力データCSVは、ヘッダー行を持ち、日付順に並んでいることを前提とする。
生成されるCコードは、浮動小数点演算ユニット(FPU)を持つマイコン(STM32F4/F7等)での利用を推奨する。
PC上で、3層DNN 日経平均変動の上下動を学習推論するコード
"""
L_BP_StockMarket.myL_BP_MarketPrice3 の Docstring
過去3日分 スライディングウィンドウ法
表示整理
"""
import sys ,os
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
import pandas as pd
from pathlib import Path
from dataclasses import dataclass
import os, sys
np.set_printoptions(linewidth=200)
#**************************************
#中間処理関数
#**************************************
# 活性化関数:シグモイド関数
def sigmoid(x):
return 1/(1+ np.exp(-x))
# ソフトマックス関数
# x:最終段
def softmax(x):
if x.shape[1]==1:
x=x.squeeze() #意味のない 長さ1の次元を消す
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis = 0)
y = np.exp(x)/np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x)
y = np.exp(x)/np.sum(np.exp(x))
return y
# 損失関数:交差エントロピー
# y:予測値
# t:正解ラベル
def cross_entropy_error(y,t):
if y.ndim == 1:
t = t.reshape(1,t.size)
y = y.reshape(1,y.size)
if t.size == y.size: #教師データがhot-one
t = t.argmax(axis = 1)
print(t)
batch_size = y.shape[0]
print(y[np.arange(batch_size), t])
print(np.log(y[np.arange(batch_size), t]))
return -np.sum(np.log(y[np.arange(batch_size), t]+1e-7)) / batch_size
# 恒等関数 (回帰問題用)
# x:最終段予測値
def identify_function(x):
return x
# 損失関数:二乗和誤差
# y:予測値
# t:正解ラベル
def mean_squared_error(y,t):
return 0.5 * np.sum((y-t)**2)
#******************************************
# BP各レイヤー
#******************************************
# Affineレイヤー
class Affine:
def __init__(self, W,b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self,x):
self.x = x
out = np.dot(self.x,self.W) +self.b
return out
def backward(self,dout):
dx = np.dot(dout,self.W.T)
self.dW = np.dot(self.x.T,dout)
self.db = np.sum(dout, axis=0)
return dx
# Reluレイヤー(活性化レイヤー)
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x<0) #[[false,true,[false,true]]]
out = x.copy()
out[self.mask] =0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
# Sigmoidレイヤー(活性化レイヤー)
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self,dout):
dx = dout*self.out*(1.0-self.out)
return dx
# 二乗和誤差レイヤー
class meanSquaredLoss:
def __init__(self):
self.loss = None
self.t = None
self.y = None
def forward(self, y, t):
self.t = t
self.y = identify_function(y)
self.loss = mean_squared_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
# 教師データ t が、推論データ y と同じ形状(shape)をしている場合
# (One-Hot Vector、または回帰問題の実数値データなどが該当)
if self.t.size == self.y.size:
dx = (self.y - self.t)/batch_size
else:
dx = self.y.copy()#ont-Hotをラベルで管理しているとき
#メモリ節約などで。やっていることは、上と同じ。
dx[np.arrange(batch_size), self.t] -=1
dx = dx / batch_size
if dx.ndim == 1:
dx = dx.reshape(dx.shape[0],1)
return dx
#**********************************************************
# DNN 多層レイヤー 初期設定管理クラス ********************
#**********************************************************
class NNLayerInfo:
def __init__(self, nodeNumls):
self.TotalLayerNum=len(nodeNumls)-1 #総レイヤー数
self.nodeNumlist= nodeNumls #ex.[3,10,5,1]
self.LayerParamsNameList=[] #各レイヤーに属するクラスレイヤの名前キー登録
#self.inputSize=nodeNumls[0]
#self.outputSize=nodeNumls[-1]
#nodelist作成
for layerNum in range(1,self.TotalLayerNum+1):
ls=[]
n = str(layerNum)
nodeWStr = 'W' + n
nodebStr = 'b' + n
nodeLayerStr = 'Affine' + n
ls.append(nodeWStr)
ls.append(nodebStr)
ls.append(nodeLayerStr)
if layerNum < self.TotalLayerNum:
nodeactivateLayerStr = 'Sigmoid' + n
ls.append(nodeactivateLayerStr)
else:
ls.append("")
self.LayerParamsNameList.append(ls)
print("============================================\n")
print(self.LayerParamsNameList)
#**********************************************************
# DNN 多層レイヤー 全体の統括,計算クラス *******************
#**********************************************************
class neuralNetWork:
def __init__(self, nnLayerInfo):
self.TotalLayerNum = nnLayerInfo.TotalLayerNum
self.nodeNumlist = nnLayerInfo.nodeNumlist
self.paramsNameList = nnLayerInfo.LayerParamsNameList
#self.inputSize = nnLayerInfo.inputSize
#self.outputSize = nnLayerInfo.outputSize
scale = 1.0
np.random.seed(33)
#重み初期化
self.params = {}
self.layers = OrderedDict()
for i,name in enumerate(self.paramsNameList):
#self.params[name[0]] = scale * np.random.rand(self.nodeNumlist[i], self.nodeNumlist[i+1])
# 修正後: randn (正規分布) を使用し、Heの初期値などを意識して少し小さめの値をセットするのが一般的
self.params[name[0]] = scale * np.random.randn(self.nodeNumlist[i], self.nodeNumlist[i+1])
self.params[name[1]] = np.random.randn(self.nodeNumlist[i+1])
if name[2][:-1] == 'Affine':
self.layers[name[2]] = Affine(self.params[name[0]], self.params[name[1]])
if name[3][:-1] == 'Sigmoid':
self.layers[name[3]]= Sigmoid()
#最終レイヤー初期化
self.lastLayer = meanSquaredLoss()
# 順方向計算
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
# 損失関数の評価
def loss(self, x, t):
y = self.predict(x) #推論値
return self.lastLayer.forward(y,t)
# 微分値計算
def gradient(self, x, t):
#forward
loss = self.loss(x,t)
#backward
dout=1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())#インスタンスの参照を取得、リスト化
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
for i,name in enumerate(self.paramsNameList):
grads[name[0]], grads[name[1]] = self.layers[name[2]].dW, self.layers[name[2]].db
#print(grads)
#t=input()
return loss, grads
#*********************************************************
# main
#*********************************************************
# 時系列データから、過去n日分をまとめた入力データを作る関数
def make_dataset_window(x_data, t_data, window_size):
x_list = []
t_list = []
for i in range(len(x_data) - window_size):
# xは過去 window_size 分のデータをまとめる
x_window = x_data[i : i + window_size]
# tは、その翌日のデータ(予測対象)
t_val = t_data[i + window_size]
x_list.append(x_window)
t_list.append(t_val)
return np.array(x_list).reshape(len(x_list), window_size), np.array(t_list).reshape(len(t_list), 1)
# データの準備 ----------------------
# 現在のフォルダ('.')の中で、パターンに合うファイルを探す
files = list(Path('.').glob('market_comparison_*.csv'))
if files:
# 見つかったファイルのうち、一番新しいもの(または最初の一つ)を使う
# ファイル名に日付が入っているので、ソートすると最新が最後(-1)に来ます
targetFile = sorted(files)[-1]
print(f"✅ファイルが見つかりました。{targetFile}")
else:
print(f"✖ ファイルが見つかりませんでした。")
sys.exit()
if targetFile.exists():
# index_col=0 で1列目(Date)をインデックスにし、
# parse_dates=True で日付型として認識させる
df_NJPY = pd.read_csv(targetFile, index_col=0, parse_dates=True)
print(type(df_NJPY)) # 型の確認
print(df_NJPY.head()) # 先頭5行を表示
print(df_NJPY.info()) # 各列の型や欠損値の状況を表示
# 戻り値は、pandas dataframe
print(f"ローカルファイル{targetFile}から取り込み完了")
else:
print("ファイルが見つかりません")
sys.exit()
# データの格納 Cleansing---------------------
#DataFrame 変数名の取得
dfName = df_NJPY.columns.tolist()
print("DataFrame Index:", dfName)
#変化率に変換=>欠損データの除去
df_NJPY_Change = df_NJPY.dropna().pct_change().dropna()
df_NJPY_Cg = df_NJPY_Change.copy()
print(df_NJPY_Cg[:5])
#サンプルデータ総数
trainSize = len(df_NJPY_Cg)
print('データ数:',trainSize)
#入力データ(JPY=X)変化率 numpy配列化、標準化
x_train = df_NJPY_Cg[dfName[0]].to_numpy().copy()
meanJPY_changeRate = x_train.mean()
stdJPY_changeRate = x_train.std()
x_train = (x_train-meanJPY_changeRate)/stdJPY_changeRate
#正解データ(Nikkei n225)変化率 numpy配列化、標準化
t_train = df_NJPY_Cg[dfName[1]].to_numpy().copy()
meanNikkei_changeRate = t_train.mean()
stdNikkei_changeRate = t_train.std()
t_train = (t_train - meanNikkei_changeRate)/stdNikkei_changeRate
print(x_train[:5])
print(x_train[-5:])
print(t_train[:5])
print(t_train[-5:])
# ウィンドウデータを作成
WINDOW_SIZE = 3 #過去x:2日分 xセット
x_train_win, t_train_win = make_dataset_window(x_train, t_train,WINDOW_SIZE)
print(f"Window Input Shape:{x_train_win.shape}")
#tarinSizeを更新
trainSize = x_train_win.shape[0]
# DNN ********************************************
# DNNネットワーク初期化 ----------------------
nodeNumsls = [WINDOW_SIZE,10,5,1]
nnLayerInfo1 = NNLayerInfo(nodeNumsls)
#print(nnLayerInfo1.LayerParamsNameList)
net = neuralNetWork(nnLayerInfo1)
#print(net.params)
#rint(net.layers)
# 学習ループの初期化
iterNum = 30000 #イテレーション回数
itnumMax = iterNum #途中離脱時のイテレーション回数の記録用
batchSize = 64 #バッチサイズ
learning_ratio = 0.001 #学習率
data=[] #表示用バッファ
train_loss_list = [] #loss値記録リスト
# 学習ループ---------------------------------------
print("学習開始........")
for itnum in range(iterNum):
#ランダムにサンプルから、バッチデータを作成
batchMask = np.random.choice(trainSize,batchSize)
x_batch = x_train_win[batchMask]
t_batch = t_train_win[batchMask]
#損失値、勾配ベクトルの算出
loss, grads = net.gradient(x_batch,t_batch)
#パラメータ更新
for name in net.paramsNameList:
net.params[name[0]] -= learning_ratio * grads[name[0]]
net.params[name[1]] -= learning_ratio * grads[name[1]]
#学習率の更新(精度向上)
learning_ratio *=0.99995
#loss値推移の記録
if itnum % 100 == 0:
train_loss_list.append(loss)
#print(f"loss {loss:.6f}")
#学習終了条件(条件成立で、学習停止)
if (itnum >= iterNum-int(iterNum*0.1) and loss<0.7):
itnumMax = itnum
break
lastloss = loss
#学習終了後処理------------------------------------
print('*'*50); print("学習終了")
print("iteration:",itnum)
print("last loss", lastloss)
np.set_printoptions(precision= 7, suppress = True)
#最終重みバイアスパラメータ表示
for name in net.paramsNameList:
print(name[0])
print(net.params[name[0]])
print(name[1])
print(net.params[name[1]])
#標準化データを元に戻す 逆標準化
#学習データをもとに日経平均変化率を推定。
n225_changeRate = net.predict(x_batch) #学習データをもとに計算 (64,5)=>(64,)
predicted_n225_changeRate = (n225_changeRate *stdNikkei_changeRate) + meanNikkei_changeRate
print("==============>\n",predicted_n225_changeRate)
#ドル円変化率を元に戻す。
jpy_changeRate = (x_batch * stdJPY_changeRate) + meanJPY_changeRate #(64,5)
#教師データとして使用した、リアル日経平均変化率を元に戻す。
actual_n225_changeRate = (t_batch * stdNikkei_changeRate) + meanNikkei_changeRate #(64,)
#表示用dataにまとめる
data.append(jpy_changeRate.flatten()) #64*3=192
data.append(actual_n225_changeRate.flatten()) #(64,)
data.append(predicted_n225_changeRate.flatten()) #(64,)
data.append(data[2] - data[1]) #(64,)
# 方向が合っているか判定 (符号が同じなら正の数になることを利用)
# 予測と実測の積がプラスなら方向一致
data.append(np.where(data[1] * data[2] > 0, 1, 0)) #(64,)
"""print("data shape!!!!!!!!!!!!!!!!!!!!!!!!!")
for i in range(0,len(data)):
print(f"data[{i}]:",data[i].shape)"""
#バッチ内の方向正解率
dir_acc_batch = np.mean(data[4])*100
strBatchCorrectRate = f"バッチ内 方向正解率:{dir_acc_batch:.1f}%"
print("ファイル:",targetFile)
print(strBatchCorrectRate)
#全データの方向正解率
all_predictions = net.predict(x_train_win)
total_accuracy = np.mean(np.sign(all_predictions) == np.sign(t_train_win))*100
print("ファイル:",targetFile)
print(f"全データ 方向正解率:{total_accuracy:3.3f}%")
# data[:, 1] が 0 でない場所だけ計算、0 の場合は 0 を代入(あるいは既存の値を維持)
#data[:,4] = np.where(data[:,1]!=0,data[:,3]/data[:,1]*100, 0)
#最終イテレーションでの損失値
loss = net.loss(x_batch, t_batch)
print(f"Iteration {itnumMax+1}: Loss={loss:.5f}")
#最終結果一覧
#print(data[0][:9]);print(data[1][:5]);print(data[2][:5]);print(data[3][:5])
print(" JPY変化率(3sets) 実日経変化率 予測日経変化率 差分 方向一致(1=Yes)")
idata = np.zeros((64, len(data)+2))
buf= np.array(data[0]).reshape(64,3)
idata[:,0] = buf[:,0]
idata[:,1] = buf[:,1]
idata[:,2] = buf[:,2]
idata[:,3] = np.array(data[1])
idata[:,4] = np.array(data[2])
idata[:,5] = np.array(data[3])
idata[:,6] = np.array(data[4])
print(idata)
#グラフ表示
avr = np.mean(train_loss_list)
min = np.min(train_loss_list)
print("iterNumMax ",itnumMax)
x = np.arange(itnumMax/100)
print("x ",x[:3])
print("x ",x[-3:])
print("train_loss_list size ", len(train_loss_list))
plt.rcParams['font.family'] = 'MS Gothic'
fig,(ax1,ax2) = plt.subplots(1,2, figsize=(12,5), gridspec_kw={'width_ratios':[2,1]})
ax1.set_title(f"2日変化率を{WINDOW_SIZE}個セット スライドウィンド変化率で推論した場合のloss値の推移")
ax1.set_xlabel("iteration")
ax1.set_ylabel("loss")
ax1.plot(x*100, train_loss_list)
#one input line
ax1.axhline(32, xmin=0, xmax=1, color='green', linestyle='--',label=f'single average:{32}')
ax1.text(0, 32+2, f'simgleAvr:{32.0:3.3f}', color='green',fontsize=13,fontweight='bold')
#five input line mean
ax1.axhline(avr, xmin=0, xmax=1, color='red', linestyle='--',label=f'WINDOW_SIZE{WINDOW_SIZE} average:{avr}')
ax1.text(20000, avr+2, f'WS{WINDOW_SIZE}Avr:{avr:3.3f}',color='red',fontsize=13,fontweight='bold')
#five input line mini
ax1.axhline(min, xmin=0, xmax=1, color='pink', linestyle='--',label=f'WINDOW_SIZE{WINDOW_SIZE} min:{min}')
ax1.text(0, min+2, f'WS{WINDOW_SIZE}Min:{min:3.3f}', color='pink',fontsize=13,fontweight='bold')
ax1.legend()
ax2.axis('off') #xy軸の表示消去
ax2.text(0,0.5,strBatchCorrectRate,fontsize=12,va = 'top', ha='left', linespacing=2)
ax2.text(0,0.6,f"全データ方向正解率:{total_accuracy:3.3f}%",fontsize=12,va = 'top', ha='left', linespacing=2)
ax2.text(0,0.7,f"ファイル:{targetFile}")
plt.show()
#c言語の配列形式で、パラメータを出力するヘルパー関数
# 使う時にインデックスを計算する: W[i][j] -> W_flat[i * 2 + j]
def to_c_array(name, params):
print("//使う時にインデックスを計算する: W[i][j] -> W_flat[i * 2 + j]")
print(f"// {name} shape: {params.shape}")
print(f"const float {name}[] = {{")
flat_params = params.flatten() #1次元に平坦化
for i, val in enumerate(flat_params): #enumerate indexとvlueを返す
end = ","
if i == len(flat_params) -1: end = "" #最後の要素にカンマをつけない
print(f" {val:.8f}f{end}")#float型として出力
print("};")
print()
def to_c_array1(name,x):
print("//使う時にインデックスを計算する: X[i][j] -> X_flat[i * 2 + j]")
print(f"// {name} shape: {x.shape}")
print(f"float {name}[] = {{")
flat_params = x.flatten() #1次元に平坦化
for i, val in enumerate(flat_params): #enumerate indexとvlueを返す
end = ","
if i == len(flat_params) -1: end = "" #最後の要素にカンマをつけない
print(f" {val:.8f}f{end}")#float型として出力
print("};")
print()
print("// X_batch************************")
to_c_array1("val_"+"x_batch", x_batch)
print("// t_batch************************")
to_c_array1("val_"+"t_batch", t_batch)
# STM32用 コード整形出力
print("/* ============================================")
print(" * STM32 Neural Network Parameters")
print(" * Generated from Python")
print(" * ============================================ */")
print("#ifndef WEIGHTS_H")
print("#define WEIGHTS_H")
print()
# 1. 前処理・後処理用のパラメータ
print(f"// Standardization Parameters")
print(f"const float MEAN_JPY = {meanJPY_changeRate:.8f}f;")
print(f"const float STD_JPY = {stdJPY_changeRate:.8f}f;")
print(f"const float MEAN_NIKKEI = {meanNikkei_changeRate:.8f}f;")
print(f"const float STD_NIKKEI = {stdNikkei_changeRate:.8f}f;")
print()
# 2. 重みとバイアス (ヘルパー関数を使用)
for layer_idx,name in enumerate(net.paramsNameList):
print(f"// Layer {layer_idx+1} ({net.params[name[0]].shape[0]} -> {net.params[name[0]].shape[1]})")
to_c_array("val_"+name[0], net.params[name[0]])
to_c_array("val_"+name[1], net.params[name[1]])
# 3.入力データの表示
sample_input = x_train_win[0]
print(f"//Example Input (Past{len(sample_input)} days change rates")
to_c_array1("sample_input",sample_input)
# 4.日経リアルデータ
sample_pred = net.predict(sample_input.reshape(1,-1))
print(f"// Expected Output(Python Prediction): {sample_pred[0][0]:.8f}f")
print("#endif // WEIGHTS_H")