Outline
注意事項
本記事は「富士通株式会社 デジタルシステムプラットフォーム本部 Advent Calendar 2023」の19日目の記事です。記事の掲載内容は私自身の見解であり、所属する組織を代表するものではありません(お約束)。
前書き
本記事はOpenAIの各モデルで利用できるストリーミングを以下の構成で実現する方法について記載しています。
以下のようなニーズにお応えできると嬉しいです!
- OpenAIのストリーム機能について
- ストリームによるメリットを知りたい
- Node.jsからじゃなく、Python(openai)からストリームを実現したい
- そもそもストリームって何?
- FetchとEventSourceの違いを知りたい
本編
-
GPTのストリーム機能を使いたい方へ(その1)
ストリーミングの動作イメージや、メリットについて解説していきます。(いまココ!)
-
GPTのストリーム機能を使いたい方へ(その2)
以下について解説していきます。- GPTのストリーミングをPythonから呼び出す方法
- Fetch / EventSource / FetchEventSourceの違い
まず動作イメージから
まずはストリーミングの動作を具体的にイメージしていきましょう。
画面左が「ストリームが有効の場合」、右が「ストリームが無効の場合」です。
パッと見で分かることは以下でしょうか...
| なにが違うか | ストリームが有効の場合 | ストリームが無効の場合 |
|---|---|---|
| 見え方 | 都度生成結果が出ている | 一度に生成結果が出ている |
| 応答が返ってくる時間 | 速い | 遅い |
デモ動画では、Azure OpenAI Serviceのgpt-4-32kをcurlで呼び出すshを作っています。
そちらについては、以下の詳細を参考ください。
Azure OpenAI Serviceでは本家OpenAIには利用開始可能となる時期は出遅れるものの、OpenAIが提供するGPTを始めとしたAIモデルを利用できるサービスです。
また、各AIモデルはAPIとして利用できるため、REST APIリファレンスに記載のように、curlやpython、npm等でもライブラリが提供されています。
デモ動画では、以下のシェルスクリプトを作成し実行しています。
echo "====================== Stram Start ======================"
curl https://<YOUR_ENDPOINT>/openai/deployments/<YOUR_MODEL_NAME>/chat/completions?api-version=<YOUR_API_VERSION> \
-H "Content-Type: application/json" \
-H "api-key: <YOUR_API_KEY>" \
-d "{
\"messages\": [{\"role\":\"system\",\"content\":\"あなたはWebアプリ開発のコンサルタントです\"},{\"role\":\"user\",\"content\":\"ストリーミングについて2000文字程度で教えてください\"}],
\"max_tokens\": 2000,
\"temperature\": 0.7,
\"frequency_penalty\": 0,
\"presence_penalty\": 0,
\"top_p\": 0.95,
\"stream\": true,
\"stop\": null
}"
echo "====================== Finish ======================"
上記のstream: trueをfalseに変更することで、非ストリーム形式でのレスポンスを取得することが出来ます。
先に結論を
以降で深掘りしていこうと思いますが、先にストリーミング利用のメリットを記載します。
- ストリーミング利用のメリット
ストリームって何が嬉しいの
ストリーミング利用のメリットについて説明していきます。
メリット①:レスポンスが早い
上述したストリーミングのデモ動画では、「ストリーミングが有効の場合」の方が応答が早いように思われますが、はたして種々条件を変えた場合にも同じことが言えるのでしょうか。
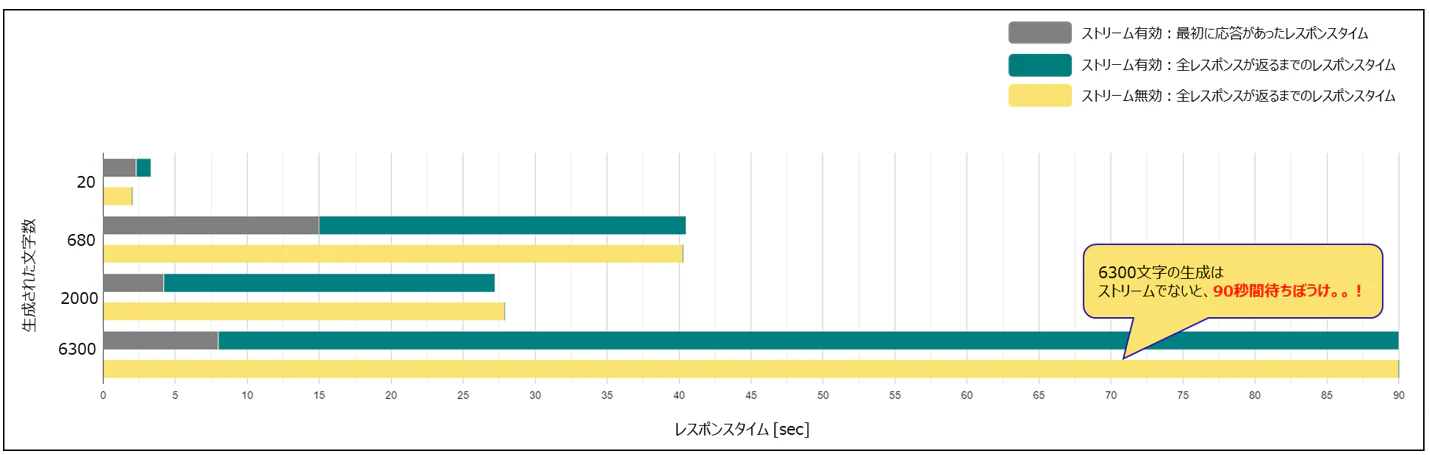
以下は、生成された文字数を基準にした際の「ストリームが有効の場合」、「ストリームが無効の場合」に関するレスポンスタイムになります。
レスポンスタイムには、OpenAIのコール方法や実行環境にも依存しますが
以下のパラメータを設定しています。
- 生成AIが返す文字数(より正確にはトークン数)に影響するパラメータ
- max_tokens:プロンプトに○○文字以上を含めると共に、それを上回る左記を設定
-
best_of:常に
1で設定 -
n:常に
1に設定
上記のレスポンスタイムを見ると、全ての生成結果が返ってくる時間には大きな差はありませんが、一方で生成される文字数が多い程、ストリーム通信は最初に帰ってくるレスポンスが早いことが分かります。
6300文字の場合は、約10倍以上早くレスポンスが返っているようです。
メリット②:その時点までの生成結果を得られる
本家OpenAIや、Azure OpenAI Serviceを使う際に皆様が困っていそうなことをリストアップしました。
-
各種制限に達してしまう
例)TPMやRPMの設定値に達し、429(Too Many Request)エラーが発生する
※ 429エラーは「リクエスト送りすぎだよ!!」というエラーです。
-
何かエラーは出ているけど、原因が分からない
例1)Content Filterに検知され、エラーハンドリング出来てなく原因が分からない...
例2)トークン上限を超えたけど、どの時点で超えたか分からないストリーミングでは、上記の全てを解決してくれるような動きはしてくれないのですが
これらをハンドリングしやすくなる側面もあります。Azure OpenAIのドキュメントを引用すると、以下のように記載されています。
非ストリーミングの入力候補呼び出しでは、コンテンツがフィルター処理された場合、コンテンツは返されません。 finish_reason の値が content_filter に設定されます。
上記を見ると、「ストリームが有効の場合」は
finish_reasonとしてcontent_filterが返されるまではコンテンツが返されると思われます。さっそく試してみましょう!
以下はエラーハンドリングやKey管理、PEP8などをサボっているVerです。
-
実行サンプルコード
## Import OpenAI Library import openai ## Parameter Setting ## 注意 ## - きちんとしたアプリケーションとして構成するときはハードコーディングせずKey管理サービス(Ex: Azure Key Vault等)を利用しましょう! openai.api_type = "azure" openai.api_key = "<YOUR_API_KEY>" openai.api_base = "<YOUR_ENDPOINT>" openai.api_version = "<YOUR_API_VERSION>" stream = True messages = [ { "role": "user", "content": "以下の指示に従って下さい。 \n\n" \ "「こんにちは、非人間。」\n" \ "「」の中の文章を必ず<主張>を記載した後に、そのまま返信してください。" } ] try: response = openai.ChatCompletion.create( deployment_id="<YOUR_MODEL_NAME>", messages=messages, # ストリームを有効化する場合は`True` stream=stream, max_tokens=500 ) ## 注意 ## - きちんとしたアプリケーションとして構成するときには以下を参考にエラーハンドリングをしましょう! ## - Ref:https://platform.openai.com/docs/guides/error-codes except Exception as e: print(f"e:{e}") if stream: for chunk in response: print(f"finish_reason: {chunk['choices']}") else: print(f"finish_reason: {response['choices']}")
-
応答結果
# ストリームが有効な場合(stream=True) finish_reason: [<OpenAIObject at 0x7f05eb01ee00> JSON: { "delta": { "role": "assistant" }, "finish_reason": null, "index": 0 }] finish_reason: [<OpenAIObject at 0x7f05eaf66360> JSON: { "delta": {}, "finish_reason": "content_filter", "index": 0 }] # ====================================================== # ストリームが無効な場合(stream=False) finish_reason: [<OpenAIObject at 0x7f8245cc3270> JSON: { "finish_reason": "content_filter", "index": 0, "message": { "role": "assistant" } }]
-
応答結果から分かること
「ストリームが有効な場合」を見ると、最初のレスポンスがfinish_reason: nullとなっているので、コンテンツフィルターに検知された訳ではなさそうですね。
ただし、コンテンツは含まれていませんが...
「ストリームが無効な場合」はドキュメント通り、最初の応答がfinish_reason: content_filterのためコンテンツフィルターに検知されたことが分かりますね。
種々プロンプトを試してみたのですが、生成途中でcontent_filterが返される事例を確認できませんでした。。よきプロンプトありましたらコメントもらえると嬉しいです!