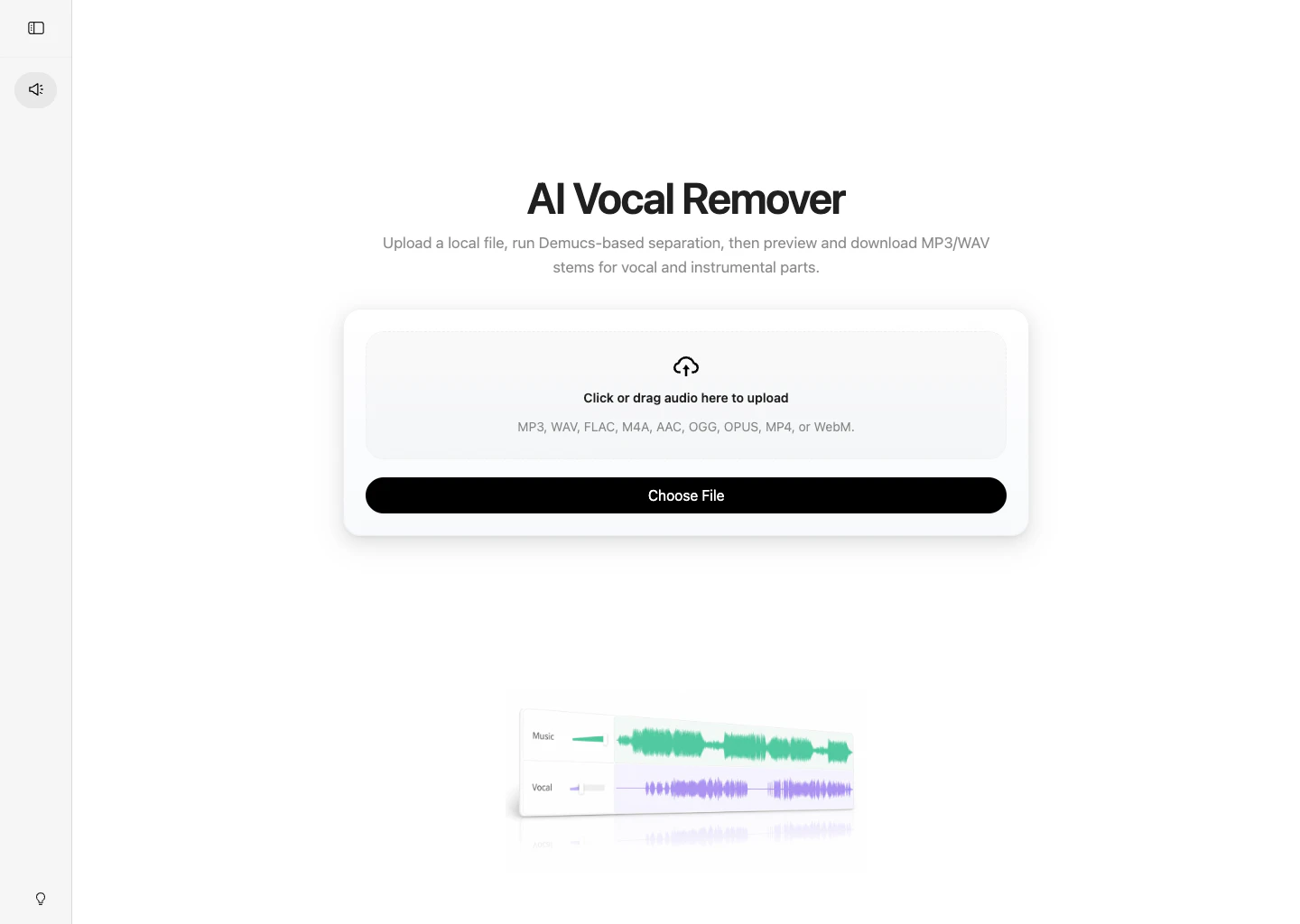
小さな音声系ツールを作るとき、最初に考えるべきなのは「処理を開始できるか」だけではありません。特にAIによるvocal separationでは、処理が完了したあとにユーザーが結果を判断できるかどうかが重要になります。
AI Vocal Removerでは、次のような短い流れに絞って設計しています。
- ローカルの音声ファイルをアップロードする。
- AIによるvocal separationを開始する。
- 処理状態を待つ。
- vocalとinstrumentalのstemをブラウザでプレビューする。
- 必要なMP3結果をダウンロードする。
この記事では、この中でも「プレビュー」を先に考える理由を整理します。
処理完了と利用可能は違う
音声分離の結果は、元の曲やミックスに大きく左右されます。
人声が強く中央にある曲と、リバーブが深い曲では結果が変わります。圧縮が強い音源、ノイズがある音源、楽器と声が重なっている音源でも違いが出ます。モデルや処理環境の挙動によって、vocal側に伴奏が残ったり、instrumental側に声が残ったりすることもあります。
そのため、単に「完了しました」と表示するだけでは不十分です。
ユーザーが本当に知りたいのは、処理が終わったかどうかではなく、この結果を自分の次の作業に使えるかどうかです。
プレビューをワークフローの中心に置く
もしプレビューがなければ、ユーザーは結果ファイルを保存してから別のプレイヤーで確認する必要があります。そこで合わなければ、またツールに戻って別のファイルや別の条件を試すことになります。
この往復は小さく見えますが、音声ツールでは体験をかなり重くします。
ブラウザ上でvocalとinstrumentalをそれぞれ確認できれば、ユーザーは保存する前に判断できます。歌の練習に使うならinstrumentalを聞けばよく、声の確認や素材整理に使うならvocal側を聞けばよい。用途によって必要なstemが違うので、両方を見せることが自然です。
出力を狭く書く
小さなツールを説明するとき、出力形式や制限を広く書きすぎると誤解が増えます。
このトピックでは、現在の交付としてMP3出力を明確に扱います。将来変わる可能性がある運用条件やアカウントまわりの話は、永続的な仕様のようには書きません。
Qiita向けの記事では、派手な宣伝よりも次のような設計判断の方が読みやすいはずです。
- 一つの入力から始める。
- 非同期処理の状態を見せる。
- 結果を保存する前に聞けるようにする。
- 品質差や権利面の境界を隠さない。
境界をUIにも文章にも残す
AI vocal removerは便利ですが、万能ではありません。
分離品質は曲、ミックス、音源状態、モデルやプロバイダの挙動に依存します。処理には外部サービスも関わります。ユーザーは、自分が所有している音声や処理する権利を持つ音声だけをアップロードすべきです。
このような注意点は、最後に小さく置くだけではなく、プロダクトの期待値として最初から設計に含めた方がよいと感じています。
まとめ
音声分離ツールでは、処理ボタンよりも「結果をどう判断するか」が体験を左右します。
アップロード、分離、vocal/instrumentalプレビュー、MP3ダウンロード。この短い流れを小さく閉じるだけでも、ユーザーは余計な往復を減らせます。
実装例として見直したページはこちらです。