
この記事は、架空の大学「圏峰(けんぽう)工科大学」の研究室を舞台にした、ひとつの対話篇です。
登場するのは、機械学習のコードは日々書いているけれど、圏論はまだ専門的には学んでいない学部生と、圏論・経済学・機械学習の応用を専門とする若手専任講師のふたりです。
この記事は、(初回)「圏論はゲーム理論を書き換える(Compositional Game Theory 入門)」、(続編)「圏論でORを組み立て直す(Compositional Optimization 入門)」に続く、3部作シリーズの最終回にあたる記事です、
前回と前々回の記事をまだお読みでない方にも、この記事を単独でお読みいただけるように執筆致しました。過去の記事については、本作の必要な場面の中で振り返るように書きました。
作中、登場する人物や大学はフィクションですが、とり扱う内容(理論・論文・実装)は、すべて実在する理論と研究です。出典は、この記事の末尾にまとめました。
想定読者は、
PyTorchやTensorFlowで深層学習のコードは書いているけれど、その裏側の数学は、正直、雰囲気で流している ── そんなエンジニア・データサイエンティスト・機械学習エンジニア・AI Research Scientistの皆様です。難しい専門用語や数学用語は、すべて初出の段階でかみくだいて説明します。
数式が出てきても、読み飛ばしていただいて差し支えありません。
想定読者
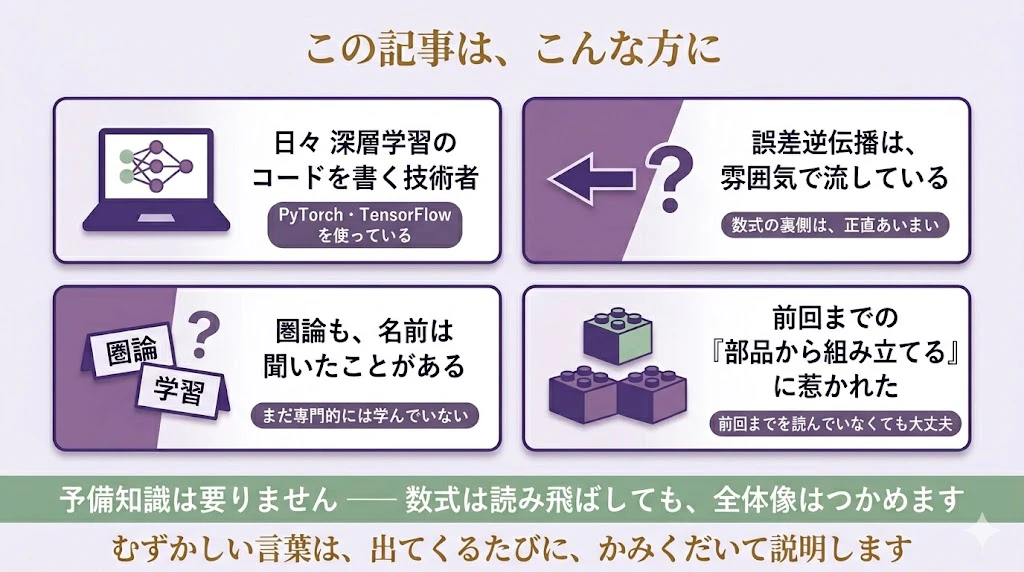
- 日々
PyTorchやTensorFlowで深層学習のコードを書いているエンジニア・データサイエンティスト・機械学習エンジニア・AI Research Scientist
-
loss.backward()と書けば学習が進むことは知っているけれど、その裏で何が起きているのかは、正直、雰囲気で流している方
-
圏論も、応用圏論も、名前は聞いたことがあるが、いずれもまだ専門的には学んだことがない方
- 前々回の「合成的ゲーム理論」や、前回の「合成的最適化(OR)」の対話篇をお読みになり、「部品から組み立てる」という発想が、いよいよ機械学習そのものに及ぶことに、興味を持たれた方(前の2回を読んでいなくても、問題ありません)
数学やアルゴリズムの予備知識は、前提にしていません。
難しい専門用語や数学用語は、高校数学の復習となる程度から、丁寧にかみくだいて説明いたします。
数式や圏論の記号が出てきても、読み飛ばしていただいて、この記事の全体像はつかんでいただけるように執筆しました。
この記事を読むことで得られること(この記事を読む価値)

-
誤差逆伝播(backpropagation)の”正体”が腑に落ちます。
loss.backward()の裏で、いったい何が起きているのか。「予測が前へ流れ、誤差が後ろへ還ってくる」という往復の構造が、なぜ学習の核心なのかが、見えてきます。
-
大きなモデルを、いったん「部品」に分解し、その「部品」から「組み立てる」というアプローチが、なぜ機械学習にも有効なのか ── このことを、エンジニアの皆様に馴染み深い感覚(モジュール化・関数合成)に引きつけて理解できます。
-
「レンズ(lens)」「Para」「学習器(learner)」「関手」 といった、難しそうな専門用語が何を意味するのかを、双方向のパイプや、工場の組み立てラインの比喩を通してつかんでいただけます。
-
モデルを部品から組み立て、その学習のさせ方まで自動的に決まるという最先端の研究を、具体例(
MNISTの手書き数字分類・画像変換モデルCycleGAN)を、実装コードを交えて、ひも解いてイメージをつかむ ことができます。
- 前々回の 「ゲーム理論」、前回の 「OR・最適化」、そして今回の 「機械学習」 というテーマが、「部品から組み立てる」「構造を保つ変換」「不動点」「双方向のやりとり」 という、共通の言葉でつながっていること ── そして驚くべきことに、学習とゲームが、数学的にひとつにつながることが、一枚の地図として見えてきます。
- モデルを「数学的に厳密な部品」から組み立てられる、という性質が、なぜ AI の安全性につながるのかが見えてきます。無人運転車や、生活空間へ進出する各種ロボット(Physical AI)のように「絶対に間違えてはいけない」場面で、巨大な AI の振る舞いを形式的に検証し、安全性を担保するための土台に、この「合成的な厳密さ」がなりうるという展望が得られます。AIモデルを実装し、デプロイ後のパフォーマンスを継続監視する仕事を担われているエンジニアの方々にとって、「作る技術」が「安全性を検証する技術」へとつながる、その地続きの道筋 が見えてきます。
なお、この記事で取り上げる技術は、2020年代の現在では、「すでに産業界で広く使われている技術」ではなく、「研究の最前線」です。
そのため、AIテクノロジー研究の最前線の現在地点をおさえる ことができます。
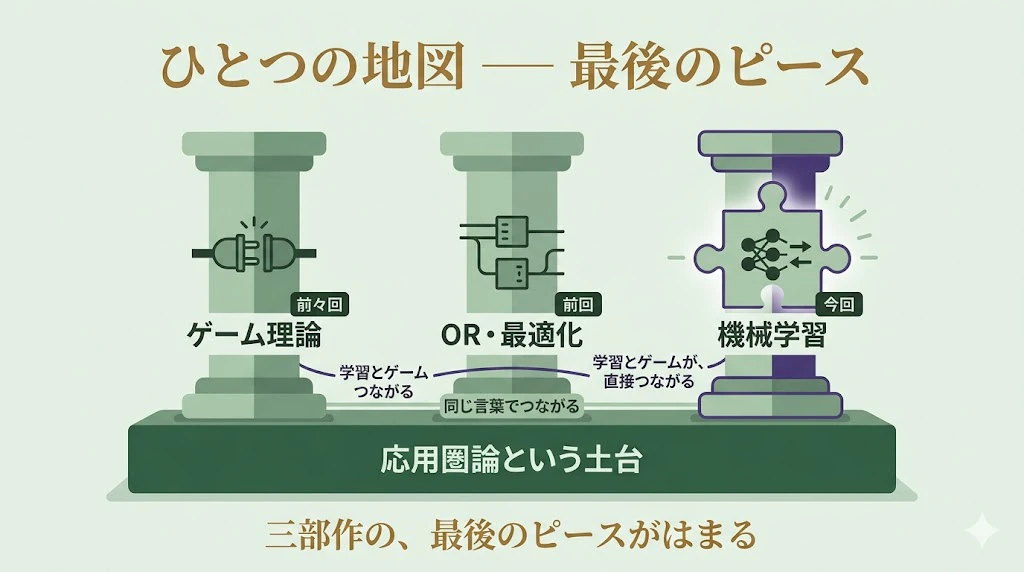
ひとつの地図 ── 3部作の、最後のピース
その「一枚の地図」を、ここで先取りしてお見せします。
前々回の ゲーム理論、前回の OR・最適化、そして今回の 機械学習
── これらは本来、まったく異なる別々の分野のはずです。
ところが、応用圏論という舞台の上では、「部品から組み立てる」「構造を保つ変換」「不動点」 という、同じ言葉で 語られはじめている。
これが、3部作を貫く風景 でした。
今回、その地図に、最後のピース がはまります。
お届けするのは、「学習も同じ言葉で書ける」というひとつの事実に留まるもののではありません。
この記事が皆さまにお伝えするのは、
- 学習とゲームが、関手という橋で、直接つながる。
- 教師あり学習のニューラルネットワークは、ある意味で、「ゲーム」として 見ることができる
そんな、景色なのです。
ここでいう「ゲーム」とは、前々回(合成的ゲーム理論)で扱った ゲーム理論の意味での「ゲーム」 です。
プレイヤーがいて、戦略を選び、利得を評価する、あの 「開いたゲーム(open game)」 を指します。前回の記事で、OR・最適化に出てきた最適化問題のことではありません。
本作では、3部作のこれまでの記事にちりばめた伏線を回収する結末で、締めくくられます。
▼ 画像生成プロンプト(ひとつの地図・先取り)
なお、この地図は、いまはまだ「予告」に過ぎません。
この記事を読み終えてくださったとき、末尾の 「まとめ ── 完成した『ひとつの地図』」 で、同じ地図 に、今度は、皆様と一緒に学んだきたキーワード( レンズ・Para・学習器・関手 )が書き込まれた完成版の地図と再会する場面が皆さまを、静かに待っています。
いまは輪郭だけ、頭の隅に置いておいていただけますと幸いです。
TL;DR(最初に、結論だけ)

機械学習の「学習」── とくに誤差逆伝播(backpropagation)── を、圏論の言葉で「部品から組み立て直す」 研究が、応用圏論 という研究領域で進んでいます。
その出発点が、Backprop as Functor(Fong–Spivak–Tuyéras, 2019)という論文です。ここでの主張を、ひとことで言えば、こうです。
ニューラルネットの各層のような 「部品」 を、順伝播(予測を前へ送る)と逆伝播(誤差を後ろへ返す)の両方を持つ、双方向の部品として表す。
その部品どうしを、配線図のようにつなぐと、大きなモデルになる。
そして ── 勾配降下による「学習のさせ方」は、部品を組み立てた構造から、自動的に決まる。
これを、「学習とは、構造を保つ変換(関手)である」と言い表したのが、この論文のタイトル「Backprop as Functor(関手としての誤差逆伝播)」に込められた意味です。
この枠組みには 動く実装 があります。
なお、この実装は、後続の Cruttwellらによるパラメトリック・レンズの枠組み(Categorical Foundations of Gradient-Based Learning, 2021 / Deep Learning with Parametric Lenses, 2024)にもとづく Python ライブラリです。
本記事の第6幕で扱う論文「Backprop as Functor」(Fong–Spivak–Tuyéras, 2019)そのものの実装ではありません。
両者は地続きで、前者が築いた理論的な土台(学習器の圏と勾配降下の関手)を、後者が実装可能な形に展開したもの、という関係にあります。
上記のGitHubリポジトリは、Python のライブラリとして公開され、手書き数字認識(MNIST)のモデルを、層を >>(直列)と @(並列)でつなぐだけで組み立て、実際に学習させることができる実装コードになります。
そして三部作の最終回として ── この「学習」が、前々回の「ゲーム理論」と、関手という橋で直接つながるところまでをお見せします。これが、この記事のゴールです。
序章 ── 「backward() って、結局なにをしているの?」
圏峰工科大学、夕暮れの研究室。学部生が、ノートパソコンの画面を見つめながら、ため息をついている。
学部生:
先生。僕、深層学習のコードは、もう何十回も書いてきました。
PyTorch で層を積んで、loss.backward() と書けば、ちゃんと学習が進む。
動くんです。動くんですが ──
講師:
が?
学部生:
その backward() の中で、いったい何が起きているのか、正直、雰囲気でしか分かっていないんです。
「誤差を逆伝播して、勾配で重みを更新している」
── 言葉としては言える。
でも、なぜそれを「逆向き」にやるのか、その逆向きの計算が、層をまたいで、どうしてきれいにつながるのか
── そこが、もやっとしたままで。
講師:
良い”もやもや”を抱えているね。
そして、ちょうどいい。
今日は、その backward() の中身を、圏論という道具で、ひらいてみよう。
すると、不思議なことが起きる。
「学習」という行為そのものが、君がよく知っている「部品をつないで組み立てる」という話に、すっぽり収まるんだ。
前々回は ゲーム理論 を、前回は OR を、その発想で組み立て直した。
今日は、いよいよ ── 機械学習そのものを、圏論の言葉で組み立てなおしてみよう。
学部生:
学習を、部品から組み立てる……。
前回までと、同じ地図の上にある んですね。
講師:
そういうことだ。
しかも今日は、3部作の最終回。
最後に、とっておきの再会が待っている。
── まずは、足元から固めていこう。
第1幕 ── そもそも「学習」とは何をすることか
講師:
まず、いちばん素朴なところから始めよう。
機械学習の「学習」 とは、いったい何をすることだろうか。
学部生:
データを与えると、モデルが、だんだん賢くなる……ことですよね??
講師:
おおむね、それでいい。
だが、もう少し解剖してみよう。
前回、ORの「最適化」 を、3つの部品に分けたのを覚えているかな?
変数・制約・目的関数の3つ だ。
実は、「学習」も、似たように分解できる。
教師あり学習を、4つの部品 に分けてみよう。
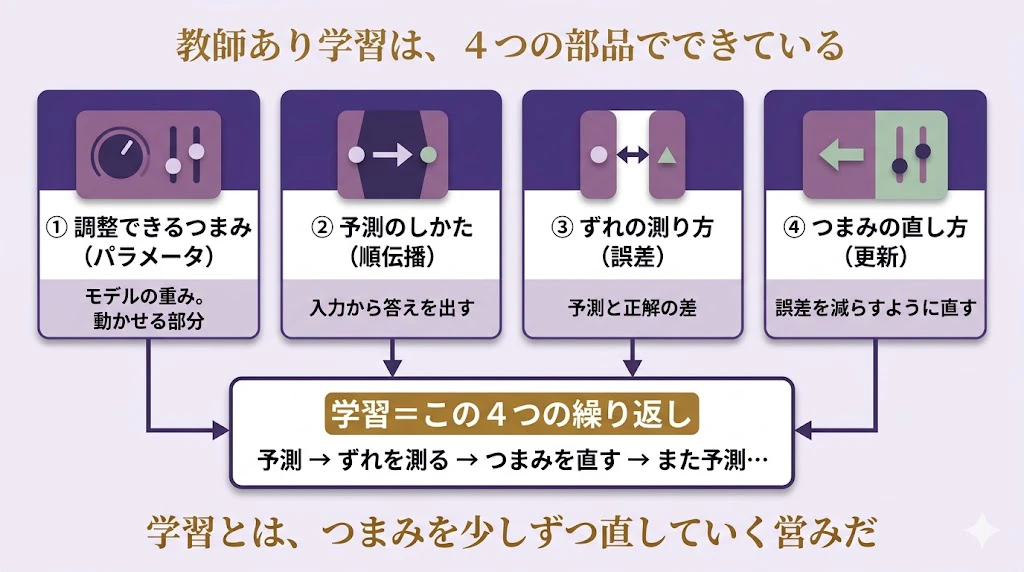
講師:
順に見ていこう。
① 調整できるつまみ(パラメータ)。
モデルには、動かせる「つまみ」がたくさんある。ニューラルネットで言えば、重み(weight)だ。学習とは、結局、このつまみを、いい具合に回していくことに尽きる。
② 予測のしかた(順伝播)。
つまみをある値に設定したとき、入力を受け取って、答え(予測)を出す。入力が前から後ろへ流れていくので、**順伝播(forward)**と呼ぶ。
PyTorch の forward() メソッド、あのものだ。
③ ずれの測り方(誤差)。
出てきた予測が、正解と、どれだけズレているか。
これを測るのが、誤差関数(損失関数)だ。
④ つまみの直し方(更新)。
ズレの大きさが分かったら、それを減らすように、つまみを少し回す。
この「直し方」が、学習の心臓部 だ。
学部生:
予測して、ずれを測って、つまみを直す。
それを、ひたすら繰り返す ── それが 学習だ、と。
講師:
そのとおり。
さて、ここで問題になるのが、④の「つまみの直し方」だ。
モデルが小さいうちは、まだいい。
だが、層を何十段も重ねた深いネットワークだと
── 「いちばん奥の層のつまみを、どっちにどれだけ回せば、最終的な誤差が減るのか」を、どうやって知ればいいと思う?
学部生:
そこで……誤差逆伝播、ですか。
講師:
そうなんだ。
誤差を、出口から入口へと、逆向きに伝えていく。
これが、今日の主役のひとつだ。
なぜ「逆向き」なのかは、 次の対話(幕)で、その必然性を、絵に描いて眺めて見てみよう。
第2幕 ── なぜ「逆向き」なのか:予測は前へ、誤差は後ろへ

講師:
まず、上の絵を見てみてほしい。
入力が、層を通って、前へ前へと流れ、最後に予測が出る。
これが、順伝播 だ。
出口で、正解とのズレ(誤差)を測る。
問題は、そのズレの責任を、どの層のつまみが、どれだけ負っているかだ。
出口に近い層は、まだ分かりやすい。
だが、入口に近い奥の層は、出口から遠い。
その奥のつまみが、最終的な誤差にどう効いているのだろう?
── これを知るためには、誤差を、出口から入口へ、逆向きにたどっていくしかない。
学部生:
川の流れでたとえると
── 順伝播は上流から下流へ水を流すこと。
逆伝播は、下流で測った「濁り(誤差)」が、どの支流から来たのか を、上流へさかのぼって突き止めること、でしょうか。
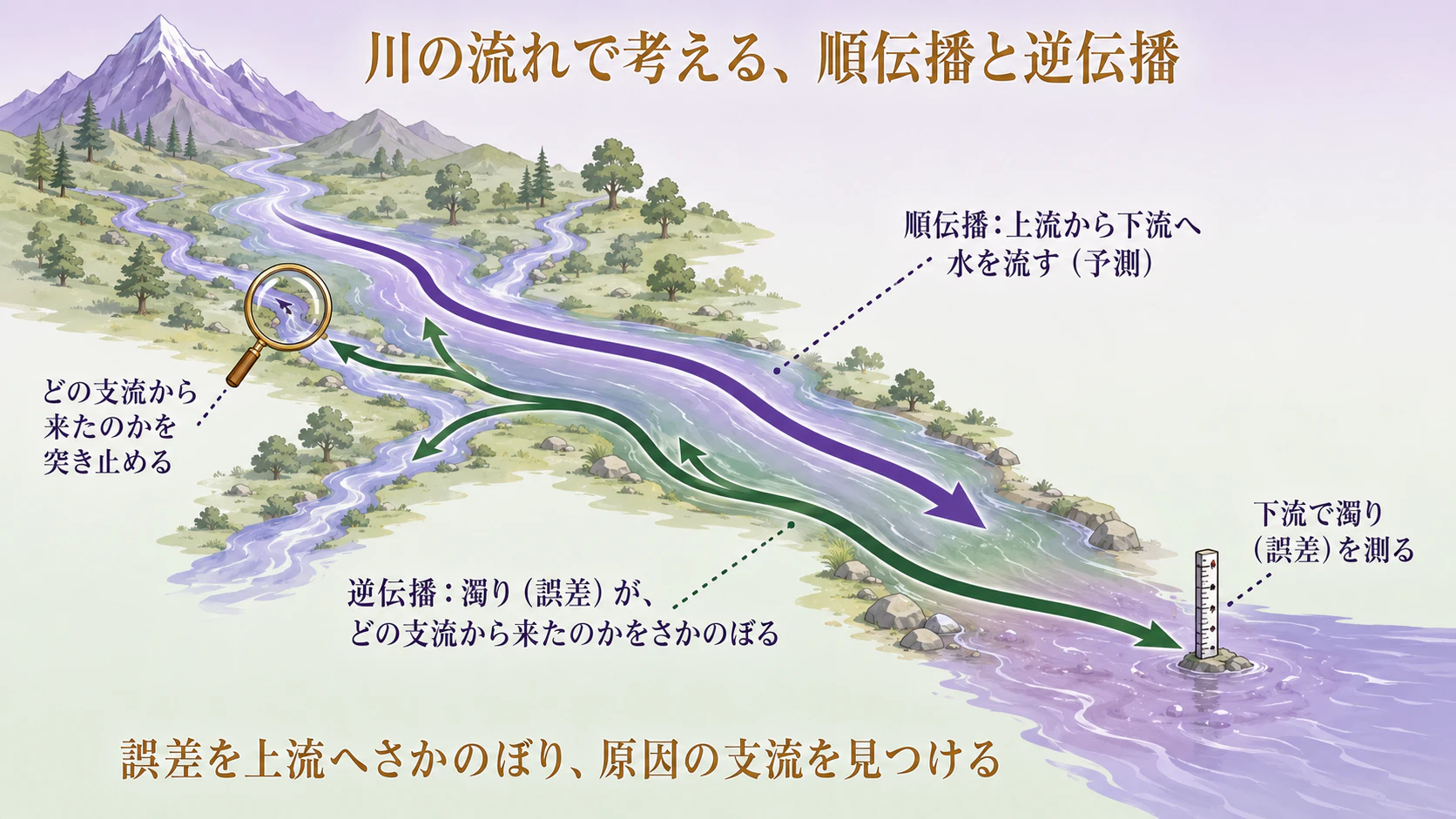
講師:
見事なたとえだ。まさにそれだ。
そして、ここからが今日の核心になる。
この「前へ予測、後ろへ誤差」という往復の構造こそが、実は、圏論できれいに書けるんだ。
学部生:
圏論で?
なぜここで、圏論 が登場するんですか?
講師:
その理由はね、
順方向と逆方向の、ふたつの向きを同時に持つ部品。
それを、数学では、すでに名前をつけて研究してきたからだ。
その名前を、レンズ(lens) という。
学部生:
レンズ……。カメラの、あのレンズですか?
講師:
名前は同じだが、中身は別物だ。次の幕で、その「双方向の部品=レンズ」を、ていねいに見ていこう。ここが、今日いちばん大事なところだ。
第3幕 ── レンズ:双方向の部品
講師:
レンズ(lens)とは、ひとことで言えば、「行き」と「帰り」の、ふたつの向きをセットで持った部品だ。

講師:
身近なたとえで言おう。会社の、ある部署を想像してほしい。
**行き(順方向)**は、上流の部署から材料を受け取って、加工して、下流の部署へ渡す仕事だ。これは、ふつうの「処理の流れ」だね。
帰り(逆方向)は、こうだ。下流から「この製品、ここがダメだった」というクレーム(誤差)が返ってくる。すると部署は、それを受けて、「では、上流からは、本当はこういう材料が欲しかった」という注文を、上流へ返す。
レンズは、この「行きの加工」と「帰りの注文返し」を、ひとつの部品にまとめて持っている。
これが、双方向の部品 ということだ。
学部生:
なるほど。
順伝播が「行きの加工」、
逆伝播が「帰りのクレームと注文返し」。
それを、層ごとに、ひとつの部品として まとめて持っている、と。
あ、そういえば。
いまスマホで LLM に、「圏論で『レンズ』って言葉はある?」と聞いてみたんです。
そうしたら、Lens というスペルで、以下のURLを含む解説文が返されてきました。
これ、先生がいま説明してくださっている「双方向の部品」と、同じものなんでしょうか?
講師:
お、いい引き方をしたね。しかも今回は、その LLM の答え、当たりだ。
ひとつ褒めておきたい。君が、返ってきたURLを、ちゃんと自分で開いて確かめようとしていることだ。
LLMは、それらしいリンクを、中身のないまま自信たっぷりに並べることがある。
「URLが実在するか」「そのページが本当にそう言っているか」を確かめる癖は、これからますます大事になる。
今回のふたつは、どちらも実在して、中身も正確だ。
ひとつ目の nLabのページ は、いままさに話している、計算機科学・圏論での「レンズ」の標準的な解説だ。
データ構造の一部を「読む」操作と「書き換える」操作を、ひと組の部品にしたもの。
すでに会話の中に出てきた 双方向の部品、あれの正式な居場所 だね。
ふたつ目の arXivの論文 は、今日の話の先取りになっていて、面白い。
レンズと、「学習器(learner)」と呼ばれるものが、じつは同じモノイダル圏の射として、忠実な関手で結びつく、ということを示した仕事 だ。
「学習器」という言葉は、まだ出していなかったね。
だが、君がいま自分で引き当てたこのリンクが、このあと第5幕で扱う「学習する部品の圏(Learn 圏)」への、ちょうど入り口になっている。
偶然にしては、よく掘り当てたものだよ。
学部生:
いまここでやりとりしている、多層(深層)ニューラルネットワークのモデルを、圏論の枠組みで捉えるこの視座は、ごく一部の圏論研究コミュニティの中だけで行われていることなんでしょうか?
それとも、まだニッチな分野ではあるけれど、AIアルゴリズムの研究者たちの世界でも、徐々に、この視界を視野に入れはじめている人が増えているんでしょうか?
とても専門的なので、AIの世界で、どれくらいメジャーな議論なのか、今後の成長株のテーマなのか、肌感を知っておきたいんです。
……と思って、LLM と会話していたら、日本人の方で、圏論についての記事を数多くZennに書かれている方が、Lens の具体例を解説してくださっているのを見つけました。
しかも、具体例のひとつに、「例3:ニューラルネットワーク」も出てくるんです。
講師:
肌感、という聞き方がいいね。正直に答えよう。
まず、規模で言えば、これはまだニッチだ。
AIの研究の主流は、圧倒的に、性能を競う実験的な深層学習であって、それを圏論で捉え直す人は、世界でもまだ少数だ。
だが、「ごく一部の純粋な圏論コミュニティの中だけ」という段階は、もう過ぎている。
理由は、前回までに見たとおりだ。
この見方は、機械学習だけの孤立した趣味ではなく、ゲーム理論、最適化、制御、強化学習までを、同じ「双方向の部品」で貫こうとする、応用圏論という、ひとつの生きた研究の流れの一部なんだ。
実装ライブラリが公開され、国際会議が毎年開かれ、企業の研究者も少しずつ顔を出しはじめている。
その国際会議が、応用圏論国際会議( Applied Category Theory、通称 ACT )だ。2018年から毎年ひらかれていて、2026年はエストニアのタリンで第9回目になる。

学部生:
開催地のタリンって、もしかして、サイバー攻撃を国際法上どう扱うかを、研究者レベルで集めて書いた、あの『タリン・マニュアル(Tallinn Manual)』の、タリンですか?
たしか、NATOのサイバー防衛の研究拠点(CCDCOE)も、タリンにあった気がします。
応用圏論の国際会議が、その同じタリンでひらかれるということは。もともとエストニアのなかでも、タリンという街が、学術や知の集まりやすい土地、ということなんでしょうか。
講師:
よく気づいたね。そのタリンだ。
NATOのサイバー防衛協力センター(CCDCOE)がタリンにあって、『タリン・マニュアル』も、そこが旗を振ってまとめられた。
ただ、ひとつだけ補っておくと、街そのものが特別というより、エストニアという国が、行政も選挙もデジタルで動かす「電子国家」として知られていて、数学や計算機科学の層が厚い。
応用圏論の会議 がここで開かれるのも、その土壌と無縁ではない、というくらいの話だね。
今日の本筋からは少し外れるが、覚えておくと面白い符合だよ。
学部生:
その他の開催地は、アメリカとイギリスが、続いていますね。
東京も、大阪も、京都もない。上海も、ニューデリーも、ムンバイもない。シンガポールも、シドニーも、メルボルンも、ブラジルも、ないです。
講師:
よく見ているね。そのとおりだ。いまの応用圏論は、研究人口の中心が、ヨーロッパと北アメリカにある。会議の開催地が、その分布を、そのまま映しているんだ。
少し、地図を描いてみよう。
イギリスが、ひとつの核だ。スコットランドのストラスクライド大学には、まさに今日の主役のひとり、Jules Hedges がいる。学習とゲームをつなぐ、あの仕事の人だね。エディンバラ大学にも、量子と圏論の研究者がいる。
アメリカも厚い。カリフォルニアの Topos Institute という研究所が、応用圏論のソフトウェアづくりの拠点になっていて、大学では、フロリダ大学やカリフォルニア工科大学などに、人がいる。
そして、いま会議がひらかれるエストニアのタリン。じつは、ここ数年で、タリン工科大学が、ヨーロッパの新しい一大拠点になった。Pawel Sobocinski が率いる「合成的システム」の研究グループがあって、レンズや双圏の研究者が、世界中から集まってきている。今回の開催地がタリンなのは、偶然ではないんだ。
ほかにも、点々とある。イタリアのボローニャ、フランスのパリ、ドイツ、ポルトガル、セルビア。ヨーロッパに、小さな灯が、いくつも散らばっている。
学部生:
やっぱり、アジアは ──
講師:
そこなんだ。
東アジアには、まだ、応用圏論の大きな拠点が、はっきりとは育っていない。
ただ、ひとつ、面白い例外 がある。
オーストラリア だ。
シドニーのマッコーリー大学には、古くから 「オーストラリア圏論センター」( Centre of Australian Category Theory (CoACT), Macquarie University )があって、レンズの理論などで、世界的な仕事をしてきた。
リンクを、ふたつ置いておこう。
ひとつ目が、大学の研究拠点としての公式ページ。
ふたつ目が、いまも毎週ひらかれている「オーストラリア圏論セミナー」 の案内だ。
すでに半世紀ちかく続く歴史を歩んできた研究拠点だということが、見てとれるよ。
このオーストラリアの研究拠点があるので、アジア太平洋が、応用圏論研究のまったくの空白地帯というわけではない。
だが、君が並べてくれた東京も、大阪も、京都も、上海も、ムンバイも、シンガポールも
── この地図には、まだ載っていない。
学部生:
白いままの場所が、まだ、たくさんある。
講師:
そういうことだ。
そして、それは悪い話じゃない。
この分野は、まだ若くて、世界じゅうに広がりきってはいない、研究の最前線なんだ。
逆に言えば、地図の大半が、まだ白いまま残されている。そこに、これから描き足していく人が要る。
たとえば、日本語で、この景色を書く人が。さっき君が見つけた、あのZennの記事たちのようにね。
学部生:
オーストラリアは、英連邦の一部ですからね。アメリカとイギリスの、英米文化圏が、圏論の中心なんでしょうか。
もっとも、イタリアやフランス、ドイツ、ポルトガルといった、ラテン系やゲルマン系の国にも、旧東欧圏にまで、研究拠点が「点々と」生まれているようですから、英米圏だけに閉じたコミュニティ、というわけでもなさそうですが。
そもそも、圏論の発祥は、イギリスだったんでしたか?
講師:
いや、そこは、よくある誤解だ。
圏論が生まれたのは、イギリスじゃない。アメリカなんだ。
1945年、Samuel Eilenberg と Saunders Mac Lane という2人が、「自然変換の一般理論」という論文を発表した。これが、圏論の出発点だ。
圏も、関手も、自然変換も、この1本の論文で、いっぺんに世に出た。発表の舞台は、アメリカ数学会だった。
ただ
── ここが面白いんだが、生みの親の2人を見ると、純粋な「英米」とも言い切れない。
Eilenberg はポーランドの出身で、1930年代のポーランド数学の土壌で育った人だ。
Mac Lane はアメリカ人だが、若いころ、ドイツのゲッティンゲンに留学している。
当時の数学の中心地のひとつだね。
学部生:
最初から、国をまたいで生まれていたんですね。
講師:
そういうことだ。
圏論そのものは、20世紀なかばのアメリカで生まれ、その後、世界じゅうの純粋数学に広がった。
そして、いま僕らが見ている 「応用」圏論 ── 圏論を、機械学習やゲームや物理に使おうという、この新しい波 ── は、2010年代の後半になって、ようやく形になってきた。まだ、10年も経っていない。
だから、いまの研究拠点の分布は、「英米が偉い」という話ではないんだ。
たまたま、この新しい波の口火を切った人たち
── Fong や Spivak はアメリカ、Hedges はイギリス ──
が、英語圏にいた。
その縁(えん)で、初期のコミュニティが、英語圏とヨーロッパに広がった。
学部生:
え??
圏論を数学以外の領域に「応用」され始めたのは、たかだかこの10年間なのですか?
なにか、きっかけはあったのでしょうか?
講師:
正確に言い分けよう。
「圏論を、数学の外に応用する」試みそのものは、もっと古い。
たとえば、2000年代から、Bob Coecke という人が、圏論で量子力学を書き直していた。じつは、それを、そのまま自然言語の意味の計算に転用したのが、このシリーズの別の回で扱った量子と言語の話 ── あの系譜だ。
物理のほうでも、John Baez という人が、ずっと前から、圏論を物理や工学に使う活動を続けていた。
だから、「応用」の試み自体は、点々と、前からあった。
変わったのは、2010年代の後半だ。
それまで、ばらばらに行われていた「圏論を、現実の何かに使う」という試みが、ひとつの名前のもとに、束ねられた。
その名前が、**応用圏論(applied category theory)**だ。
学部生:
名前がついて、ばらばらだったものが、ひとつの分野になった。
講師:
そう。そして、その合図になった出来事が、いくつかある。
ひとつは、2018年に、Fong と Spivak
── 今日の主役、Backprop as Functor の著者たちだね ── が、一冊の本を出したこと だ。
Seven Sketches in Compositionality、副題が、ずばり 「応用圏論への招待」 。
MITの講義をもとにした、予備知識なしで読める入門書だ。
その序文に、いい言葉がある。
「圏論は、長く mind(精神)の領域にとどまりすぎた。いまこそ、hand(手)の領域へ持ち出すときだ」 と。
もうひとつは、同じ2018年に、第1回の応用圏論国際会議(ACT)が、オランダのライデンで開かれたことだ。
さっき年表で見た、あの会議のはじまりだね。
学部生:
本と、会議。分野が「生まれた瞬間」が、ちゃんとあるんですね。たった、数年前に。
講師:
そういうことだ。
だから、君がいま立ち会っているのは ── すでに完成した、古い学問じゃない。生まれて、まだ10年も経っていない、若い分野なんだ。教科書も、会議も、実装ライブラリも、いままさに、同時並行で作られている。
今日、君が見つけた日本語の記事も ── その、生まれたての地図に、新しい地名を書き足す営みの、ひとつなんだよ。
学部生:
まだ、誰のものでもない地図。
講師:
そういうことだ。
そんな分野だから、僕は、いまの応用圏論を、こう見ている。主役にはまだ遠いが、静かに育っている成長株だと。性能で勝つための技術というより、「賢くなったAIを、どう理解し、どう信頼するか」という、これから重みを増す問いの側に、効いてくる視座だ。
そして
── 君がいま自分で見つけた、あの2つのZennの記事。あれ自体が、ひとつの証左だよ。
yvvakimotoさんの「レンズの具体例」と、lotzさんの「レンズだけで作るニューラルネットワーク」。どちらも、日本語で、今日の景色を、自分の手で書いている人たちだ。
英語の一次資料や論文が、世界に向けた標準の地図だとすれば
── こうして日本語で書かれた記事は、さっき話した「まだ白いままの場所」に、日本語の地名を書き足していく営みだ。
生まれたての分野に、もう、日本語の道案内が、いくつも立ちはじめている。
君がそれを、自分で見つけて、読もうとしている。それが、何よりの証拠だよ。
さて、寄り道はここまでにして、レンズそのもの に話を戻そう。
ここが、レンズの美しいところだ。
こういう双方向の部品は、つなぐと、ちゃんと双方向のまま、大きな部品になる。
部署を、上流から下流へ、$A$、$B$、$C$ と並べてみよう。
製品は、$A$ から $B$、$B$ から $C$ へと「行き」で流れていく。
逆に、クレームは「帰り」で伝わる。いちばん下流の $C$ が「本当はこういう入力が欲しかった」と注文を返すと、その注文が、ひとつ上流の $B$ にとっての「正解」になる。
すると $B$ も、それを受けて $A$ へ注文を返す。
こうして、クレームが、$C$ から $B$、$B$ から $A$ へと、下流から上流へ、一本につながって流れていく。
これが、層をまたいだ逆伝播が、きれいにつながる理由だ。
レンズを、「読む」と「書き換える」の対 として定義すると、君が見つけてくれたZennの記事が、レンズの具体例として挙げてくださっていたように、GetterとSetter、多様体の余接ベクトル、ニューラルネットワーク ・・・これらすべてが、レンズの具体例になっていることがわかる。
そして、ニューラルネットワークの例では、順方向が推論、逆方向がまさに逆誤差伝搬(後進自動微分)だと説明されている。
今日、僕らが「行きの加工」「帰りの注文返し」と呼んできたものが、別の言葉で、同じように描かれているわけだ。日本語で、この景色をもう一度たどりたくなったら、このZenn記事は、よい入り口になるよ。
学部生:
部品が双方向だから、つないでも双方向。だから、逆伝播が、層をまたいで自動的につながる ── そういうことだったんですね。backward() が層を貫いて動く理由が、すっきりしました。
講師:
よし。この「双方向の部品=レンズ」に、もうひとつ、大事な飾りをつける。それが パラメータだ。
次は、Para(パラ) という考え方を見よう。
これで、ようやく「学習する部品」が完成する。
第4幕 ── Para:つまみ付きの部品
講師:
レンズは「双方向の部品」だった。だが、学習するには、もうひとつ要る。動かせるつまみ(パラメータ) だ。
つまみ付きの部品 ── これを、圏論では Para(パラ) という構成で扱う。
“parameter” の頭の四文字だね。
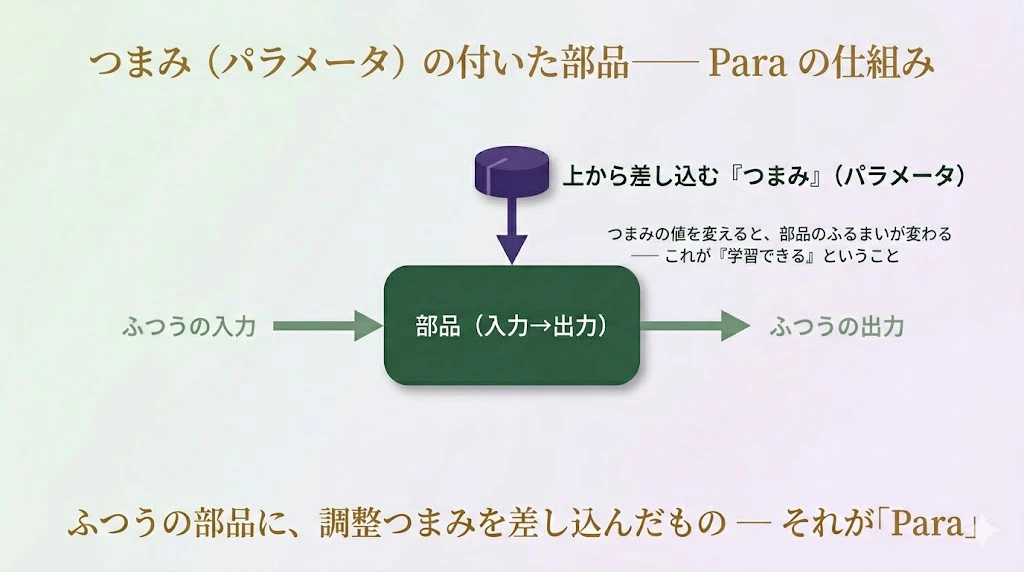
講師:
絵のとおりだ。ふつうの部品は、左から入力を受け、右へ出力を出す。
Para の部品は、それに加えて、上から「つまみ(パラメータ)」を差し込む。
つまみの値を変えると、同じ入力に対しても、出力が変わる。「学習する」とは、結局、このつまみの値を、いい具合に調整していくことだった ── ①の部品を思い出してほしい。
学部生:
ニューラルネットの一層が、まさにこれですね。入力があって、重み(つまみ)があって、出力を出す。重みを変えれば、ふるまいが変わる。
講師:
そう、それでいい。そしてPara の部品も、つなぐと大きなPara の部品になる。直列につなげば、つまみは合わさってひとつの大きなつまみの束になり、入力から出力への道は一本につながる。
ここで、今日の道具が、ふたつ出そろった。「Para(つまみ付き)」 と 「レンズ(双方向)」。
このふたつを重ねると、 「つまみ付きで、双方向の部品」 ができる。
これこそが、学習する部品 だ。
圏論では、これを パラメトリック・レンズ(parametric lens) と呼ぶ。
学部生:
つまみ付き(Para)で、双方向(レンズ)。ニューラルネットの一層が、まさにそれですね。
あ、いま、この論文を見つけました。タイトルが、そのままずばり、という印象です。
「Deep Learning with Parametric Lenses」
── 深層学習を、パラメトリック・レンズで、と書いてあります。いままさに、先生が説明してくださっている「つまみ付きの、双方向の部品」が、そのままタイトルになっているんですね。
講師:
お、また自分で掘り当てたね。しかも、ど真ん中だ。
そのとおり、タイトルがそのまま中身だよ。
「パラメトリック・レンズで深層学習を」。
いま君が手にした「つまみ付き(Para)で、双方向(レンズ)」を、そのまま深層学習ぜんぶに広げてみせた論文だ。
しかも、この論文には、続きがある。
Adam や AdaGrad といった、君がふだん使っている最適化アルゴリズムまで、ぜんぶ、このレンズの言葉で書けると示しているんだ。さらに、Python で動く実装まで付いている。
だが ── それは、もう少し先のお楽しみにとっておこう。
いまは、ひとつだけ覚えておけばいい。「つまみ付きで、双方向の部品」=パラメトリック・レンズ。
これが、学習する部品の正体だ。
そして ── ここからが、いよいよ Backprop as Functor の核心だ。この「学習する部品」を集めると、ひとつの圏ができる。その名を Learn 圏という。次の幕で、その正体を見にいこう。
学部生:
先生、また新しいウェブサイトを見つけました。
今日、研究室を出たあとに、この3つの記事も、よく読んでみようと思っているんですが、いまの議論と、うまくかみ合うサイトでしょうか。
講師:
いい収穫だ。
3つとも、本物で、しかも今日の話の、ど真ん中にかみ合っている。
前のときと同じで、リンクが実在して、中身も正しいと、自分で確かめてから読むといい。
今回は、僕が見てもいい3本だよ。
3つとも、性質が違う。順番に、ひとことずつ見ていこう。
1つ目の nLab の「Para construction」は、いまやった「つまみ付きの部品(Para)」の、標準のリファレンスだ。
じつは、この「Para」という呼び名そのものが、今日の主役、Backprop as Functorの論文 で、最初に使われた。
いちばん足場の固い、一次資料に近い一本だね。
2つ目の Cybercat Institute は、この応用圏論サイバネティクスを進めている、研究コミュニティ自身のブログ だ。
英語だが、いま話した「Para とレンズ」を、依存型の言語で、実際に動くニューラルネットとして組み上げてみせている。研究の最前線の景色が、そのまま見える。
3つ目は、日本語の記事だ。
lotzさんが、レンズ(ParaLens)だけで、ニューラルネットを Haskellのコードで組んで、本当に学習させている。
今日のレンズとParaが、そのままコードになっているよ。
しかもこの記事の結びは、僕らがこのあと、最終幕でたどり着く場所まで、そっと指さしている。何のことかは、まだ言わないでおこう。
さて。それでは次に、約束したLearn圏の正体を、見にいこう。
第5幕 ── Learn 圏:「学習する部品」の世界
講師:
Learn 圏は、Backprop as Functor論文の主役 だ。
対象(もの)は、ただの集合。そして射(部品・矢印)が、学習器(learner)
── つまり「学習する部品」だ。
ひとつの学習器は、4つの道具をセットにして定義される。
論文では、これを $(P, I, U, r)$ という4つ組で書く。
むずかしそうに見えるが、ぜんぶ、さっきの「会社の部署」のたとえで読み解ける。
ひとつずついこう。

講師:
4つ組 $(P, I, U, r)$ を、ひとつずつ。入力の集合を $A$、出力の集合を $B$ としよう。
-
$P$:パラメータ空間。 動かせる「つまみ」の全体だ。ニューラルネットなら、重みぜんぶの集まり。たとえばつまみが $N$ 個なら、$P$ は $N$ 次元の空間になる。
-
$I$:実装関数(implement)。 つまみ $P$ と入力 $A$ を受け取って、出力 $B$ を出す。これが順伝播、つまり「行きの加工」だ。記号で書けば
I : P \times A \to B
- $U$:更新関数(update)。 つまみ $P$、入力 $A$、それに「正解 $B$」を受け取って、新しいつまみ $P$ を返す。クレーム(誤差)を受けて、つまみを直す仕事だ。記号では
U : P \times A \times B \to P
- $r$:要求関数(request)。 ここが、いちばん大事で、いちばん面白い。つまみ $P$、入力 $A$、正解 $B$ を受け取って、「本当は、こういう入力 $A$ が欲しかった」という注文を返す。記号では
r : P \times A \times B \to A
学部生:
$I$ が行きの加工、$U$ がつまみの直し、そして $r$ が……上流への注文返し。さっきの部署のたとえ、そのままですね。
講師:
そのとおり。そして、強調しておきたい。この4つのうち、$r$(要求)こそが、部品どうしを”つなぐ”ための鍵なんだ。
考えてみてほしい。学習器をひとつだけ、ぽつんと置くなら、実は $r$ は要らない。つまみ $P$ と、その直し方 $U$ さえあれば、その部品単体は学習できる。
ところが、部品を直列につなぐと、話が変わる。
下流の部品が、「本当は、こういう入力が欲しかった」と $r$ で注文を返す。
その注文が、上流の部品にとっての 「正解 $B$」になる。
**こうして、クレームが、下流から上流へ、$r$ を伝って、バケツリレーのように渡っていく。
**これが、層をまたいだ誤差逆伝播の、数学的な正体だ。
学部生:
$r$ がないと、部品をつないだときに、誤差を上流へ渡せない
── だから $r$ は、単体では要らないのに、合成のためには絶対に要る。
逆伝播が「つなぐための仕組み」だったというのが、はっきりしました。
講師:
そこまで言い切れれば、申し分ない。論文も、まさにそう述べている。
要求関数 $r$ は、単体の学習には不要に見えるが、学習器を合成するためには、決定的に重要だ、と。
そして、この $(P, I, U, r)$ という学習器を射として、集合を対象とすると、ちゃんと圏の条件(結合則・恒等射)を満たす。
これが Learn 圏だ。
さらに「縦につなぐ(直列)」だけでなく「横に並べる(並列)」もできるので、対称モノイダル圏になる。── 前回までに出てきた言葉が、また顔を出したね。
学部生:
縦につなぐ・横に並べる ── モノイダル圏。
前回のOR や、ゲーム理論と、同じ骨格 だ。
講師:
そういうことだ。
分野は違えど、骨格は同じ。これこそ、応用圏論の醍醐味だよ。
第6幕 ── Backprop as Functor:学習は「関手」である
講師:
さて、いよいよ、この記事のタイトルの意味にたどり着く。
Backprop as Functor ── 関手 としての誤差逆伝播だ。
関手(functor) という言葉は、前回までにも出てきた。
ひとことで言えば、「ある世界の部品と組み立て方を、別の世界へ、構造を保ったまま、まるごと翻訳する仕組み」 だ。
「構造を保つ」 とは、「組み立ててから翻訳しても、翻訳してから組み立てても、同じ結果になる」 ということだったね。
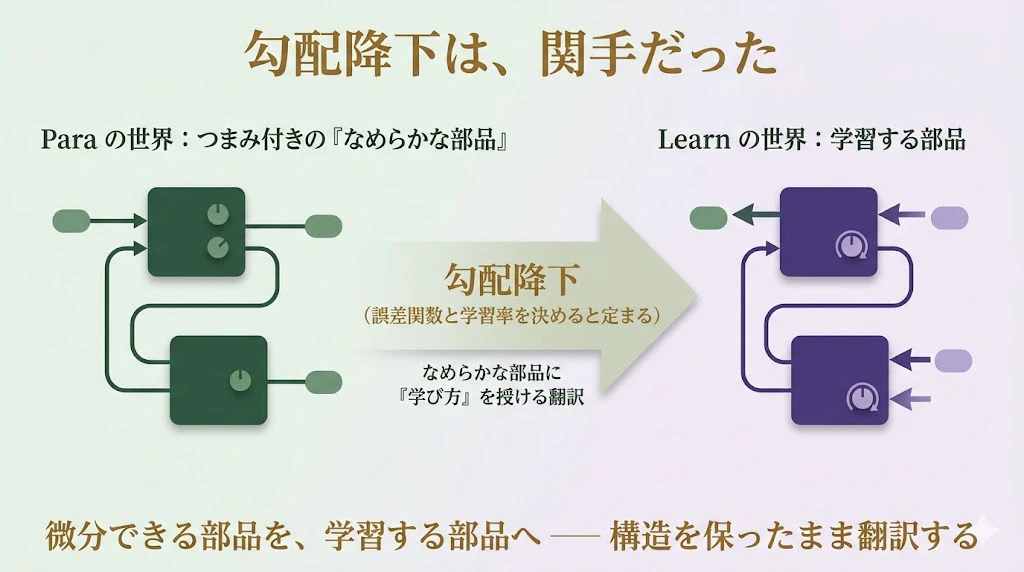
講師:
論文の主張は、こうだ。
まず、左側に「つまみ付きの、なめらかな(微分できる)部品」たちの世界がある。これを Para の世界としよう。ニューラルネットの各層は、まさにこれだ
── 重みというつまみを持ち、入力をなめらかに変換する。
ここで、**「誤差関数」と「学習率」**を、ひとつ決める。
すると、 「勾配降下」という、たったひとつの翻訳ルールが定まる。
この翻訳 は、Paraの世界の部品を、さっきの Learn圏の学習器 $(P, I, U, r)$ へと、送り込む。
具体的には、なめらかな部品(順伝播 $I$ にあたるもの)から、勾配を計算して、更新 $U$ と要求 $r$ を、自動的に作り出す。
微分が、$U$ と $r$ を生むんだ。
(厳密に言うと、この翻訳がいつでも定まるためには、誤差関数に軽い技術的条件が要る ── 各点で「ずれの測り方」が、ひと方向にきちんと効く、という条件だ。詳しくは Appendix A-2 に譲る。読み飛ばして構わない。)

学部生:
つまり ── モデル(なめらかな部品)を組み立てさえすれば、「誤差をどう逆伝播し、つまみをどう直すか」は、勾配降下という翻訳が、自動的に決めてくれる。
講師:
そういうことだ。そして、この翻訳が 関手 であること
── つまり**「構造を保つ」**ことには、決定的な意味がある。
次の絵を見てほしい。前回も登場した、あの「ふた通りの道」だ。
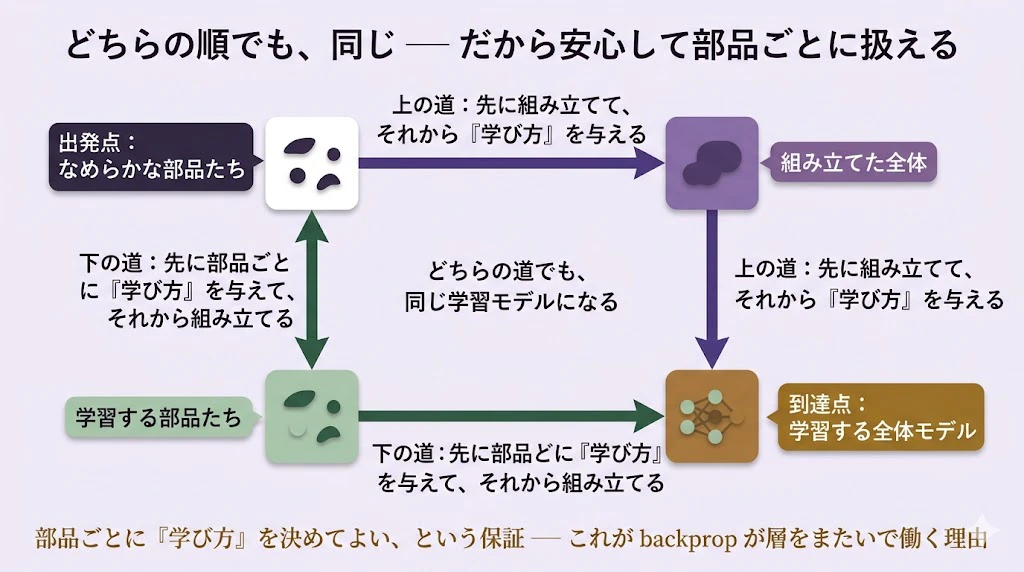
講師:
出発点は「なめらかな部品たち」、到達点は「学習する全体モデル」。
そこへ、ふた通りの道がある。
上の道は、先に部品を組み立てて、大きなモデルにしてから、勾配降下で「学び方」を与える。
下の道は、先に部品ひとつひとつに「学び方」を与えて、それから組み立てる。
関手であるとは、このふたつの道が、必ず同じ結果に着く、ということだ。
学部生:
それが保証されているから
── 全体をいっぺんに考えなくても、層ごとに「学び方(勾配と更新)」を決めて、あとでつなげばいい。
まさに、PyTorch が層ごとに backward を定義して、それが自動でつながっていく、あの仕組みの、数学的な裏づけ なんですね!
講師:
よく言い当てた。
「backward() が、なぜ層をまたいできれいに動くのか」
── その答えが、これだ。
学習が関手だから・・・ 組み立てと、学び方の付与が、交換できる。
だから、部品ごとに考えてよい。
これが、Backprop as Functor の、心臓部 だ。
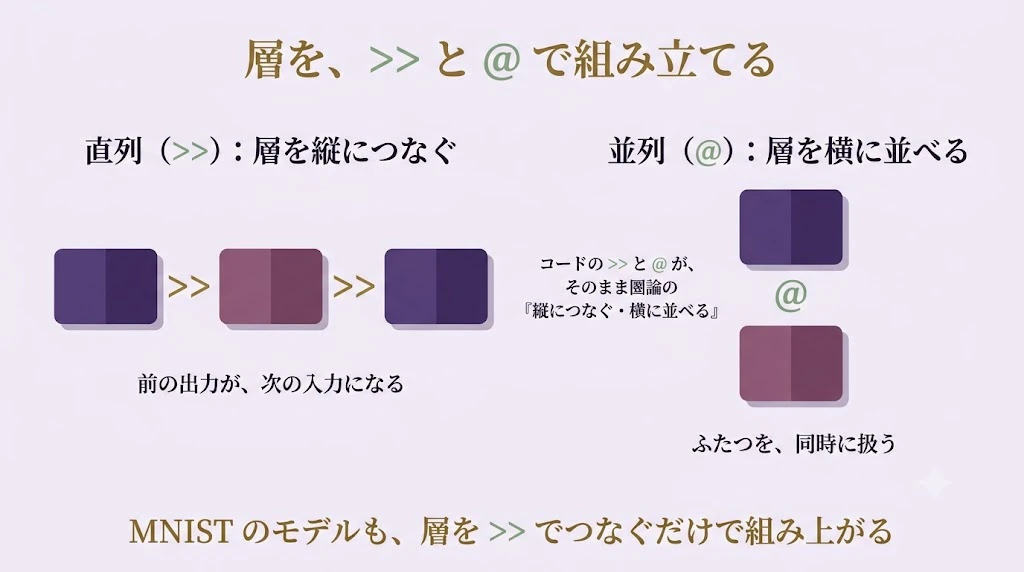
第7幕 ── 動く実装:MNIST を「>>」と「@」で組み立てる
講師:
ここまでは理論の話だった。
だが ── これは「研究室の中だけの空論」では、もうない。
動く実装が、すでに存在する。
Cruttwell・Gavranović・Ghani・Wilson・Zanasi の論文 Deep Learning with Parametric Lenses(2024)は、いままで話してきた 「パラメトリック・レンズ」 を、そのまま Python のライブラリにした。
そして、 手書き数字認識の MNIST を、このライブラリで実際に組み立てて、学習させている。
しかも、定番の Keras で組んだ同じモデルと、ほぼ同じ精度を出した、と報告している。
講師:
このライブラリでは、部品(パラメトリック・レンズ)を、ふたつの演算子でつなぐ。
f >> g が、直列(縦につなぐ)。
f の出力が、g の入力になる。
前回までの 「縦の合成」そのもの だ。
f @ g が、並列(横に並べる)。
ふたつの部品を、横に並べて同時に扱う。
「横に並べる(モノイダル積)」そのもの だ。
学部生:
>> が縦、
@ が横。
圏論の「縦につなぐ・横に並べる」が、そのままコードの演算子になっているんですね!
これは、PyTorch の nn.Sequential で層を積むのと、感覚が近い です。
講師:
まさに。
だが、決定的な違いがある。
Keras や PyTorch では、層をつなぐと、その「学び方(逆伝播)」は、フレームワークが裏で面倒を見てくれる ── つまり、中身はブラックボックスだ。
その一方で、このライブラリでは、部品そのものが「パラメトリック・レンズ(双方向・つまみ付き)」 で、>> でつないだ瞬間に、逆伝播のつながり方まで、レンズの合成として、数学的に決まっている。
先ほど見てきた、「学習が関手」が、コードのレベルで実現されているんだ。
論文の言葉を借りれば、勾配の計算が、レンズの合成によって、見通しよく簡単になる。
イメージとして、MNIST 分類モデルは、こんな雰囲気で組み上がる。
# ※ 層や活性化の関数名は簡略化しています(実APIに近い擬似コード)。
# 実装は numeric-optics-python(Wilson ほか)で、
# 実際に層を >> と @ でつなぎます。論文・実装の MNIST は畳み込みモデルです。
# 部品(パラメトリック・レンズ)を用意する
dense1 = linear(784, 128) # 28x28=784 の入力を 128 次元へ
relu1 = activation_relu()
dense2 = linear(128, 10) # 128 次元を 10 クラス(数字 0〜9)へ
softmax = activation_softmax()
# 層を >> で直列につないで、モデルを組み立てる
model = dense1 >> relu1 >> dense2 >> softmax
# これだけで「順伝播」も「逆伝播(学び方)」も、
# レンズの合成として、すでに決まっている。
# あとは、誤差関数と学習率を与えて、学習を回す。
学部生:
dense1 >> relu1 >> dense2 >> softmax
── 層を >> でつなぐ、ただこれだけ。
そして、つないだ時点で、逆伝播のさせ方まで、もう決まっている。
第6幕の 「組み立てれば、学び方も決まる」が、本当にコードになっている んですね。
講師:
そういうことだ。
── これは、たとえ話じゃない。
この >> と @ は、実際に公開されているライブラリ(numeric-optics-python)の、本物の演算子だ。
全結合層ひとつでさえ、linear >> bias >> activation と、3つの部品の合成として書く。
「縦につなぐ・横に並べる」という圏論の言葉が、そのまま、君が打てるコードになっているんだ。
理論が、絵に描いた餅ではない、という何よりの証拠だね。
しかも、この枠組みのうれしさは、もうひとつある。
「学び方」を取り替えるのも、部品を取り替えるのと同じように、簡単なんだ。
**新しい最適化アルゴリズムを使いたければ、対応するレンズを、ひとつ定義し直せばいい。
**実際、後続の研究では、Adam や AdaGrad といった、君もよく使う最適化手法までもが、この同じ枠組みで、統一的に表せることが示されている(Cruttwellら。2021)。
学部生:
最適化アルゴリズムまで、部品として差し替えられる ── モデルも、学び方も、ぜんぶ「レゴ・ブロック」の積み木なんですね!

講師:
そうだ。そして
── ここで、3部作を通じて、ひとつ気づいてほしいことがある。
実装に使われている言語だ。
前々回、ゲーム理論のopen-games は、Haskell で書かれていた。
前回、最適化のAlgebraicOptimization は、Julia だった。
そのたびに僕は言ったね ──「圏論だから関数型」でも「圏論だから Julia」でもない、言語の選択は、その分野の生態系(エコシステム)との相性で決まる、と。
学部生:
はい。「必然ではなく、相性」だと。
講師:
今回は、Python だ。
機械学習のライブラリも、自動微分も、データも、ぜんぶ Python に揃っている。
だから、学習を圏論で組み立て直すライブラリも、Pythonで書かれた。
学部生:
Haskell、Julia、そして Python
── 3つの分野が、それぞれの母語で実装されてきて、最後に、僕がいちばん書き慣れた言語に、帰ってきたんですね。
講師:
そういうことだ。
3部作の最後が、君の母語で書かれている
── 偶然だが、悪くない偶然だろう。
圏論という共通の骨格は、言語を選ばない。
どの言語で書いても、同じ「縦につなぐ・横に並べる」が現れる。
君は、その骨格に、Python から手を伸ばすことができるんだ。
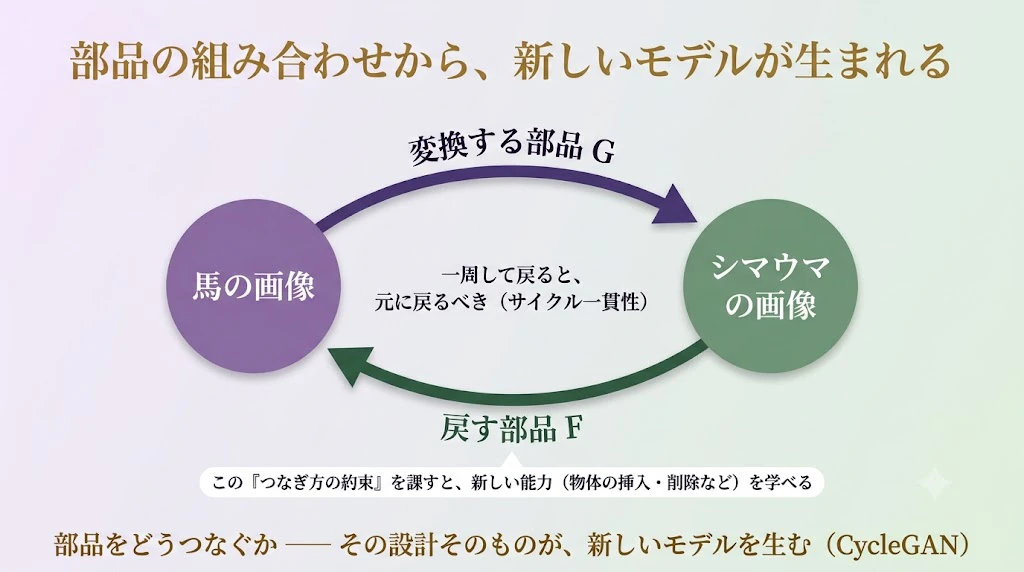
第8幕 ── 部品から、新しいモデルを生む:CycleGAN の実例
講師:
「MNIST を組み立てる」だけなら、ふつうのフレームワークでもできる、と思うかもしれない。だから、もう一歩、踏み込んだ例を見せよう。部品の組み合わせ方そのものから、新しいモデルを生み出した研究だ。
Gavranović の Compositional Deep Learning(2019)
── これは、CycleGAN という画像変換モデルを、圏論で定式化した仕事 だ。
講師:
CycleGAN を、ごく簡単に説明しよう。
たとえば「馬の写真を、シマウマの写真に変換する」モデルだ。
ポイントは、変換する部品 $G$( $馬→シマウマ$ )と、戻す部品 $F$( $シマウマ→馬$ )を用意して、「一周して戻ってきたら、元の画像に戻っていなければならない」 という 約束(サイクル一貫性)を課す ところにある。
これは、まさに**「部品どうしのつなぎ方に、約束(不変条件)を課す」** という発想だ。
Gavranović は、この CycleGAN を、複数のニューラルネットを合成で組み合わせた「圏論的な図式(スキーマ)」として捉え直した。
前回、ORで出てきた、Spivak の「圏論的データベース(関手的データモデル)」
── データの構造を圏で表すあの発想 ── を、ニューラルネットの相互接続に応用したんだ。
学部生:
あ、前回の Spivak の話と、つながった。
データベースのスキーマを圏で表したのと同じ要領で、ニューラルネットのつなぎ方を、圏で表す ──
講師:
そういうことだ。
もう少し、仕組みを具体的に言おう。
スキーマというのは、 「どんな対象(画像のドメイン:馬・シマウマ……)があり、それらを、どのネットワーク(射)がつなぐか」、そして「一周したら元に戻る」のような、守るべき約束(合成の不変条件=サイクル一貫性) を、ひとつの圏の図として描いたものだ。
そこに、実際の中身を流し込む。
── 各対象に画像の集合を、各射に本物のニューラルネットを割り当てる。
これが、「集合への関手」 だ。
前回OR で見た、Spivak の関手的データモデル、あの構造そのものだね。

面白いのは、ここだ。
ふつうの機械学習が「関数」を学習するのに対し、この枠組みでは、 「関手」そのものを、勾配降下で学習する 。
スキーマという設計図を保ったまま、中身のネットワークを訓練していく んだ。

学部生:
じゃあ、新しいことをやりたければ ──
講師:
新しいスキーマを描けばいい。
「物体を挿入する」「物体を削除する」という新しい対象と射、そして守らせたい約束(不変条件)を、図として描く。
すると、その図から、対応するネットワーク構造と、訓練のときに課すべき制約(損失)が、おのずと決まってくる。

Gavranović は、この方法で、まったく新しいネットワーク構造を、実際に設計してみせた。課題は、「画像のなかに、物体を描き加えたり、消したりする」ことだ。
学部生:
それって、ふつうの画像変換と、何が難しいんですか。
講師:
ふつうは、「物体がある写真」と「それを消した写真」を、ぴったり対(ペア)にして用意して、学ばせる。
だが、そんな都合のいいペアは、現実にはなかなか集まらない。
Gavranović の設計は、そのペアなしで、バラバラの画像だけから学習できるんだ。
実際に、3つのデータセットで試して、有望な結果が出ている。
学部生:
既存のモデルを圏論で”説明した”だけじゃなくて、その枠組みを使って、**新しいモデルを”生み出した”**んですね?
部品の組み合わせ方の理論が、新しい設計を導いた
── これは、実用的な価値が、はっきり見えます。
講師:
そこに気づいてもらえると、うれしい。
「部品から組み立てる」という視点は、ただの後づけの説明ではない。
新しいものを作るための、設計の指針になりうる。
さらに近年では、Gavranović の博士論文(2024)のように、深層学習のさまざまなアーキテクチャを、統一的な圏論の言葉で、実装可能な(プログラムに落とせる)かたちで体系化する試み も進んでいる。
学部生:
ということは ── レゴ・ブロックのように、たとえば、肉声を文字に起こす Speech to Text の部品と、テキストから感情を推定したり、固有表現抽出をしたりする部品。
この2つを組み合わせれば、「人の話し声から、その感情や、話に出てくる固有表現(地名・組織名・金額・時刻・人名など)まで、まとめて取り出す」という、ひとつの大きな部品が、組み立てられる
── そういうことですか?
講師:
発想は、まさにその方向だ。
部品を直列につないで、大きな部品にする。今日ずっとやってきた「縦につなぐ」だね。
ただ、ひとつだけ、正直に線を引いておこう。
いま君が言った「Speech to Text の出力を、感情推定や固有表現抽出に渡す」
── これ自体は、実は、圏論を持ち出さなくても作れる。
前の部品の出力を、次の部品の入力に流す。
ふつうの「パイプライン」だ。多くの実務のシステムが、すでにそうやって組まれている。
学部生:
じゃあ、圏論が効いてくるのは、どこなんですか?
講師:
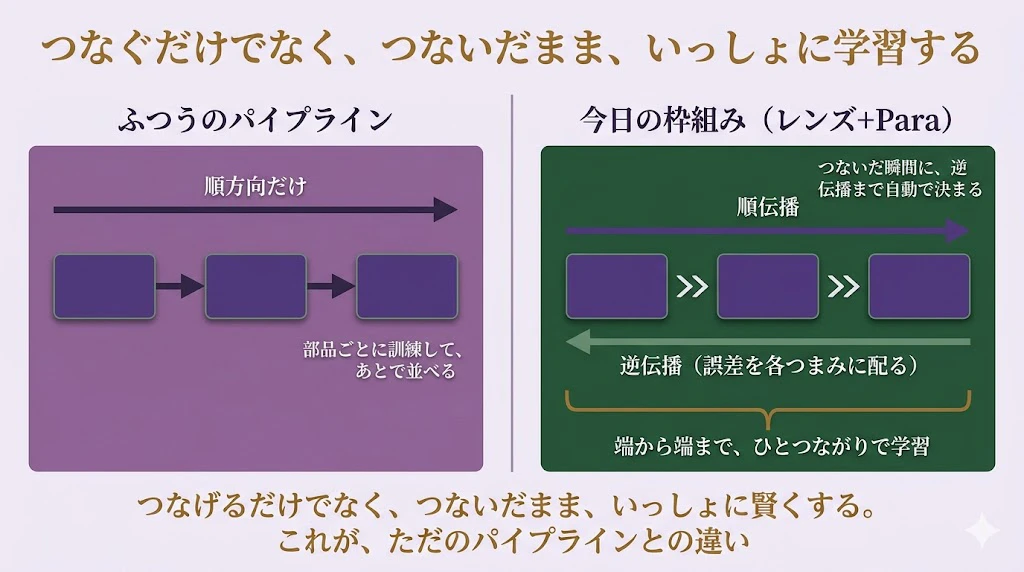
その先だ。
ふつうのパイプラインは、部品どうしを「つなぐ」ことはできても、つないだ全体を「いっしょに学習させる」のは、簡単ではない。それぞれの部品を別々に訓練して、あとで並べることが多い。
今日の枠組みのうれしさは、そこにある。
部品を「双方向(レンズ)で、つまみ付き(Para)」として書いておけば、>> でつないだ瞬間に、順伝播だけでなく、逆伝播 ── つまり「全体の誤差を、どう各部品のつまみに配るか」── まで、合成として、自動的に決まる。
だから、つないだ大きな部品を、端から端まで、ひとつながりで学習させられる。
「つなげる」だけでなく、「つないだまま、いっしょに賢くする」── そこが、ただのパイプラインとの、決定的な違いなんだ。
学部生:
なるほど。部品を組み合わせて大きくする、まではパイプラインでもできる。
でも、「組み合わせたまま、まとめて訓練できる」のが、この枠組みならではの強み、ということですね。
ところで、部品から組み立てられる、というのは
── ただ「作りやすい」だけじゃなくて、もっと先がありそうですね。
講師:
鋭い。そこは、いま社会的にも、いちばん切実なところにつながる。
考えてみてほしい。
2026年のいま、AIは、もう画面の中だけの存在ではなくなった。
無人運転車が公道を走り、
倉庫や工場の搬送ロボット、
飲食店の配膳ロボット、
介護施設や家庭の介助ロボット、
ビルを巡回する警備ロボット
── AI が、人間の暮らす生活空間そのものへ、出てきている。
こうした「人の安全に直結する(safety-critical)」場所にAIを載せるとき、「だいたい動く」では済まない。
「この範囲の入力では、危険な誤動作をしない」と、できれば数学的に保証したい。
だが、巨大なニューラルネットは、判断が膨大な重みに溶けていて、中で何が起きているかを、人間が追いにくい。形式的な検証とは、とても相性が悪いんだ。
学部生:
そこに、「部品から組み立てる」が、効いてくるんですか?
講師:
そこが、希望の芽だ。
モデルを、意味のはっきりした部品と、構造を保つ合成として書けるなら
── 全体の振る舞いを、部品ごとに、構造に沿って論じられる可能性が出てくる。
「組み立て方が、数学的にきちんとしている」ことは、いつか「組み上げたものを、形式的に検証する」ための、土台になりうる。

正直に言えば、これは今日明日の話ではない。
いま safety-critical な現場で実際に使われているのは、古典的な形式手法だ。
だが ── 巨大化する AI の振る舞いを、どう数学的に検証し、安全性を担保するか、という問いに、この「合成的な厳密さ」が、一枚かんでくるかもしれない。
「賢い AI」だけでなく、「信頼できる AI」をどう作るか
── そこに、今日の枠組みは、静かに接続しているんだ。
学部生:
モデルを組み立てる技術が、そのまま、モデルを検証する技術の足がかりになるかもしれない
── それは、僕らエンジニアにとって、すごく現実的な意味を持ちますね。
2026年6月のいま、すでに、AI の挙動を正確に予測したり、安全性を保証したりする目的で、応用圏論で AI の機能部品を組み合わせる、という発想の研究は、出はじめているんですか?
講師:
誠実に、線を引いて答えよう。
ここは、期待が先行して、先走りやすいところだからね。
まず、「ニューラルネットを形式的に検証する」研究そのものは、とても活発だ。
無人運転や衝突回避のような safety-critical な場面を念頭に、「この入力の範囲では、危険な出力を出さない」と数学的に証明しようという研究が、世界中で進んでいる。
さらに、その中には「合成的(compositional)」と呼ばれる流れもある。
巨大なネットを丸ごと検証するのは大変だから、部品ごと、あるいはモードごとに分けて検証して、それを組み合わせる。
「分けて検証して、つなぐ」という発想だね。これは、今日の「部品から組み立てる」と、精神的には近い。
学部生:
じゃあ、もう、応用圏論で安全性を保証する研究が、ちゃんとある、ということですか。
講師:
そこは、はっきりさせておきたい。
いま言った「合成的検証」の多くは、制御理論や形式手法の世界で育った技術であって、今日僕らが見てきた応用圏論 ── レンズや Para や関手 ── を、直接の道具にしているわけではない。
「部品に分けて検証する」という発想は共有しているが、同じ家系の研究、とまでは言えないんだ。
圏論そのものと、検証技術が出会う場所 も、ないわけじゃない。
理論計算機科学の側では、プログラムの正しさを圏論の言葉で論じる、長い伝統 がある。
だが、それを「深層学習の安全性検証」に、今日の枠組みのまま、まっすぐ接続した主流の研究は、正直に言って、まだ、はっきりとは立ち上がっていない。
学部生:
じゃあ、さっきの「検証の土台になりうる」というのは ──
講師:
そう、あれは「すでにある成果」ではなく、「これから芽が出るかもしれない方向」だ。希望の芽、と言ったろう。芽であって、果実ではない。
2つの流れ ── 「圏論で部品から組み立てる」流れと、「形式手法で検証する」流れ ── は、いまは、別々の畑で育っている。
この二つが、いつか地続きになるかもしれない。そう見ている研究者はいるし、僕も、そうなってほしいと思っている。だが、それが「もう起きた」と言ってしまうのは、ロマンに足をすくわれることだ。
学部生:
「つながりうる」ことと、「もうつながっている」ことは、分けて持つ。
講師:
そのとおり。
今日、何度も練習した作法だね。
期待は大きく持っていい。
だが、現在地の旗は、正確な場所に立てておく。
── そのうえで言えば、君のような、 両方の畑を見渡せるエンジニアが、その二つをつなぐ最初の一人に、ならないとも限らないよ。
第9幕 ── 再会:学習とゲームは、ひとつにつながる
講師:
さて ── 3部作の、最後の山場 だ。
ここまで、君は 前々回で「ゲーム理論」を、前回で「OR・最適化」を、そして今回は「機械学習」を、すべて「部品から組み立てる」発想 を見てきた。
これらは、同じ”地図”の上にある、という話 を、ずっとしてきた。
だが、今日の締めくくりは、それよりも、もっと強い。
学習とゲームは、ただ似ているだけではない。関手という橋で、直接つながっている。
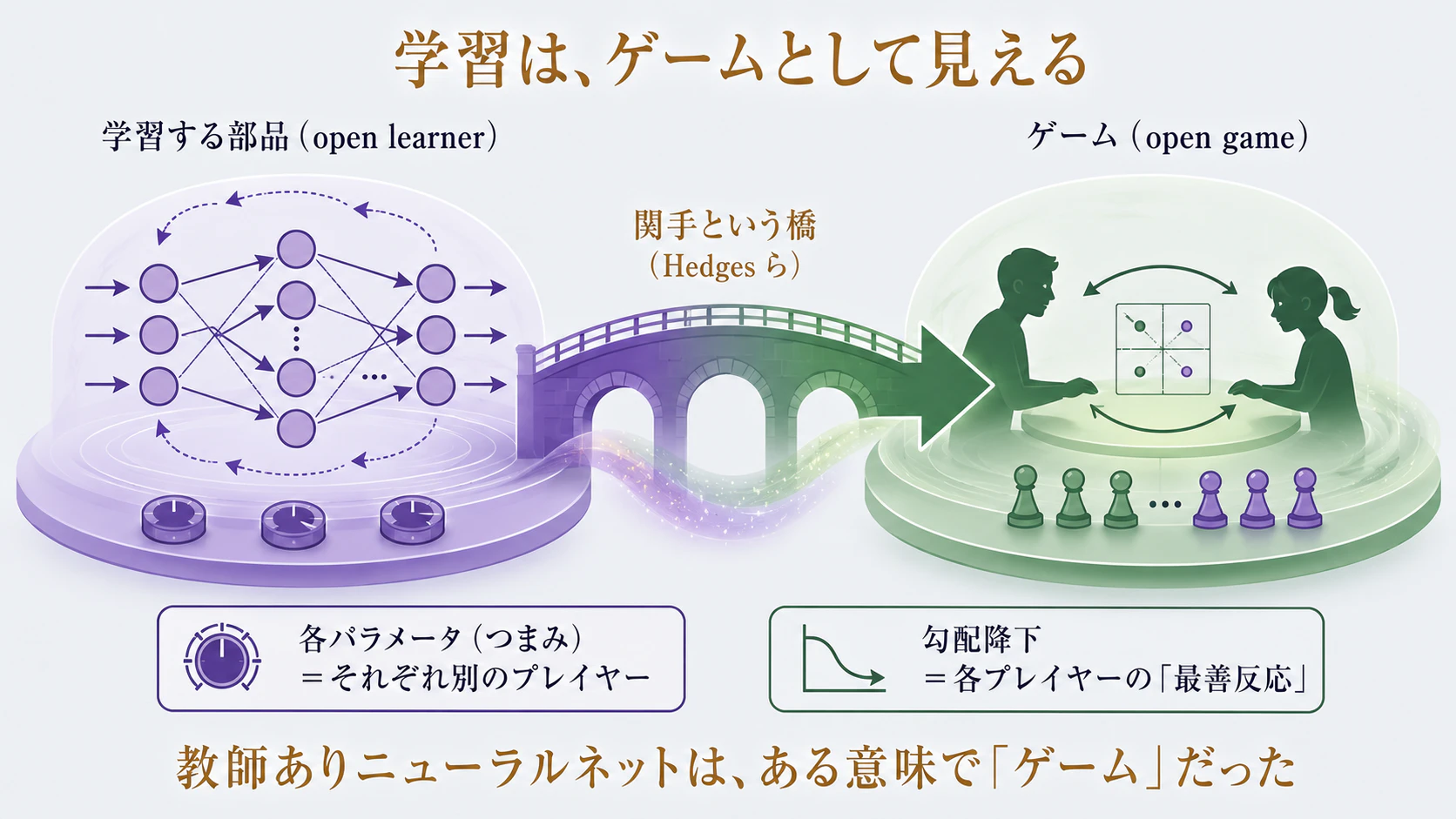
講師:
前々回、ゲーム理論を「開いたゲーム(open game)」── 入力と出力の境界を持つ、合成できるゲームの部品 ── として組み立てたのを、覚えているね。
そして今回、学習を「開いた学習器(open learner)」として組み立てた。
驚くべきことに、このふたつのあいだに、関手(構造を保つ橋)が存在することが、証明されている んだ。
Jules Hedges が2019年の短いノート「From open learners to open games(開いた学習器から、開いたゲームへ)」で示した結果でね。
論文のタイトルが、そのまま今日の話の締めくくりになっている。
「教師あり学習のニューラルネットワークは、ある意味で、ひとつのゲームとして見ることができる」。
学部生:
ニューラルネットが……ゲーム? どういうことですか。
講師:
こういうことだ。
ネットワークのそれぞれのパラメータ(つまみ)を、別々のプレイヤーだと思う。
各プレイヤーは「自分のつまみを、どう設定するか」という戦略を持つ。
そして ── 勾配降下による学習が、各プレイヤーにとっての「最善反応」 にあたる。
誤差を減らす方向につまみを動かすことが、そのプレイヤーの最善の手、というわけ だ。
学部生:
でも、先生 ── 正直、ひとつ引っかかります。
ゲームのプレイヤーは、相手の手を読んで、戦略的に動きますよね。
でも、勾配降下は、ただ目の前の坂を下っているだけです。先を読んでいるわけじゃない。
それを「プレイヤー」「最善反応」と呼んでしまって、いいんでしょうか。
講師:
良い指摘だね。
そこは、はっきり線を引いておこう。
ここで言っているのは、「ニューラルネットの訓練が、文字どおり戦略的な駆け引きだ」という主張ではない。
そうではなく、ふたつの圏のあいだに、構造を保つ関手がある
── 学習器という部品の 組み立て方 が、ゲームという部品の 組み立て方 に、きれいに 翻訳できる、という構造の対応 だ。
Hedges 自身、論文の中で、「ある意味で( in a canonical way )見なせる」と、慎重に書いている。
前々回、ラングランズと圏論を「血縁ではなく、精神的な親戚」と測り分けたのを覚えているね。
今回は、それより一段強い。
比喩ではなく、関手という、れっきとした数学の橋がかかっている。
だが ── 橋がかかっていることと、両岸が同じ町だ、ということは、別の話だ。
そこは、混同してはいけない。
ロマンに足をすくわれず、論証の手すりを離さない ── 前々回からの、僕らの作法だね。
学部生:
「似ているから同じ」ではなく、「構造を保つ関手で、正確につながっている」。
でも、つながっていることと、同一であることは、分けて持つ、と。
── ちなみに、この橋は、まだ理論の上だけの話なんですか?
講師:
いや、そこも面白い。この橋は、もう「理論のうえだけの話」では終わっていない。
つい最近(2025年)、この発想を、実際の訓練の改良に持ち込んだ研究が出てきた。
"Game-Theoretic Gradient Control for Robust Neural Network Training"(2025、arXiv:2507.19143)だ。
ニューラルネットの訓練そのものを、複数のエージェントが関わる「ゲーム」として捉え直すんだ。
前々回の記事で取り上げた 合成的ゲーム理論の枠組みのなかに、逆伝播を置く。
そのうえで、逆伝播のときに、各ニューロンの勾配を確率的に間引く「勾配ドロップアウト」という工夫を入れて、入力ノイズに強いモデルを作ろうとする。
実際に、10種類のデータセットで試して、回帰の課題では、ノイズへの頑健性がはっきり上がった、と報告している。
学習とゲームの橋は、いまも、現在進行形で架け広げられている んだ。
理論として「つながる」と示されただけでなく、その見方を使って、モデルを実際に鍛えようという人が、もう現れている。
学部生:
Hedges さんが2019年に「橋がある」と証明して、いまはもう、その橋を渡って、実際にモデルを鍛えようとする人が現れている。理論が、ちゃんと先へ進んでいるんですね。
講師:
そういうことだ。── そのうえで、もう一度、地図を眺めてみよう。
前々回、ゲームの均衡(ナッシュ均衡)を「不動点」として捉えた。
前回、設計(co-design)の最適解も「不動点」だった。
そして今回、学習が落ち着く先も、各プレイヤーが最善反応をしあった「不動点」 として見える。
学部生:
ゲームの均衡も、設計の最適解も、学習の収束も ── ぜんぶ「不動点」。
そして、学習とゲームは、関手で直接つながっている……。
3つの記事が、いま、一本につながりました。
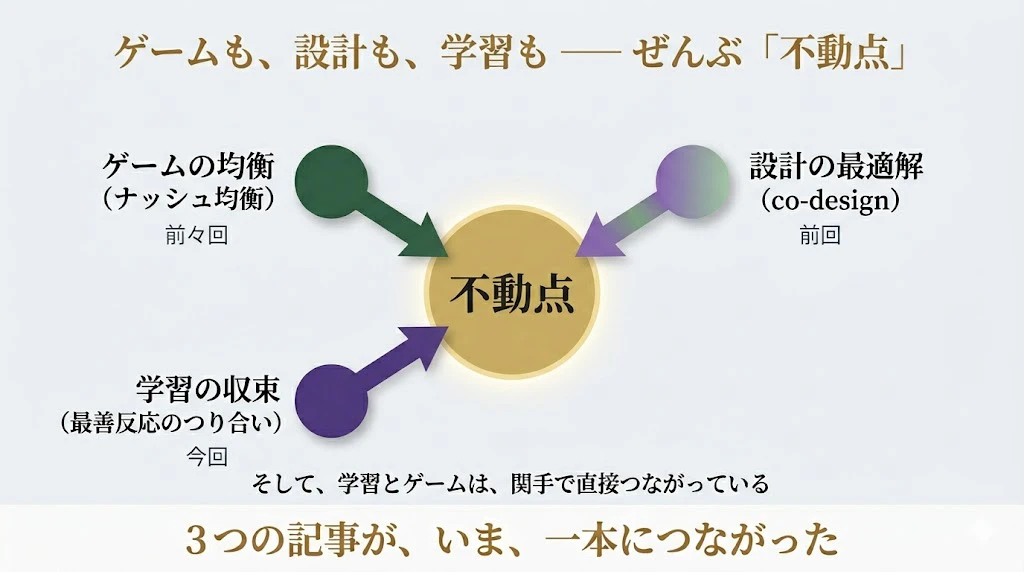
講師:
これが、3部作を通じて、君に届けたかった風景だ。
分野の名前は、ゲーム理論・最適化・機械学習と、ばらばらだ。だが、それを支える骨格 ── 部品から組み立てる、構造を保つ変換、不動点、双方向のやりとり ── は、ひとつだ。
応用圏論は、その共通の骨格を、まっすぐに見つめる営みなんだ。
まとめ ── 完成した「ひとつの地図」
講師:
最後に。
この記事のはじめに、「ひとつの地図」を予告として見せたのを、覚えているだろうか。
前々回のゲーム理論、前回のOR、今回の機械学習が、ひとつの土台の上に並ぶ
── あの、まだ輪郭だけの 地図だ。
いまなら、その地図に、名前を書き込むことができる。
空白だった土台には、レンズ・Para・学習器・関手・不動点という、今日たどってきた道具立てが収まる。
そして、ゲームと学習をつなぐ橋も、描き込める。
予告編だった地図が、こうして完成版になった。

学部生:
ゲーム理論から始まった旅が、最適化を経て、機械学習にたどり着いて
── そして、出発点のゲーム理論と、また出会った。きれいな円を、描いていたんですね。
講師:
そういうことだ。
今日紹介した「OR × 圏論」や「機械学習 × 圏論」は、まだ非常に若い領域だ。
いまこの瞬間、世界の AI を動かしているのは、圧倒的に PyTorch や TensorFlow と、その成熟した自動微分だ。今日の圏論的な枠組みが、明日にもそれを置き換える、という段階にはない。
ただし ── 動く実装は、すでに存在する。
論文とともにコードが公開され、MNIST が実際に学習し、新しいモデルの設計まで導かれている。
もはや「研究室の中だけの空論」ではない。
学部生:
理論と実装は存在し、応用の入り口に、研究者が立っている ── 前回までと、同じ”地図”ですね。
講師:
まさに、そのとおりだ。
「すでに広く使われているのは、伝統的な深層学習フレームワークであり、圏論的な機械学習は、その”作り方”そのものを、見通しよく捉え直そうとする、新しい挑戦である」
── そういう地図として、受け取ってほしい。
そして、これから10年、20年をかけて、この地図がどこまで描かれていくか
── それを、Python を書きながら見届けられる時代に、君は生きている。
3部作は、ここまでだ。
長い旅に、付き合ってくれて、ありがとう。
学部生:
こちらこそ、ありがとうございました。
次は ── 自分のコードで、この地図を、すこしだけ描き足してみます。
窓の外は、すっかり日が落ちていました。
序章で夕暮れだった研究室は、いつのまにか、夜の色に沈んでいます。
ホワイトボードには、ゲームと、最適化と、学習を、一本につなぐ図が、残されていました。

講師:
あと、より厳密な数学的定義や、実装の細かいところは、末尾の Appendix にまとめておこう。
今日たどった地図を、自分のコードや、原論文で確かめたくなったときの、足がかりにするといい。
ホワイトボードの図は、消さずに残しておくよ。
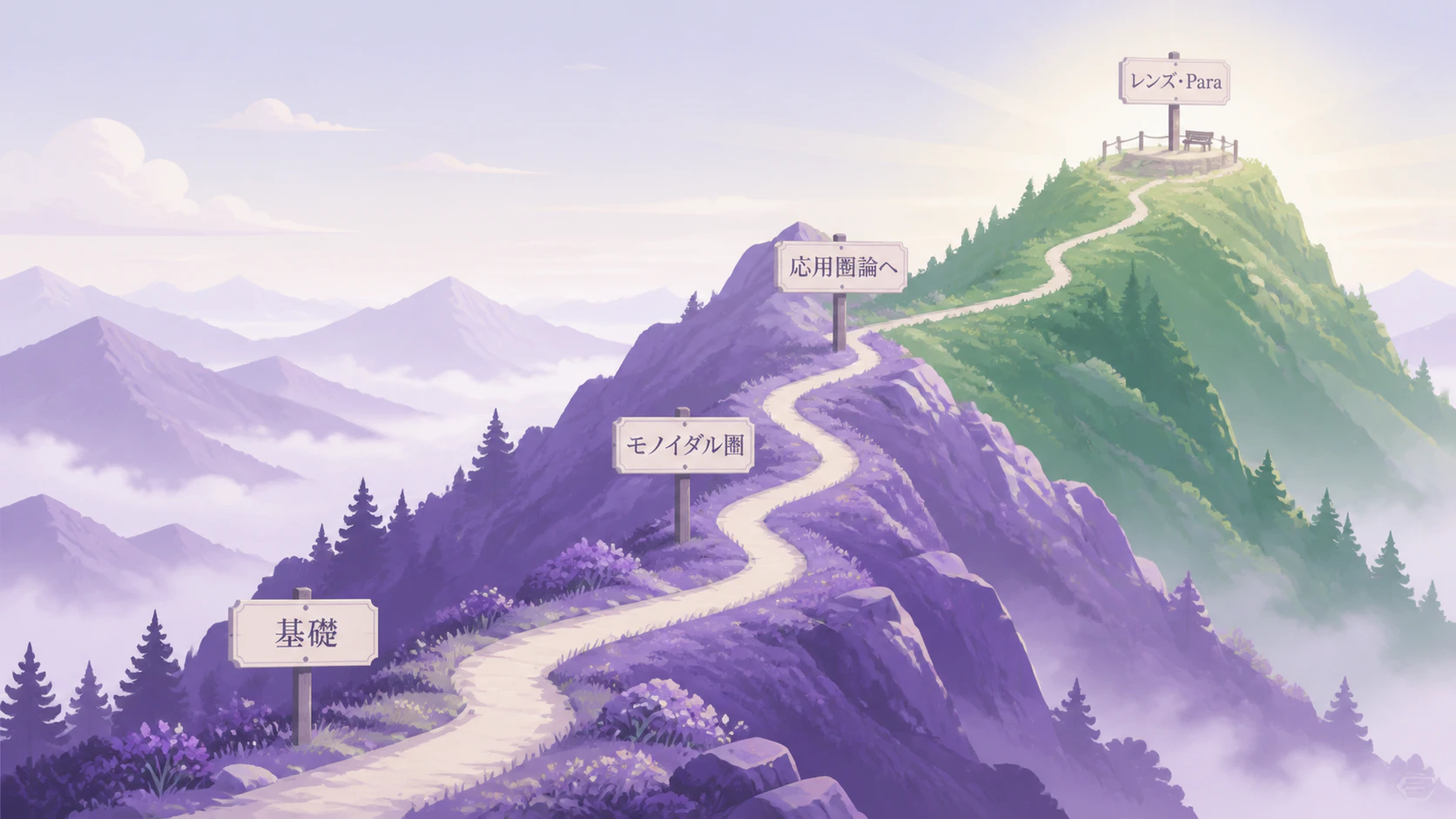
補講 ── 圏論学習のロードマップ:今日のレンズは、圏論のどこにあるのか
講師:
本筋は、ここまでだ。だが、最後にひとつ、寄り道の地図を渡しておきたい。
今日、君は 「レンズ」「Para」「学習器」「関手」と、いくつもの圏論の言葉 に出会った。
では、これらは、圏論という広い土地の、どのあたりにある概念なのか。
それを知っておくと、いつか自分で学び直すときの、道しるべになる。
学部生:
そう、それです。それ、今日研究室を退出する前に、聞いておかなきゃなって、考えていたんです。
今日の対話の中で登場したレンズや Para みたいな話は、圏論を本格的に学びはじめたとき、どのあたりで出てくる概念なんですか?
圏論の教科書の、最初のほうですか?
それとも、中盤の中級くらい?
あるいは、上級者が手に取る、専門の論文のなかでしょうか。
講師:
実はね、答えは、君が並べた3つの、どれでもない。
まず、ふつうの圏論の教科書 ── Awodey でも、Mac Lane でも、Riehl でもいい ── を開くと、最初に来るのは、決まってこの順番だ。
圏、関手、自然変換。
そして、同値、極限と余極限、米田の補題、随伴、モナド。
これが、古典的な圏論の「背骨」だ。
一学期ぶんの講義が、だいたいこれで埋まる。
学部生:
そのなかに、レンズ は・・・
講師:
出てこない。
正確に言おう。
レンズが乗っている 土台は、「モノイダル圏」── 縦につなぐ・横に並べる、という、今日も何度も出てきた、あの構造 だ。
ところが、その モノイダル圏でさえ、標準的な教科書では、本筋からは外された「発展的な話題」 の扱いなんだ。
Awodey は、自分の教科書の序文で、モノイダル圏や2-圏は、あえて入れなかった、と書いているくらいでね。
学部生:
土台のモノイダル圏からして、もう教科書の外なんですか。
講師:
そういうことだ。
だから、こう考えるといい。
古典的な教科書を、最初から順に登っていっても、その道の延長線上に、レンズは無い。
レンズは、別の山道にあるんだ。
圏・関手・自然変換、という基礎の尾根を登ったあと、そこから「モノイダル圏」「string diagram(ひも図)」という、応用圏論 のほうへ伸びる道に入る。
レンズや Para、そして今日のオプティックは、その先で、ようやく姿を現す。
多くは、教科書ではなく、研究の論文や、生まれたばかりの応用圏論の入門書 ── たとえば Fong と Spivak の『Seven Sketches』── のなかに、ある。
学部生:
じゃあ、最短ルートは ──
講師:
まず最初に、基礎(圏・関手・自然変換)を、ひととおり学ぶ。
そのうえで、モノイダル圏とひも図に親しむ。
そこまで来れば、今日のレンズの話は、もう「すぐ隣」にある。
逆に言えばね ── 君は今日、その古典的な背骨を全部は登らないまま、いきなり 応用圏論の尾根の、いちばん景色のいいところへ、近道で連れてこられた わけだ。
それでも、ちゃんと話が分かった。
それは、たとえ話と絵で、本質だけを先に渡したからだ。
いつか、ふもとから自分の足で登り直すと、「ああ、あのとき見た景色は、ここだったのか」と、つながる日が来るよ。
講師:
大事なことだから、もう一度、地図のかたちで整理しておこう。
まず、圏論の標準的な教科書 ── Awodey、Mac Lane、Riehl ── の中核は、これだ。
圏、関手、自然変換、同値、極限と余極限、関手圏、表現可能関手、米田の補題、随伴、モナド。
この並びが、古典的な圏論の背骨 だと思っていい。
Awodey は、計算機科学者向けの追加トピックとして、デカルト閉圏とλ計算を入れている。
だが、2-圏、トポス(深くは)、そしてモノイダル圏は、あえて含めなかった、と自分で明言しているんだ。
ここが肝心だ。
レンズや Para が乗っている土台は、モノイダル圏だったね。
そのモノイダル圏でさえ、標準教科書の、標準コースの外側にある。
そして、レンズそのものは ── これらの古典的な教科書のどこにも、項目として出てこない。レンズは、応用圏論という文脈のなかで育った、比較的新しい概念なんだ。
応用圏論の教科書 というもの自体、ようやく最近になって出はじめた。
Spivakが2014年に Category Theory for the Sciences を、Fong と Spivak が2019年に Seven Sketches in Compositionality(応用圏論への招待) を、それぞれ書いた。
まだ、その段階だ。
だから、レンズが体系立てて登場するのは、古典的な教科書ではなく、こうした応用圏論側の文献や、研究の論文のほう なんだよ。
学部生:
古典の背骨と、応用圏論の山道は、そもそも別の地図だった
── だから、教科書を順に読んでも、レンズには行き当たらない。腑に落ちました。
講師:
言葉だけだと、迷子になりやすい。
だから、今日の話が、圏論という土地のどこを通ってきたのか、一枚の地図にまとめておこう。
上から順に、古典的な背骨を登り、途中で応用圏論の山道へ分かれて、その先でレンズや Para に出会う。
今日たどった道筋を、まるごと描いてみると、こうなる。
Appendix:数学的補足
以下は、本文中で、「レンズ」「学習器」「関手」などとかみくだいた事柄の、より厳密な定義 です。
いずれも読み飛ばして構いません。関心のある方が、専門書や原論文へ進むときの足がかりとして添えておきます。
A-1. Learn 圏(学習器の圏)の厳密な定義
(Fong, Spivak, Tuyéras, “Backprop as Functor”, 2019)
集合 $A, B$ に対し、$A$ から $B$ への**学習器(learner)**とは、4つ組 $(P, I, U, r)$ である。ここで $P$ は集合(パラメータ空間)であり、
I : P \times A \to B, \quad U : P \times A \times B \to P, \quad r : P \times A \times B \to A
はそれぞれ実装関数・更新関数・要求関数と呼ばれる。
ふたつの学習器 $(P, I, U, r) : A \to B$ と $(Q, J, V, s) : B \to C$ の合成 $(P \times Q,, IJ,, UV,, r*s) : A \to C$ は、次で与えられる。
(I*J)(p, q, a) = J(q, I(p, a))
(U*V)(p, q, a, c) = \big(\, U(p,\, a,\, s(q,\, I(p,a),\, c)),\ \ V(q,\, I(p,a),\, c)\, \big)
(r*s)(p, q, a, c) = r\big(p,\, a,\, s(q,\, I(p,a),\, c)\big)
更新 $UV$ と要求 $rs$ の式に、下流の要求関数 $s$ が現れていることに注目してほしい。下流の部品が返す要求が、上流の部品の「正解」として渡されている ── これが、本文で述べた「クレームが、下流から上流へ、$r$ を伝って渡る」ことの、数式上の姿である。
学習器を、適切な再パラメータ化の同値関係で割ったものが、対称モノイダル圏 Learn をなす。
A-2. 勾配降下の関手
(同上)
$\mathrm{Para}(\mathrm{Smooth})$ を、なめらかな(微分可能な)パラメータつき写像の対称モノイダル圏とする。学習率 $\epsilon$ と、適当な条件(各 $x_0$ で $y \mapsto \dfrac{\partial e}{\partial x}(x_0, y)$ が可逆)をみたす誤差関数 $e$ を固定すると、次の対称モノイダル関手が定まる。
L_{\epsilon, e} : \mathrm{Para}(\mathrm{Smooth}) \to \mathbf{Learn}
この関手は、なめらかなパラメータつき写像に対し、勾配降下を実装する学習器を割り当てる。具体的には、順伝播の微分(勾配)から、更新関数 $U$ と要求関数 $r$ を構成する。
本文の「組み立てれば、学び方も自動で決まる」「学習が関手である(組み立てと、学び方の付与が交換する)」とは、この関手 $L_{\epsilon, e}$ が合成を保つ、という主張にほかならない。
なお、正確を期して、三点だけ補足する。第一に、関手であるのは「学習一般」ではなく、固定した $(\epsilon, e)$ のもとでの勾配降下の構成 $L_{\epsilon, e}$ である。
本文で「学習が関手」と縮めて言うのは、この構成を指している。
第2に、$\mathrm{Para}$ 構成として明示・一般化したのは後続の研究($\mathrm{A}\text{-}3$)であり、原論文(2019)の始域は、より直接に「微分可能なパラメータつき写像の圏」として与えられている。
第3に、$\mathrm{Para}(C)$ は厳密には再パラメータ化を高次の射に持つ双圏(2-圏)であり、本稿および上式では、それを通常の圏(1-圏)として簡略化して扱っている。いずれも、入門的な記述のための標準的な省略である。
A-3. パラメトリックレンズと、その後の発展
(Cruttwell, Gavranović, Ghani, Wilson, Zanasi, “Categorical Foundations of Gradient-Based Learning”, 2021 / “Deep Learning with Parametric Lenses”, 2024)
その後の研究では、学習器の構成は、Para 構成と Lens(レンズ) 構成を組み合わせた パラメトリックレンズ(parametric lens) として、より一般的に整理されている。
レンズ は、順方向の写像と逆方向の写像を、ひと組にした双方向の射である。
順方向が「行きの加工」、逆方向が「帰りの注文返し(勾配の逆伝播)」にあたる。
逆微分圏(reverse derivative category)という構造 を用いると、この逆方向を、順方向の微分から、きちんと定めることができる。
この枠組みでは、損失関数(平均二乗誤差・ソフトマックス交差エントロピーなど)や、最適化アルゴリズム(素朴な勾配降下・モメンタム・Adam・AdaGrad・Nesterov など)が、いずれも特定のレンズ/パラメトリック射として表され、統一的に扱うことができる。
本文で触れた Python 実装(MNIST 分類を Keras と同等精度で再現)は、この定式化にもとづく。
この「逆方向」を、数学としてきちんと支えているのが、逆微分圏(reverse derivative category) という構造である。
少し説明しておこう。
ふつう「微分」というと、順方向の微分を思い浮かべる。入力を少し動かすと、出力がどれだけ動くか、を測るものだ。これを、圏論で公理化したもの を、デカルト微分圏(Cartesian differential category)という。
逆微分圏は、その「逆向き」を公理化したものだ。
Cockett・Cruttwell ら(2019)が、機械学習と自動微分の根幹にある「逆微分」という操作を、デカルト微分圏と同じ流儀で、直接、圏の言葉に書き下した。
中身は、各部品に「逆微分」という操作を割り当てるもので、それが満たすべき7つの規則(公理)として定められている。
この構造のうれしさは、ふたつある。
ひとつは、逆連鎖律。
部品をつないだとき、出力側で測った変化が、後ろの部品から前の部品へと、逆向きに流れて、入力側の変化を計算する。これは、まさに逆伝播そのものだ。本文で「クレームが下流から上流へ伝わる」と呼んできたものの、数学的な姿である。
もうひとつ は、レンズとの直結だ。
ある部品とその逆微分を、ひと組にすると、ちょうどレンズになる。
逆微分を持っていることが、ふつうの部品を「情報を後ろへ流せる部品=学習できる部品」に変える。
なめらかな写像の場合、この逆微分は、ヤコビ行列の転置を掛ける操作にあたる。順伝播のヤコビ行列を、転置して逆向きに使う
── つまり、深層学習の逆伝播で、実際に行われている計算と、ぴたりと重なる。
面白いことに、逆微分を持つ圏は、順微分も自動的に持つ。
だが、逆は成り立たない。
順微分があっても、逆微分があるとは限らない。
逆微分のほうが、構造として一段豊かなのだ。
その「豊かさ」の正体が、逆伝播を可能にしている、というわけである。
A-4. 学習とゲームをつなぐ関手
(Jules Hedges, "From open learners to open games", arXiv:1902.08666, 2019)
「開いた学習器(open learner)」── Fong・Spivak・Tuyéras の圏 Learn の、入出力の境界を持つ版 ── のなす圏から、「開いたゲーム(open game)」── 前々回の Ghani・Hedges・Winschel・Zahn の圏 ── のなす圏への、忠実な対称モノイダル関手が存在することを、Hedges が証明した。
これにより、フィードバック等の複雑な機構を持たない教師ありニューラルネットワークは、標準的なやり方で、ひとつの開いたゲームと見なせる。
直観的には、各パラメータが別々のプレイヤーによって制御され、ゲームの最善反応関係が、勾配降下の力学を符号化する。前々回のナッシュ均衡(最善反応の不動点)と、本記事の学習の収束が、ともに「不動点」として現れる、という本文の主張の、厳密な背景である。
正確には、こうである。
勾配降下が到達するのは損失関数の臨界点(多くの場合は局所最適)であり、それが「均衡」に対応するのは、上の関手によって誘導される開いたゲームのもとで、各プレイヤーの最善反応がつり合う不動点として、である。
「学習の収束=ゲームの均衡=不動点」という対応は、この誘導されたゲームを介して成り立つ、という意味だと捉えてほしい。
この洞察は後に、Capucci・Gavranović・Hedges・Rischel「Towards Foundations of Categorical Cybernetics」(ACT 2021、arXiv:2105.06332)で、学習器とゲームの双方を「環境とコントローラに双方向に作用するプロセス」という共通の枠組み(圏論的サイバネティクス)のもとに一般化された
── 前回の対話で触れた、レンズ/オプティックによる「双方向の部品」の統一が、これにあたる。
なお、本記事の第9幕で触れた、この対応を実装に展開した近年の例として、各層を個別の開いたゲームとし、ネットワークをその逐次合成として扱う研究がある
("Game-Theoretic Gradient Control for Robust Neural Network Training", 2025, arXiv:2507.19143)。
A-5. 既存のフレームワーク(PyTorch・TensorFlow)との関係 ── 実務者への補足
第7幕で紹介した >>・@ による組み立てと、numeric-optics-python の位置づけについて、日々 PyTorch や TensorFlow を書く方のために、現実的なところを補足します。
まず、はっきりさせておきます。
numeric-optics-python は、研究のための概念実証(proof-of-concept)の実装であり、PyTorch や TensorFlow を置き換える、本番運用のためのライブラリではありません。
日々の開発では、引き続き成熟したフレームワークを使うのが現実的です。「明日から >> でプロダクトを書く」という話ではない、という意味です。
では、この枠組みの実務的な価値は、どこにあるのか。大きく三つです。
-
第1に、見通し(説明)の枠組みとして。
PyTorchで書いた既存のモデルを、「双方向の部品(パラメトリック・レンズ)の合成」として捉え直すと、順伝播と逆伝播のつながり方が、数学的に透明になります。フレームワークが裏で面倒を見てくれている部分の「なぜ」が、見えるようになります。
-
第2に、検証・解析のための足場として。 本文(第8幕・第9幕)で触れたとおり、モデルを「構造を保つ部品の合成」として書けることは、将来的に、振る舞いを形式的に検証するための土台になりえます。
numeric-optics-pythonのような実装は、その方向の研究・実験のための、小さく見通しのよい試験台です。実際、原論文では同じモデルをKerasでも実装し、結果を突き合わせています
── 既存環境を「答え合わせ」の基準として併走させる、という使い方です。
だから、いまの段階での正しい付き合い方は、「PyTorchの代替」ではなく、「PyTorchと並走させ、構造を理解・検証したいときに重ねる、別系統の検証用フレームワーク」と捉えることです。
-
第3に、設計の指針として。 第8幕の
CycleGANのように、「部品をどう組み合わせるか」という圏論的な視点そのものが、新しいアーキテクチャの設計を導くことがあります。これは、どのフレームワークで実装するかとは独立した、一段上の見方です。
まとめると、現時点では、この枠組みは「PyTorch の代替」ではなく、「PyTorch で書くものを、より見通しよく捉え、設計し、いつか検証するための、共通の数学的な言葉」だと位置づけるのが正確です。
実装の足場が要るなら既存フレームワークを使い、構造を理解・検証したいときに、この圏論的なレンズを重ねる。
そういう共存のしかたになります。
参考文献・出典
圏論と機械学習(学習の合成的定式化)
- Brendan Fong, David I. Spivak, Rémy Tuyéras, “Backprop as Functor: A compositional perspective on supervised learning,” Proceedings of LICS 2019, pp. 1–13. arXiv:1711.10455.
- G. Cruttwell, B. Gavranović, N. Ghani, P. Wilson, F. Zanasi, “Categorical Foundations of Gradient-Based Learning,” ESOP 2022. arXiv:2103.01931.
- G. Cruttwell, B. Gavranović, N. Ghani, P. Wilson, F. Zanasi, “Deep Learning with Parametric Lenses,” 2024. arXiv:2404.00408.
- Numeric Optics(Python実装): statusfailed/numeric-optics-python(Paul Wilson ほか)
層を >>(合成)・@(テンソル)でつなぎ、MNIST 分類を Keras と同等精度で再現している。
リポジトリの説明にも、モデルは基本部品の >>(composition)と @(tensoring)で構築すると明記されている(例:linear >> bias >> activation)。
- Bruno Gavranović, “Compositional Deep Learning,” 2019. arXiv:1907.08292.
(コード実装)
- Bruno Gavranović, “Fundamental Components of Deep Learning: A category-theoretic approach,” PhD thesis, 2024. arXiv:2403.13001.
学習とゲームの接続
- Jules Hedges, “From open learners to open games,” 2019. arXiv:1902.08666.
open learner から open game への忠実な対称モノイダル関手を証明した論文。
教師ありニューラルネットワークは、ある意味で開いたゲームと見なせる。
- M. Capucci, B. Gavranović, J. Hedges, E. F. Rischel, “Towards Foundations of Categorical Cybernetics,” ACT 2021, EPTCS 372 (2022). arXiv:2105.06332.
学習器とゲームを「環境とコントローラに双方向に作用するプロセス」として一般化(圏論的サイバネティクス)した論文。
- “Game-Theoretic Gradient Control for Robust Neural Network Training,” 2025. arXiv:2507.19143.
https://arxiv.org/abs/2507.19143
上記の対応を実装に展開した論文。
各層を個別の open game とし、ネットワークをその逐次合成として扱う近年の概念実証。
前々回・前回の記事(同シリーズ)
この記事で扱った人物・大学はフィクションですが、理論・論文・実装は、すべて実在する研究にもとづいています。本文中のコードは、概念を伝えるためのイメージであり、実際の API は各論文とその公開実装をご参照ください。