
この記事は、架空の大学「圏峰(けんぽう)工科大学」の研究室を舞台にした、ひとつの対話篇です。
登場するのは、自然言語処理に興味を持ちはじめた学部生と、圏論・量子計算を専門とする若手専任講師のふたり。
人物や大学はフィクションですが、扱う中身(理論・ライブラリ・実験)は、すべて実在する研究と技術にもとづいています。出典は記事末にまとめました。
想定読者は、高校の数学はだいぶ忘れたけれど、毎日 Python のコードを読み書きしているエンジニア・データサイエンティスト・機械学習エンジニア・AI リサーチャーの皆様です。
むずかしい言葉は、初めて出てくるところでかみくだいて説明します。数式が出てきても、読み飛ばして大丈夫なように書きました。
TL;DR ── この記事で分かること(お急ぎの方へ)
QNLP(量子自然言語処理) とは、「猫が魚を食べる」のような文を、量子回路に変換して、量子コンピュータの上で意味を計算する技術です。

lambeq(ランベック)という Python ライブラリで、実際に文を量子回路に変換できます。
Transformer や LLM が「大量のテキストから、意味を統計的に学習する」のに対し、QNLP は「文法構造そのものを、計算の骨格として利用する」
── 同じ「言語を扱う」でも、発想がまったく別の系譜です。
文法の配線図と量子回路が同じ数学的構造を持つことを利用して、文をそのまま量子回路へ写します。
これは、量子版 Transformer」でも「LLM の置きかえ」でもなく、もう一つの言語理解のアプローチです。

何ができるのか(現時点)
- 文の分類(例:その文が「料理の話」か「IT の話」かを判定する)
-
感情分析(肯定的か否定的か)
- 簡単なタスクでは、従来の古典的手法と互角の結果が、すでに小規模な量子ハードウェア上で示されている
期待されている実用メリット ── 産業界が注目する「2つの軸」
1. 説明可能なAI(Explainable AI, XAI):
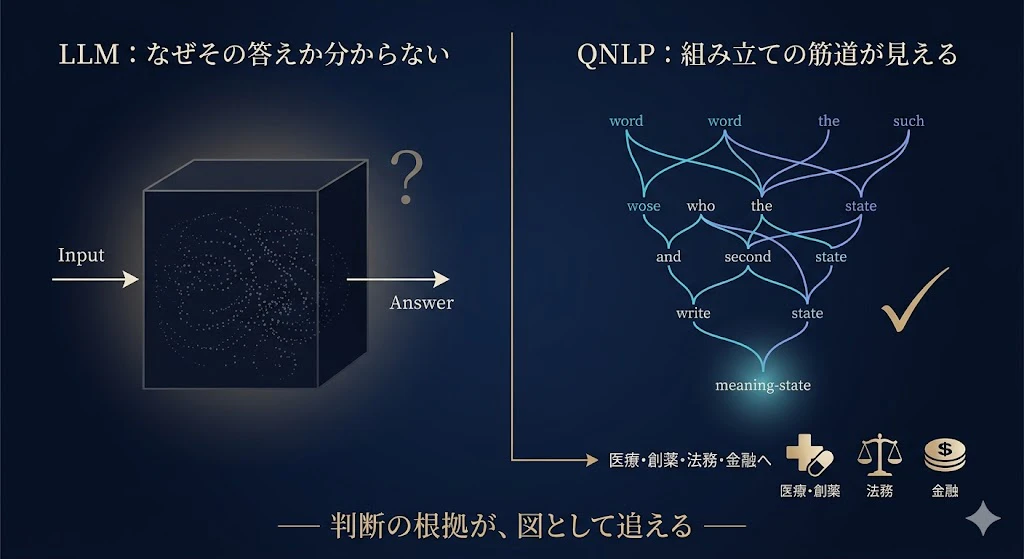
- 意味が「どの単語から、文法にそってどう組み上がったか」が配線図(図)として残る。
- LLM の「なぜその答えになったか分からない」ブラックボックス性と対照的で、意味の組み立ての筋道が、図として追える。医療・創薬・法務・金融など「判断の根拠」が問われるハイステークスな分野で価値が期待される(実際に製薬大手メルクが評価)。
- 圏論的量子力学の生みの親 Bob Coecke たちは、これを、「合成的解釈可能性(compositional interpretability)」 として、説明可能AI(XAI)の理論的枠組みにまで一般化している(2024)。
2. 量子の大容量・高速計算性:
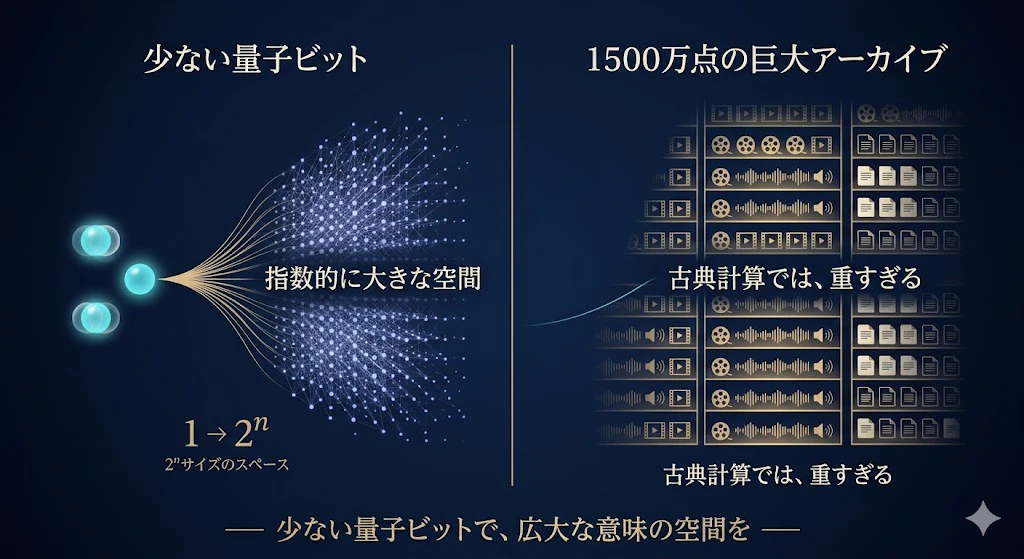
- 量子ビットは「重ね合わせ」により、1量子ビットで複数の状態を同時に保持でき、$n$ 量子ビットで $2^n$ 次元という指数的に大きな空間を扱える。
- 文の意味のような高次元データを少ない量子ビットで表せる可能性があり、将来、量子ハードウェアが育てば、大容量データの高速処理で優位になりうる、と期待されている。
- たとえば BBC は、1500万点超の巨大アーカイブ(古典計算では検索が重すぎる規模)の検索への応用を、UCL・Quantinuum と探っている。
- 応用先として、ほかにも対話・テキストマイニング・翻訳・音声合成・言語生成・バイオインフォマティクスが挙げられている。
- さらに近年、「計算を誤らない・バグの潜まないAI」を形式検証・定理証明で保証したいという、社会インフラ・自動運転・ドローンなど安全が最優先の分野のニーズと、QNLP の説明可能性・合成的な構造が将来つながりうる、という議論も出はじめている(詳細は本文「第9幕」で後述)。

どれくらい注目されているのか
- 中心にいるのは、量子計算企業 Quantinuum(オックスフォードに専任の「Quantum NLP & 合成的量子知能」研究グループのチーフサイエンティスト Bob Coecke氏とAI 責任者 Stephen Clark氏です)。
- 大学では、 オックスフォード大学、ユニバーシティ・カレッジ・ロンドン(UCL、Mehrnoosh Sadrzadeh)、米国の ノートルダム大学・インディアナ大学などの名門大学に、研究グループや study groupがある。日本でも、中部大学(量子測定論で著名な小澤 正直氏)が、Quantinuumと量子AI・認知の共同研究を行っている。
- 産業・公共との連携も始まっており、英国放送協会(BBC)が UCL・Quantinuum と、巨大アーカイブ(1500万点超)の検索への QNLPの応用先を探るコンソーシアムを組んでいる(英国王立工学アカデミーが出資)。
- 専任の研究グループ・国際会議・商用ツール(lambeq)・産業コンソーシアムが揃いつつある、「黎明期だが、産学で本格的に立ち上がりはじめた」段階。
現状と課題
- まだ研究段階で、いまの大規模言語モデル(LLM)と性能を競うものではありません。量子ハードウェアも、ノイズの多い小規模な世代(NISQ)です。
- それでも、「言語と量子が同じ数学でつながる」という発見の深さと、産学の本気度から、長い目で見て育っていく分野として注目されています。
なお、現時点の QNLP は、あくまで研究段階で、LLM を置きかえる技術ではありません。
この記事の目的は、性能比較ではなく、「なぜ文法と量子がつながるのか」を腑に落とすことです。
以下、その仕組みと意味を、対話形式でじっくりほどいていきます。
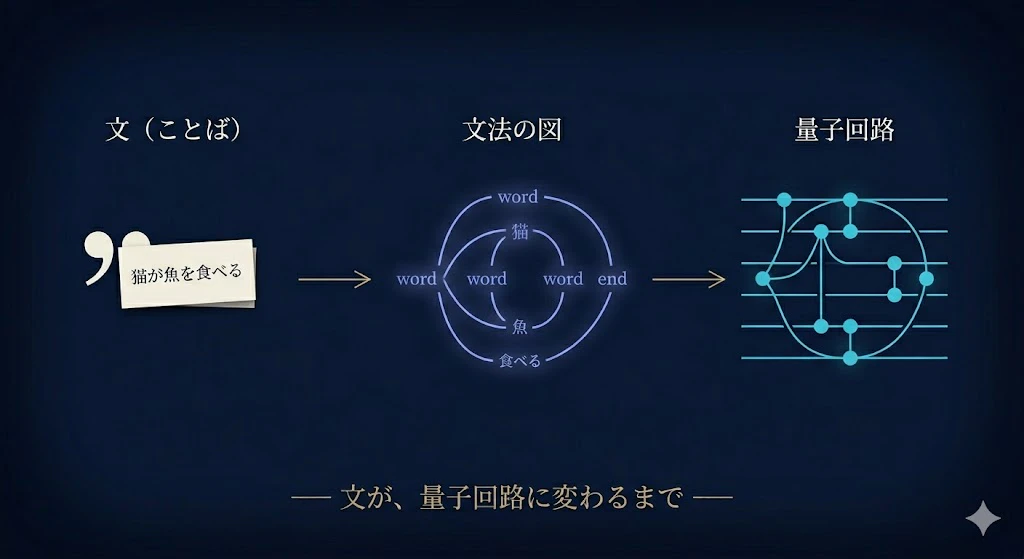
序章 ── 「文が量子回路になる」って、具体的にどういうこと?
学部生:
先生、いきなり核心からなんですが ──「文を量子回路にする」って、具体的に何をどうするんですか?
「猫が魚を食べる」みたいな文が、どうやって回路になるのか、まったくイメージが浮かびません。

講師:
いい入り方だ。
具体例で一気にいこう。
英語の "skillful programmer prepares software"(熟練したプログラマーがソフトを用意する)という文を例にする。
3つのステップに分けて考えてみようか。
ステップ1:文法を読み取って、配線図にする。
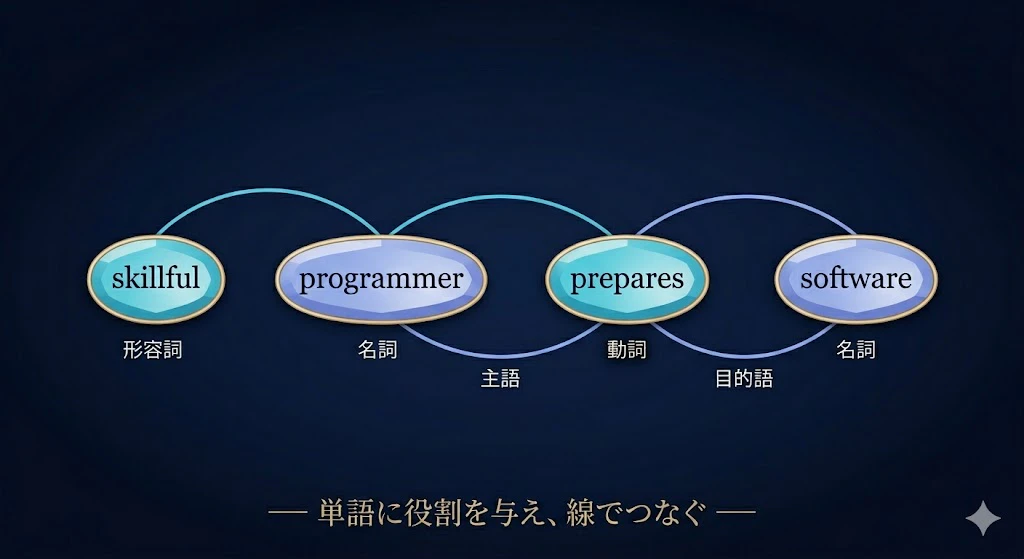
まず、各単語に「役割」を割り当てていくよ。
programmer・software は名詞、prepares は動詞、skillful は名詞を修飾する形容詞。
そして、「主語 ← 動詞 → 目的語」「形容詞 → 名詞」というつながりを、線でつないだ図にする。
これは、ふだん意識しない「文の骨組み」を、配線図として目に見える形にしたものだ。
学部生:
文を、いったん「部品と配線の図」にするんですね。
講師:
そうだ。
ステップ2:単語を、量子状態に対応させる。
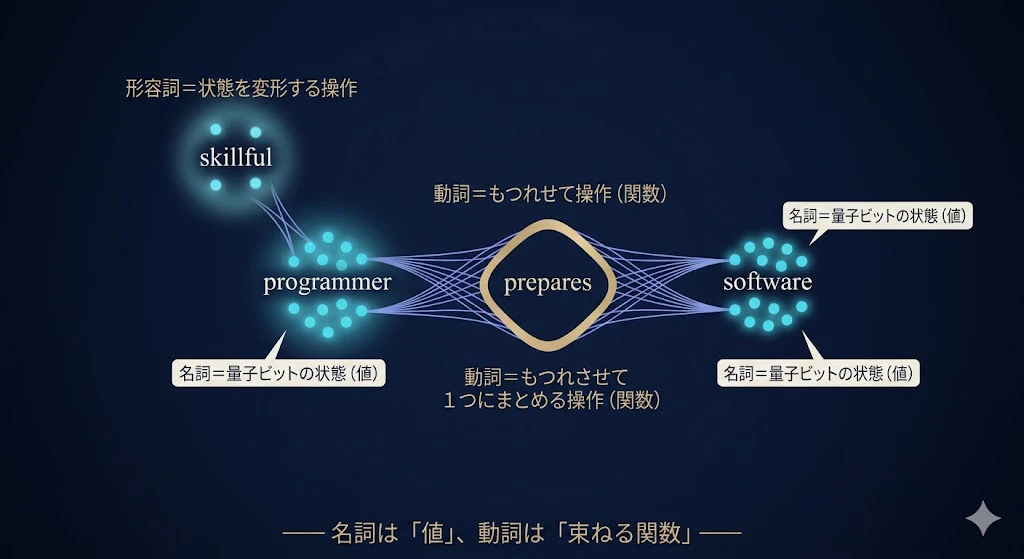
次に、配線図の各単語に、中身を入れていくよ!
programmerという名詞の単語を、いくつかの量子ビットの状態として表す。
preparesという動詞の単語は、主語と目的語の量子ビットをもつれさせて、1つの状態にまとめる操作として表す。
形容詞は、名詞の状態を少し変形する操作だ。
学部生:
名詞が「データ」、動詞が「データを束ねる操作」。
プログラムの値と関数の関係に、そっくり ですね。

講師:
まさにそうだ。
学部生:
……あれ。待ってください。
「異なる領域が、同じ構造を共有している」 って ── それ、もしかして カリー・ハワード対応と同じ話ですか?
論理の証明と、プログラムが、同じ構造だっていう、あれです。
あと、まったく違う分野のあいだに本質的な同じ構造を見つける圏論そのものとも。
……いや、それを言ったら、兄貴の専門の ラングランズ・プログラムとも、どこかつながっていたりしませんか?
講師:
……いい嗅覚だね。しかも、ほとんど当たっている。簡単にだけ答えよう。
まず、きみがさっき言った 「名詞=値、動詞=関数」 ── あれは偶然じゃない。
カリー・ハワード対応は、「論理の証明」と「プログラム」が同じ構造を持つ、という発見だ。
そこに、圏論を加えた カリー・ハワード・ランベック対応という三つ巴の対応もある。

学部生:
ランベック……あれ、その名前、さっき lambeq のところで。
講師:
そう、同じ Joachim Lambek だ。
QNLP の文法(プレグループ文法)を作った人と、この対応に名を残した人は、同一人物なんだ。
論理・プログラム・圏論・そして言語 ── これらが同じ骨格を持つ、という話の、ちょうど結び目にいた人だよ。

学部生:
じゃあ、ラングランズは?
講師:
そこは、慎重に言うね。
ラングランズ・プログラムが、QNLP やカリー・ハワードと「同型だ」と言うのは、言い過ぎだ。
直接の数学的な同型関係があるわけじゃない。
ただ ── 「まったく別々に見える分野(数論と幾何)が、深いところで対応している」という、壮大な橋渡しの精神において、よく似ている、とは言える。
実際、カリー・ハワード・ランベックを「言語と論理の小さなラングランズ」になぞらえる人もいるくらいだ。
あくまで精神的な親戚、という距離感だね。
学部生:
精神的な親戚。なるほど、それくらいの言い方が、ちょうどいいんですね。
講師:
そういうことだ。この話は、深掘りすると一本どころか何本も記事が書ける大鉱脈でね。
この記事の最後の「関連する話題」で、地図だけ少し眺めてみよう。
本格的な解説は、また別の Qiita 記事で、じっくりやることにするよ。
ステップ3:全体を、1つの量子回路として組み立てて、実行する。
いま描いた配線図にそって、これらの量子状態と操作をつないでいくと、文全体が1つの量子回路になる。
それを、量子コンピュータ(または、ふつうのパソコン上のシミュレータ)で実行して測定すると、文の意味に対応する状態を得ることができるんだ。
学部生:
$「文 → 配線図 → 量子回路 → 実行」$。
一本の流れになるんですね!
これ、本当にコードで書けるんですか。
講師:
素晴らしいことに、ちゃんとコードで書ける。
Quantinuum 社が公開している lambeq(ランベック)という Python ライブラリが、まさにこの3段をやってくれる。
pip install lambeq して、文を渡すと、構文解析して配線図にし、量子回路に変換してくれる。
"skillful programmer prepares software" と入れれば、対応する量子回路がそのまま出てくるんだ。

学部生:
日本語でもできるんですか。
講師:
仕組みとしてはできる。
理論(あとで話す DisCoCat という枠組み)は、特定の言語にしばられていないからだ。
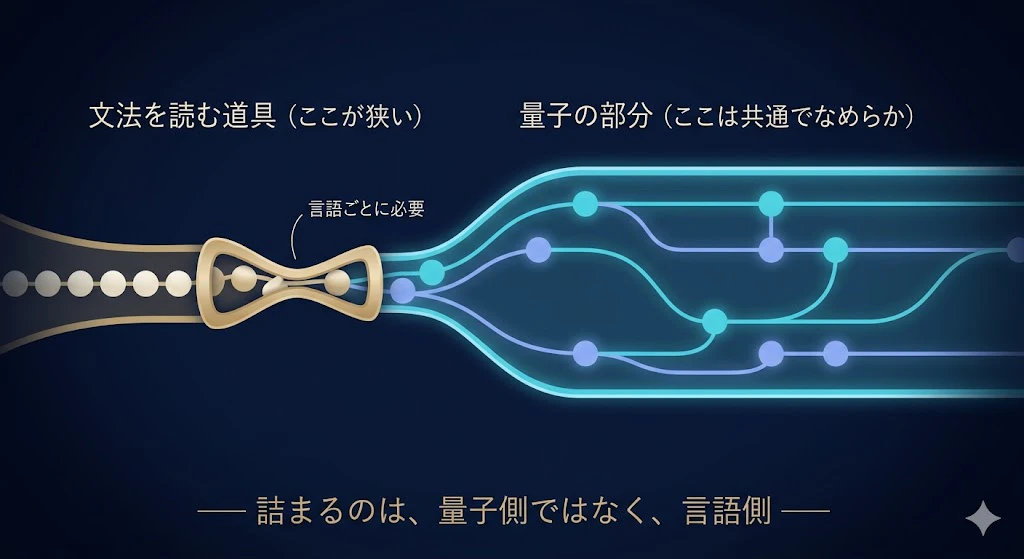
ただ、実装の面では、文を配線図にする「構文解析器(パーサ)」が言語ごとに必要でね。
lambeq に標準で付くのは英語向けで、日本語に使うなら日本語用のパーサ(たとえば DepCCG)を別に用意してつなぐ。
実際、ヒンディー語のような英語以外の言語に適用した研究も出ている。
ボトルネックは量子側じゃなく、「その言語の文法を読む道具」がどれだけ整っているかにある
── これは従来の自然言語処理と同じ事情だね。(この点は、あとの第7幕でも詳しく触れる。)
学部生:
なるほど。で、いちばん聞きたいんですが ── それができると、何が嬉しいんですか?
いまは、LLMがなんでもやってくれますよね?

講師:
現状と期待を分けて答えよう。
まず、QNLPを用いて、いま実際にできるのは、主に文の分類だ。
たとえば、ある文が「料理の話」か「ITの話」かを判定する。
あるいは、感情分析 ── その文が肯定的か否定的か。
こうした二値分類のタスクで、簡単なものなら、すでに従来の古典手法と互角の結果が、小規模な量子ハードウェア上で示されている。
学部生:
互角、ということは、まだ「勝ってはいない」と。
講師:
そこは誇張しない。
いまの LLM と性能を競う段階ではない。
量子ハードウェアも、ノイズの多い小規模な世代だしね。
だから、QNLPが持つ価値は「速さ」や「精度」より、別の軸にある。
QNLPに期待される役割
期待されている実用メリットは、大きく2つある。
ひとつは、説明可能なAI。
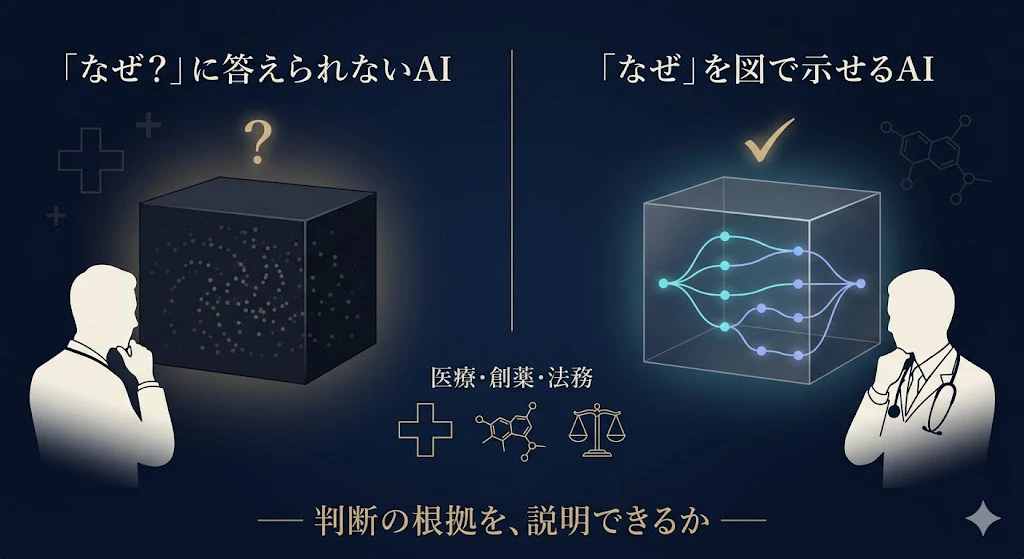
QNLP では、文の意味が「どの単語から、文法にそってどう組み上がったか」が、配線図としてはっきり残る。LLM が「なぜその答えになったか分かりにくい」ブラックボックスなのと、対照的だ。
意味の組み立ての筋道が見える。
これは、医療や創薬、法務のように「判断の根拠」が問われる分野で効いてくる。
実際、製薬大手のメルクが早くから lambeq を評価して、「QNLP は説明可能なAIへの道を開く。医療では、正確さと同時に説明責任が決定的に重要だ」と述べている。
学部生:
意味の組み立てが、図として説明できる。
たしかに、医療の世界では、「なぜこう判断したか言えない AI」は怖いですよね。
講師:
もうひとつは、量子の大容量・高速計算性だ。
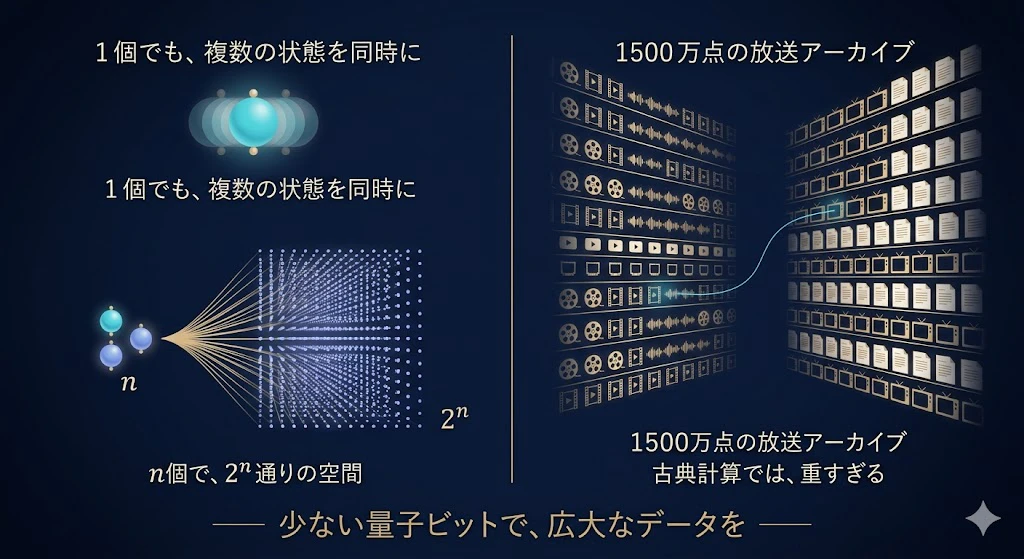
量子ビットは「重ね合わせ」で、1個(1量子ビット)でも複数の状態を同時に抱えられる。
この量子ビットが$n$ 個あれば $2^n$ 通りという、指数的に大きな空間を扱える。
文の意味のような高次元データを、少ない量子ビットで表せる可能性がある。
だから将来、量子ハードウェアが育てば、巨大なデータの処理で有利になりうる、と期待されている。
たとえば、 BBC は、1,500万点を超える巨大アーカイブ ── 古典コンピュータでは検索が重すぎるほどの規模 ── の content discovery(内容にもとづく発見)やアーカイブ検索に QNLP が使えないか、UCL・Quantinuum と組んで探っている。
学部生:
放送局の巨大アーカイブの検索……それは生々しい応用ですね。
講師:
応用先として名前が挙がっているのは、ほかにも対話システム、テキストマイニング、翻訳、音声合成、言語生成、バイオインフォマティクスだ。どれもまだ「将来の可能性」だが、研究の旗は立っている。それに、もうひとつ ── 「絶対に間違えてはいけない AI」を作る、という大きな課題とも、この説明可能性はつながってくる。これは後半(第9幕)でじっくり話そう。
QNLP 研究コミュニティの大きさ
学部生:
正直、QNLP なんて初めて聞きました。
これ、どれくらい本気でやられているんですか。一部の人の趣味、という規模じゃないんですよね?
講師:
趣味の規模ではないね。
中心にいるのは、量子計算企業の Quantinuumだ。
オックスフォードに「Quantum NLP & 合成的量子知能」という専任の研究グループを構えていて、率いるのは圏論的量子力学の生みの親 Bob Coecke、AI 責任者は Stephen Clarkだよ。
大学では オックスフォード大学、UCL(Mehrnoosh Sadrzadeh)、米国の ノートルダム大学やインディアナ大学などに研究グループがある。
日本でも、量子測定論で世界的に有名な小澤正直氏のいる 中部大学が、Quantinuum と量子AI・認知の共同研究を進めている。
学部生:
大学だけじゃなく、企業や、放送局まで。
講師:
そうなんだよ。
Quantinuum という商用プレイヤー、
lambeq という公開ツール、
BBC を巻き込んだ産業コンソーシアム(英国王立工学アカデミーが出資)、
そして、 QNLP をテーマにした国際会議やワークショップも開かれている。
まだ黎明期だけど、「論文の中だけの空想」じゃなく、産学が本気で立ち上げにかかっている分野なんだ。

学部生:
今後、メジャーになるんでしょうか。
講師:
それは誰にも断言できない ── 量子ハードウェアがどこまで育つかに懸かっているからね。
でも、僕はこう見ている。
「言語」と「量子」という、まったく無関係に見えるものが、同じ数学の骨格を共有している。
その発見の深さと、産学の本気度を考えると、たとえ将来の主役にならなくても、追いかける価値のある問いだ。
── さて、ここまでが、QNLPの全体像の説明 だ。
次の第2幕から、なぜ文法と量子が「同じ形」になるのか、その心臓部を、ゆっくりほどいていこう。
第2幕 ── 「文を、量子回路にする」って、どういうこと?
自然言語処理(NLP)といえば、いまや Transformer と大規模言語モデル(LLM)の全盛期です。
けれど、それとはまったく別の系統から、「文の意味を、量子コンピュータで計算する」という、少し信じがたいアプローチが育っているのをご存じでしょうか。
念のため、先に誤解をひとつ解いておきます。

QNLP は「量子版 Transformer」ではありません。
むしろ、Transformer とは異なる発想から生まれた、もう一つの言語理解の系譜です。
LLMが大量のテキストから「統計的に」意味を学ぶのに対し、QNLP は文法構造そのものを計算の骨格に使います
── 競合というより、目のつけどころが違うのです。
その名を 量子自然言語処理(QNLP, Quantum Natural Language Processing) といいます。
そして、それを動かすための Python ライブラリ lambeq(ランベック) が、すでに無料で公開されています。
pip install して、文を放り込むと、その文が量子回路に変換されて出てくるのです
(標準でよく動くのは英語ですが、仕組み自体は言語を選びません ── この点は、あとで詳しく触れます)。
「文が、量子回路になる」。
字面だけ見ると魔法のようですが、その裏には、文法と量子が、同じ数学の形をしているという、美しい発見があります。
この記事では、その仕組みを絵とコードでほどき、最後に「いまの LLM とは何が違うのか」まで、対話でたどっていきます。
第3幕 ── 文法って、もしかして「計算の設計図」?
学部生:
先生。
「文を量子回路にする」と聞いて、まず引っかかったんです。
文って、ただの単語の並びですよね?
それが、どうやって「回路」みたいな構造になるんですか。
講師:
いい引っかかり方だ。
鍵は「文法」にある。
ふだん意識しないけど、文には、単語をつなぐ見えない骨組みがあるよね?
「猫が魚を食べる」という文を考えてみよう。
学部生:
主語が「猫」、目的語が「魚」、動詞が「食べる」、ですね?
講師:
そうだね。
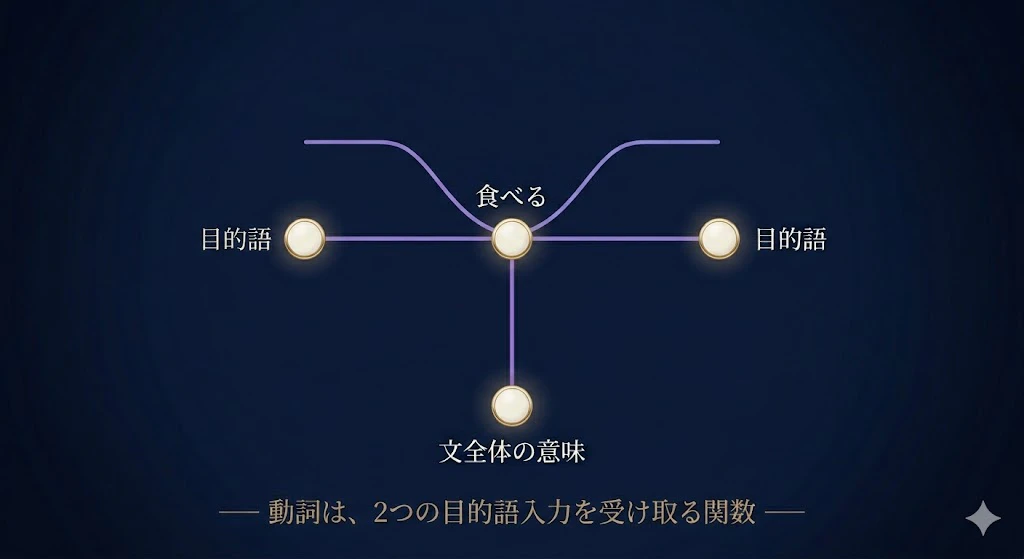
ここで、動詞「食べる」に注目してほしい。
「食べる」は、単独では宙ぶらりんだ。
左から主語を、右から目的語を受け取って、はじめて「文全体の意味」を返す。
これ、プログラマの君には、見覚えのある形じゃないか?
学部生:
あ……引数を2つ取る関数だ。
eat(猫, 魚) みたいな。
講師:
まさにそれだ。
きみのその直感は、実は数学的にほぼ正確なんだ。
動詞は、「2つの入力を受け取って、1つの出力を返す部品」。
名詞は「値そのもの」。
つまり、文法とは、部品どうしの“配線図” なんだよ。
どの単語が、どの単語に、どうつながって意味を作るか
── その配線の規則が、文法の正体だ。
学部生:
文法を「配線図」と見る……考えたこともなかったです。
講師:
この見方を、数学的にきっちり定式化したのが、プレグループ文法(pregroup grammar) というものでね。
言語学者ヨアヒム・ランベック(Joachim Lambek) が作った仕組みだ。
さっきの lambeq というライブラリの名前は、この人へのオマージュなんだよ。
読み方も「ランベック」だ。
学部生:
ライブラリ名に、人の名前が隠れていたんですね。
講師:
プレグループ文法では、それぞれの単語に「型(タイプ)」を割り当てる。
名詞には名詞の型を、
動詞には「左から名詞、右から名詞を受け取って文を返す型」を、
割り与える。
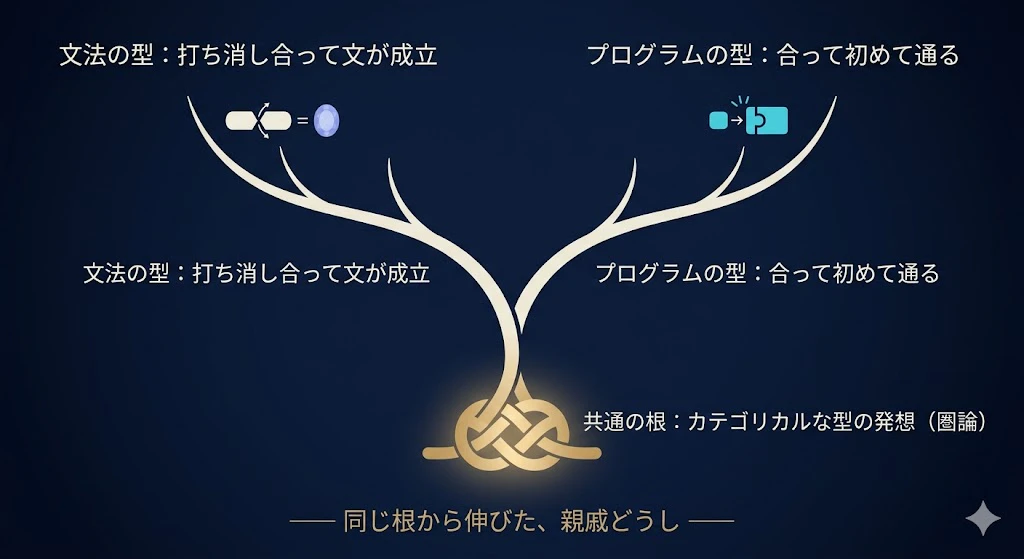
そして、となり合う型がうまく“打ち消し合う”と、文全体が「正しい文」として成立する。
学部生:
その「打ち消し合う」が、よく分かりません。型が消える、ってどういうことですか。
講師:
いい質問だ。
プログラムの「引数の消費」を思い出すといい。
たとえば関数 f(x) は、x をひとつ受け取ると、その引数の口がひとつ埋まって消えるよね。
プレグループの「打ち消し合う」も、それとそっくりなんだ。
動詞「食べる」を、こう考えてみよう。
動詞は、**左に「名詞を一つ食べる口」、右にも「名詞を一つ食べる口」**を持っている。
(左に名詞の口)── 食べる ──(右に名詞の口)
ここに「猫」(名詞)が左から、「魚」(名詞)が右から来る。
すると ──
- 左の口に「猫」がはまる → 口と名詞がぴたりと合って、消える
- 右の口に「魚」がはまる → これも消える
口がぜんぶ埋まって消えたあとに、最後に残るのが「文」という型だけ。
これが、「打ち消し合って、文が成立する」ということなんだ。
学部生:
なるほど。
動詞の「名詞をくれ」という口に、隣の名詞がぴたっとはまって、両方消える。
最後に「文」だけが残れば、文法的に正しい、と。
講師:
まさにそうだ。
逆に、口が埋まらずに余ったり、はまるべき名詞がなかったりすると、打ち消し合いが完成せず、「文として成立しない」と判定される。
プログラムで、関数に渡す引数が足りなかったり、型が合わなかったりするとコンパイルが通らない ── あの感覚に、本当にそっくりなんだよ。
学部生:
……あれ、いま「型が合わないとコンパイルが通らない」と言いましたよね。
そうすると ── データの型と関数の型の整合性を、コンパイル時に厳密に検証する関数型プログラミング言語 ── Haskell とか Idris とか ── と、QNLP は相性がいいんですか?
型で正しさを保証する、という発想がそっくりに見えて。
講師:
鋭いところを突くね。
思想のレベルでは、確かに地続きだ。
さっき名前の出た Joachim Lambek は、実は型理論の重要な仕事もしていてね。
プレグループ文法の「型が打ち消し合って文が成立する」という考え方 と、関数型言語の「型が合って初めてプログラムが通る」という考え方 は、同じカテゴリカルな型の発想を、親戚のように共有しているんだ。
Haskell の 型システム が 圏論(モナドなど) と深く結びついているのも、同じ根っこだよ。
学部生:
じゃあ、QNLP を Haskell や Idris で書くと自然、ということですか?
講師:
そこは、正直に区別しよう。
「数学的な発想が似ている」ことと、「その言語で実装すると有利」ということは、別の話だ。
実際の lambeq は Python で書かれている
── 機械学習や量子計算のライブラリが Python に揃っているからね。
Haskell や Idris の強力な型検査は、「文法の型が正しく組み合わさっているか」をコンパイル時に保証する、という用途には概念的にとても向いている。
だから、「型で文法の正しさを保証する QNLP 処理系を、依存型言語で書く」という研究方向は、筋として面白いし、ありうる。
でも、いま主流の実装がそうなっている、という事実はない。
学部生:
なるほど。
「相性がいい“発想”」ではあるけれど、「いま実際にそう作られている」わけではない、と。
講師:
そういう距離感だ。
── ここも、さっきのカリー・ハワード対応とつながる話でね。
「型」「証明」「プログラム」「文法」が、深いところで同じ構造を共有している。
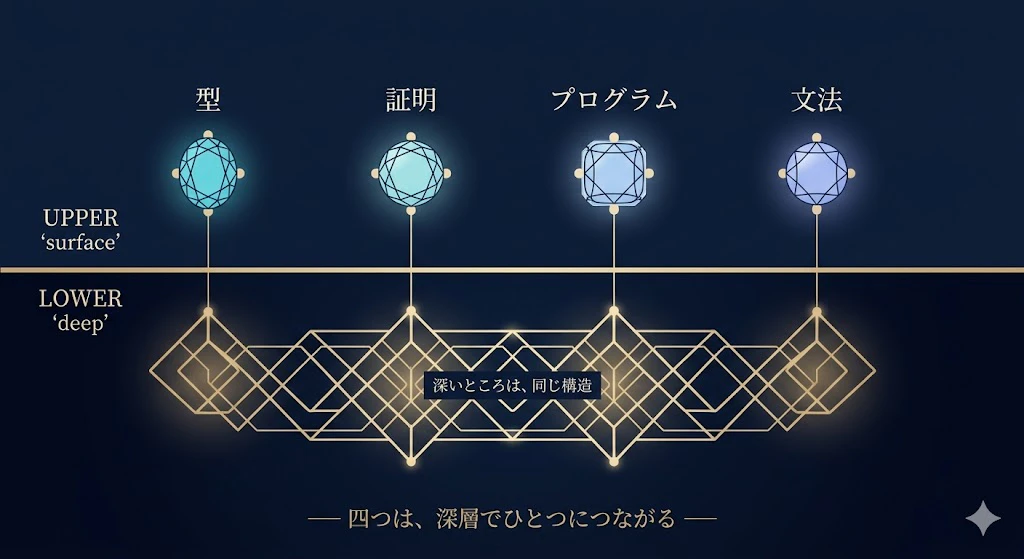
その大きな地図の話は、最後の「関連する話題」でもう一度ふれよう。
第4幕 ── 文法と量子が、同じ「形」をしている
学部生:
自然言語(英語、日本語など)の文法が配線図だということは、分かりました。
でも、それがなぜ「量子」につながるんですか。議論が飛躍しているように感じます。
講師:
ここが、この分野でいちばん美しいところだ。
結論を先に言うね。
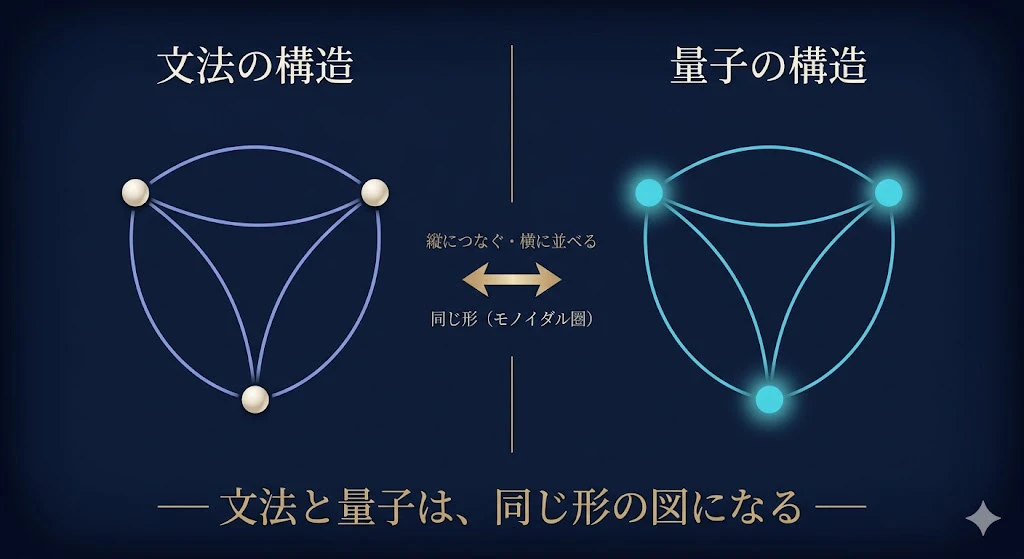
文法の配線図と、量子の世界の“組み立て方”が、圏論の目で見ると、まったく同じ形をしているんだ。
学部生:
同じ形……。どういう意味でしょう。
講師:
まず、量子のほうを見よう。
量子コンピュータでは、いくつかの量子ビットが、「もつれ(エンタングルメント)」という現象で結びついて、1つの状態を作る。

複数の部品が、線でつながって、1つのまとまった状態になる
── この「部品を線でつないで合成する」やり方が、さっきの文法の配線図と、ぴたり重なるんだ。
学部生:
文法も 「部品を線でつないで合成する」、
量子も 「部品を線でつないで合成する」。
たしかに、言葉にすると同じですね。
講師:
偶然の一致じゃない。数学的に、両方とも「同じ種類の圏(カテゴリー)」になっていることが証明されている。難しい名前だと「コンパクト閉圏」とか「リジッドなモノイダル圏」と呼ぶ。圏(けん)というのは、ざっくり「部品(対象)と、部品をつなぐ矢印(射)でできた世界」のこと。そして「モノイダル」というのは ──
学部生:
また知らない言葉が出てきました。モノイダル圏。
講師:
身がまえなくていい。「部品を、縦につないだり、横に並べたりして、図で組み立てられる世界」のこと、と思えばいい。プログラマの感覚だと、こうだ。関数を縦につなぐのが合成(f のあとに g を実行する)、データを横に並べるのがタプル((a, b))。この「縦につなぐ・横に並べる」の2つの操作がそろった世界を、数学では「モノイダル圏」と呼ぶ。それだけのことなんだ。
学部生:
縦と横で、ものを組み立てる世界。意外と素朴ですね。
講師:
そう。そして決定的なのは、文法の世界も、量子の世界も、どちらもこの「縦と横で組み立てる世界(モノイダル圏)」になっていることだ。器の形が同じなら、片方で成り立つ図を、もう片方の図として読み替えられる。だから ──
学部生:
あ。文法の配線図を、そのまま量子回路の配線図だと読み替えられる、ということですか。
講師:
そういうことだ。
文法という配線図を設計図にして、量子回路を組み立てる。これが QNLP の心臓部だよ。
第5幕 ── 「文の意味」を、量子状態として計算する
学部生:
配線図を読み替えるところまでは分かりました。
でも、「意味」はどこから来るんですか?
配線図は骨組みだけですよね?
「猫」や「魚」が何を意味するかは、別に要りそうです。
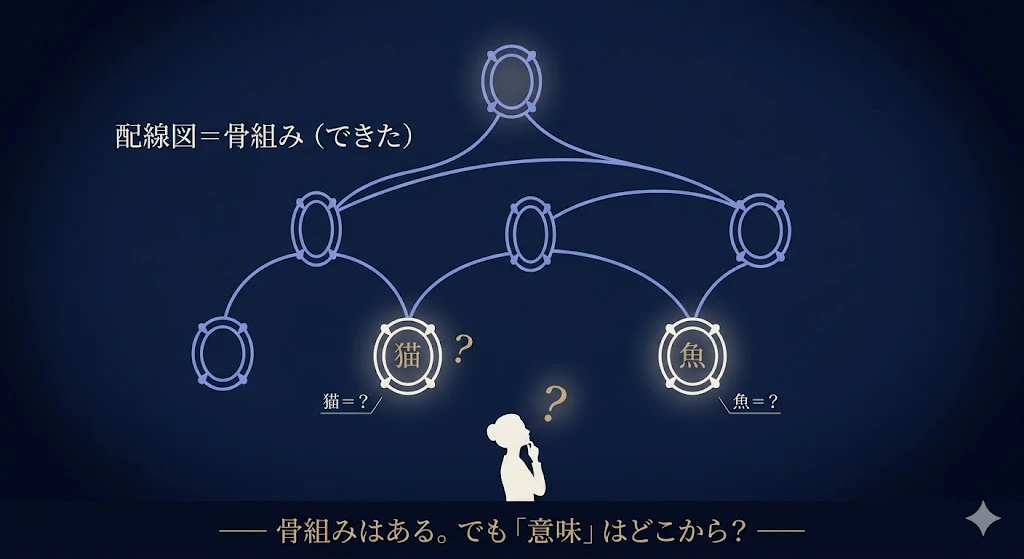
講師:
鋭い。そこで、もう一つの材料 ──「単語の意味ベクトル」が要る。
これは、君がNLPで慣れ親しんだ単語埋め込み(word embedding)と同じ発想だ。
「猫」という単語を、数のベクトルで表す。意味の近い単語は、近いベクトルになる。
学部生:
word2vec とか、あのあたりの話ですね。
それなら分かります。
講師:
そう、おなじみのあれだね。
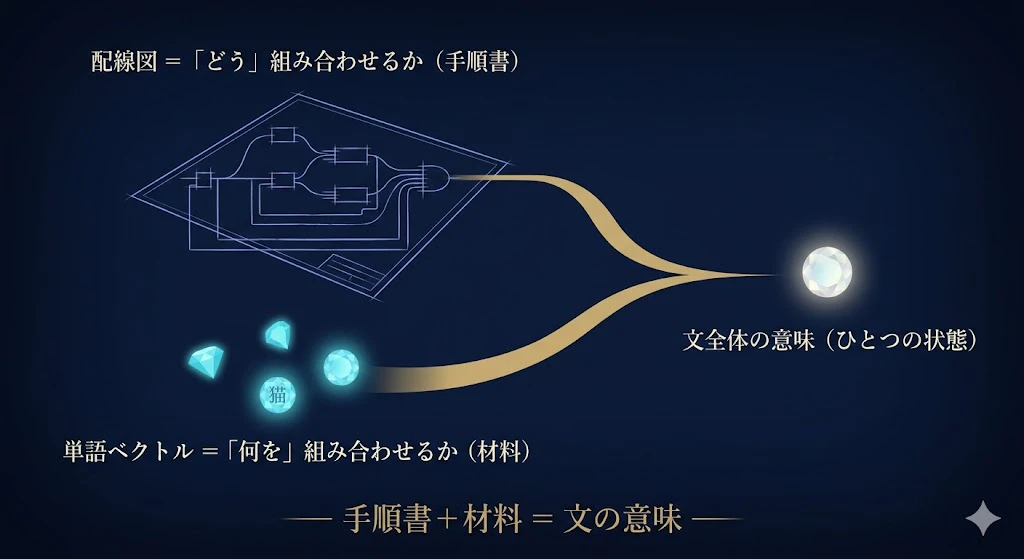
QNLP のアイデアを、ひとことで言うとこうだ。
「単語の意味(ベクトル)」を、「文法の配線図」にそって組み合わせる。
配線図が、「どう組み合わせるか」の手順書になり、
単語ベクトルが、「何を組み合わせるか」の中身になる。
両者を合わせると、文全体の意味が、1つの状態として計算される。
学部生:
文法が「計算の設計図」で、単語ベクトルが「材料」。
その2つから、文の意味が組み上がる……。
講師:
うまくまとめたね。
この枠組みには名前があって、DisCoCat(ディスコキャット) と呼ばれる。
Distributional Compositional Categorical の略
── 「分布的(ベクトルで意味を表す)」・「合成的(部品から組み立てる)」・「圏論的(圏の言葉で)」の3つを合わせた造語だ。

クーケ、サドルザーデ、クラークが2010年に提唱した。
学部生:
その**「組み合わせる計算」を、量子コンピュータがやる**んですか?
講師:
そこが、QNLPのエッセンスだね。
文法の配線図を「量子回路」として実装すると、単語ベクトルは「量子状態」として用意され、文法にそった合成が「量子ゲートの並び」として実行される。
そして、最後に回路を測定すると、文の意味に対応する状態が得られる。

クーケはこれを、半ば冗談めかして、「文法的な場の量子論(grammatical quantum field theory)」と呼んだ。
物理が時空のうえに“場”を乗せるのと同じ構造で、文法のうえに“意味”を乗せている、というわけだ。

ここまでの要点(いったん整理)
- 文法は、単語をつなぐ「配線図」として表せる。
- 量子回路もまた、「配線図」として表せる。
- その2つは、同じ数学(モノイダル圏) の上の図になっている。
- だから、文法の配線図を、そのまま量子回路へ写せる。
この4つが腑に落ちていれば大丈夫です。次は、それを実際に Python で動かしてみます。
学部生:
ひとつだけ確認させてください!
さっきから出てくる「モノイダル圏」
── これがあるから「文法と量子は同じ数学」と言える、という理解で合っていますか。
講師:
合っているよ。
ここだけ、コードに入る前に固めておこう。
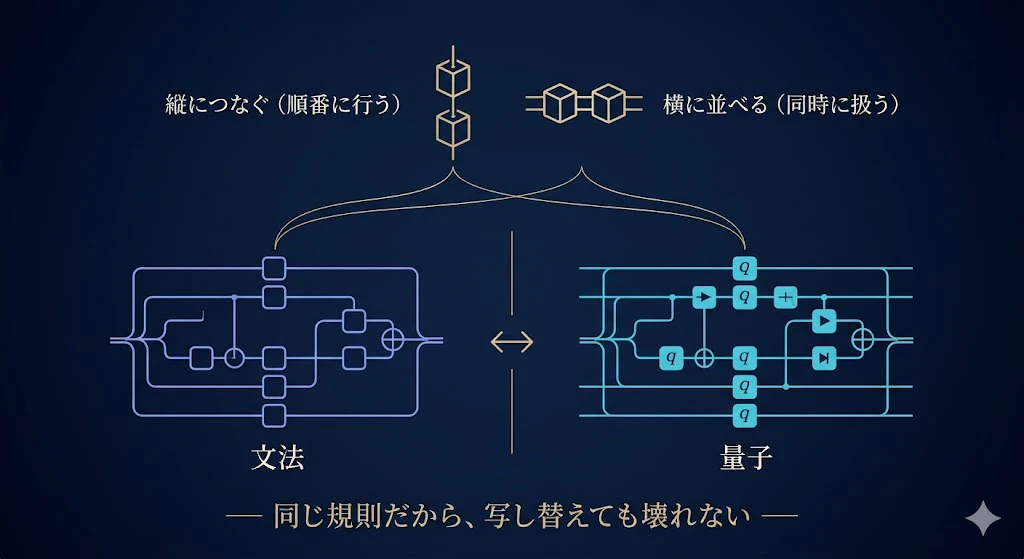
モノイダル圏というのは、なにも、そう難しく身がまえなくていい。
**「部品を、縦につなぐ/横に並べる、の2つの操作で図を組み立てられる世界」**のことなんだ。
-
縦につなぐ=処理を順番に行う(関数
fのあとにg) -
横に並べる=ものを同時に扱う(タプル
(a, b))
ポイントは、こうだ。
文法も、量子も、どちらもこの「縦と横で図を組み立てる世界」の規則をきっちり満たしている。
だから、「似ている」じゃなくて、「数学的に同じ種類の世界(同じモノイダル圏の構造)に住んでいる」と言い切れる。
学部生:
「なんとなく似てる」じゃなくて、「同じ規則を満たすことが証明されている」から、写し替えてよい、と。
講師:
そういうことだ。
図を縦横に組み立てるルールが両者で同じだから、文法の図を量子の図として読み替えても、構造が壊れない。
これが、「文法の配線図を、そのまま量子回路へ写せる」ことの、数学的な裏づけ なんだ。
── じゃあ、その“写し替え”を、実際に Python にやってもらおう。
第6幕【ハイライト】 ── lambeq で、文を量子回路にしてみる
学部生:
ここまで理屈は追えました。でも、やっぱり手を動かしたいです。さっきの lambeq、実際どう書くんですか。
講師:
OK. どう動くのか、説明しよう。
lambeq は Quantinuum 社が公開しているオープンソースの Python ライブラリで、pip install lambeq で入る。
やることは、さっきの話のとおり3段階だ。
(1) 文を構文解析して図にする → (2) 図を簡約する → (3) 量子回路に変換する。
コードでも、ほぼこの順に書く。

(1) 文を「ひも図(string diagram)」に変換する
# (1) 文を「ひも図(string diagram)」に変換する
from lambeq import BobcatParser
parser = BobcatParser() # 構文解析器を用意
diagram = parser.sentence2diagram("cats eat fish") # 文 → 図
diagram.draw() # 配線図を描画してみる
まず BobcatParser という構文解析器が、文を読んで、さっき話した「文法の配線図」── lambeq ではこれをひも図(string diagram) と呼ぶ ── に変換する。
draw() すると、単語が線でつながった、あの配線図が実際に絵で出てくる。
学部生:
おお、文がそのまま図になるんですね。
講師:
次が、図を量子回路に落とす段だ。
(2) & (3) 図を簡約し、量子回路(パラメータ付き)に変換する
# (2)(3) 図を簡約し、量子回路(パラメータ付き)に変換する
from lambeq import IQPAnsatz, AtomicType
# 各「型」を、何個の量子ビットに割り当てるか決める
ansatz = IQPAnsatz({AtomicType.NOUN: 1, AtomicType.SENTENCE: 1},
n_layers=1)
circuit = ansatz(diagram) # ひも図 → 量子回路
circuit.draw() # 量子回路として描画
Ansatz(アンザッツ)というのは、「図を、どんな量子回路に対応させるかの方針」のことだ。
名詞を1量子ビットに、文を1量子ビットに割り当てる、というふうに決めてやると、ansatz(diagram) が、ひも図を、パラメータ付きの量子回路に変換してくれる。
学部生:
パラメータ付き、というのは?
講師:
回路のなかに「あとで学習で調整するつまみ」が埋まっている、ということだ。
ここがニューラルネットと似ている。
最初はでたらめな値で、学習データ(たとえば「この文は料理の話/IT の話」というラベル付きの文)を使って、つまみを少しずつ回し、正しく分類できるように訓練する。
lambeq には、その学習を回す仕組みも用意されている。
学部生:
じゃあ、流れとしては、$「文 → ひも図 → 量子回路 → 学習」$ になりますね。
ふつうの MLパイプラインの、モデルの部分が量子回路に置き換わった感じですね。

講師:
その理解でほぼ正しい。
しかも lambeq の内部は、各段階が「ファンクタ(functor)」── 圏から圏への、構造を保つ変換 ── として実装されている。
構文解析の結果(CCG という形式の図)を、プレグループの図に変換し、それを簡約し、最後に量子回路に変換する。
これらすべての工程が、「図を、構造を保ったまま別の図に移す」操作の連なりなんだ。
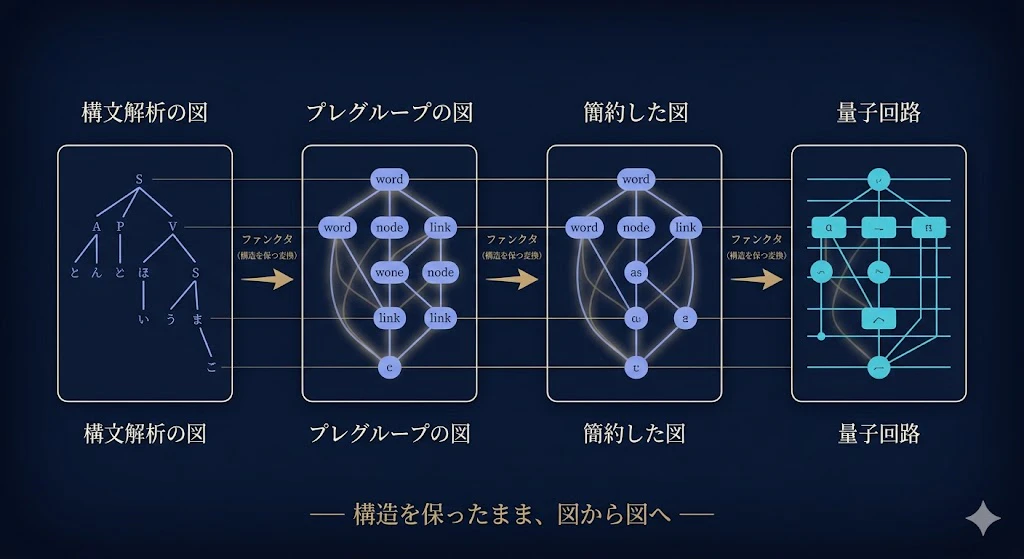
理屈(圏論)と実装(ライブラリ)が、きれいに対応している。
学部生:
理論がそのままコードの構造になっている、というのは気持ちいいですね。
学部生:
理論がそのままコードの構造になっている、というのは気持ちいいですね。
……ということは、QNLP を深く理解するには、圏論の勉強は避けて通れないんでしょうか?
圏論をごく浅くしか知らないプログラマと、毎月こつこつ深め続けているプログラマとでは ── QNLP エンジニアや量子回路の設計者として、できることの幅は、どれくらい変わってくると考えるべきですか?
講師:
とても実際的な問いだね。
正直に、レベルを分けて答えよう。
「使うだけ」なら浅くていい。でも「作る側」に回るほど、深さがそのまま武器になる。
3段階で考えるといい。
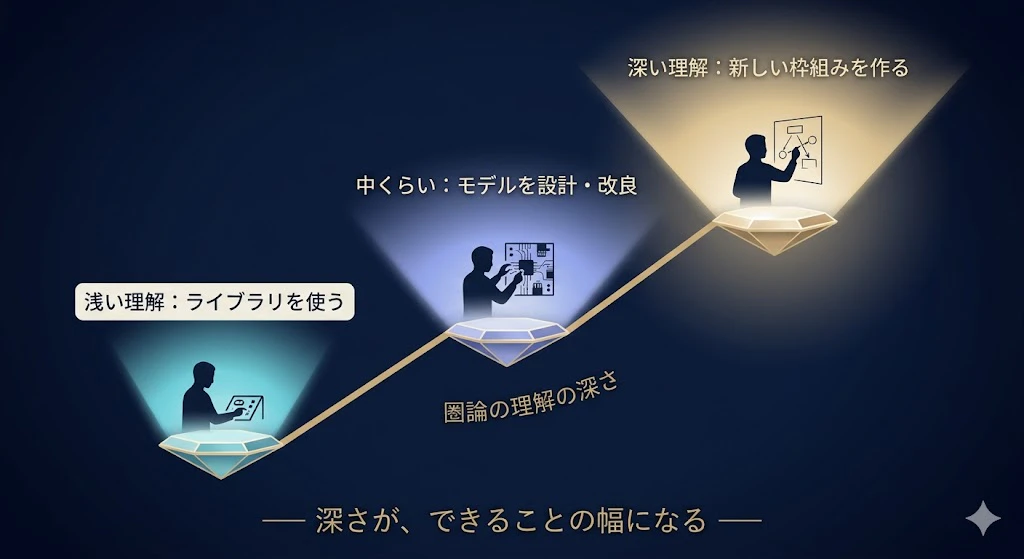
レベル1:ライブラリを使う人(浅い圏論でも十分)。
lambeq のようなライブラリは、圏論の難しさを内部に隠してくれている。
parser.sentence2diagram(...) と ansatz(...) を呼べば、圏論を厳密に知らなくても、文を回路にして分類器を訓練できる。
「モノイダル圏とは縦と横で図を組み立てる世界」くらいの直感があれば、応用タスクは十分に回せる。
ここは、ふつうの機械学習ライブラリを使うのと同じ感覚だ。
レベル2:モデルを設計・改良する人(中くらいの圏論が効く)。
「どの ansatz を選ぶか」「型にどう量子ビットを割り当てるか」「図をどう簡約すれば回路が軽くなるか」──
こうした設計判断になると、図(string diagram)が何を保存していて、どの変換が許されるのか、という圏論的な感覚 が、効いてくる。
圏論への理解の浅い人は、「ライブラリの既定値を使う」しかないが、理解が深い人は、「構造を壊さずに、より良い変換」を自分で選べる。
選択肢の幅が、はっきり広がる。
レベル3:新しい枠組みを作る人・研究の最前線(深い圏論が必須)。
DisCoCat の次(たとえば、文をまたいで合成する DisCoCirc など)や、新しい合成モデル、ZX計算と組み合わせた回路最適化
── こうした未踏の部分を自分で設計するなら、コンパクト閉圏やファンクタといった圏論が、もはや道具ではなく思考そのものの言語になる。
ここでは、深さが「できる/できない」を分ける。
学部生:
さっき「DisCoCirc」って出てきましたよね?
GitHub に text_to_discocirc っていうリポジトリも見つけたんですが ── DisCoCat と何が違うんですか?
講師:
いい着眼だ。
一言でいうと、DisCoCat は「文」止まり、DisCoCirc は「文章(テキスト)」へ、という違いだ。
これまで見てきた DisCoCat は、一文の意味を計算する枠組みだった。
「猫が魚を食べる」一文を回路にする、という話だったよね。
でも現実の文章は、文がいくつも連なって、前の文が後の文にくる。
「猫がいた。それは魚を食べた」
── この「それ」は前の文の猫だ。文をまたいだ、こういうつながり**は、一文だけ見る DisCoCat では捉えきれない。
学部生:
たしかに。文章って、文と文がつながって意味が変わっていきますよね。
……あれ、これって ── NLP で、word2vec から sentence2vec や paragraph2vec が出てきて、さらに attention メカニズムや、長いコンテキストを並列で扱える Transformer へ、と扱う単位が広がっていった流れと、似ていませんか?
$単語 → 文 → もっと長い文脈$、って。
講師:
うん、その対応づけは、すごく筋がいい。
「扱う単位を、単語から、文、そして文脈・文章へと広げていく」という“動機”は、確かにそっくりだ。
深層ニューラルネットワークのNLPが、word2vec → 文・段落の埋め込み → attention/Transformer と、より広い文脈を捉えにいったのと、QNLPが、DisCoCat(文)→ DisCoCirc(文章)と広げていくのは、向かっている方向が同じだね。
ただ ── ここは、この記事で何度も言ってきた区別を、もう一度だけ強調しないといけない。
「広げる動機」は似ていても、「広げ方の発想」は別系統なんだ。
- Transformer は、attentionメカニズム で、「どの単語がどの単語に効くか」を、大量データから統計的に重みづけして学ぶ。つながりをデータから推定する。
- DisCoCirc は、登場人物をワイヤーとして持続させ、文をゲートとして作用させる ── つながりを構造として明示的に組み立てる。
学部生:
同じ「文脈を扱いたい」でも、Transformer は“統計で推定”、DisCoCirc は“構造で明示”、と。
講師:
そういうことだ。

目的地(より広い文脈の理解)は近いのに、登り方(統計か、構造か)が違う。
だから、「QNLP は Transformer の後追い」ではないし、「Transformer の量子版」でもない。
同じ山を、別の斜面から登っている、と思うのがいちばん正確だね。

学部生:
なるほど。似た流れに見えて、よりどころにしているものが、根本から違うんですね。
講師:
そこで DisCoCirc(Distributional Compositional Circuits)だ。
発想がうまくてね。
登場人物(名詞)を、回路の「ワイヤー(線)」として、文章のあいだずっと持続させるんだ。
そして、**それぞれの文は、そのワイヤーに作用する「ゲート」**として働く。
文が進むたびに、ゲートが登場人物の状態を更新していく。
- DisCoCat:単語の意味は固定された状態。一文で完結。
- DisCoCirc:単語の意味は時間発展する状態。文章が進むと、登場人物が更新されていく。
学部生:
あ、それって……まさに 「量子回路で、ワイヤー上の状態がゲートで変化していく」のと、同じ絵 ですね。
講師:
まさに! そこが美しいところだ。

DisCoCirc は、最初から**量子回路と同じ「2次元の図」**として描かれる。
2次元 というのは、
- 横方向に「処理の順番(文が進む時間)」
- 縦方向に「同時に並ぶ登場人物たち」
を取る、という意味だ。
さっき、第4幕で見た 「縦につなぐ・横に並べる」── あのモノイダル圏の図そのもの だね。

だから、文章をまるごと量子計算にのせる ── 複数の文からなるテキストの処理へ、自然に道がつながる。

さっきの text_to_discocirc は、その「英語の文章を DisCoCirc の回路(テキスト回路)に変換する」ためのツールだね。
学部生:
DisCoCat の「次の一手」が DisCoCirc、というわけですね。
講師:
そういうことだ。
講師:
しかも面白い副産物があってね。
テキスト回路にすると、「文法上の事務手続き」── 言語ごとの語順の違いなんかが、かなり消えるんだ。
だから、英語で作った回路が、ウルドゥー語やベンガル語にもそのまま移りやすい、という「言語をまたぐ普遍性」が報告されている。
学部生:
「文法上の事務手続き」って、具体的にはどういうことですか。
講師:
たとえば語順だ。
英語は、「主語・動詞・目的語」の順だけど、日本語やウルドゥー語は「主語・目的語・動詞」の順だよね。
同じ意味なのに、言語ごとに並べ方の作法がバラバラだ。
ほかにも、助詞をつけるか語尾を変化させるか、長い一文で言うか短い文に区切るか ── こういう「意味そのものではなく、その言語固有の“書き方の作法”」が、たくさんある。
これが「文法上の事務手続き(grammatical bureaucracy)」だ。
学部生:
語順の違い、よく分かります。── そういえば、もっと近い例もありますね。
同じラテン語から派生したヨーロッパの言語どうしでも、フランス語は名詞の後ろに形容詞が来るのに、英語は形容詞の後ろに名詞が来る。語の並べ方が逆なんですよね。
略語にも、それが出ます。
国際連合は、英語表記の略号だと UN(United Nations) ですが、フランス語だと ONU(Organisation des Nations Unies)。
NATO も、フランス語だと OTAN になる。
同じ組織を指す名詞なのに、言語の語順の作法が違うから、頭文字の並びまで変わってしまう。
講師:
まさにそれ。
DisCoCirc のテキスト回路は、「誰が・何に・どう作用したか」という意味のつながりだけを残して、語順みたいな事務手続きをそぎ落とすように作られている。
だから、「猫が魚を食べた」という情況を、英語の文として書き表しても、日本語の和文で記述しても、できあがる回路(意味の骨組み)は、ほぼ同じ形になる。
このことが持つ意味は大きい。
ふつうの自然言語処理だと、言語ごとに文法処理を作り直す手間が重い。
でも、もし意味の回路が言語に依存しないなら ── 一度作った意味の構造を、言語をまたいで使い回せるかもしれない。
翻訳や多言語処理にとって、これは魅力的な性質だ。
学部生:
それは関連する論文がありますか? 読んでみたいです。
講師:
あるよ。出発点はこれだ。
- Wang-Maścianica, Liu, Coecke (2023)「Distilling Text into Circuits」(arXiv:2301.10595)
英語のかなりの範囲について、文章をテキスト回路に変換する仕組みを実際に作った論文だ。
「文法上の事務手続きが消える」という話も、ここで論じられている。
そして「言語をまたぐ普遍性」を具体的な言語で検証したのが、このあたりだ。
- Waseem, Liu, Wang-Maścianica, Coecke「Language-independence of DisCoCirc's Text Circuits: English and Urdu (arXiv:2208.10281)
これは、英語とウルドゥー語で、語順の違いがテキスト回路に移すと消えることを示した研究だ。
最近では、英語とベンガル語で同じ普遍性を検証・再評価した研究(arXiv:2511.08601)もある。
実装を触りたいなら、さっきの GitHub の text_to_discocirc から入るのがいい。
まず論文 (2301.10595) で発想をつかんで、次にリポジトリで手を動かす
── この順がおすすめだよ。
さっき話した 「言語に縛られない」という QNLP の理想に、DisCoCirc は一歩踏み込んでいる んだよ。
この領域の研究の系譜を本格的に追いかけようとすると、記事一本ぶんの大きな話になる。
学部生:
じゃあ、「圏論の関する見識を毎月深め続ける」ことの見返りは・・・
講師:
レベルを上げるほど、大きくなる。
レベル1で止まるなら、追加の圏論はそこまで要らない。
でも、レベル2・3へ行きたいなら、圏論に関する理解の深さが、そのまま「設計できる量子回路そのものの選択の幅」になる。
しかも ── さっき話したカリー・ハワード対応を思い出してほしい。
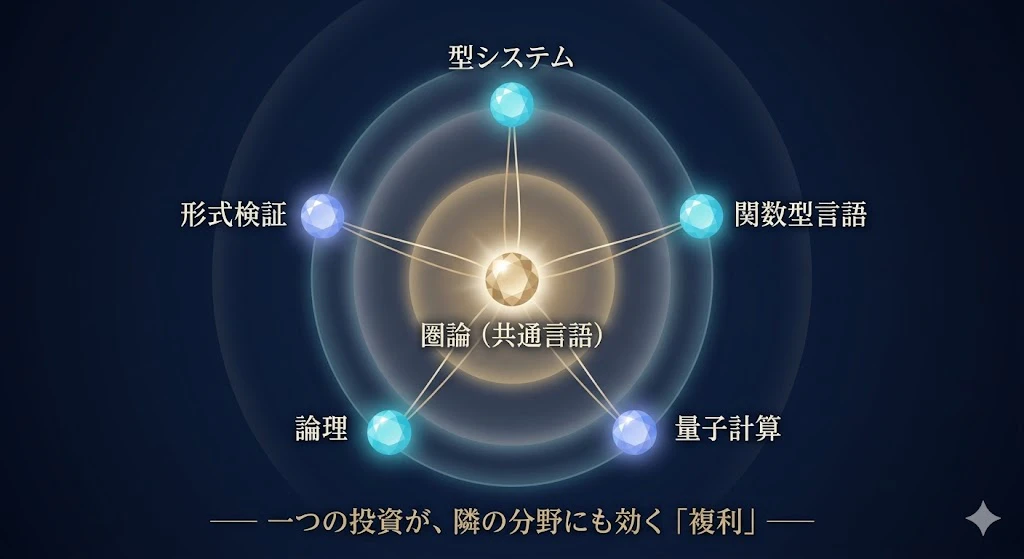
圏論は、QNLP だけの道具じゃない。
**型システム、関数型言語、量子計算、論理、形式検証
── それら全部に通じる“共通言語”**だ。
だから、圏論に時間と精神的エネルギーを投資することは、QNLP一分野にとどまらず、隣の分野へも効く複利になる。
そこが、毎月続ける価値のあるところだよ。
学部生:
一つの分野のためだけじゃなく、いくつもの分野に効く“複利”。……それは、続ける動機になりますね。
講師:
ちなみに lambeq は、量子回路だけじゃなく、ふつうのパソコンで動く「テンソルネットワーク」 にも変換できる。
TensorAnsatz を使えば、NumPy や PyTorch、JAX で評価できる。
だから、「量子コンピュータがまだ手元にない」人でも、古典シミュレーションで QNLP の実験を試せるんだ。
実際に lambeq を動かしてみる
ここからは、実際のコードで「何ができるか」を見ていきます。
pip install lambeq で導入できます(初回はパーサのモデルのダウンロードが走ります)。
コードは概念の流れを示すもので、API はバージョン(本記事は 0.5 系を想定)により変わることがあります。
① 文を「文法の図(ひも図)」にして、描画する
from lambeq import BobcatParser
# 構文解析器を用意(初回はモデルをダウンロード)
parser = BobcatParser(verbose='text')
# 1文を「ひも図(string diagram)」に変換
diagram = parser.sentence2diagram("John gave Mary a flower")
# 配線図を描画する(単語が線でつながった、あの図が出てくる)
diagram.draw()
sentence2diagram が、文を読み取って「単語=箱、文法のつながり=線」のひも図にします。draw() で、本文で見てきた配線図が実際に絵として表示されます。
② ひも図を「量子回路」に変換する
from lambeq import AtomicType, IQPAnsatz
# 各「型」を何量子ビットに割り当てるか決める
# 名詞(NOUN)=1量子ビット、文(SENTENCE)=1量子ビット
ansatz = IQPAnsatz({AtomicType.NOUN: 1, AtomicType.SENTENCE: 1},
n_layers=1, n_single_qubit_params=3)
# ひも図 → パラメータ付き量子回路
circuit = ansatz(diagram)
circuit.draw()
Ansatz(アンザッツ)は「図を、どんな量子回路に対応させるか」の方針です。IQPAnsatz は IQP 型の回路を生成します。これで、文がパラメータ付きの量子回路になりました(パラメータ=あとで学習で調整する“つまみ”)。
③ 量子コンピュータがなくても試せる ── テンソルネットワーク版
from lambeq import TensorAnsatz
from lambeq.backend.tensor import Dim
# 量子回路の代わりに、古典計算で評価できるテンソル網にする
# 名詞=4次元、文=2次元、のように次元を割り当てる
tensor_ansatz = TensorAnsatz({AtomicType.NOUN: Dim(4),
AtomicType.SENTENCE: Dim(2)})
tensor_diagram = tensor_ansatz(diagram)
tensor_diagram.draw()
TensorAnsatz を使うと、同じひも図をふつうのパソコンで動くテンソルネットワークに変換できます。量子実機が手元になくても、QNLP の実験を古典シミュレーションで試せます。
④ 文の分類を「学習」する(エンドツーエンド)
最後に、ラベル付きの文(たとえば「IT の話=0/料理の話=1」)から、分類器を訓練する流れです。
from lambeq import BobcatParser, AtomicType, IQPAnsatz, RemoveCupsRewriter
from lambeq import TketModel, QuantumTrainer, SPSAOptimizer, Dataset
# --- 前処理:文を図にし、簡約し、量子回路にする ---
parser = BobcatParser(verbose='text')
remove_cups = RemoveCupsRewriter() # 図を簡約して回路を軽くする
ansatz = IQPAnsatz({AtomicType.NOUN: 1, AtomicType.SENTENCE: 1},
n_layers=1, n_single_qubit_params=3)
def to_circuits(sentences):
diagrams = parser.sentences2diagrams(sentences)
diagrams = [remove_cups(d) for d in diagrams]
return [ansatz(d) for d in diagrams]
train_circuits = to_circuits(train_data) # train_data: 文のリスト
val_circuits = to_circuits(val_data)
# --- モデルと学習器を用意して訓練する ---
model = TketModel.from_diagrams(train_circuits + val_circuits)
trainer = QuantumTrainer(
model,
loss_function=lambda y_hat, y: -np.sum(y * np.log(y_hat)) / len(y), # クロスエントロピー
epochs=100,
optimizer=SPSAOptimizer,
optim_hyperparams={'a': 0.05, 'c': 0.06, 'A': 10},
)
train_dataset = Dataset(train_circuits, train_labels, batch_size=16)
val_dataset = Dataset(val_circuits, val_labels)
trainer.fit(train_dataset, val_dataset) # 学習スタート
流れは、ふつうの機械学習とそっくりです。
文 → 図 → 量子回路に変換し(前処理)、QuantumTrainer が SPSAOptimizer(量子回路向けの最適化アルゴリズム)で“つまみ”を調整し、文の分類を学習します。
学習が終われば、model に新しい文の回路を渡して、ラベルを予測できます。

この④で、序章で触れた「文の分類」や「感情分析」が、実際に動く形になります。
TketModelをPennyLaneModelに替えれば、古典のニューラルネットと組み合わせたハイブリッド学習もできます。
第7幕 ── これって、英語しかできないの?
学部生:
ひとつ気になったんですが、これは英語しかできないんですか。日本語や中国語、アラビア語は?
講師:
いい質問だ。答えは2段階に分かれる。
まず理論のレベル。
さっきの DisCoCat の考え方 ── 文法構造を図にして、量子の合成に対応させる ── は、特定の言語にしばられていない。
文法を圏の図にできさえすれば、どんな言語でも原理的に扱える。
実際、英語以外でも、たとえばヒンディー語を pregroup 文法と DisCoCat で図にして、量子回路に変換する研究が出ている。
学部生:
じゃあ、日本語でもいけるんですか。
講師:
仕組みとしては、いける。
ただし実装のレベルで、ひとつ壁がある。
lambeq は、文を図にする前に「構文解析器(パーサ)」で文法構造を読み取る。
標準で付いてくるパーサは英語向けなんだ。
日本語に使いたいなら、日本語用のパーサ(たとえば DepCCG という外部の解析器)を別に用意して、つなぐ必要がある。
lambeq の公式サイトでも「日本語に適用したい場合は別のパーサを入れてね」と案内されている。
学部生:
なるほど。
「量子回路に変換する部分」は共通で、「文法を読み取る部分」だけ言語ごとに差し替える、と。

講師:
まさにその構造だ。
図にしてしまえば後は同じ。
だから、ボトルネックは量子側じゃなく、言語側の“文法を読む道具”がどれだけ整っているかにある。
英語はその道具が一番そろっているから、すぐ動く。
他の言語は、解析器の整備しだい ── ここは、従来の自然言語処理と同じ事情だね。
学部生:
量子の話なのに、結局いちばん地味な「文法解析」が効いてくるんですね。
第8幕 ── で、いまの大規模言語モデル(LLM)とは何が違うの?
学部生:
正直に聞きます。
自然言語処理は、いま Transformer と LLM が圧倒的ですよね。QNLP は、それと張り合うものなんですか?
講師:
正直に答えよう。
いまの LLM と性能を競うものでは、まだない。
QNLP は実用規模ではまだ研究段階で、扱える文の規模も、タスクの種類も、限られている。
そこは誇張せずに言っておきたい。

学部生:
じゃあ、何が違うんでしょうか?
講師:
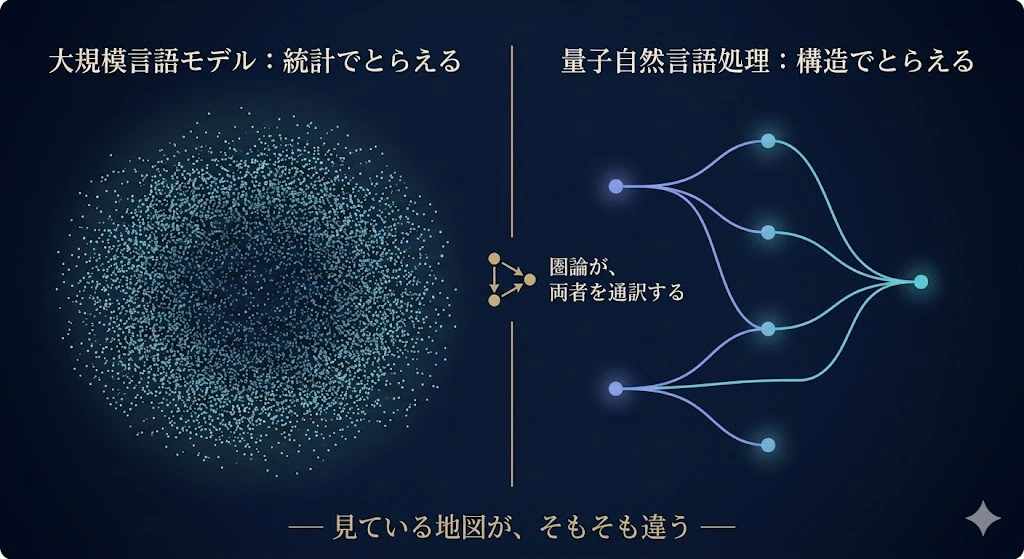
発想の系統が、根本的に違うんだ。
表に並べてみよう。
| 大規模言語モデル(LLM) | 量子自然言語処理(QNLP) | |
|---|---|---|
| 意味のとらえ方 | 巨大なデータからの統計 | 文法構造にそった合成 |
| 中核の計算 | 行列のかけ算とニューラルネット | 圏論の図 → 量子回路 |
| 文法の扱い | 明示的には持たない(暗黙に学習) | 文法を、計算の骨格として明示的に使う |
| 現状 | 実用全盛 | 研究段階 |
| 強み | スケールと性能 | 構造の透明さ・分野をまたぐ普遍性 |
講師:
いまの LLM は、巨大なテキストから「統計的に」言語を扱う。
どの単語の次に何が来やすいか、を膨大なパラメータで覚える。
文法は、明示的には持たず、データから暗黙に学ぶ。
LLMの精度は高く、文章要約も、人間ユーザとの会話もうまくいくのですが、「なぜその意味になるのか」の筋道は、モデルの内部に溶けてしまい、人間には見えにくい。
他方で、QNLP は、「文法構造を、量子の合成構造に対応させる」という、もっと構造主義的なアプローチだ。
QNLPは、意味が「どの部品から、どう組み上がったか」が、配線図として目に見える。
学部生:
透明さ、ですか。
講師:
そう。
意味の合成の道筋が、図としてはっきり残る。
これは、「説明可能性」という点で、長い目で見ると面白い性質だ。
それに ── ここがいちばん大事なんだけど ── 「意味の合成のしかた」を、圏論という1つの共通言語で、物理・計算・言語にまたがって扱える。
同じ「縦と横で組み立てる図」の文法で、量子も、言語も、論理も書ける。
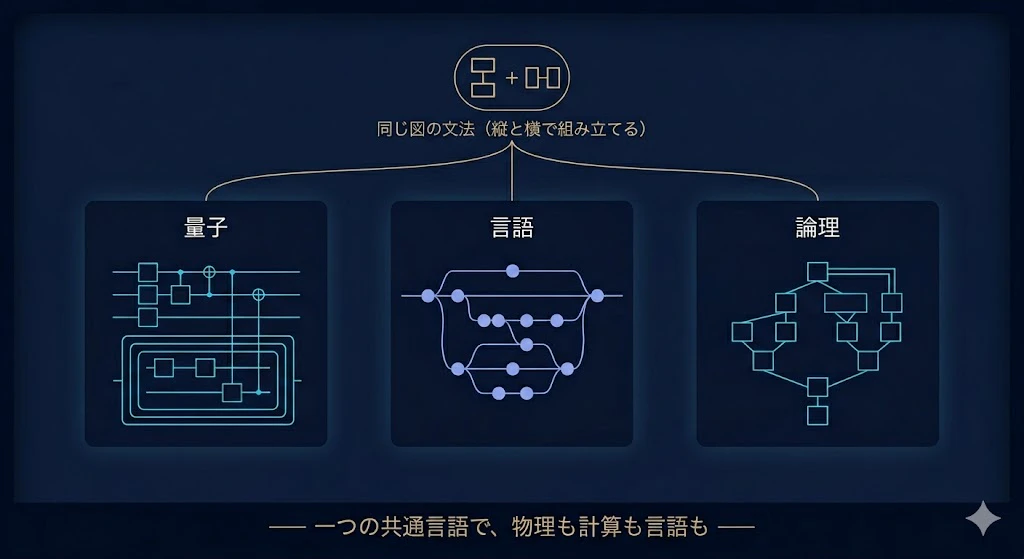
学部生:
へえ……圏論が、量子と言語の“通訳”になっているんですね。
講師:
うまいことを言うね。実は、それが圏論のいちばんの効能なんだ。「違って見える分野が、同じ構造を共有している」と見抜いて、橋を架けること。
量子・言語・論理を、ひとつの絵の文法でつなぐ ── それが、この分野の醍醐味だよ。
学部生:
橋を架ける、ですか。
……そういえば、前に話した僕の兄が研究している ラングランズ・プログラムも、関係してくるんですかね?
あれも、「橋を架ける」話 だと聞いたことがあって。
講師:
おっと、大物の名前が出たね。ラングランズを知らない読者のために、まず説明しておこう。
ラングランズ・プログラムというのは、ひとことで言うと、数学のなかの、まったく別々に見える二つの大陸 ── 「数論」(整数や素数の世界)と「幾何・解析」(図形や関数の世界)── のあいだに、深い対応の橋が架かっているはずだ、という壮大な予想と計画のことだ。
1960年代に Robert Langlands が提唱して、いまも多くの数学者が取り組んでいる、現代数学の最前線のひとつだよ。
「数学の大統一理論」 と呼ばれることもある。
学部生:
別々に見える分野に、橋を架ける ── たしかに、今日ずっと話してきた圏論と、雰囲気が似ています。
講師:
そう、“精神”はよく似ている。
「遠く離れて見える世界が、深いところで対応している」という発想は、ラングランズも、圏論も、カリー・ハワード対応も、そして QNLP も、共通して持っている。
ただ ── ここははっきり、正確に言うね。
「QNLP とラングランズが、数学的に直接つながっている・同じものだ」というわけではない。
ラングランズは、数論と幾何という、QNLP とはまったく別の対象を扱っている。
だから、両者を結ぶ厳密な数学的な橋が、いま架かっているわけじゃない。
似ているのは、あくまで**「橋を架ける」という構え、精神のほう**だ。
実際、さっき話したカリー・ハワード・ランベック対応を「ささやかなラングランズのようなものだ」となぞらえる人もいるくらいでね。
血縁ではなく、遠い親戚。
それくらいの距離感が、ちょうど正確なんだ。
学部生:
なるほど。
「同じだ」と興奮しすぎず、「橋を架ける精神において、遠い親戚」と捉える、と。
講師:
そういうことだ。
この話は、記事の最後の「関連する話題」で、もう少しだけ地図を広げてみよう。
本格的に追うなら、それぞれ一冊の本になる世界だからね。
学部生:
話を戻すと、QNLPとLLMは、NLPという技術領域・研究領域の中で、どっちが勝つか、という話じゃないんですね。
見ている地図が、そもそも違う。
講師:
そのとおり。
性能の競争という短い物差しだけじゃなく、「言語と物理が同じ数学でつながる」という、もっと深い地図を描こうとしている。
その地図がどこへ向かうかは、まだ誰にも分からない。
でも、そういう問いを追いかけられること自体が、豊かなこと だと思うよ。
第9幕 ── 「絶対に間違えてはいけないAI」と、説明可能性の交差点
学部生:
さっきの「説明可能なAI」、もう少し聞きたいです。
LLMが、深層ニューラルネットワークモデルの思考過程を取り出して、人間に対して説明できないと、具体的に何が困るんですか?
講師:
いちばん深刻に困るのが、間違いが許されない分野だ。
社会インフラの制御、自動運転車、ドローン、医療機器
── こういう「安全が最優先(safety-critical)」なシステムに AI を載せるとき、「だいたい合ってる」では済まない。
「絶対に、この範囲の入力では危険な誤動作をしない」と、数学的に保証したいんだ。
ちなみに、こういう「安全が最優先される分野」── 失敗が人命や重大な被害に直結する領域を、工学では セーフティ・クリティカル(safety-critical) と呼ぶ。自動運転、医療機器、航空、原子力なんかが典型だね。
学部生:
似た言葉で「ミッション・クリティカル」って聞いたことがあります。あれと同じですか?
講師:
近いけど、厳密には少し違うんだ。
**ミッション・クリティカル(mission-critical)**は、「失敗すると、任務や事業そのものが立ち行かなくなる」もの ── 銀行の基幹システムや、通信インフラがそうだ。必ずしも人命とは限らない。
一方、セーフティ・クリティカルは、失敗が“人の安全”に直結する。
重なる部分は大きいし、日常では混ぜて使われることも多いけれど
── いま僕らが話している自動運転やドローンは、人の命に関わる、という意味で、よりセーフティ・クリティカル寄りの話だね。
学部生:
なるほど。
その「絶対に間違えてはいけないAI」が求められる分野で、間違えないAIであることを保証するために、たくさんテストする、ではダメなんですか。
講師:
ダメなんだ。
入力のパターンは事実上無限にあるから、テストでは尽くせない。
そこで使うのが、形式検証(formal verification)や定理証明という技術だ。
プログラムや制御則が、仕様を論理的に・網羅的に満たすことを証明する。
航空宇宙や鉄道の制御で昔から使われてきた、堅い手法だよ。
学部生:
プログラムの正しさを、証明で保証する、と。
講師:
そう。ところが
── ここで大問題が起きる。
いまの AI の主力であるディープニューラルネットは、この形式検証ととても相性が悪いんだ。
理由は2つ。
ひとつ は、ブラックボックスだから。
判断が膨大な重みの数値に溶けていて、「なぜその出力になったか」を人間が追えない。
検証しようにも、中で何が起きているか見えない。
もうひとつ は、入力の次元が高すぎて計算が爆発すること。
カメラ画像のような高次元入力だと、「ありうる入力すべて」を調べる計算量が、現実的でなくなる。
実際、自動車などの機能安全の規格も、いまのところニューラルネットベースの自動運転を十分に検証する枠組みを、まだ持てていない。
世界中が「どうやって AI の安全を保証するか」に、いままさに取り組んでいる、という段階 なんだ
(※既存の機能安全規格やニューラルネット検証の取り組みについては、記事末の参考文献を参照)。
学部生:
「賢いけど、なぜそう判断したか説明できず、保証もできない AI」は、人の命がかかる場所には載せにくい、と。
講師:
そういうことだ。
「賢さ」と「保証できること」が、いまトレードオフになっている。
ここで ── ようやく、さっきの QNLP の説明可能性 と話がつながる。
学部生:
QNLP が、その安全問題に効くんですか?
講師:
QNLPはまだ産業界の最前線で実用化されている段階ではない。
でも**「つながりうる方向」は、はっきり見えている**。
ここは誇張せず正確に話すね。
QNLP や DisCoCat の本質 は、「全体の意味を、部品と“組み立て方”に分解して、図で表す」 ことだった。
これは、AIの判断をブラックボックスにせず、合成的な構造として透明にする、ということでもある。
Bob Coecke たちは2024年に、この発想を QNLP の枠を超えて一般化し、「合成的解釈可能性(compositional interpretability)」 という、説明可能AI(XAI)の理論的枠組みとして提案した。
ニューラルネットも Transformer も、ぜんぶ「図(string diagram)」として並べて、その解釈可能性を圏論の言葉で測ろう、という試みだ。

学部生:
その2024年の研究って、これですか? ── 「Towards Compositional Interpretability for XAI」(arXiv:2406.17583)。
講師:
そう、それだ。よく見つけたね。Sean Tull、Robin Lorenz、Stephen Clark、Ilyas Khan、Bob Coecke たちの論文だよ。
中身を、ひとことで言うとこうだ。
いまの AI は、解釈可能性を欠いたブラックボックスの機械学習モデルに大きく依存している。
その問題に取り組むのが XAI(説明可能AI)で、金融・法務・医療といった、判断の重みが大きい分野で決定的に重要だ
── そう述べたうえで、圏論を使って「AIモデルとは何か」「その解釈可能性とは何か」を定義し直す、というアプローチを提案している。
学部生:
具体的には、何を比べているんですか。
講師:
ここが面白くてね。
線形モデル、ルールベース、ニューラルネット、Transformer、VAE、因果モデル、そして DisCoCirc
── これらをぜんぶ「合成的モデル(compositional model)」として、同じ土俵に並べて比較するんだ。
つまり、まったく方式の違う AI たちを、圏論という共通の物差しで「どれだけ解釈可能か」を測れるようにした。
さっき言った「いろんな AI を図として並べて測る」が、まさにこの論文のやっていることだよ。
学部生:
具体的には ── 線形モデル、ルールベース、ニューラルネット、Transformer、VAE、因果モデル、そして DisCoCirc。こんなに方式の違うものを、どうやって「同じ土俵」に並べたんですか?
講師:
鍵は、ひとつのアイデアだ。どんなモデルも、「ひも図(string diagram)」として書き表す。これに尽きる。
思い出してほしい。
ひも図というのは、ずっと見てきた「箱(部品)と、線(つながり)でできた図」だったね。
この論文は、こう考える。
どんな AI モデルも、結局は「何かを入力して、内部で部品が組み合わさって、何かを出力する」ものだ。
ならば、その部品と組み合わせ方を、ひも図として描けるはずだ、と。
学部生:
方式がどれだけ違っても、「部品と配線の図」というレベルまで降りれば、同じ言葉で書ける、と。
講師:
そういうことだ。
しかもこのひも図は、決定論的なモデルも、確率的なモデルも、量子的なモデルも、まとめて表せるように作られている。
だから、ニューラルネットも、Transformer も、因果モデルも、DisCoCirc も ── ぜんぶ「ひも図」という共通の形式に翻訳して、横に並べて見比べられるようになる。
これが「同じ土俵に並べる」の正体だよ。
学部生:
並べたうえで、何を見るんですか。
講師:
**「その図が、どれだけ透明か」**だ。
論文は、モデルの解釈をその図の構造そのものから定義する。
すると面白いことが分かる。
── 昔から「本質的に解釈しやすい」と言われてきたモデル(線形モデルなど)が、なぜ透明なのかが、図にすると最もはっきり浮かび上がるんだ。
そこから一歩進めて、**「合成的に解釈可能なモデル(CI モデル)」**という、より広い概念を定義する。
因果モデルや概念空間モデル、そして DisCoCirc も、その仲間に入る。
学部生:
そうすると ── ディープラーニングのモデルも、あのアーキテクチャ図を「ひも図」に置き換えれば、解釈可能になるんですか? もしそうなら、これで万々歳じゃないですか。
講師:
……気持ちは分かる。でも、そこには大事な落とし穴がある。
「ひも図に書ける」ことと、「解釈できる」ことは、別なんだ。
ここで、論文がきっちり区別している2つの言葉を分けよう。
-
合成的モデル:
とにかくひも図として書き表せるモデル。── ディープラーニングも Transformer も、これには当てはまる。形としては、図にできる。
-
合成的に解釈可能なモデル(CIモデル):
図にできるだけでなく、その図の一つひとつの箱(部品)が、人間に意味の分かる中身を持っているモデル。
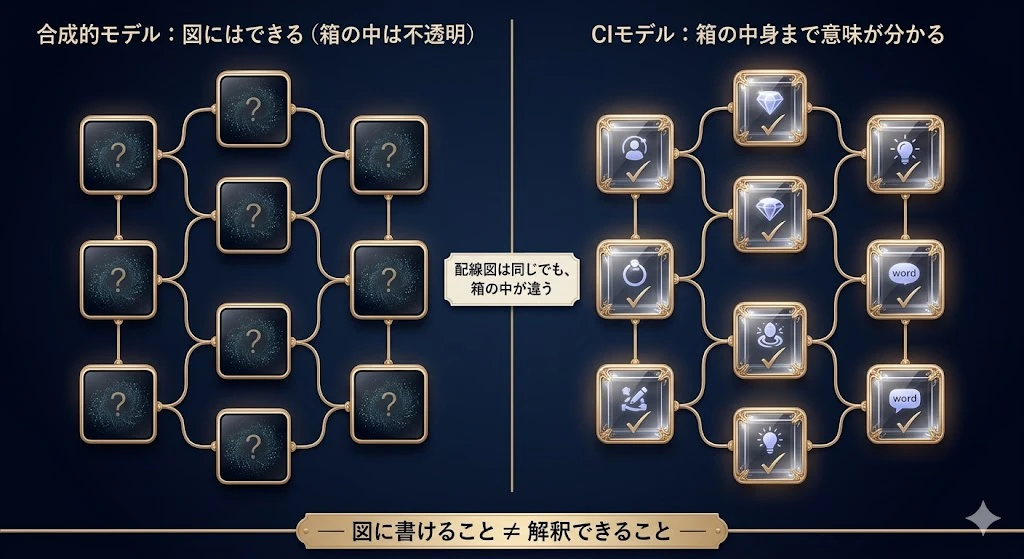
学部生:
あ……ディープラーニングは、前者ではあっても、後者とは限らない、と。
講師:
そこなんだ。
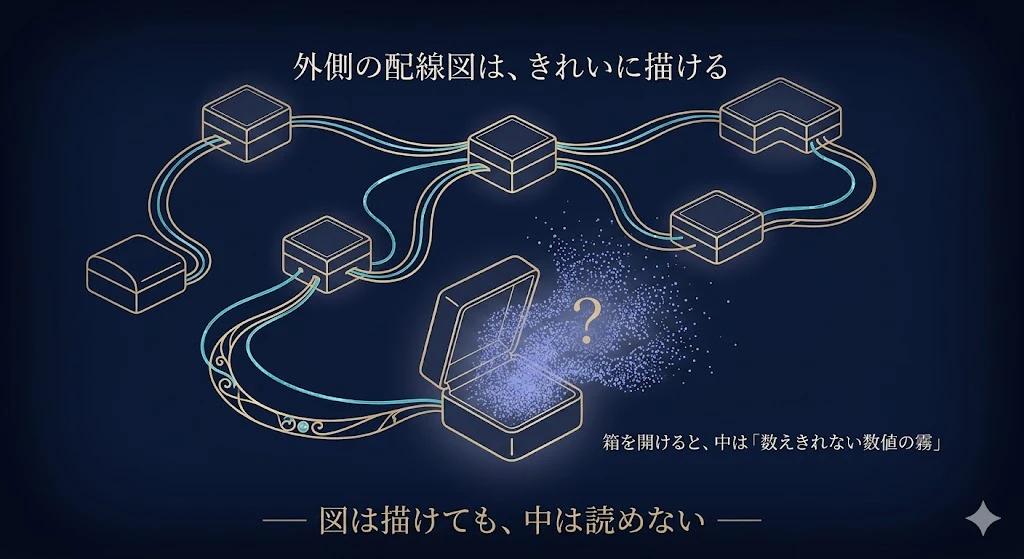
ディープラーニングを図にしても、箱の中身は、相変わらず「何百万個の数値の塊」のままでね。
図の形は描けても、ひとつひとつの箱が「何を意味しているか」は、依然として読めない。
外側の配線図はきれいに描けるのに、箱を開けると中は霧のまま
── これでは、本当の意味で解釈可能になったとは言えない。
学部生:
じゃあ、図にすること自体が無駄、ということですか?
講師:
いや、無駄じゃない。
図にすることで、「どこが透明で、どこが不透明か」が、はっきり切り分けられるようになる。
「配線(部品のつなぎ方)は見えているが、各部品の中身が見えていない」
── そう診断できること自体が、大きな前進なんだ。
そのうえで論文は、「部品の中身まで意味が分かる」ところまで行けているモデル(線形モデルや、因果モデル、DisCoCirc など)を、CIモデルとして特別に取り出している。
学部生:
なるほど。「図にすれば万々歳」じゃなくて、「図にすることで、何が足りないかが見えるようになる」。そこからが、本当のスタートなんですね。
講師:
そういうことだ。**透明性は、図にした“だけ”では手に入らない。でも、図にしないと、どこを直せばいいかも分からない。**── だからこの枠組みは、ゴールじゃなくて、説明可能なAIを目指すための「共通のものさし」なんだよ。
学部生:
「解釈できる/できない」を、感覚じゃなくて、図の構造として定義し直したんですね。
講師:
まさに。
だから、この論文の射程は QNLP を超えている。
「説明可能な AI とは何か」を、圏論とひも図で、原理から定義しようとした仕事なんだ。
学部生:
QNLP の話だと思っていたら、AI全体の「説明可能性」の話に広がっているんですね。
講師:
そこがこの論文の射程の広さだ。
QNLP(DisCoCat / DisCoCirc)で培った「合成的に意味を組み立てる」という発想を、AI一般の解釈可能性の理論にまで一般化した
── そういう位置づけの仕事 なんだ。興味が湧いたら、ここから読んでみるといい。
学部生:
判断を「図」にできれば、その図を調べることで、検証や説明ができるかもしれない、と。
講師:
そこが希望の芽だ。
図は、規則にそって操作・変形できる。
判断の構造が図として残るなら、「この図は、この安全条件を満たすか」を、図のレベルで論じられる可能性がある。
説明可能性(なぜそう判断したか)と、形式検証(絶対に間違えないか)は、“構造が見える”という一点で、地続きなんだ。
学部生:
でも、まだ「可能性」なんですよね?
講師:
そこは正直に言う。
いま、QNLP で自動運転の安全を保証した、という実用例はない。
安全が重要視される分野で実際に使われているのは、量子ではなく古典の形式検証技術だ。
NLP 自体、まだ小さな文の分類ができる研究段階にすぎない。
だから、これは「現状の実用」ではなく「将来の可能性」の話として聞いてほしい。
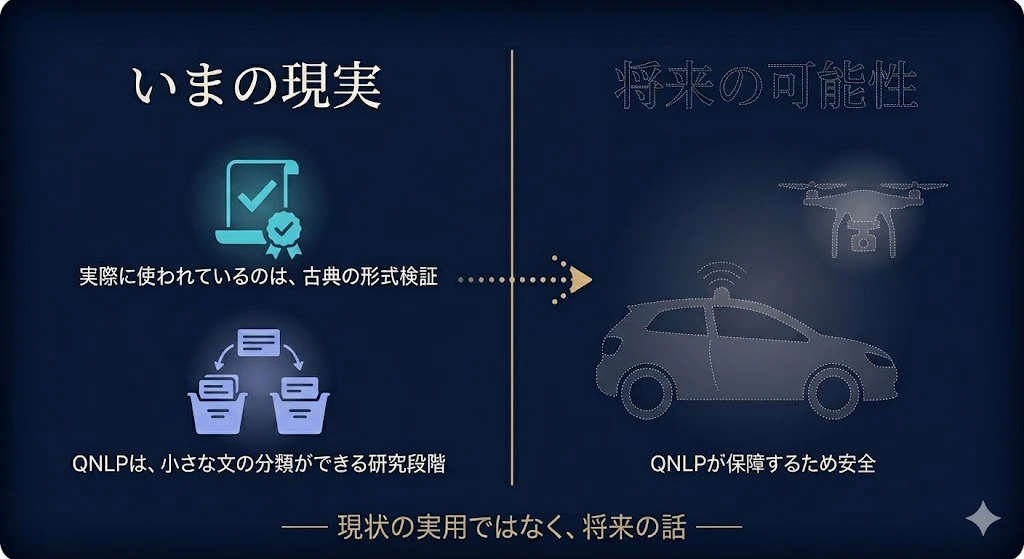
ただ、地図としてはこう描ける。
片方に、「安全のために、AI の判断を検証・説明したい」という社会からの強い要請がある。
もう片方に、「意味や判断を、合成的な図として透明に表す」という圏論的アプローチの強みがある。
この2つが、いつか出会うかもしれない
── その交差点に、QNLPと圏論的XAI は立っている。
すぐ実るかは分からない。
でも、追いかける価値のある方向だと、僕は思っているよ。
学部生:
「賢いAI」だけじゃなく、「信頼できるAI」をどう作るか。その問いに、この理論が一枚かんでくるかもしれない、と。
講師:
そういうことだ。
説明可能性は、単に「親切」なだけじゃない。安全を保証するための、土台にもなりうるんだ。

まとめ
-
QNLP(量子自然言語処理) は、「文の意味」を量子回路として表し、量子コンピュータで計算しようとする試み。
- 出発点は、文法の配線図と、量子の合成構造が、同じ数学の形(モノイダル圏)をしているという発見。
- その枠組みが DisCoCat(クーケ・サドルザーデ・クラーク 2010)で、「単語ベクトル(材料)」を「文法(設計図)」にそって組み合わせ、文の意味を計算する。
- Python ライブラリ lambeq を使えば、
pip installして、文を「ひも図 → 量子回路」へ変換できる。量子機がなくても、テンソルネットワークとして古典シミュレーションも可能。
- いまの LLM とは系統が違い、性能を競う段階ではない。QNLP の価値は、意味の合成の透明さと、圏論という共通言語で物理・言語・論理をつなぐ普遍性にある。
- その透明さ(説明可能性)は、自動運転・ドローン・社会インフラのような「絶対に間違えてはいけないAI」を、形式検証で保証したいという流れともつながりうる。Coecke らの 「合成的解釈可能性」(2024)は、その交差点を見据えた一歩 ── ただし現状は、まだ実用段階には到達しておらず、あくまで将来の可能性に期待がかかる段階。
日常言語の文法という、誰もが毎日使っている身近なものの奥に、量子と同じ数学の骨格が眠っている ── そのことに気づかせてくれるだけでも、この分野は一見の価値があります。
Transformer が「大量の文章から、意味を統計的に学ぶ」道だとすれば、QNLP は「意味の組み立て方そのものを計算する」道です。
どちらが主流になるかは、まだ誰にも分かりません。

けれど、言語と量子が、同じ数学の骨格を共有しているという発見は ── それだけで、十分に驚くべきことではないでしょうか。

関連する話題 ── この先に広がる「対応」の地図(さわりだけ)
本編の途中で、学部生が「これはカリー・ハワード対応や圏論、さらにはラングランズ・プログラムと関係あるのでは?」と問いかけました。
その約束どおり、ここでは地図だけを、ごく簡単に眺めます。
本格的な解説は、それぞれ別の記事に譲ります(深入りすると、それだけで何本も書けてしまう大鉱脈なので)。
学部生:
さっきの「名詞=値、動詞=関数」から、ぐっと話が広がった気がします。
最後に、その地図を見せてください。
講師:
いいよ。3つだけ、距離感に気をつけながら並べよう。
「どれくらい近いか」を正直に言うのが大事だからね。
① カリー・ハワード(・ランベック)対応 ── これは「本物の対応」。
「論理の証明」と「プログラム」が、同じ構造を持つ ── これがカリー・ハワード対応だ。
証明を書くことと、プログラムを書くことが、深いところで同じ営みだ、という発見だね。
そこに、圏論を加えると、三つ巴の カリー・ハワード・ランベック対応になる。
証明・プログラム・圏が、同じ構造の三つの顔だ、という話だ。
ただし、ひとつ正確に言っておく。
これらは「厳密な同型」とまで言うのは、実は言い過ぎでね。
専門的には、「アナロジー以上、同型未満」── 部分ごとにきっちりした対応はあるけれど、丸ごと同じ、ではない。
そこは誠実に区別しておきたい。
学部生:
そして、その結び目に Lambek がいた、と。
講師:
そうだね。
QNLP の文法を作った人と、この対応に名を残した人が、同じ Joachim Lambek。論理・プログラム・圏論・言語が同じ骨格を持つ、という物語の、ちょうど留め金の位置にいた人だ。
だから、君の 「名詞=値、動詞=関数」という直感 が、この大きな対応の入口に通じていた のも、偶然じゃないんだよ。
② 圏論 ── これは「共通の言葉」そのもの。
圏論は、「違って見える分野のあいだに、同じ構造を見つけて橋を架ける」ための数学だ。
QNLP も、カリー・ハワード・ランベックも、その橋のひとつ。
この記事でずっとやってきた「文法と量子が同じモノイダル圏」という話自体が、圏論の橋渡しの実例だった、というわけだね。
③ ラングランズ・プログラム ── これは「精神的な親戚」。距離は遠い。
ここはいちばん慎重に言うよ。
ラングランズ・プログラムは、数論と幾何という、まったく別々に見える分野のあいだに、深い対応がある、と予想する壮大な計画だ。
── ただし、「QNLP やカリー・ハワードと、ラングランズが数学的に同型だ」と言うのは、少し踏み込み過ぎて、過剰な主張になり、危うい。。
直接の同型関係があるわけじゃないからね。
似ているのは、あくまで精神のほうだ。
「遠く離れて見える世界が、深いところでひとつの構造でつながっている」
── そういう“橋を架ける”発想において、よく似ている。
実際、カリー・ハワード・ランベックを「ささやかなラングランズのようなものだ」となぞらえる人もいるくらいでね。
血縁ではなく、精神的な親戚。それくらいの距離感が、ちょうど正確なんだ。
学部生:
「同じだ」と言いたくなるけど、そこをぐっとこらえて「精神的な親戚」と言う ── その距離の取り方が、誠実なんですね。
講師:
そういうことだ。安易に「すべては同じ」と言わないことが、かえって本当の面白さを守る。
それぞれの対応が、どこまで厳密でどこから比喩なのか ── その線引きにこそ、数学の誠実さがある。
この3つは、どれも一本の記事になる大きな話だ。
いつか、別の Qiita 記事で、ひとつずつじっくり歩いてみよう。今日は、地図の上に旗を立てたところで、筆を置くことにするよ。
おわりに
学部生:
……ここまで来て、ひとつ大きなことを考えてしまいました。
QNLP を足がかりに、カリー・ハワード対応、圏論、ラングランズ ── 隣接する分野への入り口(接続)が、いくつも見えてきましたよね。
そういえば、前に話した僕の兄が、最近「自分は 数学的宇宙論者になりつつある」と言うんです。
物理学者の Max Tegmark が唱えた世界観だそうで。
この世界観、僕は、こういうことなんじゃないか、と思うんです。
── 圏論を蝶番(ちょうつがい)にした、自然言語と量子回路の構造的な同一性。
その背後には、自然言語にも、論理(公理系)にも、いろんな数学にも、物理学にも現れる圏論的な構造がある。
それらすべては、ある共通した数理的な構造が背後にあって、そこから現象として立ち現れたものなんじゃないか。
自然言語も、論理の公理系も、数学の各分野の方程式も、物理の方程式も。
── つまり、この宇宙と、人間の知的世界は、すべて、一つの数理的な構造体を、異なる角度から眺めた描像にすぎない。
そんな世界観を、ここから提案してくる人たちも、出てくるのかもしれませんね。
講師:
……壮大なところに着地したね。
その直感が湧いてくる気持ちは、よく分かるよ。
これだけ違う分野が同じ圏論的な構造を共有しているのを見ると、「背後に、たったひとつの数理構造があるのでは」と言いたくなる。
ただ ── ここでも、距離を正確に取ろう。
Tegmark の数学的宇宙仮説は、とても刺激的だけれど、あくまで一つの“哲学的・形而上学的な仮説”だ。
物理学者や哲学者のあいだでも、賛否が大きく分かれている。
そして大事なのは、QNLP や、この記事で見てきた構造的な同一性が、その仮説を“裏づけている”わけではない、ということだ。
学部生:
あくまで、別の話だ と。
講師:
そうだ。
僕らが見てきたのは、「いくつかの具体的な分野のあいだに、圏論で記述できる対応がある」という、地に足のついた事実 だ。
その一方で、「宇宙のすべてが数学的構造そのものだ」というのは、そこから一足飛びに跳ぶ、はるかに大きな主張でね。
前者は後者の証拠にはならない。
「似た構造があちこちに見つかる」ことと、「だから世界の本質は数学だ」と結論することのあいだには、まだ大きな飛躍 がある。
でも ── こういう問いを抱くこと自体は、すばらしいと思う。
圏論や QNLP が面白いのは、まさにこういう「世界の見え方そのものを揺さぶる問い」へ、自然に人を連れていくからだ。
ただし、ロマンと、論証は、分けて持つ。
「すべては一つの構造の現れかもしれない」というロマンを胸に抱きながら、足元では「この対応は、どこまで厳密で、どこからが比喩か」を冷静に見極める。
── その両方を持てる人が、いちばん遠くまで行ける よ。
学部生:
ロマンと、論証を、分けて持つ。……肝に銘じます。

参考文献
- Coecke, B., Sadrzadeh, M., Clark, S. (2010). "Mathematical Foundations for a Compositional Distributional Model of Meaning." Linguistic Analysis, 36.(DisCoCat の原論文)
- Abramsky, S., Coecke, B. (2004). "A categorical semantics of quantum protocols." LICS 2004.(圏論的量子力学の出発点)
- Kartsaklis, D. et al. (2021). "lambeq: An Efficient High-Level Python Library for Quantum NLP." arXiv:2110.04236.(lambeq の技術論文)
- de Felice, G., Toumi, A., Coecke, B. (2020). "DisCoPy: Monoidal Categories in Python." ACT 2020.(lambeq のバックエンド)
- Lambek, J. (1999/2008). 型論理・プレグループ文法に関する一連の研究。
- lambeq 公式ドキュメント(Quantinuum): パイプライン(構文解析 → ひも図 → 簡約 → 量子回路/テンソルネットワーク)の各段階の解説。
- Tull, S., Shaikh, R. A., et al./Coecke, B. ら (2024). "Towards Compositional Interpretability for XAI." arXiv:2406.17583.(圏論にもとづく説明可能AI=合成的解釈可能性の枠組み)
- 量子自然言語処理(QNLP)の産業連携に関する一連の公表資料(Quantinuum・UCL・BBC コンソーシアム、製薬 Merck の早期評価、Quantinuum・中部大学の共同研究 など)。
- ニューラルネットの形式検証・安全クリティカルAIに関するサーベイ(NNV ツール、VNN-COMP、ISO 26262/SOTIF の現状など)。
- Curry–Howard–Lambek 対応(証明=プログラム=圏の対応)に関する解説。なお、これらは「アナロジー以上・同型未満」であり、厳密な同型とまでは言えない点に注意。ラングランズ・プログラムとは数学的な同型関係ではなく、「離れた分野を橋渡しする」という精神において類比的に語られることがある。
※ 本記事は対話形式の解説です。登場人物・大学は架空ですが、理論・ライブラリ・実験は上記の実在の研究にもとづいています。
コード例は概念を伝えるためのイメージを含み、実際の API はバージョンにより異なる場合があります。専門家の方々からのご指摘・ご指導を歓迎します。