
"自分の記事、最近、ChatGPTやClaude、Perplexityから参照されている気がする。
でも、それが本当に起きているのか、何もわからない。
いいねも、ハートも、フォローも付かないAI Agentの足跡を、どうやって可視化すればいいのか"
note・Qiita・Zenn・Medium・dev.to・Substack・個人ブログ
── さまざまな媒体で記事を発信されている書き手の皆様、AI 時代の書き手として、こんな違和感、課題感を感じたことはありませんか?

この記事は、その違和感を、技術的に解明し、可能な範囲で可視化するための実装ガイドです。

なお、この記事は、2026年5月時点で確認できる公開情報を整理したものです。
AI企業やプラットフォームの仕様変更により、内容は変化する可能性があります。
TL;DR(記事全体像)
-
AI Agent(GPTBot、ClaudeBot、PerplexityBot等)が、あなたの記事を読んでいるのは事実だが、note・Qiita・Zenn・Medium 等のホスティング型プラットフォームでは、その足跡は基本的に見えない。
- AI Agent の足跡を可視化できるのは、自分のサーバーで運営しているブログ・サイト(独自ドメイン、GitHub Pages、Vercel、Cloudflare Pages、WordPress、Hugo、Astro、Hashnode、Ghost 等)のみ。
- 可視化の3つの主要アプローチ:(1) サーバー access ログの直接解析(無料・最高精度・要技術力)、(2) Cloudflare AI Crawl Control(無料・GUI・全Cloudflareプランで利用可能)、(3) Edge middleware(Vercel Edge Functions、Cloudflare Workers でリアルタイム可視化)。
-
重大な注意点:
(a) AI Bot は User-Agent を偽装可能
(b) Cloudflare 報告(2025年8月)で Perplexity は未宣言クローラーで robots.txt 回避が確認されている、
(c) AI Bot は3カテゴリ(訓練・検索・エージェント)あり、混同すると分析が無意味になる
(d) IP 検証 + reverse DNS が canonical verification
(e) llms.txt は2026年現在も主要LLM に "meaningful volume" では読まれない。
- ホスティング型プラットフォーム(note・Qiita・Zenn)の書き手のための回避策:自分専用の独自ドメイン上のサイトを"鏡"として運営し、記事の原本やナビゲーション・ハブをそこに置く方法。
-
本記事を読んで解消される悩み:
「AI Agent が自分の記事を読んでいるかどうか分からない」
「サーバーログをどう解析すればよいか分からない」
「Cloudflare AI Crawl Control は何ができるのか」
「llms.txt とは何で、効果はあるのか」。
-
本記事を読んでも解消されない悩み:
「note・Qiita・Zenn 上で AI Agent の足跡を直接見たい」
「AI Agent から金銭的報酬を得たい(Pay Per Crawl は限定的状況のみ)」
「Perplexity のような未宣言クローラーを確実に検出したい」
「ChatGPT・Claude 上で実際に何回引用されたか数えたい」。
想定読者

本記事は、以下の方々を想定読者としています。
-
Qiita 技術者(データサイエンティスト、ML エンジニア、SRE、セキュリティ研究者、Web エンジニア)── 自分の Qiita 記事が、 AIに読まれているか気になっている方
-
note クリエイター(特に専門性の高いコンテンツを継続的に書く方)── note の「スキ」では測れない記事の真の到達範囲を知りたい方
-
Zenn 技術書執筆者 ── 自分のZenn記事 / Zenn Book技術書が、AIのコード生成や回答に参照されているか調べたい方
-
Medium・dev.to ライター ── 英語圏での AI Agent の挙動を把握したい方
-
Substack ニュースレター運営者 ── ニュースレターのアーカイブページが、AIに参照されているか知りたい方
-
個人ブロガー(独自ドメイン・GitHub Pages・WordPress・Hugo・Astro 等)── 自分のサイトのサーバーログから AI Agent の活動を可視化したい方
-
企業の技術広報・コンテンツマーケティング担当者 ── 自社オウンドメディアでの AI Agent 訪問を CTO や経営陣に報告したい方
そして、上記のいずれにも該当しない方でも、「自分の書いた文章が、AI Agent によってどのように読まれているのか」という問いに関心を持つすべての書き手を歓迎します。
皆様が抱えるお悩み内容
私が本記事の調査と執筆を進める中で、複数のブログ記事・コミュニティ投稿・Cloudflare 公式調査資料から確認できた、書き手の皆様が抱えている代表的なお悩みは、以下のとおりです。
1.「AI に読まれている実感はあるが、証拠がない」という不確実性のお悩み。
ChatGPT に質問したら自分の記事と似た内容が返ってきた。
Perplexity の回答に自分の記事のフレーズらしきものがあった。
── けれども、それが本当に自分の記事を参照したのか、たまたま似ているだけなのか、判別できない。
2. 「note・Qiita・Zenn にはサーバーログにアクセスできない」という構造的限界のお悩み。
ホスティング型プラットフォームでは、自分の記事に対するアクセス情報はプラットフォーム提供の管理画面(note ダッシュボードのビュー数、Qiita の Contributionsの数)でしか見えない。
AI Bot の User-Agent 別アクセス数のような粒度では確認できない。
3. 「いいね・ハート・フォロー以外の指標で評価を測りたい」という評価指標のお悩み。
note のスキ数、Qiita のいいね、Zenn のハートは、人間の読者の瞬間的な感情反応を捉えますが、AI Agentが記事を参照する行動は、これらの指標には現れません。
書き手としての真の到達範囲を測る指標が欲しい。
4. 「自分のサイトを持っているが、AI Bot のアクセスをどう解析すればよいか分からない」という技術実装のお悩み。
Apache や Nginx の access.log は持っているが、grep でフィルタリングする以上の体系的な解析方法が分からない。
Cloudflare、Vercel、Netlify 等を使っているが、AI Bot 可視化機能をどう活用すればよいか分からない。
5. 「Cloudflare AI Crawl Control、llms.txt、robots.txt の関係が整理できていない」という概念整理のお悩み。
新しい標準やツールが次々と登場するが、それぞれの役割と限界が混乱している。
6. 「AI Bot を block すべきか allow すべきか判断できない」という戦略判断のお悩み。
AI Bot の訪問は、コンテンツ盗用のリスクなのか、新しい到達経路の機会なのか。
本記事は、これらのお悩みのうち、1・2・3・4・5について、現時点(2026年5月)で技術的に実装可能な解決策と、その限界を、誠実に整理します。
6番目のお悩み(戦略判断)については、判断材料を提供しますが、最終判断は各書き手の戦略に委ねます。
1. 前提知識 ── AI Bot とは何で、なぜ書き手が気にすべきか
1-1. AI Bot の3つのカテゴリ
AI Bot は、目的によって3つのカテゴリに分けられます。
この区別を理解しないと、後の分析がすべて無意味になります。
カテゴリ1:訓練ボット(Training Bot)
LLM(大規模言語モデル)を訓練するためのデータを収集するボット。
代表例は、 GPTBot(OpenAI)、ClaudeBot(Anthropic)、Google-Extended、Applebot-Extended、CCBot(Common Crawl)、Bytespider(ByteDance)、Amazonbot、Meta-ExternalAgentです。
これらのボットがあなたの記事を読むということは、あなたの記事の内容が、次のモデルのバージョンの訓練データに含まれる可能性があることを意味します。
一度訓練データに含まれてしまうと、AI モデルの中に永続的に取り込まれる可能性があります。
カテゴリ2:検索ボット(Search Bot)
AI検索エンジンのインデックスを構築するボット。
代表例は OAI-SearchBot(OpenAI の AI 検索)、Claude-SearchBot(Anthropic)、PerplexityBot、DuckAssistBot。
これらのボットは、AI Agent がユーザーの質問に答える際にリアルタイムで参照するためのインデックスを構築します。
あなたの記事がここに登録されると、AI 検索でユーザーがあなたの専門領域の質問をした際に、引用される可能性が高まります。
カテゴリ3:エージェント(User-triggered Fetcher / Agent)
ユーザーが AI に質問した瞬間に、リアルタイムでウェブをフェッチして回答に組み込むエージェントです。
代表例は ChatGPT-User(ChatGPT がユーザー質問のためにフェッチする際)、Claude-User(Claude が同様)、Perplexity-User、Gemini-Deep-Research(Gemini の深い研究エージェント)、MistralAI-Userです。
これらのボットの訪問は、今この瞬間に、誰かがあなたの専門領域に関する質問を AI にしていることを意味します。
最も書き手にとって生々しいカテゴリです。
カテゴリ4:Google AI Overviews(カテゴリ外の例外)
Google AI Overviews は、Cloudflare による分析記事によれば、独自のリアルタイムボットを持ちません。
既存の Googlebot がインデックスした内容から回答を生成します。
例外として、Gemini-Deep-Research が深い研究タスクのためにリアルタイムフェッチを行います。
カテゴリ5:偽装ボット
問題は、これらのカテゴリ以外に、User-Agent を一般のブラウザ(Chrome、Safari 等)に偽装してアクセスするボットが存在することです。
Cloudflare の2025年8月の調査によれば、Perplexity が宣言クローラー以外に、未宣言の User-Agent と IP をローテーションするクローラーを使い、robots.txt を回避していたことが報告されました。
つまり、後で説明する User-Agent ベースの検出方法には、根本的な限界があることを、最初に理解しておく必要があります。
1-2. AI Bot の現在の規模感(対象期間:2025年~2026年)
Cloudflare による 2025-2026 の調査データから、業界の現在地が見えます。
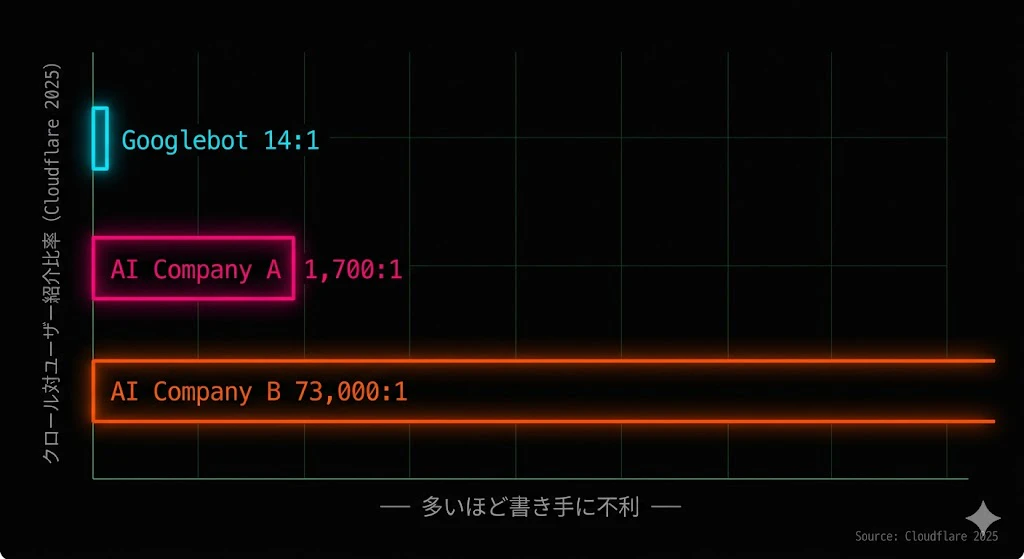
- 2024年5月から2025年5月にかけて、クローラートラフィック全体が18%増加、特に GPTBot のトラフィックは305%増、Googlebot は96%増(Cloudflare、2025年)
- Cloudflare 上のトップドメイン100万のうち、約39%が AI Bot にクロールされているが、約3%しか何らかの対策(ブロック・スロットリング)を実装していない(2024年6月時点、Cloudflare)
- 主要検索クローラー(Googlebot 等)のクロール対ユーザー紹介比率が約14:1 であるのに対し、一部の AI 企業は1,700:1、最も極端なケースで73,000:1(Cloudflare、2025年中盤)── つまり、AI 企業はあなたの記事を1,700回ないし73,000回読む間に、ユーザーを1回しか送り返さない
- Cloudflare AI Crawl Control(旧 AI Audit)の顧客は、1日あたり 10億件以上の HTTP 402 レスポンス(Payment Required)を送信している(2025年9月、Cloudflare)
これらの数字は、AI Bot の活動が、書き手・パブリッシャー・コンテンツ作成者の経済構造を、根本から変えつつあることを示しています。
1-3. 主要な AI Bot User-Agent カタログ(2026年5月時点)

以下、現時点で確認されている主要な AI Bot の User-Agent 文字列をカタログ化します。
注意喚起
これらの User-Agent 文字列は、AI 企業の判断で予告なく変更されることがあります。
実装時には、必ず最新の公式情報を確認してください。
# OpenAI
GPTBot → 訓練ボット
OAI-SearchBot → ChatGPT検索インデックス
ChatGPT-User → ChatGPTユーザー質問時のフェッチ
# Anthropic
ClaudeBot / anthropic-ai → 訓練ボット
Claude-SearchBot → Claude検索(2025年後半に確認)
Claude-User → Claudeユーザー質問時のフェッチ
# Perplexity
PerplexityBot → 検索インデックス
Perplexity-User → ユーザー質問時のフェッチ(robots.txt を尊重しないと公言)
# Google
Google-Extended → Gemini訓練用(Googlebotとは別)
Google-Agent → 2026年春に登場した新エージェント
Google-NotebookLM → NotebookLMのフェッチ
Google-Read-Aloud → 読み上げ機能のフェッチ
Google-CloudVertexBot → Vertex AI関連
# Apple
Applebot-Extended → Apple Intelligence訓練用
# Meta
meta-externalagent / FacebookBot → Meta AI関連
# ByteDance
Bytespider → Doubao/TikTok関連訓練
# その他
CCBot → Common Crawl
Amazonbot → Amazon Alexa関連
MistralAI-User → Mistral AI
DuckAssistBot → DuckDuckGo AI
これらの User-Agent を grep やフィルタリングで検出することが、可視化の最初のステップです。
2. 可視化アプローチ1:サーバー access ログの直接解析
最も精度が高く、最もコストが安い(無料)アプローチです。
ただし、自分でサーバーを運営している場合に限り利用できます。
2-1. 前提条件
- 独自ドメインで運営しているサイト
- Apache、Nginx、Caddy、または同等のウェブサーバー
- サーバーへの SSH または FTP アクセス権限
- Linux コマンドの基本的な操作能力
note・Qiita・Zenn のホスティング型プラットフォームでは、この方法は使用できません。
皆様の記事のサーバーログは、プラットフォーム側のサーバーで管理されており、ユーザーには公開されないからです。
2-2. ログファイルの場所
# Nginx の場合(典型例)
/var/log/nginx/access.log
# Apache の場合(典型例)
/var/log/apache2/access.log
# Caddy の場合
caddy.log(設定によって異なる)
# Vercel、Netlify、Cloudflare Pages 等
ダッシュボードからエクスポート、または専用のログ製品を使用
2-3. 基本的なフィルタリング(grep)
最も基本的な方法は、grep でフィルタリングすることです。
# GPTBot の訪問を抽出
grep "GPTBot" /var/log/nginx/access.log
# 複数の AI Bot をまとめて抽出
grep -E "GPTBot|ClaudeBot|PerplexityBot|Google-Extended|Bytespider" /var/log/nginx/access.log
# 過去7日間の AI Bot の総訪問数をカウント
grep -E "GPTBot|ClaudeBot|PerplexityBot" /var/log/nginx/access.log | wc -l
# 訓練ボットだけを抽出
grep -E "GPTBot|ClaudeBot|Google-Extended|Bytespider|CCBot|Applebot-Extended" /var/log/nginx/access.log
# 検索・エージェントボットだけを抽出(より意味のある分析)
grep -E "OAI-SearchBot|ChatGPT-User|Claude-SearchBot|Claude-User|PerplexityBot|Perplexity-User|Gemini-Deep-Research" /var/log/nginx/access.log
注記
訓練ボットと検索・エージェントボットを分離しないと、データが無意味になります。
GPTBotの急増は、単に、OpenAI がデータセットを更新している可能性があります。
ChatGPT-User の急増こそが、皆様が情報発信をされているテーマや論点で、誰かがAgentに対して質問をしていることを意味します。
2-4. GoAccess による可視化
GoAccess は、Web サーバーのアクセスログをリアルタイムで解析し、ターミナル上の TUI(テキスト UI)または HTML ダッシュボードで可視化するツールです。
# インストール(Ubuntu/Debian)
sudo apt install goaccess
# ターミナルで可視化
goaccess /var/log/nginx/access.log -c
# HTML レポートを生成
goaccess /var/log/nginx/access.log -o /var/www/html/report.html --log-format=COMBINED
GoAccess は User-Agent 別のアクセス数を自動集計してくれるため、AI Bot の活動を一目で把握できます。
2-5. Python による詳細分析
より柔軟な分析が必要な場合、Python で access.log をパースし、Pandas DataFrame に流し込んで分析します。
import pandas as pd
import re
from datetime import datetime
# Nginx combined log format のパターン
LOG_PATTERN = re.compile(
r'(?P<ip>\S+) - - \[(?P<time>[^\]]+)\] '
r'"(?P<method>\S+) (?P<url>\S+) (?P<protocol>\S+)" '
r'(?P<status>\d+) (?P<size>\d+) '
r'"(?P<referrer>[^"]*)" "(?P<user_agent>[^"]*)"'
)
# AI Bot のパターン
AI_BOT_PATTERNS = {
'training': r'(GPTBot|ClaudeBot|anthropic-ai|Google-Extended|Bytespider|CCBot|Applebot-Extended|Amazonbot|meta-externalagent)',
'search': r'(OAI-SearchBot|Claude-SearchBot|PerplexityBot|DuckAssistBot)',
'agent': r'(ChatGPT-User|Claude-User|Perplexity-User|Gemini-Deep-Research|MistralAI-User)',
}
def classify_bot(user_agent):
for category, pattern in AI_BOT_PATTERNS.items():
if re.search(pattern, user_agent):
return category
return 'other'
def parse_log(log_file):
records = []
with open(log_file, 'r') as f:
for line in f:
m = LOG_PATTERN.match(line)
if m:
d = m.groupdict()
d['bot_category'] = classify_bot(d['user_agent'])
records.append(d)
return pd.DataFrame(records)
df = parse_log('/var/log/nginx/access.log')
# AI Bot 別の訪問数集計
bot_counts = df[df['bot_category'] != 'other'].groupby('bot_category').size()
print(bot_counts)
# 最も読まれた記事 TOP10(AI Agent カテゴリのみ)
top_articles = df[df['bot_category'] == 'agent'].groupby('url').size().sort_values(ascending=False).head(10)
print(top_articles)
# 時間帯別のヒートマップ生成も可能
このスクリプトをベースに、Plotly、Streamlit、Grafana 等で可視化ダッシュボードを構築できます。

2-6. このアプローチの利点と限界
利点:
- 完全無料(既存のサーバーログを使うだけ)
- 最高精度(実際のサーバーレベルの記録)
- 柔軟な分析(Python・SQL・任意のツールで自由に分析可能)
- 過去ログの遡及分析が可能(ログを保持していれば過去まで遡れる)
限界:
- 自分でサーバーを運営している場合のみ利用可能
- CDN を使用している場合(Cloudflare、Vercel、Netlify 等)、CDN レベルで完結する一部のリクエストは origin サーバーに到達しないため、CDN 側のログ製品が別途必要
- User-Agent を偽装するボットは検出不可
- 解析・可視化に技術力が必要
3. 可視化アプローチ2:Cloudflare AI Crawl Control(推奨)
これは、技術力がそこまでない書き手にとって、最もコストパフォーマンスの良いアプローチです。
3-1. Cloudflare AI Crawl Control とは

Cloudflare が2024年9月に「AI Audit」として開始し、2025年9月に「AI Crawl Control」に改称した機能です。Cloudflare の全プラン(無料プランを含む)で利用可能です。
機能の概要:
- AI Bot の訪問を自動集計(GUI ダッシュボードで可視化)
- AI Bot をワンクリックでブロック / 許可可能
- robots.txt の自動管理(Cloudflare が代行)
- Pay Per Crawl(AI Bot からの課金、HTTP 402 Payment Required を返す)── 2025年9月から全顧客に展開
- Web Bot Auth に基づく暗号学的な Bot 認証(2026年から)
3-2. 設定手順
- Cloudflare アカウントを作成(無料プランで可)
- 自分のドメインを Cloudflare に追加(DNS の nameserver を Cloudflare のものに変更する必要あり)
- Cloudflare ダッシュボードで対象のサイトを選択
- 左サイドバーから「AI Crawl Control」(旧称:AI Audit)を選択
- 数日待つと、自動的に AI Bot の活動データが蓄積される
設定後、ダッシュボード上で以下が見えるようになります:
- AI Bot 別のリクエスト数(時系列グラフ)
- AI Bot 別の人気ページランキング
- robots.txt 遵守状況
- ブロック / 許可ルールの設定 GUI
3-3. このアプローチの利点と限界
利点:
- 無料(Cloudflare 無料プランで利用可能)
- 設定が簡単(GUI で完結、コマンドライン不要)
- 継続的にアップデートされる(新しい AI Bot 検出が自動追加される)
- ブロック / 許可のアクションがダッシュボードから直接可能
- Pay Per Crawl による収益化の選択肢(限定的だが可能)
限界:
- Cloudflare 経由でサイトを配信する必要がある(DNS の変更が必要)
- note・Qiita・Zenn 等のホスティング型プラットフォームには使えない(Cloudflare を間に挟めないため)
- ブロックすると AI 検索からの可視性が失われる可能性
- Pay Per Crawl は実際に支払う AI 企業が限られている
4. 可視化アプローチ3:Edge Middleware(Vercel / Cloudflare Workers)
技術力のあるエンジニアにとって、最も柔軟でリアルタイムなアプローチです。
4-1. Vercel Edge Functions の場合
Vercel でホスティングしているサイト(Next.js、Astro、Hugo 等)の場合、Edge Functions で AI Bot のリクエストを傍受し、リアルタイムでログ収集や対応が可能です。
// middleware.ts (Next.js + Vercel の場合)
import { NextResponse } from 'next/server';
import type { NextRequest } from 'next/server';
const AI_BOT_PATTERNS = {
training: /GPTBot|ClaudeBot|anthropic-ai|Google-Extended|Bytespider|CCBot|Applebot-Extended|Amazonbot|meta-externalagent/i,
search: /OAI-SearchBot|Claude-SearchBot|PerplexityBot|DuckAssistBot/i,
agent: /ChatGPT-User|Claude-User|Perplexity-User|Gemini-Deep-Research|MistralAI-User/i,
};
function classifyBot(userAgent: string): string | null {
for (const [category, pattern] of Object.entries(AI_BOT_PATTERNS)) {
if (pattern.test(userAgent)) return category;
}
return null;
}
export async function middleware(req: NextRequest) {
const userAgent = req.headers.get('user-agent') || '';
const botCategory = classifyBot(userAgent);
if (botCategory) {
// ログ収集サービスに送信(例:Axiom、Logtail、Datadog 等)
await fetch('https://api.axiom.co/v1/datasets/ai-bots/ingest', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.AXIOM_TOKEN}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
timestamp: new Date().toISOString(),
category: botCategory,
user_agent: userAgent,
url: req.url,
ip: req.ip,
}),
});
// ここでブロック・カスタムコンテンツ配信・リダイレクト等も可能
}
return NextResponse.next();
}
export const config = {
matcher: '/((?!_next/static|_next/image|favicon.ico).*)',
};
4-2. Cloudflare Workers の場合
Cloudflare Workers でも同様の処理が可能です。Cloudflare AI Crawl Control の機能を補完するカスタムロジックを実装できます。
// worker.js
const AI_BOT_PATTERNS = {
training: /GPTBot|ClaudeBot|anthropic-ai|Google-Extended|Bytespider|CCBot/i,
search: /OAI-SearchBot|Claude-SearchBot|PerplexityBot|DuckAssistBot/i,
agent: /ChatGPT-User|Claude-User|Perplexity-User|Gemini-Deep-Research/i,
};
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
const userAgent = request.headers.get('user-agent') || '';
for (const [category, pattern] of Object.entries(AI_BOT_PATTERNS)) {
if (pattern.test(userAgent)) {
// Cloudflare Analytics Engine にイベント記録
await ANALYTICS.writeDataPoint({
blobs: [category, userAgent, request.url],
doubles: [Date.now()],
indexes: [category],
});
break;
}
}
return fetch(request);
}
4-3. このアプローチの利点と限界
利点:
- リアルタイム処理(ログを後から解析するのではなく、リクエスト時に即座に対応)
- プログラマティックな対応が可能(ブロック、カスタムコンテンツ配信、認証要求等)
- 任意のログ収集サービスに統合可能(Axiom、Logtail、Datadog、Honeycomb、New Relic 等)
限界:
- プラットフォーム依存(Vercel Edge Functions のコードは Cloudflare Workers では動かない)
- 継続的なメンテナンスが必要(新しい AI Bot User-Agent への対応)
- ログ収集サービスのコストが発生する場合あり
5. 補助的な仕組み:robots.txt と llms.txt

5-1. robots.txt の役割と限界
robots.txt は、サイトのルート(example.com/robots.txt)に配置されるテキストファイルで、各 User-Agent に対してどのパスへのアクセスを許可・禁止するかを指定します。
# 訓練ボットだけブロック、検索・エージェントは許可
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
# 検索・エージェントは許可
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
限界:
- 遵守は AI 企業の自主性に依存。法的強制力はない。
- Perplexity-User は robots.txt を尊重しないと Perplexity が公言(2024年)
- Cloudflare 2025年8月報告:Perplexity が未宣言クローラーで robots.txt を回避している事例を確認
- 訓練ボットをブロックしても、過去に既に訓練データに含まれた情報は削除できない
つまり、robots.txt は法的・倫理的な意思表示にはなるが、技術的な強制力にはならないことを理解する必要があります。
5-2. llms.txt の役割と限界
llms.txt は、2024年9月に Jeremy Howard(Answer.AI / FastAI 創業者)が提案した、新しいファイル仕様です。
サイトのルート(example.com/llms.txt)に配置される markdownファイルで、AI に対してサイトの最重要コンテンツを構造化して提示します。
# Example Site
> サイトの一言要約
## 主要な記事
- [記事タイトル1](https://example.com/article1) : 短い説明
- [記事タイトル2](https://example.com/article2) : 短い説明
採用状況(2026年5月時点):
- 採用企業:Anthropic、Stripe、Cursor、Cloudflare、Vercel、Mintlify、Supabase、LangGraph
- 採用率:全ウェブサイトの約10%
- OpenAI、Google、Anthropic の主要クローラーは "meaningful volume" では読まない(GPTBot は時々 fetch する程度)
- 2025年11月の SERanking 30万ドメイン調査:「AI 引用に測定可能な効果なし」と判明
llms.txt の真の価値:
- IDE エージェント(Cursor、Continue、Cline)と MCP 統合
- 将来の標準化への備えとしては低コスト(実装に数時間)
- W3C・IETF 標準ではない(コミュニティ標準のみ)
つまり、llms.txt は2026年現在、**「やっておいて損はないが、目に見える効果は期待しすぎないほうがよい」**という位置づけです。
6. 注意点まとめ(必ず読んでください)
可視化を始める前に、以下の注意点を必ず理解してください。
6-1. User-Agent は偽装可能
最も根本的な注意点です。HTTP リクエストの User-Agent ヘッダーは、リクエスト送信側が任意の文字列を設定できます。AI Bot を装ったスパムボットも、通常のブラウザを装った AI Bot も、技術的に存在します。
Cloudflare の 2025年7月時点の公式見解:「既存の識別方法は、IP アドレス範囲(他のサービスと共有される場合や時間で変わる場合がある)と User-Agent ヘッダー(容易に偽装可能)の組み合わせに依存している。これらには限界と欠陥がある」
対策:
- IP 検証(各 AI 企業が公開している IP 範囲との照合)が canonical な検証手法
- OpenAI、Google、Common Crawl、Perplexity、Bing 等は、機械可読な IP 範囲ファイル(JSON)を公開
- Anthropic は IP 範囲ファイルを公開していない(reverse DNS が fallback)
- 2026年から Web Bot Auth(暗号学的署名による認証)が登場(Signature-Agent、Signature-Input、Signature ヘッダー)
6-2. Perplexity の挙動は特殊
Perplexity-User は、Perplexity 自身が「これはボットではなくエージェントなので、robots.txt を尊重する必要はない」と公言しています。さらに、Cloudflare 2025年8月の調査で、未宣言の User-Agent と IP/ASN をローテーションして robots.txt を回避していたことが判明。Perplexity をブロックしたい場合、robots.txt だけでは不十分で、サーバー側または WAF レベルでのブロックが必要です。
6-3. 訓練ボットと検索・エージェントボットの混同
繰り返しになりますが、訓練ボットと検索・エージェントボットを混同すると、データが無意味になります。
- GPTBot の急増は、OpenAI のデータセット更新タイミングかもしれない(書き手にとっての意味は薄い)
- ChatGPT-User の急増は、あなたの記事の専門領域で誰かが質問している(書き手にとって最も意味のあるシグナル)
ダッシュボードや分析スクリプトでは、必ずカテゴリ別に分けて集計してください。
6-4. Google AI Overviews は基本的に追跡できない
Google AI Overviews は、独自のリアルタイムボットを基本的に持たず、既存の Googlebot がインデックスした内容から AI 回答を生成します。つまり、「Google AI Overviews であなたの記事が引用されている」ことを、サーバーログから直接検出することは基本的にできません。例外は Gemini-Deep-Research(Gemini の深い研究エージェント)のみです。
6-5. llms.txt はセキュリティの注意あり
llms.txt が公開書き込み可能な状態になっていると、攻撃者が改ざんして AI に対する prompt injection 攻撃の起点になる可能性が、AI セキュリティ研究で文書化されています。robots.txt と同じレベルのアクセス制御を適用してください。
6-6. ホスティング型プラットフォームでは見えない
note・Qiita・Zenn・Medium・Substack 等のホスティング型プラットフォームでは、上記のすべてのアプローチが直接適用できません。
サーバーログにアクセスできず、Cloudflare を間に挟むこともできず、Edge Middleware も配置できない。
これらのプラットフォームで AI Bot の足跡を見たい場合、現時点では、プラットフォーム側の機能追加を待つしかないのが現実です。
ただし、後述する「ハイブリッド戦略」で、間接的な可視化は可能です。
7. ホスティング型プラットフォーム書き手のためのハイブリッド戦略

note・Qiita・Zenn でメインの記事を書いている書き手が、AI Bot の足跡を可視化したい場合、以下のハイブリッド戦略が考えられます。
7-1. 戦略1:独自ドメインのハブサイトを並走させる
- 独自ドメインで GitHub Pages、Vercel、Cloudflare Pages、Hashnode 等のサイトを運営
- そこに、note・Qiita・Zenn 記事のリンク集、自己紹介、ポートフォリオ、よく参照される記事の Markdown 版を配置
- ハブサイトに対する AI Bot の訪問を可視化する
ハブサイトに AI Bot からのアクセスがあれば、それは「AI Bot があなたの書き手としての存在を知っており、関連情報を探している」シグナルです。
間接的に、note・Qiita・Zenn 記事の到達範囲を推測できます。
7-2. 戦略2:自分の記事を独自ドメインで再公開(カノニカル管理に注意)
- 自分の記事を、独自ドメインのブログでも公開
- HTML の
<link rel="canonical">で元記事を canonical として指定(SEO 上の重複問題回避) - 独自ドメイン側のサーバーログで AI Bot の活動を観察
ただし、各プラットフォームの利用規約と SEO の影響を検討する必要があります。
7-3. 戦略3:Substack 等の中間的プラットフォームへの移行
Substack のようなプラットフォームは、独自ドメインを使うことができ、Cloudflare 経由で配信することも可能です。
note からの完全移行は読者基盤の問題がありますが、Substack や Ghost で並行運営することで、AI Bot 可視化の選択肢が広がります。
7-4. 戦略4:プラットフォーム側への声をあげる
これは技術的解決ではなく、書き手コミュニティとしての行動です。
note、Qiita、Zenn の運営に対して、「AI Bot 別のアクセス分析機能を提供してほしい」と要望を出すこと。
note は2025年1月に Google と資本業務提携を結び、AI検索適合性が強い構造を持つことを公式に明言しています。
プラットフォーム側にとっても、書き手の活動を支える機能として、いずれ提供される可能性は十分にあると考えられます。
8. 解消される悩み・解消されない悩み(再掲・拡張版)
8-1. 解消される悩み
本記事を読んで、以下の悩みは解消・前進します。
-
「AI Bot とは何か、何種類あるのか」が分かる(訓練・検索・エージェントの3カテゴリ、主要 User-Agent カタログ)
-
「自分のサーバーで AI Bot を可視化する方法」が分かる(grep、GoAccess、Python 分析、Cloudflare AI Crawl Control、Edge Middleware)
-
「robots.txt、llms.txt、Web Bot Auth の関係」が整理できる
-
「note・Qiita・Zenn では直接見えない」という構造的限界を理解した上で、ハイブリッド戦略の選択肢を持てる
- 「AI Bot を block すべきか allow すべきか」の判断材料を持てる(コンテンツ盗用リスク vs AI 検索到達機会)
8-2. 解消されない悩み
以下の悩みは、本記事を読んでも解消しません。現在の技術的・制度的限界を、誠実に共有します。
- **「note・Qiita・Zenn 上で直接、AI Bot の足跡を見たい」**── プラットフォーム側の機能追加待ち
- **「ChatGPT・Claude・Gemini の回答で自分の記事が実際に何回引用されたか数えたい」**── AI 企業側からこの情報を提供する標準的な仕組みは現時点で存在しない
- **「AI Agent から金銭的報酬を得たい」**── Cloudflare Pay Per Crawl は実装されているが、実際に支払う AI 企業は限定的
- **「Perplexity のような未宣言クローラーを確実に検出したい」**── User-Agent ローテーションと IP ローテーションを併用するクローラーには根本的に対抗困難
- **「Google AI Overviews での引用を追跡したい」**── Google AI Overviews は独自のリアルタイムボットを基本的に使わない
- **「過去の訓練データから自分のコンテンツを削除したい」**── 各 AI 企業のオプトアウトポータルを使う以外に方法はなく、既に訓練済みのモデルからの削除は基本的に不可能
これらの未解決問題は、書き手コミュニティ全体として、AI 企業・プラットフォーム運営・標準化団体に対して声をあげていく領域です。
9. 書き手としての戦略提言

本記事の最後に、私(Étale Cohomology)から、AI 時代の書き手の皆様への戦略提言を、3点お伝えします。
9-1. 「いいね」ではなく、長期的な「参照される資産」を作る
note のスキ、Qiita のいいね、Zenn のスキは、人間の読者の瞬間的な感情反応を捉えますが、AI Agent が記事を参照する行動は、これらの指標には現れません。
AI時代の書き手にとって、いいね・ストック・閲覧数は、依然として重要な指標だと思います。
その一方で、AI Agent時代には、それらの指標だけでは観測できない、AI Agentから「参照される」という価値も生まれつつあります。
人間の読者からの反応と、AI Agentからの参照。
その両方を意識することが、これからの書き手に求められる時代なのかもしれません。
9-2. ハイブリッド戦略を取る
**note・Qiita・Zenn のプラットフォーム力(既存読者基盤、SEO ドメインパワー、コミュニティ)**と、独自ドメインの可視化能力(サーバーログ、Cloudflare AI Crawl Control、Edge Middleware) を、両立する戦略を取る価値 があります。
私自身は、Étaleブランドとして note・Qiita・Zenn の3媒体で発信しつつ、将来的に GitHub Pages 等の独自ドメインで「自分の城」を構築する計画です。
プラットフォームへの完全依存も、独自ドメインへの完全集約も、それぞれリスクがあります。
9-3. 一次情報・独自体験を増やす
note 公式は「書き手独自の体験(一次情報)や、構造化されて読みやすい記事は、AI 経由の流入において優位性が高い」と明言しています。
AI Agent が無数のウェブページを参照する中で、選ばれる記事は、他では読めない一次情報を含む記事です。
業界の現場感覚、独自の理論的フレームワーク、定量的な分析、実装した検証結果
── こうした一次情報を含む記事を書き続けることが、AI 時代の書き手の最も強い武器になります。
おわりに
AI Agent は、いいねもハートもフォローもくれません。
けれども、確実に、あなたの記事を読み、学習し、参照しています。
その足跡を、技術的に可視化できる範囲で可視化することは、AI 時代の書き手としての現実認識を高める行為です。
同時に、可視化できない範囲があることを受け入れ、それでも書き続けることが、書き手としての覚悟だと、私は考えています。
Qiita・Zenn・note・Medium・dev.to・Substack ── プラットフォームを問わず、AI 時代の書き手として、ともに歩んでいきましょう。
本記事の内容や、AI Bot 可視化の実装でお困りの点があれば、コメント欄でぜひ共有してください。
Étale Cohomology(エタール・コホモロジー)
- note: https://note.com/etale_cohomology
- Qiita: https://qiita.com/etale_cohomology
- Zenn: https://zenn.dev/etalecohomology
- X(旧 Twitter): https://x.com/Etale_Cohomo
参考文献・出典
本記事は、以下の一次・準一次情報に基づいて執筆しました。
- Cloudflare 公式ブログ「Pay Per Crawl」「AI Crawl Control」(2024年9月〜2026年5月)── https://blog.cloudflare.com/tag/pay-per-crawl/
- Cloudflare AI Crawl Control 公式ドキュメント(2026年4月)── https://developers.cloudflare.com/ai-crawl-control/
- Cloudflare 2025年8月調査「Perplexity の未宣言クローラーによる robots.txt 回避」
- nohacks.co「The AI User-Agent Landscape in 2026: A Complete Reference」(2026年4月13日)── https://nohacks.co/blog/ai-user-agents-landscape-2026
- SearchEngineJournal「Complete Crawler List For AI User-Agents [Dec 2025]」── https://www.searchenginejournal.com/ai-crawler-user-agents-list/558130/
- Momentic「List of Top AI Search Crawlers + User Agents (Winter 2025)」── https://momenticmarketing.com/blog/ai-search-crawlers-bots
- SEOJuice「What Web Bot Auth Means If You're Already Blocking AI Crawlers (2026)」── https://seojuice.com/blog/web-bot-auth-googlebot-verification-2026/
- Codersera「llms.txt Explained (May 2026)」── https://codersera.com/blog/llms-txt-complete-guide-2026/
- Presenc AI「State of llms.txt 2026」── https://presenc.ai/research/state-of-llms-txt-2026
- tryzenith.ai「Tracking AI Search Traffic - A Server Log Guide (2026)」── https://www.tryzenith.ai/blog/tracking-ai-search-traffic-server-logs
- aiplusautomation.com「How to Track AI Bots on Your Website: Tools and Methods Compared (2026)」── https://aiplusautomation.com/blog/ai-bot-tracking-tools-methods
- Contently「AI Crawlers Explained: GPTBot, ClaudeBot, and PerplexityBot」(2026年5月6日)── https://contently.com/2026/05/06/ai-crawlers-explained-gptbot-claudebot-perplexitybot/
- Cloudflare ブログ「Introducing pay per crawl」(2026年1月29日)── https://blog.cloudflare.com/introducing-pay-per-crawl/
- SERanking 30万ドメイン調査(2025年11月、llms.txt の AI 引用効果に関する研究)
すべて2026年5月31日に最終アクセスを確認しました。
各 AI 企業の公式 IP 範囲(実装時には必ず最新を確認してください):
- OpenAI GPTBot IP 範囲:https://openai.com/gptbot.json
- Common Crawl IP 範囲:CCBot のドキュメント
- Perplexity IP 範囲:Perplexity 公式ドキュメント
- Bing:Bing 公式
- Google:Google 公式(GoogleBot 含む)
- Anthropic:IP 範囲ファイル未公開(reverse DNS で fallback)