TL;DR
👉 Excelで3時間 → Pythonで実行3秒(実装は3時間)
| やること | 使うモジュール | データ | コード行数 | 削減効果 |
|---|---|---|---|---|
| ① CISA KEVをWebから1行で取得 | pandas | CISA公式CSV | 3行 | Excel: 30分 → Python: 3秒 |
| ② カントリーリスクを箱ひげ図に | seaborn | サンプル(WGI形式) | 10行 | Excel: 20分 → Python: 1秒 |
| ③ 対露輸出を時系列で見る | pandas + matplotlib | 貿易統計サンプル | 20行 | Excel: 1時間 → Python: 2秒 |
| ④ 制裁ネットワークを可視化 | networkx | 公開情報 | 30行 | Excel: 不可能 → Python: 3秒 |
| ⑤ PCAでカントリープロファイル | scikit-learn | WGI 6指標 | 15行 | Excel: 不可能 → Python: 1秒 |
| ⑥ 統合リスクスコアの算出 | pandas merge | 全ソース統合 | 40行 | Excel: 2時間 → Python: 5秒 |
合計 3 時間程度で、Excelで毎月数日かかっていた経済安全保障モニタリングが Python で完全自動化されます。
PCにインストールするものは ゼロ。Google Colaboratory のみで完結します。
まずは動くコードを見てください
理屈の前に、この記事のゴールを見せます。取引先CSVを入れるだけで制裁チェックが終わるコードです。
def run_screening(supplier_csv):
import pandas as pd
# ① 取引先
suppliers = pd.read_csv(supplier_csv)
# ② OFAC SDN
sdn_url = "https://www.treasury.gov/ofac/downloads/sdn.csv"
sdn = pd.read_csv(sdn_url)
# ③ CISA KEV
kev_url = "https://www.cisa.gov/sites/default/files/csv/known_exploited_vulnerabilities.csv"
kev = pd.read_csv(kev_url)
# 名前正規化(最低限)
suppliers["name_norm"] = suppliers["name"].str.lower().str.strip()
sdn["name_norm"] = sdn["name"].str.lower().str.strip()
df = suppliers.merge(
sdn[["name_norm"]],
on="name_norm",
how="left",
indicator=True,
)
df["sdn_hit"] = df["_merge"] == "both"
return df
これだけです。Excelで毎月3時間かかっていた作業が、関数1つに収まります。
以下では、この関数の中身を演習①〜⑥に分解しながら、Pythonとpandasの威力を体験していきます。
合計 3 時間程度で、Excelで毎月数日かかっていた経済安全保障モニタリングが Python で完全自動化されます。
PCにインストールするものは ゼロ。Google Colaboratory のみで完結します。
データの利用について
本記事で扱うデータは、すべてインターネット上で無料公開されているオープンデータです。本記事は 教育目的 で各データソースを参照する方法を示すもので、データ自体を再配布するものではありません。
- 米国政府公開データ (OFAC, BIS, CISA, NIST): 自由利用可能
- World Bank WGI: CC BY 4.0
- OECD Country Risk: 教育目的での参考使用が可能(再配布不可)
- 財務省貿易統計: 公開統計として一般利用可能
業務利用の際は各データソースの最新の利用規約をご確認ください。
なぜ Tableau の次に Python なのか
Tableauは可視化最強です。けれど、こういう場面で詰みます。
| やりたいこと | Tableau | Python |
|---|---|---|
| 毎月のCSVダウンロードを自動化 | △ 手動 | ◎ URLを書くだけ |
| 12,000件の制裁リストを処理 | ○ 動くが重い | ◎ 一瞬 |
| 複雑な前処理(表記ゆれ、欠損) | △ ETL要 | ◎ pandas標準 |
| 機械学習(クラスタリング、PCA) | × ほぼ不可 | ◎ scikit-learn |
| ネットワーク分析 | × 不可 | ◎ networkx |
| 夜間バッチ・自動レポート | × 不可 | ◎ cron + Python |
| コードをGitで管理 | × 不可 | ◎ そのまま |
Tableau編から進んできた方には残酷な事実ですが、「自動化」「機械学習」「Git管理」を本気でやりたいなら、Pythonに来るしかありません。
ただし、TableauとPythonは敵ではない。 最強の組み合わせは「Pythonで前処理・分析 → Tableauで関係者と共有」です。実務で重宝されるアナリストは両方使えます。
セットアップ(所要時間: 0分)
Google Colaboratory を開いて、ノートブックを新規作成するだけです。インストール作業は本当にゼロです。
Step 1: https://colab.research.google.com/ にアクセス
Step 2: 「ノートブックを新規作成」をクリック
Step 3: 終わり
pandasもseabornもnetworkxもscikit-learnも、すべてプリインストール済みです。
演習①:CISA KEV を 3 行で取得する
最初の演習。CISA(米国サイバーセキュリティ庁)が公開している「悪用された脆弱性カタログ」を取ります。Excelで毎月手動ダウンロードしていた人は、ここで人生が変わります。
Colab のセルに貼り付けて Shift + Enter:
import pandas as pd
url = "https://www.cisa.gov/sites/default/files/csv/known_exploited_vulnerabilities.csv"
df = pd.read_csv(url)
print(f"行数: {len(df)}件")
df.head()
はい、終わりです。
実行すると、最新の脆弱性カタログ(数千件)がDataFrameとして手元に来ます。CISAがCSVを更新したら、同じコードを再実行するだけで最新版になります。
Excel版「毎月のCISA KEVチェック」: ブラウザを開く → CISAサイトへ移動 → CSVをダウンロード → Excelで開く → 巨大すぎて固まる → 仕方なく必要列だけコピー → 別シートに貼り付け → ピボットテーブル...合計30分。
Python版: 上のコードを実行。3秒。
ベンダー別 Top 10 を一発で出す
df.groupby("vendorProject").size().sort_values(ascending=False).head(10)
これがExcelで言うピボットテーブル相当の集計です。1行で完了します。
Microsoft の脆弱性だけ抽出
df[df["vendorProject"] == "Microsoft"]
Excelの「オートフィルター」がこの1行に圧縮されています。
演習②:カントリーリスクを箱ひげ図に
Tableau編でやったあの箱ひげ図(Box Plot)を、seaborn で書きます。
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(42)
df = pd.DataFrame({
"region": ["Asia"]*15 + ["Europe"]*15 + ["Middle East"]*15 + ["Africa"]*15,
"risk": list(np.random.normal(3.5, 1.5, 15)) +
list(np.random.normal(2.0, 1.0, 15)) +
list(np.random.normal(6.0, 2.0, 15)) +
list(np.random.normal(5.0, 2.0, 15))
})
plt.figure(figsize=(10, 6))
sns.boxplot(x="region", y="risk", data=df, palette="Set2")
plt.title("Country Risk by Region")
plt.show()
Tableauで何回もクリックしていたあの操作が、10行で済みます。しかも、データを実データ(World Bank WGI等)に差し替えれば、業務でそのまま使えます。
演習③:対露輸出を時系列で見る + 地政学イベントを縦線で重ねる
これが Python の真骨頂。Excelでは無理、Tableauでもギリギリ、という分析です。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# サンプル: 対露輸出の月次データ
np.random.seed(42)
dates = pd.date_range("2020-01-01", "2024-12-01", freq="MS")
trend = np.linspace(800, 900, len(dates))
seasonal = 50 * np.sin(2 * np.pi * np.arange(len(dates)) / 12)
noise = np.random.normal(0, 30, len(dates))
# 2022年2月以降に60%減
shock = np.where(dates >= "2022-02-24", -500, 0)
value = trend + seasonal + noise + shock
plt.figure(figsize=(14, 6))
plt.plot(dates, value, color="steelblue", linewidth=2)
# 地政学イベントを縦線で
events = {
"2022-02-24": "Ukraine Invasion",
"2022-03-01": "Sanctions Begin",
"2022-10-07": "US Semi Restrictions",
}
for date, label in events.items():
plt.axvline(pd.Timestamp(date), color="red", linestyle="--", alpha=0.5)
plt.text(pd.Timestamp(date), value.max(), label,
rotation=90, fontsize=9, va="top", color="red")
plt.title("Japan Exports to Russia: Monthly")
plt.show()
実行すると、対露輸出の長期トレンドに「ウクライナ侵攻」「制裁参加」「半導体規制強化」が縦線で重なります。
経営会議で「制裁の影響、どのくらいだった?」と聞かれたとき、印象論ではなく定量データで答えられます。これは強い。
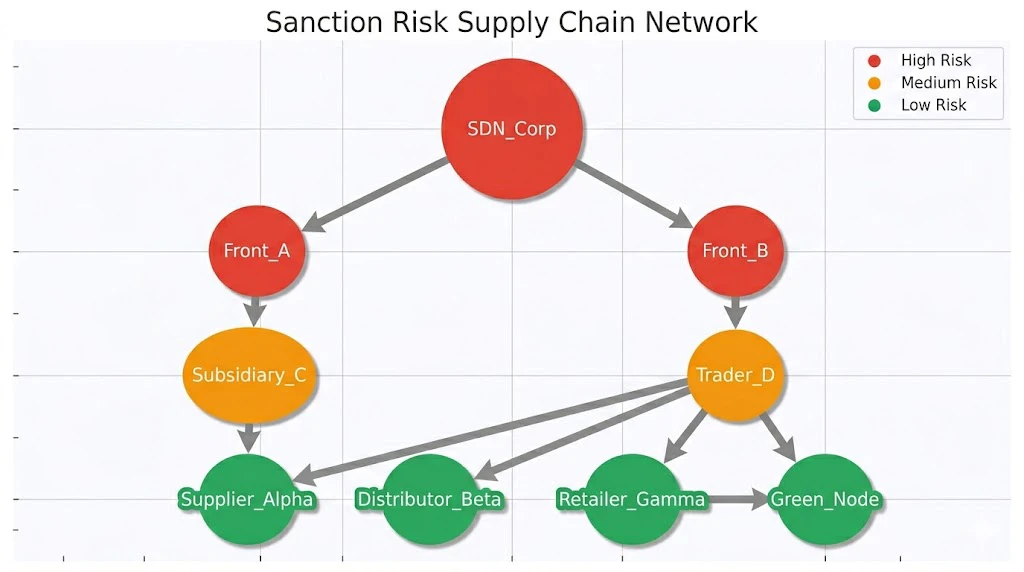
演習④:制裁ネットワークを networkx で可視化
ここが Python じゃないとできない領域。Tableauには絶対に描けない図です。
制裁対象企業 → フロント企業 → 子会社 → 商社 → 自社、というサプライチェーンの「制裁回避ルート」を可視化します。
import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph()
# ノード(企業)とリスクレベル
nodes = {
"SDN_Corp": "high",
"Front_A": "high",
"Front_B": "high",
"Subsidiary_C": "medium",
"Trader_D": "medium",
"Trader_E": "low",
"JP_Co_1": "low",
"JP_Co_2": "low",
}
for n, r in nodes.items():
G.add_node(n, risk=r)
# エッジ(取引関係)
G.add_edges_from([
("SDN_Corp", "Front_A"),
("SDN_Corp", "Front_B"),
("Front_A", "Subsidiary_C"),
("Front_B", "Trader_D"),
("Subsidiary_C", "Trader_E"),
("Trader_D", "JP_Co_1"),
("Trader_E", "JP_Co_2"),
])
color_map = {"high":"#E74C3C","medium":"#F39C12","low":"#27AE60"}
colors = [color_map[G.nodes[n]["risk"]] for n in G.nodes()]
plt.figure(figsize=(12, 8))
pos = nx.spring_layout(G, seed=42)
nx.draw(G, pos, node_color=colors, with_labels=True,
node_size=2000, font_size=10, arrows=True)
plt.show()
PageRank で「最重要ノード」を計算
import pandas as pd
pr = nx.pagerank(G)
print(pd.Series(pr).sort_values(ascending=False))
Google検索のPageRankと同じアルゴリズムで、「ネットワーク内で最重要な企業」を機械的に判定します。
人間が「重要そう」と思うノードと、PageRank が出すノードがズレることもあります。そこに発見があります。
演習⑤:PCA で「カントリープロファイル」を 2 次元に圧縮
World Bank の WGI(世界ガバナンス指標)は 6 次元あります。「政治安定」「法の支配」「腐敗管理」「規制品質」「政府効率」「言論自由」。
これを人間の脳で同時比較するのは無理です。PCA で 2 次元に圧縮します。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
data = {
"政治安定": [85, 90, 30, 25, 75, 80, 45, 70],
"法の支配": [88, 92, 35, 30, 80, 85, 40, 75],
"腐敗管理": [82, 89, 28, 22, 78, 83, 38, 72],
"規制品質": [86, 91, 32, 27, 79, 84, 42, 73],
"政府効率": [84, 88, 33, 25, 76, 82, 41, 74],
"言論自由": [80, 90, 20, 15, 85, 88, 35, 70]
}
countries = ["Japan","Germany","Russia","N.Korea","France","UK","China","Italy"]
df = pd.DataFrame(data, index=countries)
df_scaled = StandardScaler().fit_transform(df)
pca = PCA(n_components=2)
pc = pca.fit_transform(df_scaled)
plt.figure(figsize=(10, 7))
plt.scatter(pc[:,0], pc[:,1], s=200)
for c, (x, y) in zip(countries, pc):
plt.annotate(c, (x, y), fontsize=12)
plt.xlabel(f"PC1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"PC2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.show()
実行すると、6次元のカントリープロファイルが 2 次元の散布図になります。
民主主義国(Japan, Germany, France, UK)は近くに集まり、権威主義国(Russia, N.Korea, China)は反対側に位置することが視覚的にわかります。
これが scikit-learn の威力です。多変量解析がコード15行で完了します。Excel では絶対に無理、Tableau もほぼ不可能(TabPy連携で頑張れば、ですが)。
演習⑥:複数データを統合した実務リスク評価
最後の演習。これが業務で実際に作りたいレポートです。
3つのデータソース(取引先一覧 / カントリーリスク / 制裁リスト)を merge() で結合し、統合リスクスコアを計算します。
import pandas as pd
# 表1: 取引先一覧
suppliers = pd.DataFrame({
"name": ["Alpha", "Beta", "Gamma", "Delta", "Epsilon"],
"country": ["JP", "US", "CN", "RU", "DE"],
"spend": [1500, 3200, 2400, 800, 1900],
})
# 表2: 国別リスク
country_risk = pd.DataFrame({
"country": ["JP","US","CN","RU","DE"],
"risk": [2.1, 3.0, 5.5, 7.5, 2.8],
"sanctions": [False,False,True,True,False],
})
# 表3: 個別制裁リスト
sdn_list = pd.DataFrame({
"name": ["Delta"],
"list_type": ["SDN"],
})
# 統合(VLOOKUPの代わり)
df = suppliers.merge(country_risk, on="country", how="left")
df = df.merge(sdn_list, on="name", how="left")
df["sanctioned"] = df["list_type"].notna()
# 統合スコア
df["integrated_risk"] = (
df["risk"] * 0.5 +
df["sanctions"].astype(int) * 5 +
df["sanctioned"].astype(int) * 10
)
# リスクレベル分類
df["risk_level"] = pd.cut(df["integrated_risk"],
bins=[0, 3, 6, 100], labels=["Low","Medium","High"])
print(df.sort_values("integrated_risk", ascending=False))
実行すると、各取引先の統合リスクスコアと「Low / Medium / High」のラベル付きの表が出力されます。
Excelで言うと、3つのシートを VLOOKUP で結合 → 計算列を追加 → IF 関数でランク分け、という作業が、コード40行で完了します。
そして、来月もう一度実行すれば、データが更新された最新版が出ます。
おまけ: Python の出力を Tableau に流す
Pythonで前処理してCSVに書き出せば、そのままTableauに食わせられます。
df.to_csv("integrated_risk_report.csv", index=False)
これで「Pythonで自動化された経済安全保障モニタリング」と「Tableauで関係者に共有できるダッシュボード」が両立します。
ベストプラクティス: 月次バッチで Python が自動的に CSV を生成 → Tableau がそれを読みに行く → 経営層がダッシュボードで見る。これで「毎月の手動作業」が完全に消えます。
よくある質問
Q. PythonとTableau、どっちから始めるべき?
可視化に慣れたいならTableau、自動化したいならPython。両方やるのが王道です。本記事のシリーズはTableau編 → Python編の順を推奨します。
Q. Colab無料版で十分?
経済安全保障データ分析の用途では十分です。SDN 12,000件もCISA KEVも余裕です。重い機械学習モデルを訓練しないなら、無料版で完結します。
Q. 社内データを Colab に上げて大丈夫?
Colab無料版にアップしたデータはGoogleのサーバに送られます。社内機密データを扱う場合は、社内のJupyterサーバ、または有償のColab Enterpriseを使ってください。本記事の演習はすべて公開データなのでColab無料版でOKです。
Q. pandas のエラーが解決できない
-
ModuleNotFoundError→!pip install モジュール名をセル先頭に書く -
KeyError→df.columnsで列名を確認(スペル違い、大文字小文字違いが多い) -
IndentationError→ 字下げをスペース4個で統一
エラーメッセージをそのままGoogle検索すると、StackOverflowに必ず答えがあります。
Q. このコードは業務で実際に使っていい?
コード自体はCC BY 4.0で自由に利用可能です。データソースは各サイトの利用規約をご確認ください。商用ツールに組み込む場合は、各データソースに別途確認してください。
Q. 次は何を学ぶべき?
scikit-learnで機械学習に進むのが王道です。さらにその先には、ユークリッド空間ではなく曲がった多様体上でのデータ分析(Geometric Data Science)というフロンティアがあります。気になる方は GitHub の geometric-intelligence-saga リポジトリを覗いてみてください。
もっと深く学びたい人へ 📚
この記事は、筆者が作成した 全 12 回の Python 研修教材から、Qiita 読者向けに 6 回ぶんを抜き出したダイジェストです。
完全版では以下も扱っています:
- 第 3 回: 表記ゆれ統一・型変換・データクリーニングの実務テクニック
- 第 4 回: ヒストグラム・散布図・ヒートマップなど可視化の網羅
- 第 5 回: 記述統計と相関分析の徹底解説
- 第 7 回: ネットワーク中心性指標(degree, betweenness, PageRank)の解釈
- 第 9 回: PCA に加えて K-means クラスタリングによる自動分類
- 第 10 回: CISA KEV 4分割ダッシュボードの完全実装
- 第 11 回: 統合リスクスコアの設計と高リスクアラート自動化
- 付録 A: 公開データソース完全リスト
- 付録 B: pandas / seaborn / networkx クイックリファレンス
- 付録 C: よくあるエラー6種と対処法
完全版は GitHub で無料公開しています(CC BY 4.0)。
🔗 GitHub リポジトリ: https://github.com/EtaleCohomology/geometric-intelligence-saga
tools/02_python-data-analysis/ フォルダに、全 12 回の PDF 教材が入っています。
Tableau 編の教材も同じリポジトリの tools/01_tableau-economic-security/ にあります。
👉 これが完成形です
取引先CSVを入れるだけで制裁チェックが終わるコードはこれです。
def run_screening(supplier_csv):
import pandas as pd
# ① 取引先
suppliers = pd.read_csv(supplier_csv)
# ② OFAC SDN
sdn_url = "https://www.treasury.gov/ofac/downloads/sdn.csv"
sdn = pd.read_csv(sdn_url)
# ③ CISA KEV
kev_url = "https://www.cisa.gov/sites/default/files/csv/known_exploited_vulnerabilities.csv"
kev = pd.read_csv(kev_url)
# 名前正規化(最低限)
suppliers["name_norm"] = suppliers["name"].str.lower().str.strip()
sdn["name_norm"] = sdn["name"].str.lower().str.strip()
# 照合
df = suppliers.merge(sdn[["name_norm"]], on="name_norm", how="left", indicator=True)
df["sdn_hit"] = df["_merge"] == "both"
return df
おわりに
経済安全保障・地政学リスクは、もはや一部の専門家だけの仕事ではなくなりました。
そして、その分析を「毎月手動」でやり続ける時代も終わりました。
本記事の Python コードを業務に組み込めば、毎月のあの作業が「コードを実行する」だけになります。浮いた時間を、データの解釈や、関係者への説明に使えます。
Tableau 編から進んできた方、ようこそコードの世界へ。
Python から始めた方、ぜひ Tableau 編も見てみてください。両方使えると、最強です。
質問・コメントお待ちしています 🙋