はじめに
-
この記事のゴール
- 日本語文字の抽出における実務的な落とし所を、AIの提案を比較しながら検証する
- 結論として
[^\x01-\x7E]が日本語マッチとして好ましい ことを示す
-
実験環境:Google Colab(Python 3.x)
1) セットアップ
必要なもの
- Googleアカウント
- Google Colabにアクセスできる環境
Colabで試す方法
- Googleアカウントで Colab を開く
- [ノートブックを新規作成] をクリック
- 記事内のコードをセルごとにコピーして実行していきます
ハードウェアの確認(任意)
Colabのハードウェア環境情報を確認したい場合は、以下を実行します。不要な場合はスキップしてください。
2) 検証用サンプルデータ
ASCII、日本語、全角記号、絵文字が混在のケースを用意します。このサンプルデータを元に、各正規表現でマッチさせた結果を検証していきます。
次のコードを実行しておいてください。
import re
samples = [
"Hello, world!",
"Python3.12",
"日本語テキストです。",
"アイウエオ (半角カナ)",
"アイウエオ(全角カナ)",
"漢字とカタカナの混在:試験アイテム123",
"スペース含む テキスト",
"改行\nを含む",
"句読点。全角記号,()「」『』※・",
"絵文字🙂と日本語",
"Chinese 中文 和 韓文 한국어",
"ASCIIだけ!!!",
"ハンカクと全角カナ混在 カタカナ アイウ",
"ヌル\0",
"デル\u007F",
"拡張漢字𠮷野家と通常漢字漢字",
]
3) AIに「日本語にマッチする正規表現」を聞く
以下のような質問を各AIに投げてみます。
-
各AIに同文を明記:
日本語の文字にマッチする正規表現を教えて。Pythonのreモジュールで使える形でお願いします。
前提として、モデルの種類やバージョン、プロンプトの細かい違いで回答が変わります。ユーザーの環境で同じ質問を投げても、同じ回答が得られるとは限らない点に注意してください。
各AIの回答例から提示された該当の正規表現を抜粋し、以下に示します。
ChatGPT(GPT-5)


Claude(Opus 4.1)

Gemini(gemini-2.5-pro)

どれも正しいのですが、これらの正規表現の場合、句読点・半角カナ・拡張漢字・絵文字などが漏れるケースが多いことに注意が必要です。次に、その点を検証していきます。
4) AIが出した候補を検証
ここでは「ありがちな候補」と「本命」を比較します。
-
ありがちな候補:
r"[ぁ-んァ-ヶ一-龠々]"r"[\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]"
-
本命:
r"[^\x01-\x7E]"
この本命の正規表現の有用性を検証していきます。
Note: ありがちな候補としては上記以外にも r"[一-龥]" や r"[\p{Hiragana}\p{Katakana}\p{Han}]"(※reモジュール非対応(regexモジュールは対応))などもありますが、ここでは割愛します。
次のコードを実行してください。
candidate_patterns = {
# ひらがな・カタカナ・漢字だけを対象にする「ありがちな」書き方。
"range_simple": r"[ぁ-んァ-ヶ一-龠々]",
# Unicodeのブロック範囲を指定した書き方。
"unicode_block": r"[\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]",
# ASCII以外の文字をまとめて拾うシンプルな書き方。今回の本命。
"ascii_negate_main": r"[^\x01-\x7E]",
}
def test_pattern(pattern, texts):
prog = re.compile(pattern)
results = []
for s in texts:
m = prog.findall(s)
results.append({
"text": s, # 元の文字列
"matched": "".join(m), # マッチした文字を連結したもの
"count": len(m), # マッチした文字の数
})
return results
for name, pat in candidate_patterns.items():
print(f"\n--- Pattern: {name} -> {pat}")
res = test_pattern(pat, samples)
for r in res:
print(f"text: {r['text']}\nmatched: {r['matched']}\ncount: {r['count']}\n")
出力結果
--- Pattern: range_simple -> [ぁ-んァ-ヶ一-龠々]
text: Hello, world!
matched:
count: 0
text: Python3.12
matched:
count: 0
text: 日本語テキストです。
matched: 日本語テキストです
count: 9
text: アイウエオ (半角カナ)
matched: 半角カナ
count: 4
text: アイウエオ(全角カナ)
matched: アイウエオ全角カナ
count: 9
text: 漢字とカタカナの混在:試験アイテム123
matched: 漢字とカタカナの混在試験アイテム
count: 16
---省略---
出力が長いので省略しました。
実際の出力結果はGoogle Colab上で確認してみてください。
次に、出力結果の特徴を各パターン毎にまとめます。
range_simple = [ぁ-んァ-ヶ一-龠々]
含まれるもの
- ひらがな (
ぁ-ん) - カタカナ (
ァ-ヶ) - 一般的な漢字 (
一-龠々)
漏れるもの(マッチしない例)
- ✅ 半角カナ →
アイウエオ - ✅ 全角記号 →
。、「」『』()※・,など - ✅ 句読点(全角) →
。や、 - ✅ 拡張漢字(CJK拡張A/B など) →
𠮷(吉の異体字)など - ✅ 絵文字 → 🙂 😂 🔥 など
unicode_block = [\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]
含まれるもの
- ひらがな (
\u3040-\u309F) - カタカナ (
\u30A0-\u30FF) - 一般的な漢字 (
\u4E00-\u9FFF)
漏れるもの(マッチしない例)
- ✅ 半角カナ →
アイウエオ(U+FF61〜U+FF9F) - ✅ 全角記号・句読点 →
。、「」『』()※・,(U+3000〜U+303F) - ✅ 漢字の拡張領域 →
𠮷(U+20000以降) - ✅ 絵文字 → 🙂 😂 🔥(
U+1F600など)
ascii_negate_main = [^\x01-\x7E](本命)
- ASCII以外すべてマッチするので、上記の「漏れ」は起きにくい。
- ただし「中国語・韓国語・絵文字・丸数字」なども拾うため、“日本語だけ” ではない。
- 実務では「ASCII以外=非英語データ」とみなすほうが安定。
✅ まとめ表
| 文字例 | range_simple ([ぁ-んァ-ヶ一-龠々]) | unicode_block ([\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]) | ascii_negate_main ([^\x01-\x7E]) |
|---|---|---|---|
| ひらがな「あ」 | ✔ | ✔ | ✔ |
| カタカナ「ア」 | ✔ | ✔ | ✔ |
| 漢字「漢」 | ✔ | ✔ | ✔ |
| 句読点「。」 | ❌ | ❌ | ✔ |
| 半角カナ「ア」 | ❌ | ❌ | ✔ |
| 全角記号「※」 | ❌ | ❌ | ✔ |
| 拡張漢字「𠮷」 | ❌ | ❌ | ✔ |
| 絵文字「🙂」 | ❌ | ❌ | ✔ |
4-1) そもそもASCIIとは?
ASCII(American Standard Code for Information Interchange)は1960年代に策定された文字コード規格で、1文字を 7ビット(0x00〜0x7F)で表し、全部で128文字を定義しています。
- 制御文字(0x00〜0x1F, 0x7F):NUL, LF, TAB, DELなど
- 印字可能文字(0x20〜0x7E):半角スペース, 英字, 数字, 記号
このASCIIの定義を前提に、次章以降で「ASCII以外」をどう検出するかを検証していきます。
5) 速度感の目安
大規模テキスト処理での体感差を確認します。
次のコードを実行してください。
import timeit
test_text = "漢字カタカナEnglish🙂" * 1000
patterns = [
r"[^\x01-\x7E]",
r"[ぁ-んァ-ヶ一-龠々]",
r"[\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]",
]
for p in patterns:
def run():
return re.findall(p, test_text)
t = timeit.timeit(run, number=1000)
print(f"{p:30s} -> {t:.4f} sec")
出力結果(環境により前後します)
[^\x01-\x7E] -> 1.4825 sec
[ぁ-んァ-ヶ一-龠々] -> 1.2450 sec
[\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF] -> 1.2553 sec
コメント:実測では大きな差はなく、いずれも実用上十分な速度です。読みやすさと保守性を優先すれば [^\x01-\x7E] が有利です。
6) AIにどのように質問を投げればよいか
今までの検証内容から、以下のような質問文が考えられます。
ASCII文字以外をマッチさせる日本語用の正規表現を提示してください。Pythonで使用します。
ChatGPT(GPT-5)

Claude(Opus 4.1)
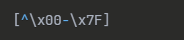
Gemini(gemini-2.5-pro)

どのAIも複数の候補を返してくれましたが、共通してよく出てきたのは[^\x00-\x7F]です。唯一、ChatGPTだけが[^\x01-\x7E]を提案しています(上図の赤線箇所参照)。
ここで重要なのは、[^\x00-\x7F]の場合、NUL (0x00) と DEL (0x7F) も含まれてしまう点です。実務ではこれらを除外できる[^\x01-\x7E]の方が望ましいでしょう。
そこで質問をもう一段階具体的にします。
ASCII文字以外をマッチさせる日本語用の正規表現を提示してください。Pythonで使用します。ASCIIの範囲は 0x01〜0x7E と見なし、NUL (\x00) と DEL (\x7F) は 非ASCIIとしてマッチ対象に含めたいです。
この条件を加えると、各AIは揃って [^\x01-\x7E] を回答しました。
ポイント: 曖昧な「日本語」を「ASCII以外」「NULとDELは非ASCII扱い」と定義したことで、AIの回答精度が上がった。要件定義の難しさは人間でもAIでも同じ。
ここがハマりどころ
Pythonの re モジュールで [^\x01-\x7E] を使うと、ASCII範囲の可視文字を除外して非ASCIIを抽出できます。
これにより日本語や全角記号などを簡単に検出できます。
一方 [^\x00-\x7F] だと NUL (0x00) や DEL (0x7F) まで拾ってしまい、ログやデータ処理でノイズになる可能性があります。
7) まとめ
- 複数のAIが提案する正規表現はどれも一理あるが、句読点や半角カナなどが漏れるケースが多い。
- 日本語を正規表現だけで厳密に定義するのは難しい。Unicodeの範囲や文字種が膨大すぎるため。
- 実務では「完璧さ」より 安定運用とシンプルさ を重視すべき。
- よって、実務的には
[^\x01-\x7E]を選ぶのが一番現実的。ASCII可視域 (0x01–0x7E) を残しつつ、NUL/DEL を除外できるので安心です。